 基于生成式人工智能的工業軟件自主創新路徑分析
基于生成式人工智能的工業軟件自主創新路徑分析
01
引言
當前,以ChatGPT 為代表的預訓練大模型 展現出自主學習、跨模態理解、推理抽象思維和人類社會理解等特征優勢,正引發新一輪人工智能范式革命,成為推動科技跨越發展、產業優化升級、生產力整體躍升的重要驅動力。隨著以大模型為代表的生成式AI 技術可用性增強及工業信息化水平提升,通用AI 的工業落地時間間隔逐步縮短,大模型為工業軟件領域自主創新提供了有效路徑。
02
我國工業軟件發展現狀
工業軟件是工業知識的計算機代碼化表達,是工業知識、經驗、技能長期沉淀積累并數學化、工程化、代碼化的結果。工業軟件作用于工業產品的研發設計、生產制造、經營管理和運維服務等全生命周期,具有細分種類多、功能差異大、行業壁壘高和用戶粘性強等特點。
我國工業軟件門類相對齊全,市場發展迅速。據工信部統計數據顯示,2021 年,我國工業軟件市場規模達2 414 億元,同比增長24.8%,未來五年內將持續以兩位數幅度增長,市場規模有望于2026 年突破4 300 億元, 具有較強的發展潛力。但總體上看,國產工業軟件市場占有率較低,與國外的差距較大,主要存在市場規模小、產品受制于人、產業安全受國外威脅,以及關鍵技術和工業知識缺失等四大短板。
云計算、大數據、人工智能等新一代信息技術正在重塑工業軟件形態。與傳統的工業軟件相比,基于新一代信息技術的工業軟件采用工業互聯網平臺體系架構, 依托工業基礎軟件的支持,以數據要素為驅動,通過低代碼工具和應用開發平臺實現應用軟件的定制化開發, 以云化和服務化的方式部署。基于新一代信息技術的工業軟件在工業知識軟件化基礎上,增加了對工業大數據的處理和智能化分析能力,使解決復雜工業系統建模、控制與優化的難題成為可能,是工業互聯網時代的新型生產工具。
03
大模型在工業領域的應用情況
3.1 大模型賦能生產制造全生命周期
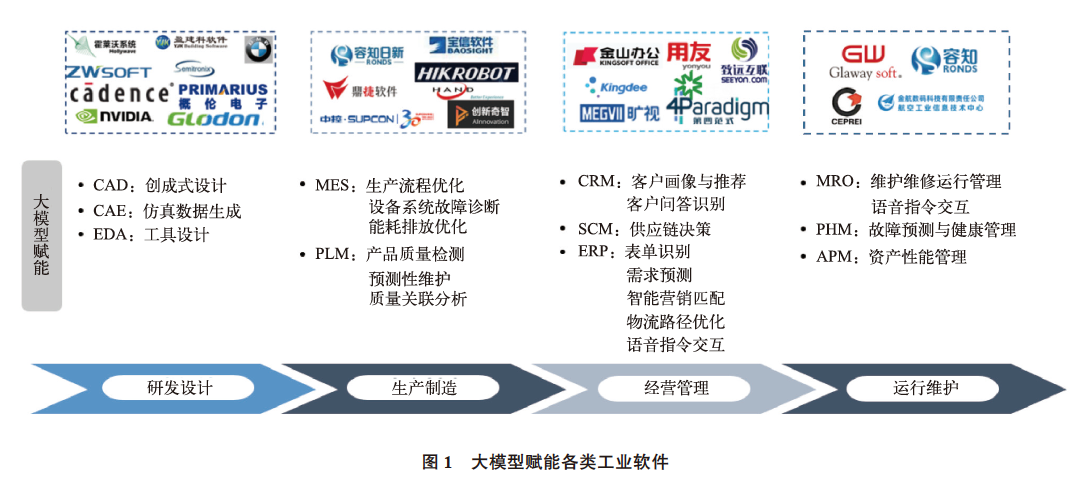
隨著大模型技術的躍遷式發展,生成式AI 同工業領域加速融合,為工業軟件創新發展提供了重要實現路徑。基于大模型的自動識別、模型優化和推理決策三大核心能力,可實現對研發設計、生產制造、經營管理和運維服務等工業制造全生命周期的賦能。大模型賦能各類工業軟件如圖1 所示。
在研發設計方面,基于云計算和大數據技術,大模型能夠自動生成或優化設計方案,提高EDA、CAD、CAE 等軟件設計效率和精度。例如,Cadence 公司推出了Allegro X AI technology 新一代系統芯片設計技術,利用生成式AI 簡化系統設計流程,將PCB 設計周轉時間縮短至原來的十分之一;大模型賦能創成式設計,可實現3D CAD 的自主優化設計,提升Siemens Solid Edge、PTC Creo 等主流CAD 的設計效率。
在生產制造方面,利用自然語言處理和計算機視覺等算法,大模型實現與人類的自然交互和協作,提高生產效率和質量。比如,西門子自動化生產SIMATIC IT 軟件引入ChatGPT,有效實現了操作者與系統自然語言的交互;西門子和微軟正在合作開發可編程邏輯控制器(PLC) 的代碼生成工具,利用ChatGPT 通過自然語言輸入生成PLC 代碼。
在經營管理方面,通過遷移學習和模型微調,大模型能夠快速掌握垂直領域知識,提高ERP、CRM、SCM 等軟件的管理效率和水平。例如,微軟推出了GPT 互動式AI 能力商業產品Dynamics 365 Copilot 和Microsoft 365 Copilot,大幅提升用戶在經營管理類軟件上的工作效率, 未來將擴展至供應鏈管理、客戶服務和市場營銷等場景;國內企業第四范式上線企業級產品4Paradigm SageGPT, 將大模型與垂直領域專業知識融合,具備企業級場景下的多模態及Copilot 能力;曠世科技布局基于視覺大模型的供應鏈智能管理,探索基于“感知- 決策- 執行- 反饋” 的全鏈條倉儲物流優化方案。
在運維服務方面,大模型可有效提升早期缺陷檢測、預測性維護、產品質量分析和生產預測等能力,持續優化MRO、PHM 等軟件性能。美國明星創業公司Uptake 將AI 能力引入設備預測性維護,并取得良好運營效果;國內容知日新開展基于AI 的工業設備狀態監測與故障診斷研究,打造基于數據、算法和算力管理的PHM 引擎, 提升智能運維能力。
3.2 大模型的工業應用挑戰
大模型在工業領域具有廣闊的應用前景,國內外科技巨頭及工業軟件企業已開展相關研究布局,主要是調用大模型的基礎能力,實現輔助操作環節應用。大模型賦能工業軟件研發設計等核心環節主要面臨技術、數據和產業三方面的挑戰。
技術方面,當前國內在大模型領域的基礎技術儲備不足、通用大模型性能仍需提升、工業領域垂直大模型尚待構建。同時,大模型訓練部署對算力、存儲、數據等基礎設施有較高需求,傳統的工業軟件主要運行在本地,計算和存儲能力有限,更新迭代慢,使得生成式AI 的研發設計、工業仿真、低代碼開發等業務場景的落地受到阻礙。
數據方面,我國工業領域數據體量大、實時性高, 存儲成本大、價值密度低,數據源異構性強,數據孤島現象嚴重,工業數據開放程度低,各種類型的設備和工序之間相互獨立,數據流通缺少統一的標準。當前工業場景的數據量對于深度學習而言都還是小規模,需要對全行業的數據進行匯聚、對齊和訓練,形成面向工業軟件領域的大模型。
產業方面,大模型的工業應用仍在探索階段。在供給側,大模型需要高昂的資金和人才投入。我國工業軟件企業綜合優勢不強,當前還停留在基礎能力補短板階段,缺乏復合型技術人才。在需求側,當前大模型對知識原理的理解有限,尚未做到答案完全可控與準確,而工業領域對安全可靠性要求高,當前大模型缺乏可落地的應用場景。
04
基于大模型的工業軟件技術創新路徑
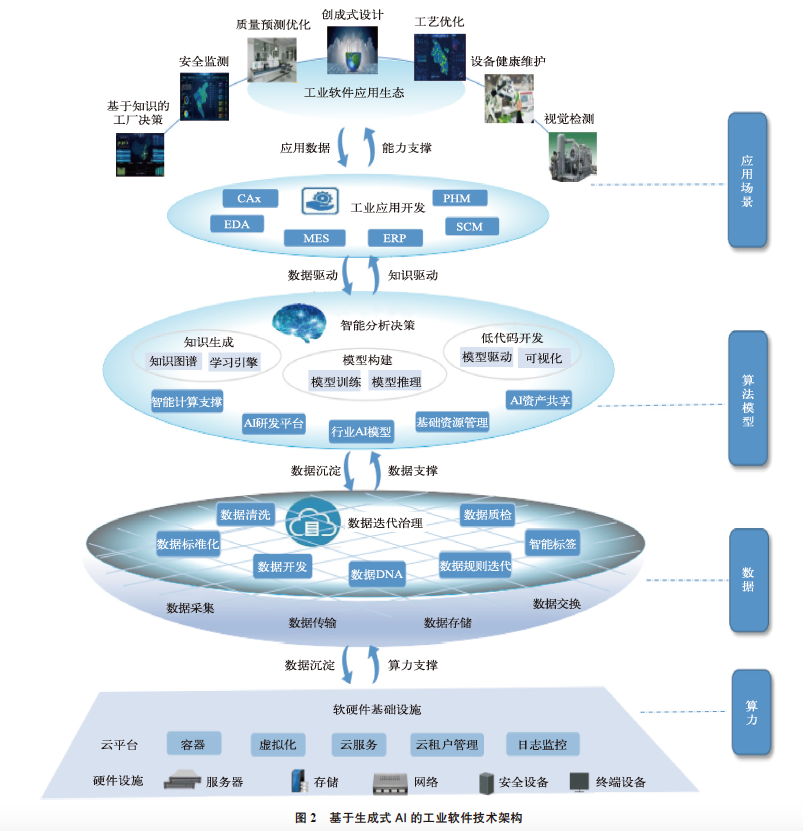
大模型在工業軟件領域具有廣闊的應用前景,國內外科技巨頭及工業企業已開展相關研究布局,但目前應用尚淺,主要是調用大模型的通用能力提供基礎服務。基于生成式AI 的工業軟件技術架構如圖2 所示。為提升大模型在工業機理方面的應用深度,推動生成式AI 與工業軟件融合發展,可考慮從如下幾方面進行研究布局。
1)構建工業軟件云。大模型的算力門檻非常高,傳統的工業軟件主要運行在本地,計算和存儲能力有限, 更新迭代慢,嚴重制約大模型的應用。工業軟件云化部署后,可大幅提高基礎服務的多樣性,通過調用高性能計算、GPU 算力、大數據服務等資源,滿足大模型訓練部署對算力、存儲、數據等基礎設施的需求,降低開發和應用成本,使得基于生成式AI 的研發設計、工業仿真、低代碼開發等業務場景能夠真正落地。通過將散落分布的業務數據匯聚到云上,對大模型進行持續優化迭代, 有效提升產品的差異化競爭力。
2)建設工業大腦。改變過去工業領域“碎片化”、“作坊式”、成本消耗大、效率低的AI 模式,基于基礎大模型底座,匯聚海量行業數據,通過模型微調、蒸餾等方式, 形成面向各個領域的行業大、中、小模型,實現工業知識和專家經驗的沉淀,構建具有深度認知能力的工業大腦。通過大小模型協同的方式,快速、高效地開發面向特定行業場景的各類工業軟件/APP,提升工業軟件的智能化水平。
3)構建“SaaS+ 低代碼”的工業軟件應用生態。工業SaaS 把傳統架構的工業軟件分解成具有統一接口、靈活且可配置的應用,通過封裝大量通用的行業Know-how 知識經驗或知識組件以及算法和原理模型組件,以低代碼方式構建上層工業APP。大模型的代碼生成能力的跨越式進步有望重塑工業PaaS 低代碼開發平臺。未來隨著生成式AI 在代碼生成能力方面的逐步成熟,可實現零代碼研發設計和生產優化,大幅提升工業軟件的應用創建能力、降低應用開發成本。
4)推動工業軟件開發新生態。從技術趨勢來看,設計、制造、仿真一體化趨勢推動工業軟件超融合發展。基于超融合平臺,可以實現AI 模型開發、訓練、調優、運營等復雜過程的封裝,提供低門檻、高效率的企業服務。從開發模式來看,多主體協作趨勢推動工業軟件走向開源與開放,大模型通過自動生成代碼、提供開源工具等方式,助力工業軟件開發。利用AI 技術生成需求文檔、功能規格說明書、代碼、測試用例和測試腳本等,實現持續交付,推動軟件工程3.0 的發展,真正實現模型驅動開發、數據驅動開發和AI 原生開發。
05
發展建議
為提升大模型的應用深度,推動生成式AI 與工業軟件的深度融合,建議搶先布局基于大模型的工業軟件應用體系,突破工業軟件核心關鍵技術,推動基于新一代信息技術的工業軟件融合創新。
1)全面規劃工業軟件創新發展的頂層戰略。制定重點行業國產工業軟件創新行動計劃,明確基于大模型的國產工業軟件發展目標、重點任務和關鍵舉措,培育基于生成式AI 的工業軟件等重點技術攻關項目。聚焦通用人工智能和工業軟件融合創新,著力構建一個適用的技術體系架構、打造一套完整的技術標準體系、支持一批重點技術攻關項目、形成一批典型的融合應用模式,以及培育一批有成效的“AI+ 工業應用”平臺,部署重點行業工業軟件應用先試先行和試點示范工程。
2)超前布局基于大模型的工業軟件技術體系。一方面,鼓勵工業軟件云化部署,支持企業開放高性能計算、GPU 算力、大數據服務等資源,通過共享算力、數據的方式,降低開發和應用成本。通過將散落分布的業務數據匯聚到云上,對大模型進行持續優化迭代,形成完整高效的開源算法模型,有效提升產品的差異化競爭力。另一方面,構建工業軟件領域的大模型評測標準體系, 研究多模態多維度的基礎模型評測基準及評測方法,開發基礎模型評測工具集,建立公平高效的自適應評測機制,推動大模型在研發設計、生產制造、經營管理和運維服務等環節的深度融合應用。
3)逐步形成大模型賦能工業軟件的數據應用機制。一是探索建立基于數據托管機制的大模型訓練數據監管體系,確保工業數據來源可靠,在數據標準、數據質量、數據安全和隱私保護等方面依法合規,保障大模型輸出結果的高質量并符合監管要求。二是建立工業軟件數據交換共享機制,使得行業數據能夠對白名單企業、機構、高校適當開放,在確保數據安全使用的同時,增強工業軟件領域大模型研究實力。三是鼓勵優先采用安全可信的軟件、工具、計算和數據資源,通過改進算法等技術手段,確保訓練數據的安全性、規范性與合法性。
4)積極推動工業軟件自主創新生態建設。一是依托北京市工業軟件產業創新中心等載體,匯聚國內工業軟件企業、大模型開發企業、高等院校和研究機構等力量, 在技術創新、場景應用、產業發展等方面深化交流合作, 推動基于大模型的工業軟件開發應用。二是加強復合型人才培養,鼓勵國內科研院所、高校和企業開展合作, 建立“產、學、研、用”綜合實踐應用平臺、人才實訓基地等,培養一批高端型工業軟件人才。三是聚焦重點行業工業軟件替代需求清單和關鍵共性技術需求清單, 開展供需對接,圍繞石化、船舶、航空等重點行業,打通技術、場景和人才壁壘,打造一批基于大模型的工業軟件示范應用,共同推動人工智能技術與產業的快速發展,助力工業經濟高質量發展。
06
結束語
搶抓新一代信息技術,推動我國工業軟件自主創新, 是解決工業軟件“卡脖子”問題的重要路徑。生成式人工智能在提升工業軟件研發設計、生產維護等效率方面取得一定的進展,但與工業機理的深度融合仍然存在難點。建議布局基于大模型的工業軟件技術和應用體系, 持續推進技術創新、場景應用、產業發展等,共同推動人工智能技術與產業的快速發展,為搶抓新一輪科技革命和產業變革機遇、實現工業經濟高質量發展作出更大貢獻。
審核編輯:劉清
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238247 -
ai技術
+關注
關注
1文章
1266瀏覽量
24285 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595 -
大模型
+關注
關注
2文章
2423瀏覽量
2640 -
生成式AI
+關注
關注
0文章
502瀏覽量
471
原文標題:基于生成式人工智能的工業軟件自主創新路徑探索
文章出處:【微信號:CADCAM_beijing,微信公眾號:智能制造IMS】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論