


引言
檢索增強生成(Retrieval Augmented Generation,簡稱RAG)為大型語言模型(LLMs)提供了從某些數據源檢索到的信息,以此作為生成答案的基礎。簡而言之,RAG是搜索+LLM提示的結合,即在有搜索算法找到的信息作為上下文的情況下,讓模型回答提出的查詢。查詢和檢索到的上下文都被注入到發送給LLM的提示中。
目前,RAG是基于LLM系統中最受歡迎的架構。許多產品幾乎完全基于RAG構建,包括將網絡搜索引擎與LLMs相結合的問答服務,以及數百種與數據聊天的應用程序。
即使是向量搜索領域也因這種熱潮而興起,盡管基于嵌入的搜索引擎自2019年就已使用faiss開發。像chroma、weavaite.io和pinecone這樣的向量數據庫初創公司建立在現有的開源搜索索引之上--主要是faiss和nmslib,并且最近增加了對輸入文本的額外存儲和一些其他工具。
有兩個最突出的開源庫用于基于LLM的管道和應用程序——LangChain和LlamaIndex,它們分別于2022年10月和11月成立,并在2023年獲得了大量的應用。
本文的目的是系統化地介紹高級RAG技術的關鍵點,并參考它們在LlamaIndex中的實現——以便幫助其他開發者深入了解這項技術。
如果您已經熟悉RAG概念,請直接跳到高級RAG部分。
基礎的RAG技術
本文中,我們用一組文本文檔的語料庫來代表RAG的起點——我們跳過了在此之前的步驟,留給那些開源數據加載器去處理,這些加載器可以連接到任何可想象的來源,從YouTube到Notion。
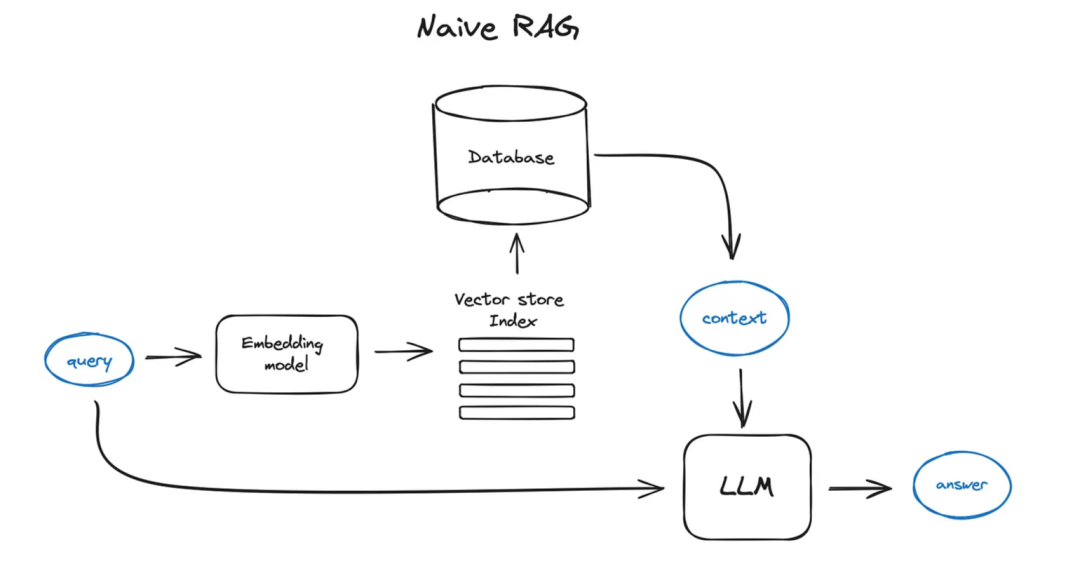
簡單RAG案例大致如下:
將文本分割成塊,然后使用基于Transformer decoder的模型將這些塊嵌入到向量中,將所有這些向量放入一個索引中,最后為LLM創建一個提示,告訴模型在我們在搜索步驟中找到的上下文中回答用戶的查詢。
在運行時,我們使用相同的編碼器模型將用戶的查詢向量化,然后對索引執行這個查詢向量的搜索,找到前k個結果,從我們的數據庫中檢索相應的文本塊,并將它們作為上下文輸入到LLM的提示中。
提示可能看起來是這樣的:
defquestion_answering(context,query): prompt=f""" Givetheanswertotheuserquerydelimitedbytriplebackticks```{query}``` usingtheinformationgivenincontextdelimitedbytriplebackticks```{context}```. Ifthereisnorelevantinformationintheprovidedcontext,trytoansweryourself, buttelluserthatyoudidnothaveanyrelevantcontexttobaseyouransweron. Beconciseandoutputtheanswerofsizelessthan80tokens. """ response=get_completion(instruction,prompt,model="gpt-3.5-turbo") answer=response.choices[0].message["content"] returnanswer
提示工程是提升RAG管道性能最經濟的嘗試之一。確保您已經查看了OpenAI提供的提示工程指南[2]。
盡管OpenAI作為LLM領域領導公司,但還有一些替代品,如Anthropic的Claude,最近流行的小型但非常強大的模型,如Mistral的Mixtral,Microsoft的Phi-2,以及許多開源選項,如Llama2、OpenLLaMA、Falcon等,所以您可以為您的RAG管道選擇一個“大腦”。
高級RAG技術
現在我們將深入了解高級RAG技術的概述。下面是一個展示核心步驟的示意圖。為了保持圖表的可讀性,省略了一些邏輯循環和復雜的多步驟代理行為。
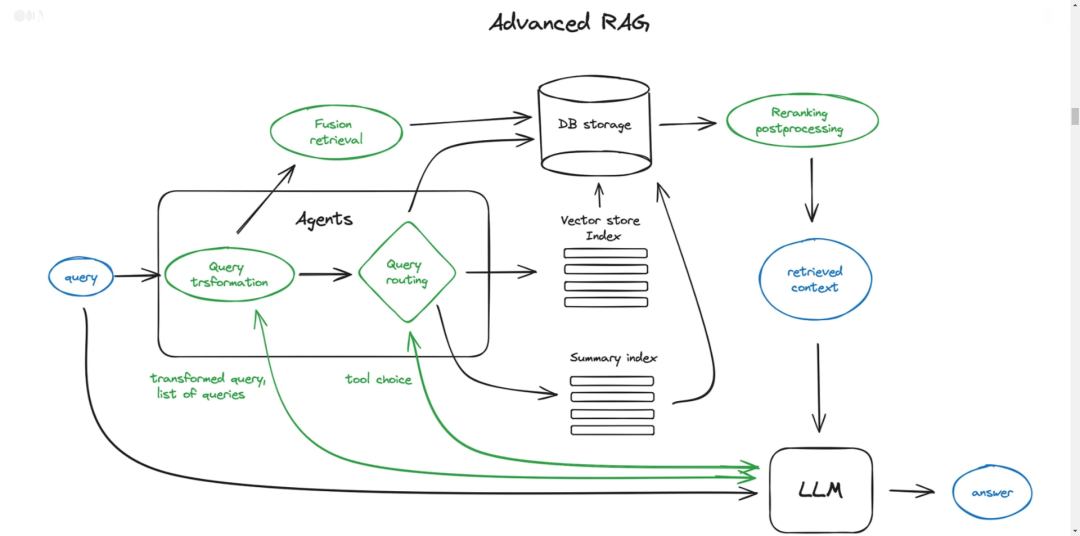
圖中的綠色元素是接下來討論的核心RAG技術,藍色元素代表文本。并非所有高級RAG理念都能輕易在單一圖表上可視化,例如,省略了各種擴大上下文的方法——我們將在后面深入探討這些。
切分和向量化
首先,我們想創建一個向量索引,代表我們文檔的內容,然后在運行時搜索這些向量與查詢向量之間最小的余弦距離,對應于最接近的語義含義。
切分:Transformer模型有固定的輸入序列長度,即使輸入上下文窗口很大,一個句子或幾個句子的向量也比幾頁文本的平均向量更好地代表它們的語義含義(也取決于模型,但通常如此),所以要切分你的數據——將初始文檔切分為某個大小的塊,不會丟失它們的含義(將文本切分為句子或段落,而不是將單個句子切成兩部分)。有各種文本分割器實現能夠完成這項任務。
塊的大小是一個需要考慮的參數——它取決于你使用的嵌入模型及其在令牌上的容量,標準的Transformer編碼器模型如基于BERT的句子轉換器最多接受512個令牌,OpenAI ada-002能夠處理更長的序列,如8191個令牌,但這里的折中是為LLM提供足夠的上下文進行推理與執行搜索的足夠具體的文本嵌入。最近的一項研究[3]說明了塊大小選擇的考慮因素。在LlamaIndex中,這是通過NodeParser類來覆蓋的,它提供了一些高級選項,如定義自己的文本分割器、元數據、節點/塊關系等。
向量化:下一步是選擇一個模型來嵌入切割后的塊——有很多選擇,例如像bge-large或E5嵌入系列這樣的搜索優化模型——只需查看MTEB排行榜上[4]的最新更新。
要了解切分和向量化步驟的端到端實現,請查看LlamaIndex中的一個完整的示例。
搜索索引
向量存儲索引:RAG管道的關鍵部分是搜索索引,它存儲了我們在上一步中獲得的向量化內容。最簡單的實現使用平面索引——在查詢向量和所有塊向量之間進行暴力距離計算。
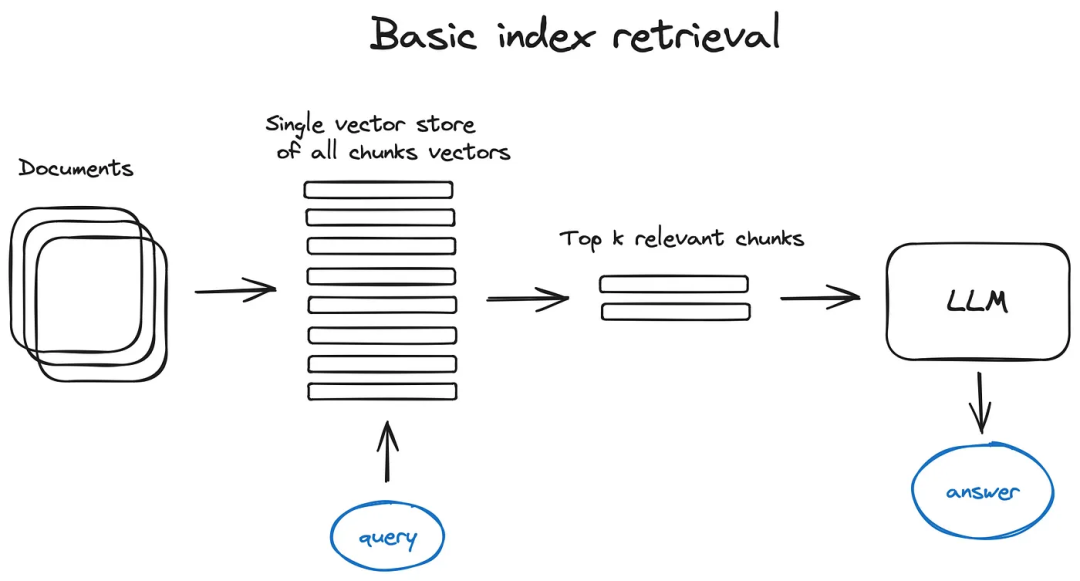
一個為10000+元素規模上的高效檢索優化的索引是一個向量索引,如faiss、nmslib或annoy,使用某種近似最近鄰實現,如聚類、樹或HNSW算法。
還有一些托管解決方案,如OpenSearch或ElasticSearch,以及向量數據庫,它們在后臺處理第1步中描述的數據攝取管道,如Pinecone、Weaviate或Chroma。根據選擇的索引、數據和搜索需求,可以將元數據與向量一起存儲,然后使用元數據過濾器來搜索某些日期或來源內的信息。
LlamaIndex支持許多向量存儲索引,但還支持其他更簡單的索引實現,如列表索引、樹索引和關鍵詞表索引——我們將在融合檢索部分討論后者。
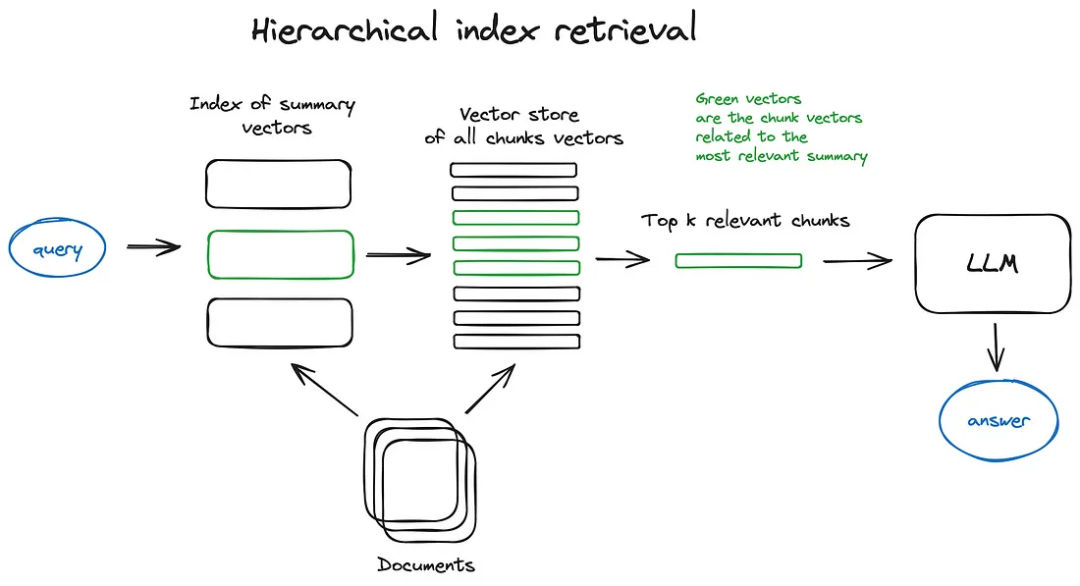
分層索引: 如果您需要從許多文檔中檢索信息,您需要能夠有效地在其中搜索,找到相關信息,并將其綜合為帶有來源引用的單一答案。在大型數據庫中做到這一點的有效方法是創建兩個索引——一個由摘要組成,另一個由文檔塊組成,并分兩步進行搜索,首先通過摘要篩選出相關文檔,然后僅在這個相關組內搜索。
假設性問題和HyDE:另一種方法是讓LLM為每個塊生成一個問題,并將這些問題嵌入向量中,在運行時針對這個問題向量索引進行查詢搜索(在我們的索引中用問題向量替換塊向量),然后在檢索后路由到原始文本塊,并將它們作為上下文發送給LLM以獲得答案。這種方法通過查詢與假設性問題之間更高的語義相似性,提高了搜索質量。
還有一種逆向邏輯方法稱為HyDE——讓LLM給定查詢生成一個假設性回應,然后使用其向量和查詢向量來提高搜索質量。
上下文豐富化:上下文豐富化是檢索更小的塊以提高搜索質量,但添加周圍上下文讓LLM進行推理。通常有兩種做法——通過在檢索到的較小塊周圍的句子擴展上下文,或者將文檔遞歸地分割成包含較小子塊的多個較大的父塊。
句子窗口檢索: 在這個方案中,文檔中的每個句子都分別嵌入,這提供了極高的查詢與上下文余弦距離搜索的準確性。為了在找到最相關的單個句子后更好地推理所發現的上下文,我們通過在檢索到的句子前后擴展k個句子的上下文窗口,然后將這個擴展的上下文發送給LLM。

自動合并檢索器(又稱父文檔檢索器):這里的想法與句子窗口檢索非常相似——搜索更精細的信息片段,然后在將這些上下文提供給LLM進行推理之前擴展上下文窗口。文檔被分割成較小的子塊,這些子塊引用較大的父塊。
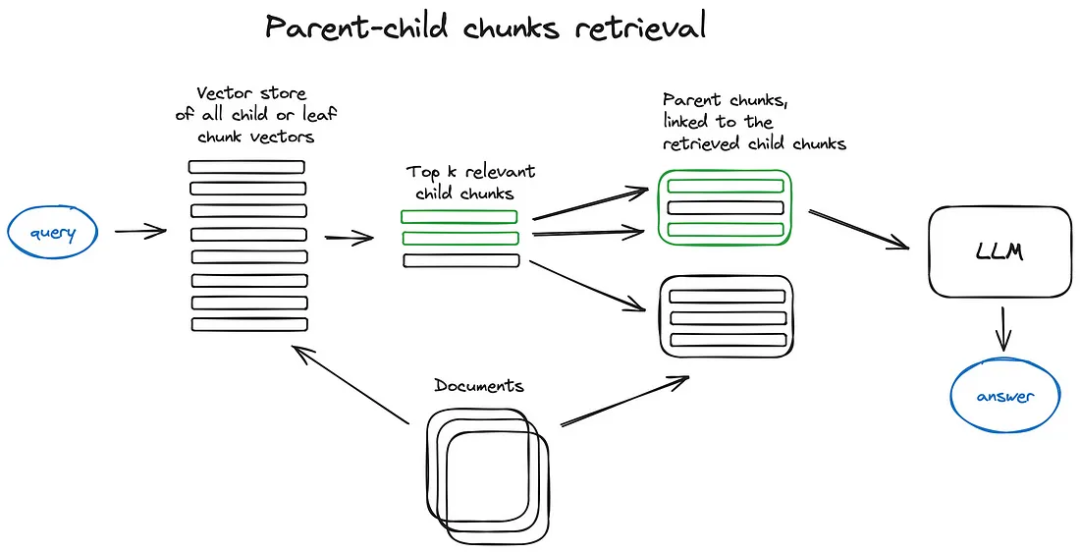
在這種方法中,首先在更細粒度的子塊上進行搜索,找到與查詢最相關的塊。然后,系統會自動將這些子塊與它們所屬的更大的父塊結合起來。這樣做的目的是在回答查詢時為LLM提供更豐富的上下文。例如,如果一個子塊是一段或一小節,父塊可能是整個章節或文檔的一大部分。這種方法既保留了檢索精度(因為是在更小的塊上搜索),同時也通過提供更廣泛的上下文來增強LLM的推理能力。
在檢索過程中首先獲取較小的塊,然后如果在檢索到的前k個塊中有超過n個塊與同一個父節點(較大的塊)相關聯,我們就用這個父節點替換提供給LLM的上下文——這就像自動將幾個檢索到的塊合并成一個較大的父塊,因此得名。需要注意的是——搜索僅在子節點索引中進行。想要更深入地了解,請查看LlamaIndex關于遞歸檢索器+節點引用的教程[5]。
融合檢索或混合搜索:這是一個相對較老的想法,即從兩個世界中各取所長——基于關鍵字的傳統搜索(稀疏檢索算法,如tf-idf或搜索行業標準BM25)和現代語義或向量搜索,并將它們結合在一個檢索結果中。這里唯一的技巧是正確組合具有不同相似性得分的檢索結果——這個問題通常通過使用倒數排名融合算法來解決,重新排列檢索結果以獲得最終輸出。
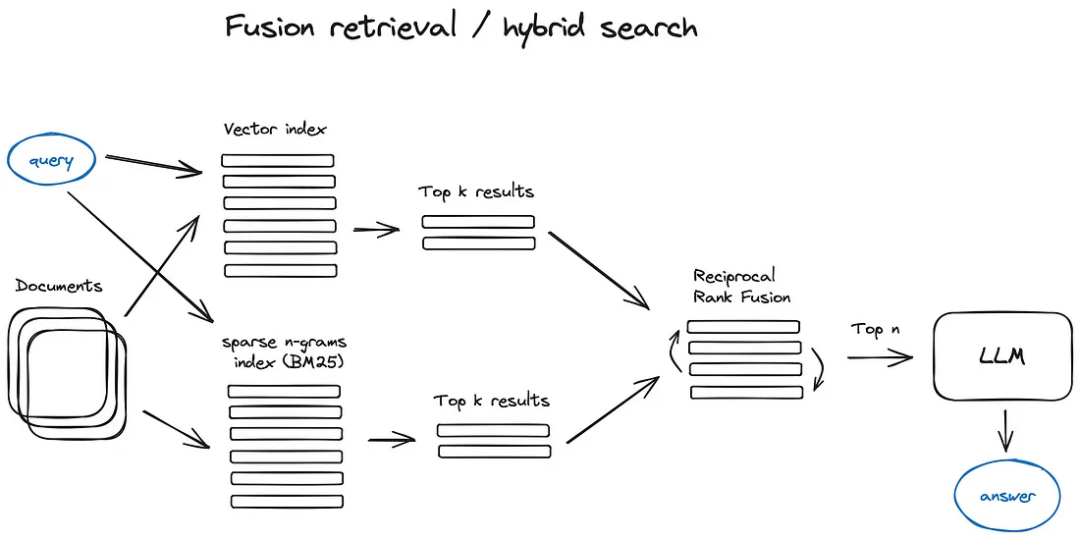
在LangChain[6]中,這是通過Ensemble Retriever類實現的,它結合了你定義的一系列檢索器,例如faiss向量索引和基于BM25的檢索器,并使用RRF進行重排。在LlamaIndex[7]中這種做法也非常類似。
混合或融合搜索通常會提供更好的檢索結果,因為它結合了兩種互補的搜索算法,同時考慮了查詢和存儲文檔之間的語義相似性和關鍵詞匹配。
重排和過濾
使用上述任何算法得到檢索結果后,現在是時候通過過濾、重排或一些轉換來精煉這些結果了。在LlamaIndex中,有多種可用的后處理器,可以根據相似性分數、關鍵詞、元數據過濾結果,或者使用其他模型進行重排,比如LLM、句子轉換器交叉編碼器、Cohere重排端點,或者基于日期的最新性等元數據——基本上,你能想到的都可以。
重排和過濾是在將檢索到的上下文提供給LLM以獲取最終答案之前的最后一步。現在是時候進入更復雜的RAG技術,如查詢轉換和路由,這兩者都涉及到LLM,因此代表了主動性行為——在我們的RAG流程中涉及到一些復雜的邏輯,包括LLM的推理。
查詢轉換
查詢轉換是一系列技術,利用LLM作為推理引擎來修改用戶輸入,以提高檢索質量。
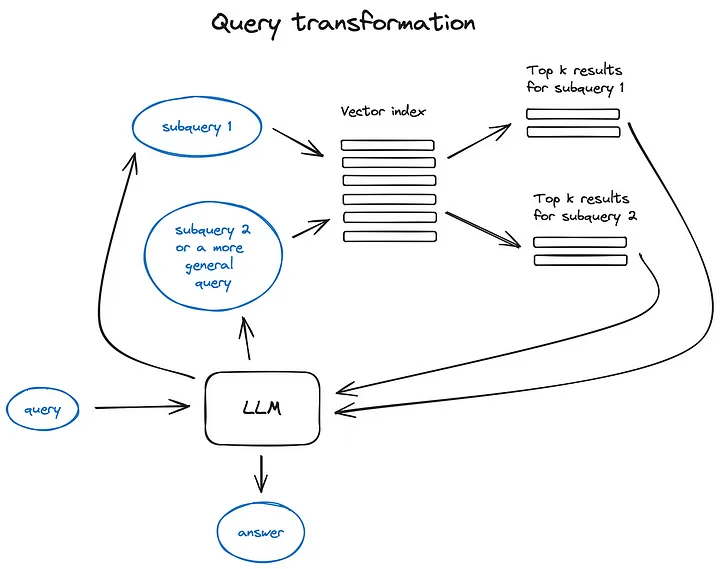
有幾種不同的方式可以做到這一點。如果查詢很復雜,LLM可以將其分解成幾個子查詢。例如,如果你問:
“在Github上,Langchain和LlamaIndex哪個框架的星星更多?”由于我們不太可能在語料庫中找到直接的比較,所以將這個問題分解成兩個預設簡單和具體信息檢索的子查詢是有意義的:
“Langchain在Github上有多少星星?”
“LlamaIndex在Github上有多少星星?”這兩個查詢將并行執行,然后將檢索到的上下文合并成一個提示,供LLM合成最初查詢的最終答案。Langchain和LlamaIndex都實現了這一功能——在Langchain中作為多查詢檢索器,在LlamaIndex中作為子問題查詢引擎。
回溯提示使用LLM生成更一般的查詢,我們為此檢索獲得更一般或高層次的上下文,有助于支撐我們對原始查詢的回答。也會對原始查詢進行檢索,兩種上下文都在最終生成答案的步驟中輸入給LLM。這是LangChain的實現方法。
查詢重寫使用LLM重構初始查詢以改善檢索。LangChain和LlamaIndex都有實現,雖然有些不同,但我認為在這里LlamaIndex的解決方案更為強大。
此外, 還有一個概念是參考引用。這一部分不作為單獨的一章來介紹,因為它更像是一種工具而不是檢索改進技術,盡管它非常重要。如果我們為了回答一個問題而使用了多個來源,可能是因為初始查詢的復雜性(我們需要執行多個子查詢,然后將檢索到的上下文合并成一個答案),或者是因為我們在不同的文檔中找到了與單個查詢相關的上下文,那么就會出現一個問題:我們能否準確地回溯引用我們的來源。
有幾種方法可以做到這一點:
將引用任務插入我們的提示中,并要求LLM提及使用的來源的ID。
將生成的響應部分與我們索引中的原始文本塊匹配——llamaindex為這種情況提供了一個基于模糊匹配的高效解決方案。如果你還沒有聽說過模糊匹配,這是一種非常強大的字符串匹配技術。
聊天引擎
在構建一個能夠針對單個查詢多次運行的優秀RAG系統中,下一個重要的環節是聊天邏輯,這與前LLM時代的經典聊天機器人一樣,需要考慮對話上下文。這對于支持后續問題、指代消解或與先前對話上下文相關的任意用戶命令是必要的。這可以通過查詢壓縮技術來解決,同時考慮聊天上下文和用戶查詢。
如同往常,有幾種處理上述上下文壓縮的方法 —一種流行且相對簡單的方法是ContextChatEngine,它首先檢索與用戶查詢相關的上下文,然后將其連同聊天歷史記錄從內存緩沖區發送給LLM,以便LLM在生成下一個回答時能夠了解之前的上下文。
更復雜的一個例子是CondensePlusContextMode — 在這種模式中,每次交互時都會將聊天歷史和最后一條消息壓縮成一個新的查詢,然后這個查詢會進入索引,檢索到的上下文連同原始用戶消息一起傳遞給LLM,以生成答案。
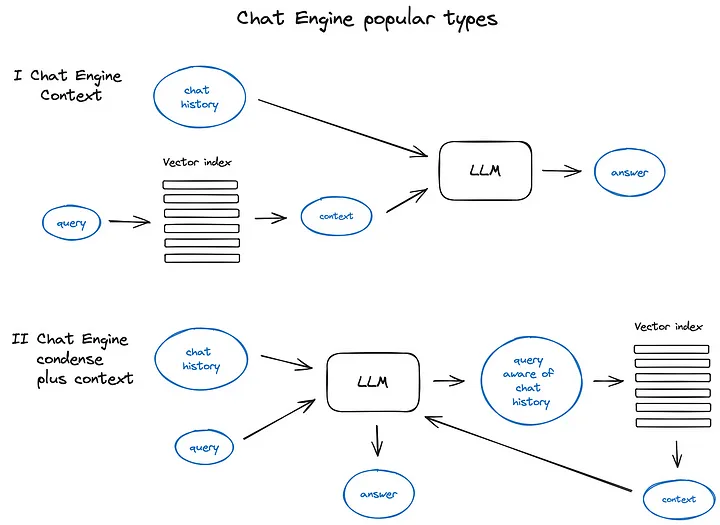
值得注意的是,LlamaIndex還支持基于OpenAI代理的聊天引擎,提供更靈活的聊天模式,Langchain也支持OpenAI功能性API。還有其他類型的聊天引擎,如ReAct Agent,但我們在后面再討論代理本身。
查詢路由
查詢路由是一個以LLM為驅動的決策步驟,決定針對用戶查詢接下來要做什么——通常的選項包括概括總結、針對某些數據索引執行搜索,或嘗試多種不同的路徑,然后將它們的輸出合成一個答案。
查詢路由器還用于選擇索引,或更廣泛地說,數據存儲位置,以發送用戶查詢——無論你擁有多個數據來源,例如經典的向量存儲、圖形數據庫或關系型數據庫,還是擁有一個索引層次結構——對于多文檔存儲,一個相當典型的情況可能是一個概要索引和另一個文檔塊向量的索引。
定義查詢路由器包括設置它可以做出的選擇。路由選項的選擇是通過LLM調用進行的,返回預定義格式的結果,用于將查詢路由到給定的索引,或者,如果我們談論主動性行為,路由到子鏈或甚至其他代理,如下面的多文檔代理方案所示。
LlamaIndex和LangChain都支持查詢路由器。
RAG中的代理
Langchain和LlamaIndex都支持的代理(Agents),自從第一個LLM API發布以來就已經存在——這個想法是為一個能夠進行推理的LLM提供一套工具和一個要完成的任務。這些工具可能包括一些確定性函數,如任何代碼函數、外部API甚至其他代理——LLM鏈式調用的這個想法是LangChain名字的由來。
代理本身是一個巨大的領域,要在RAG概覽中深入探討是不可能的,所以我將繼續討論基于代理的多文檔檢索案例,并在OpenAI助手這個相對較新的領域短暫停留,因為它是最近OpenAI開發者大會上作為GPTs介紹的,并在下面描述的RAG系統的底層工作。
OpenAI助手基本上實現了圍繞LLM所需的許多工具,我們之前在開源中擁有這些工具——聊天歷史記錄、知識存儲、文檔上傳界面,以及或許最重要的,函數調用API。后者提供了將自然語言轉換為對外部工具或數據庫查詢的API調用的能力。
在LlamaIndex中,OpenAIAgent類將這種高級邏輯與ChatEngine和QueryEngine類結合起來,提供基于知識和上下文的聊天,以及在一次對話中調用多個OpenAI函數的能力,這確實帶來了智能的代理行為。
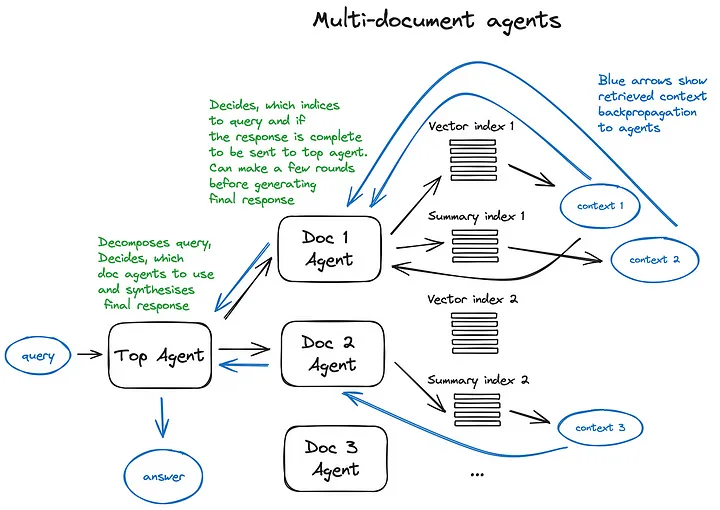
讓我們來看一下多文檔代理方案——一個相當復雜的設置,涉及對每個文檔初始化一個代理(OpenAIAgent),能夠進行文檔概要和經典的問答機制,并有一個頂級代理,負責將查詢路由到文檔代理,并進行最終答案的合成。
每個文檔代理都有兩個工具——一個向量存儲索引和一個概要索引,并根據路由查詢決定使用哪一個。而對于頂級代理來說,所有文檔代理都分別是工具。
這個方案展示了一個高級的RAG架構,其中每個參與的代理都做出了許多路由決策。這種方法的好處是能夠比較不同的解決方案或實體,這些解決方案或實體描述在不同的文檔及其概要中,同時包括經典的單文檔概要和問答機制——這基本上涵蓋了最常見的與文檔集合聊天的用例。這種復雜方案的缺點可以從圖中猜測——由于涉及代理中LLM的多次來回迭代,它有些慢。順便說一下,LLM調用總是RAG流程中最長的操作——搜索本身就是為速度優化的設計。所以對于大型多文檔存儲,我建議考慮對這個方案進行一些簡化,使其可擴展。
響應合成器
這是任何RAG流程的最后一步——基于我們仔細檢索的所有上下文和初始用戶查詢生成答案。最簡單的方法可能是將所有獲取到的上下文(超過某個相關性閾值的)連同查詢一起一次性輸入給LLM。但是,像往常一樣,還有其他更復雜的選項,涉及多次LLM調用以優化檢索到的上下文并生成更好的答案。
響應合成的主要方法包括:
通過逐塊將檢索到的上下文發送給LLM來迭代地完善答案。
概括檢索到的上下文以適應提示。
基于不同的上下文塊生成多個答案,然后將它們連接或概括起來。有關更多細節,請查閱響應合成器模塊文檔[8]。
編碼器和LLM微調
這種方法涉及對RAG流程中的兩個深度學習模型之一進行微調——要么是負責嵌入質量和上下文檢索質量的Transformer編碼器,要么是負責最佳利用提供的上下文來回答用戶查詢的LLM,幸運的是,后者是一個很好的少量樣本學習器。
如今一個很大的優勢是能夠使用像GPT-4這樣的高端LLM來生成高質量的合成數據集。但使用由專業研究團隊在精心收集、清洗和驗證的大型數據集上訓練的開源模型,并使用小型合成數據集進行快速調整,可能會降低模型的整體能力。
編碼器微調:我對編碼器微調方法也有些懷疑,因為最新的為搜索優化的Transformer編碼器相當高效。所以我在LlamaIndex筆記本設置中測試了對bge-large-en-v1.5(在撰寫本文時為MTEB排行榜前4)進行微調的性能提升,結果顯示檢索質量提高了2%。雖然不是很驚人,但了解這個選項還是不錯的,尤其是如果你有一個你正在為之構建RAG的狹窄領域數據集。
排名器微調:另一個老方法是,如果你不完全信任你的基礎編碼器,就使用交叉編碼器對檢索結果進行重排。其工作方式如下——你將查詢和前k個檢索到的文本塊傳遞給交叉編碼器,以SEP令牌分隔,并對其進行微調,以輸出1表示相關塊,0表示不相關。這里有一個這種調整過程的例子[9],結果顯示交叉編碼器微調提高了4%的成對分數。
LLM微調:最近OpenAI開始提供LLM微調API,LlamaIndex有關于在RAG設置中微調GPT-3.5-turbo的教程[10],以“提煉”一些GPT-4的知識。這里的想法是拿一個文檔,用GPT-3.5-turbo生成一些問題,然后使用GPT-4根據文檔內容生成這些問題的答案(構建一個由GPT4驅動的RAG流程),然后對GPT-3.5-turbo進行微調,使其在問題-答案對的數據集上進行訓練。用于RAG流程評估的ragas框架顯示,忠實度指標提高了5%,意味著微調后的GPT 3.5-turbo模型比原始模型更好地利用了提供的上下文來生成其答案。
一種更復雜的方法在最近的RA-DIT論文[11]中展示:由Meta AI研究提出的檢索增強雙指導調整技術,建議對LLM和檢索器(原論文中的雙編碼器)進行調整,針對查詢、上下文和答案的三元組。有關實現細節,請參考這個指南[12]。這種技術用于通過微調API對OpenAI LLM進行微調,以及對Llama2開源模型進行微調(在原論文中),結果顯示在知識密集型任務指標上提高了約5%(與Llama2 65B with RAG相比),以及在常識推理任務上提高了幾個百分點。
評估
RAG系統性能評估有幾個框架,它們共享一個理念,即擁有幾個獨立的指標,如整體答案相關性、答案的根據性、忠實度和檢索到的上下文相關性。
前一節提到的Ragas使用忠實度和答案相關性作為生成答案質量的指標,以及經典的上下文精確度和召回率用于RAG方案的檢索部分。
在Andrew NG最近發布的精彩短課程《構建和評估高級RAG》中,LlamaIndex和評估框架Truelens建議使用RAG三元組——檢索到的上下文與查詢的相關性、根據性(LLM答案受提供的上下文支持的程度)以及答案與查詢的相關性。
最關鍵且最可控的指標是檢索到的上下文相關性——基本上上面描述的高級RAG流程的第1-7部分以及編碼器和排名器微調部分旨在改善這一指標,而第8部分和LLM微調則專注于答案相關性和根據性。
一個相當簡單的檢索器評估流程的例子可以在這里[13]找到,并且已應用于編碼器微調部分。一種更高級的方法不僅考慮命中率,還考慮了平均倒數排名(一個常見的搜索引擎指標)以及生成答案的指標,如忠實度和相關性,這在OpenAI cookbook[14]中有所展示。
LangChain有一個相當先進的評估框架LangSmith[15],可以實現自定義評估器,它還監控RAG流程中的運行軌跡,以使你的系統更透明。
如果你在使用LlamaIndex構建,那么有一個rag_evaluator llama包[16],提供了一個快速工具,用公共數據集評估你的流程。
結論
我試圖概述RAG的核心算法方法,并且用一些示例來說明它們,希望這能激發一些在你的RAG流程中嘗試的新想法,或者為今年發明的眾多技術帶來一些系統化——對我來說,2023年到目前為止是ML領域最激動人心的一年。
還有許多其他需要考慮的事情,如基于網絡搜索的RAG(LlamaIndex的RAGs、webLangChain等),更深入地探討主動架構(以及最近OpenAI在這個游戲中的份額)以及一些關于LLM長期記憶的想法。
RAG系統的主要生產挑戰除了答案相關性和忠實度之外,還有速度,尤其是如果你傾向于更靈活的基于代理的方案。ChatGPT和大多數其他助手使用的這種流媒體功能不是隨機的賽博朋克風格,而只是一種縮短感知答案生成時間的方式。這就是為什么我看到小型LLM和最近的Mixtral和Phi-2發布在這個方向上有一個非常光明的未來。
審核編輯:黃飛
-
編碼器
+關注
關注
45文章
3830瀏覽量
138594 -
大模型
+關注
關注
2文章
3212瀏覽量
4202 -
LLM
+關注
關注
1文章
328瀏覽量
915
原文標題:精彩手繪全解:RAG技術,從入門到精通
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄







 工商網監
工商網監

評論