 如何配置單臺服務器
如何配置單臺服務器
1、單服務器配置
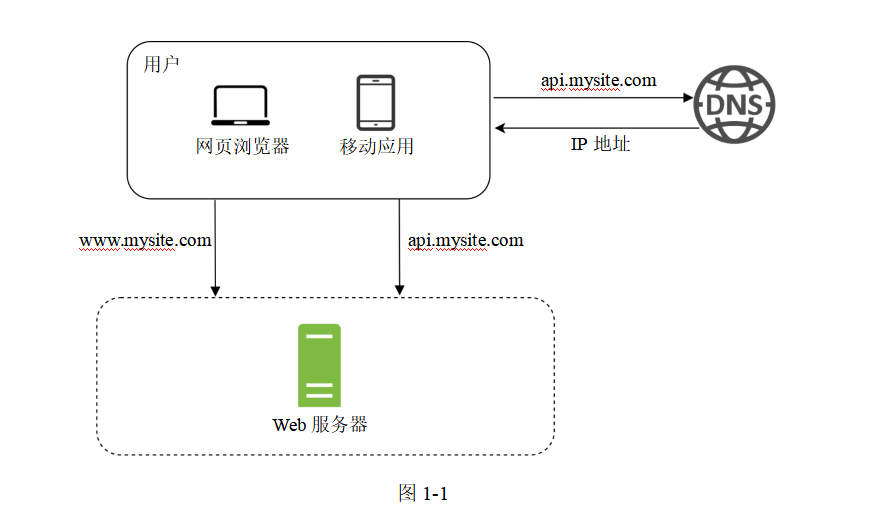
萬里征途總是從第一步開始的,構建一個復雜系統也是如此。我們從簡單的部分著手,先讓所有的功能都在一個服務器上運行。圖1-1展示了如何配置單臺服務器,讓一切都在其上運行,包括Web應用、數據庫、緩存等。
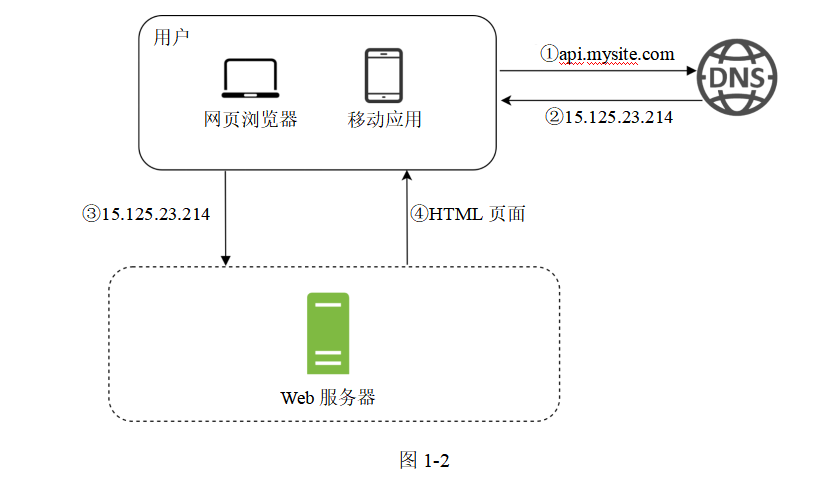
研究請求流和流量源頭有助于我們理解這個配置。我們先來看請求流(如圖1-2所示)。
圖片
圖片
1.用戶通過輸入域名(例如api.mysite.com)來訪問網站。通常,域名系統(DNS)是由第三方提供的付費服務,它并不是由我們的服務器來托管的。
2.IP地址被返回給網頁瀏覽器或者移動應用。在圖1-2所示的例子中,被返回的IP地址是15.125.23.214。
3.一旦獲知IP地址,HTTP請求就被直接發送給Web服務器。
4.Web服務器返回HTML頁面或者JSON響應來渲染頁面。
接下來,我們研究一下流量源頭。Web服務器的流量有兩個源頭:Web應用和移動應用。
—Web應用:它運用服務器端語言(Java、Python等)來處理業務邏輯、數據存儲等;它還使用客戶端語言(HTML和JavaScript)來展示內容。
—移動應用:HTTP是移動應用與Web服務器之間的通信協議。而JSON(JavaScript Object Notation)因其十分簡單而被廣泛用作數據傳輸時的API響應格式。以下是一個JSON格式的API響應例子。
GET/users/12–獲取id=12的用戶對象 { "id":12, "firstName'":"John", "lastName":"Smith", "address":{ "streetAddress":"212ndStreet", "city":"NewYork", "state'":"NY", "postalCode":10021 }, "phoneNumbers":[ "212555-1234", "646555-4567" ] }
2、數據庫
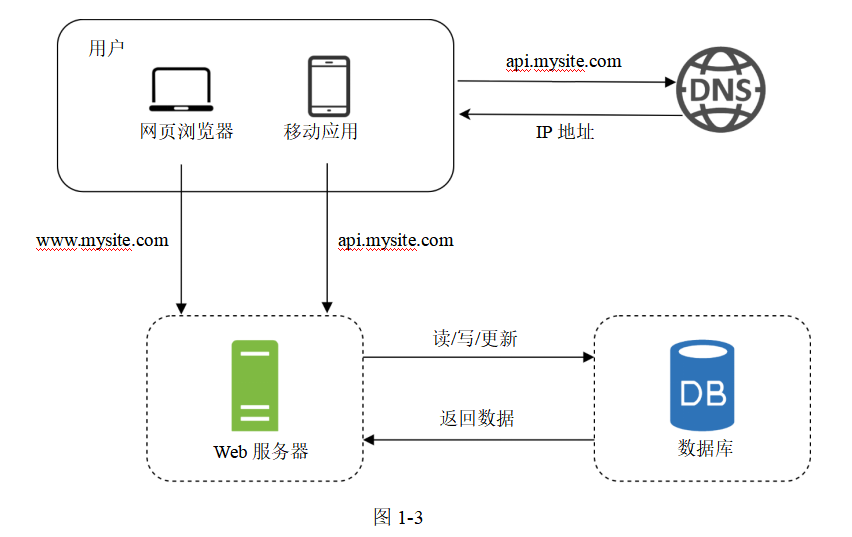
隨著用戶基數的增長,一臺服務器已經無法滿足需求,我們需要多臺服務器:一臺用于處理Web應用/移動應用的流量,另一臺用作數據庫(如圖1-3所示)。把處理Web應用/移動應用流量(網絡層)的服務器與數據庫(數據層)服務器分開,我們就可以對它們分別進行擴展。
圖片
使用何種數據庫
你可以選擇傳統的關系型數據庫,也可以選擇非關系型數據庫。我們來看看它們的區別。
關系型數據庫通常也叫作關系型數據庫管理系統(RDBMS)或者SQL數據庫,其中最流行的有MySQL、Oracle、PostgreSQL等。關系型數據庫通過表和行來表示和存儲數據。你可以使用SQL對不同的數據庫表執行連接(join)操作。
非關系型數據庫又叫作NoSQL數據庫。流行的非關系型數據庫有CouchDB、Neo4j、Cassandra、HBase、Amazon DynamoDB等。它們可以分為四類:鍵值存儲、圖存儲、列存儲和文檔存儲。非關系型數據庫一般不支持連接操作。
對于大多數開發者而言,關系型數據庫是最好的選擇,因為它們已經有40多年的歷史,而且一直表現不錯。但如果它們無法滿足你的特殊使用場景要求,你就需要考慮關系型數據庫之外的選項。當需要滿足如下條件時,非關系型數據庫可能是一個正確的選擇:
—你的應用只能接受非常低的延時。
—應用中的數據是非結構化的,或者根本沒有任何關系型數據。
—只需要序列化(JSON、XML、YAML等格式)和反序列化數據。
—需要存儲海量數據。
3、縱向擴展 vs. 橫向擴展
縱向擴展也叫作向上擴展,指的是提升服務器的能力(CPU、RAM等)。橫向擴展也叫作向外擴展,指的是為你的資源池添加更多服務器。
當流量小的時候,縱向擴展是一個很好的選擇,其主要優勢是簡單。不過,它有一些重大局限。
—縱向擴展是有硬性限制的,你不可能給一臺服務器無限添加CPU和內存。
—縱向擴展沒有故障轉移和冗余。一旦一臺服務器宕機,網站/應用也會隨著一起完全不可用。
由于縱向擴展存在這些限制,因此對于大型應用來說,采用橫向擴展更合適一些。
在我們前面的設計中,用戶是直接連接到Web服務器的。一旦服務器離線,用戶就無法訪問網站了。還有一種場景是,非常多的用戶同時訪問Web服務器,達到了其負載上限,這時用戶就會普遍感受到網站響應慢或者無法連上服務器。解決這些問題的最佳方法是使用負載均衡器。
4、負載均衡器
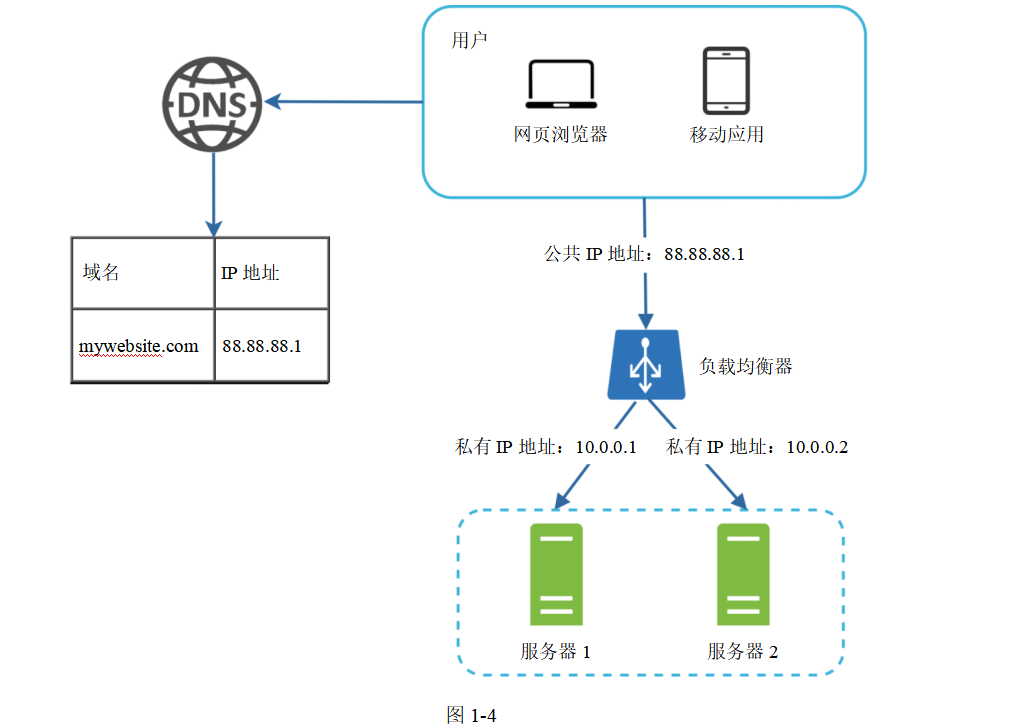
負載均衡器會把輸入流量均勻分配到負載均衡集里的各個Web服務器上。圖1-4展示了負載均衡器是怎么工作的。
如圖1-4所示,用戶可以直接連接該負載均衡器的公共IP地址。這樣設置后,Web服務器就再也不能被任何客戶端直接訪問了。為了提高安全性,服務器之間的通信使用私有IP地址。私有IP地址只可以被同一個網絡中的服務器訪問,在公網中是無法訪問的。負載均衡器和Web服務器之間使用私有IP地址來通信。
增加了負載均衡器和一臺Web服務器后,我們成功解決了網絡層的故障轉移問題,提升了網絡層的可用性。具體細節如下:
—如果服務器1離線,所有的流量都會被路由到服務器2,從而避免整個網站宕機。我們可以之后再將一臺新的“健康的”Web服務器添加到服務器池中,以平衡負載。
—如果網站流量增長非常快,兩臺服務器不足以處理這些流量,那么負載均衡器可以輕松地解決這個問題。只需要在服務器池中添加更多服務器,負載均衡器就會自動將請求發給新加入的服務器。
圖片
現在網絡層看來已經不錯了,那么數據層呢?目前的設計方案中只有一個數據庫,所以無法支持數據庫的故障轉移和冗余。數據庫復制是解決這些問題的常用技巧。
5、數據庫復制
根據維基百科上的定義,“在很多數據庫管理系統中,通常都可以利用原始數據庫(Master,主庫)和拷貝數據庫(Slave,從庫)之間的主從關系進行數據庫復制。”。
主庫通常只支持寫操作,從庫保存主庫的數據副本且僅支持讀操作。所有修改數據的指令,如插入、刪除或更新等,都必須發送給主庫來執行。在大部分應用中,對數據庫的讀操作遠多于寫操作,因此系統中從庫的數量通常多于主庫的數量。圖1-5展示了一個主庫搭配多個從庫的例子。
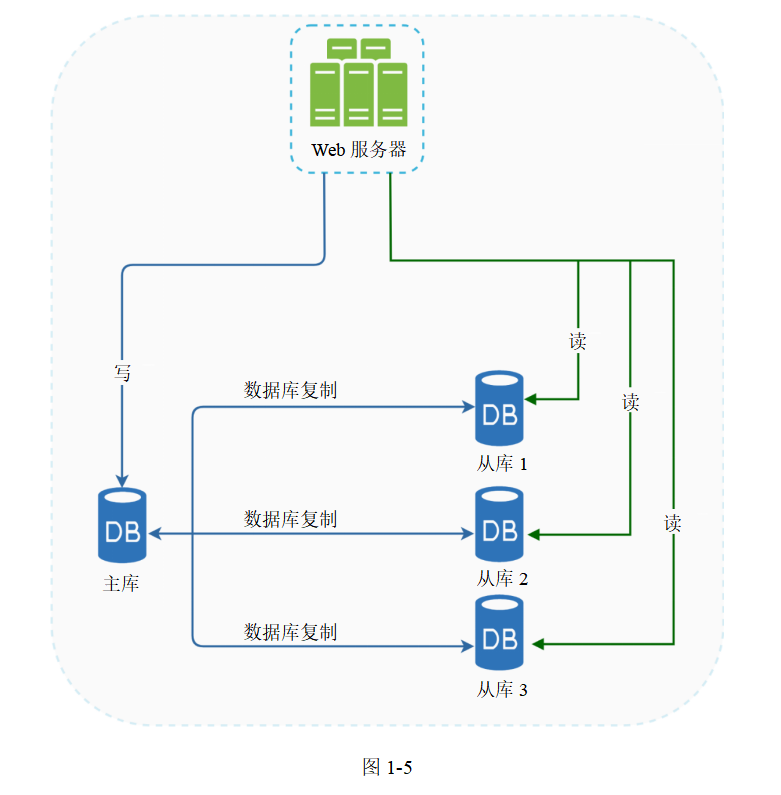
數據庫復制有如下優點:
—性能更好。在主從模式下,所有的寫操作和更新操作都發生在主節點(主庫)上,而讀操作被分配到各個從節點(從庫),因此系統能并行處理更多的查詢,性能得到提升。
—可靠性高。如果有一臺數據庫服務器因自然災害而損毀,比如遭遇臺風或者地震,數據依然被完好保存,你不需要擔心數據會丟失,因為這些數據已經被復制到處于不同地理位置的其他數據庫服務器中。
—可用性高。由于不同物理位置的從庫都復制了數據,因此即使一臺數據庫服務器宕機,你的網站依然可以運行,因為另一臺數據庫服務器里存儲了數據。
前面討論了負載均衡器是如何幫助提升系統可用性的,這里我們問一個同樣的問題:如果有數據庫服務器宕機了怎么辦?圖1-5所示的架構可以應對這種情況。
—如果只有一個從庫,而它宕機了,則系統暫時會將讀操作路由至主庫。一旦發現有從庫宕機,就會有一個新的從庫來替代它。要是有多個從庫可用,讀操作會被重定向到其他正常工作的從庫上;同樣,也會有一個新的數據庫服務器來替代宕機的那個。
—如果主庫宕機,會有一個從庫被推選為新的主庫。所有的數據庫操作會暫時在新的主庫上執行。另一個從庫會替代原來的從庫并立即開始復制數據。在生產環境中,因為從庫的數據不一定是最新的,所以推選一個新的主庫會更麻煩。缺失的數據需要通過運行數據恢復腳本來補全。盡管還有別的數據復制方式可以解決數據缺失問題,比如多主復制或者循環復制,但是它們的設置更加復雜,本書不對這些內容進行討論。感興趣的讀者可以進一步閱讀相關參考資料。
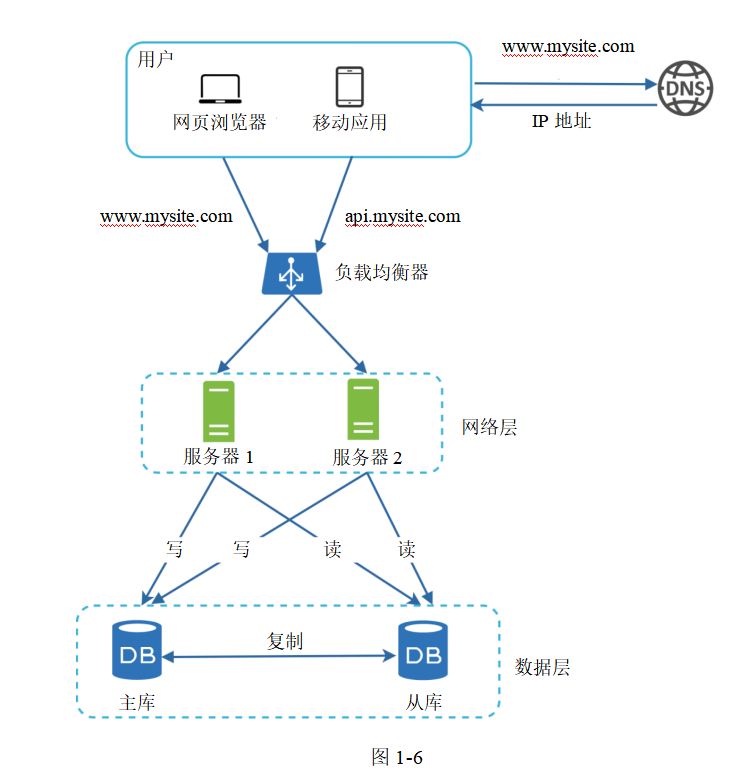
圖1-6展示了添加了負載均衡器和數據庫復制之后的系統設計方案。
圖片
我們再來看一下現在的設計:
—用戶從DNS獲取負載均衡器的IP地址。
—用戶通過這個IP地址連接負載均衡器。
—HTTP請求被轉發到服務器1或者服務器2上。
—Web服務器在從庫中讀取用戶數據。
—Web服務器把所有修改數據的操作請求都轉發到主庫上,包括寫、更新和刪除操作。
現在我們對于網絡層和數據層都有了一定的理解,接下來可以提升加載和響應速度了。可以通過添加緩存層、把靜態資源(JavaScript、CSS、圖片、視頻文件)轉移到內容分發網絡(CDN)上來實現加速。
6、緩存
緩存是臨時的存儲空間,用于存儲一些很耗時的響應結果或者內存中經常被訪問的數據,這樣后續再訪問這些數據時能更快。如圖1-6所示,每次加載一個新網頁,都要執行一個或者多個數據庫請求來獲取數據。不斷向數據庫發送請求會使應用的性能受到很大影響,而緩存可以緩解這種情況。
緩存層
緩存層是一個臨時數據存儲層,比數據庫快很多。設置獨立緩存層的好處有:提高系統性能,減輕數據庫的工作負載以及能夠單獨擴展緩存層。圖1-7展示了一種設置緩存層的方式。

圖片
當收到一個請求時,Web服務器首先檢查緩存中是否有可用的數據:如果有,Web服務器就直接將數據返回給客戶端;如果沒有,就去查詢數據庫并把返回的響應存儲在緩存中,再將其返回給Web服務器。這種緩存策略叫作通過緩存讀(Read-through Cache)。根據數據的類型、大小和訪問模式,可以采用不同的緩存策略。在網站Codeahoy上有一篇文章“Caching Strategies and How to Choose the Right One”,解釋了不同的緩存策略是如何工作的。
大部分緩存服務器都為常見的編程語言提供了API,與其進行交互很簡單。下面的代碼段展示了典型的Memcached API:
SECONDS=1
cache.set('myKey','hithere',3600*SECONDS)
cache.get('myKey')
使用緩存時的注意事項
使用緩存時有以下幾點需要注意:
—決定什么時候應使用緩存。如果對數據的讀操作很頻繁,而修改卻不頻繁,則可考慮使用緩存。因為被緩存的數據是存儲在易變的內存中的,所以緩存服務器不是持久化數據的理想位置。比如,如果緩存服務器重啟,其中的所有數據就會丟失。因此,重要的數據應該保存在持久性的數據存儲中。
—過期策略。執行過期策略是好的做法。一旦緩存中的數據過期,就應該將其從緩存中清除。如果不設置過期策略,緩存中的數據會一直被保存在內存中。通常建議不要把過期時間設得太短,因為這樣會導致系統不得不經常從數據庫重新加載數據;當然,也不要設得太長,這樣會導致數據過時。
—一致性:這關系到數據存儲和緩存的同步。當對數據的修改在數據存儲和緩存中不是通過同一個事務來操作的時候,就會發生不一致。當跨越多個地區進行擴展時,保持數據存儲和緩存之間的一致性是很有挑戰性的。如果你感興趣,可以閱讀Facebook的文章“Scaling Memcache at Facebook”。
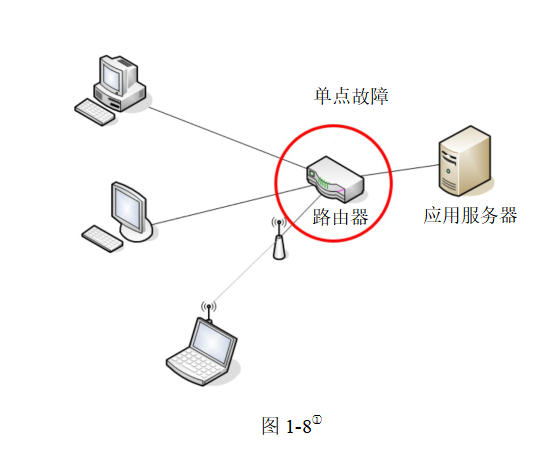
—減輕出錯的影響:單緩存服務器是系統中的一個潛在單點故障(Single Point Of Failure,SPOF)(如圖1-8所示)。在維基百科中,單點故障的定義如下:“單點故障是指系統中的某一部分,如果它出現故障,整個系統就不能工作”。所以,推薦的做法是在不同的數據中心部署多個緩存服務器以避免單點故障。另一個推薦的做法是為緩存超量提供一定比例的內存,這樣可以在內存使用量上升時提供一定的緩沖。
驅逐策略:一旦緩存已滿,任何對緩存添加條目的請求都有可能導致已有條目被刪除,這叫作緩存驅逐。LRU(Least-Recently-Used,最近最少使用)是最流行的緩存驅逐策略。也可以采用其他緩存驅逐策略,比如LFU(Least Frequently Used,最不經常使用)或者FIFO(First In First Out,先進先出),以滿足不同的使用場景。
圖片
7、單服務器配置
內容分發網絡(Content Delivery Network,CDN)是由在地理上分散的服務器組成的網絡,被用來傳輸靜態內容。CDN中的服務器緩存了像圖片、視頻、CSS和JavaScript文件這一類的靜態內容。
動態內容緩存是一個相對新的概念,不在本書討論的范圍內。它可以基于請求路徑、查詢字符串、cookie和請求頭來緩存HTML頁面。感興趣的讀者可以訪問ASW的網站以了解更多內容。本書只講解如何使用CDN緩存靜態內容。
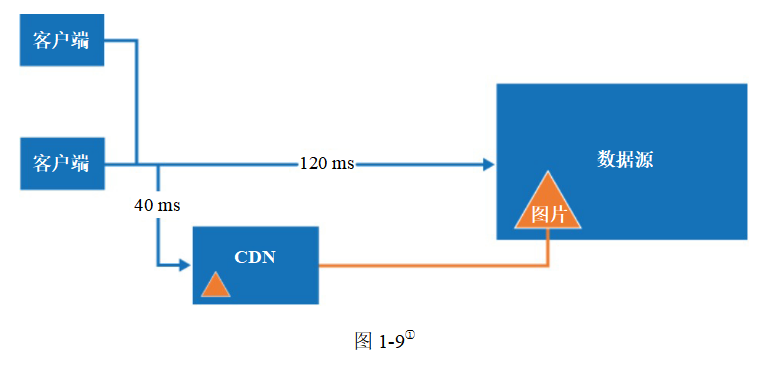
現在我們大致介紹一下CDN是如何工作的:當用戶訪問一個網站時,離用戶最近的CDN服務器會返回靜態資源。給人的直觀感受是,離CDN服務器越遠,網站加載內容就越慢。舉個例子,如果CDN服務器在舊金山,那么洛杉磯的用戶就比歐洲的用戶更快獲取網站內容。圖1-9展示了CDN是如何縮短加載時間的。
圖片
圖1-10展示了CDN的工作流。
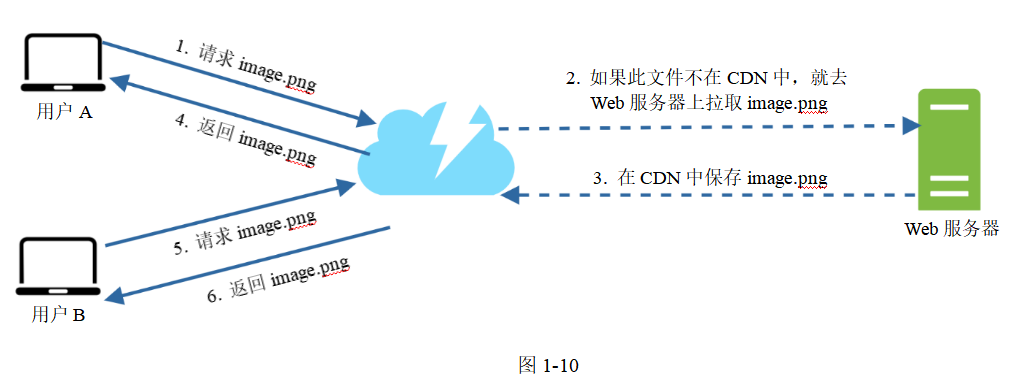
圖片
1.用戶A嘗試通過請求圖片的URL去獲取image.png。這個URL的域名由CDN服務商提供。亞馬遜和Akamai CDN上的圖片URL大概是下面這個樣子:
—https://mysite.cloudfront.net/logo.jpg
—https://mysite.akamai.com/image-manager/img/logo.jpg
2.如果CDN服務器的緩存中沒有image.png,CDN服務器就會向數據源服務器請求這個文件。數據源服務器可以是Web服務器,或者線上存儲,比如Amazon S3。
3.數據源服務器將image.png文件返回給CDN服務器,其中包括可選的HTTP頭Time-to-Live(TTL,生存時間)。TTL描述了該圖片文件應該被緩存多長時間。
4.CDN服務器緩存這個圖片并將其返回給用戶A。這個圖片一直緩存在CDN服務器中,直到TTL到期。
5.用戶B發送請求,要求獲取這張圖片。
6.只要TTL還沒到期,CDN服務器的緩存就會返回該圖片。
使用CDN時的注意事項
—花銷:CDN是由第三方供應商來運營的,對數據在CDN中的進出都會收費。緩存不經常使用的內容,并不能給性能帶來顯著的好處,應該考慮把這些內容從CDN中移出。
—設置合理的緩存過期時間:對于時間敏感的內容,設置緩存過期時間是很重要的。這個時間不應該過長或過短。如果過長,內容會不夠新。如果過短,可能導致頻繁地將內容從數據源服務器重新加載至CDN。
—CDN回退:要好好考慮你的網站或應用如何應對CDN故障。如果CDN出現故障暫時無法提供服務,客戶端應該有能力發現這個問題,并直接向數據源服務器請求資源。
—作廢文件:以下操作均可以在文件過期之前將其從CDN中移除。
調用CDN服務商提供的API來作廢CDN對象。
通過對象版本化來提供一個不同版本的對象。可以在URL中添加一個參數,比如版本號,來給一個對象添加版本。比如,在查詢字符串中可以加入版本號2(image.png?v=2)。
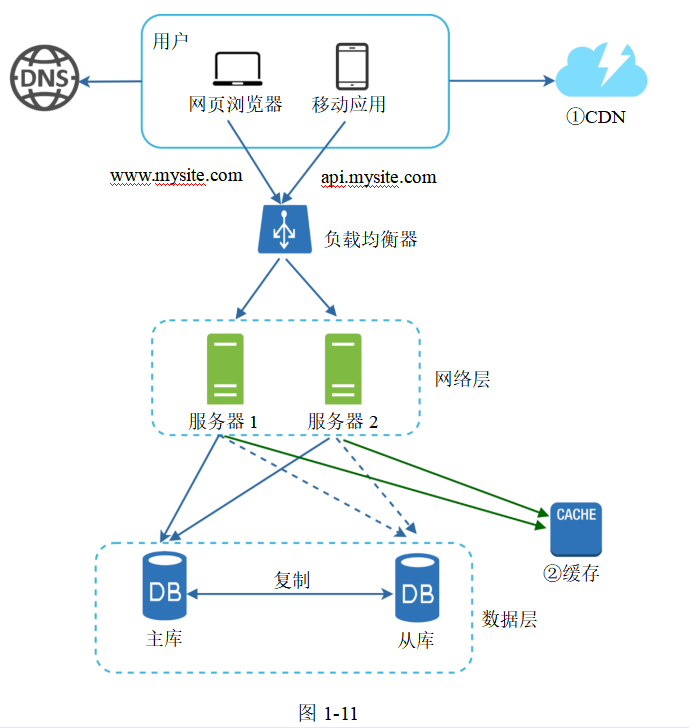
圖1-11展示了加入了CDN和緩存之后的系統設計方案。
1.靜態資源(JavaScript代碼、CSS文件、圖片等)不再由Web服務器提供,而是從CDN中獲取,以提高響應速度。
2.數據被緩存后,數據庫的負載就減輕了。
8、無狀態網絡層
現在是時候考慮橫向擴展網絡層了。為此,我們需要將狀態(例如,用戶會話數據)從網絡層中移出。一個好的做法是將會話數據存儲在持久性存儲(如關系型數據庫或NoSQL)中。集群中的每個Web服務器都可以經由數據庫訪問狀態數據。這就是所謂的無狀態網絡層。
有狀態架構
有狀態的和無狀態的服務器是有一些關鍵差異的。有狀態的服務器處理客戶端發來的一個個請求,并記下客戶端的數據(狀態)。無狀態的服務器則不保存狀態信息。
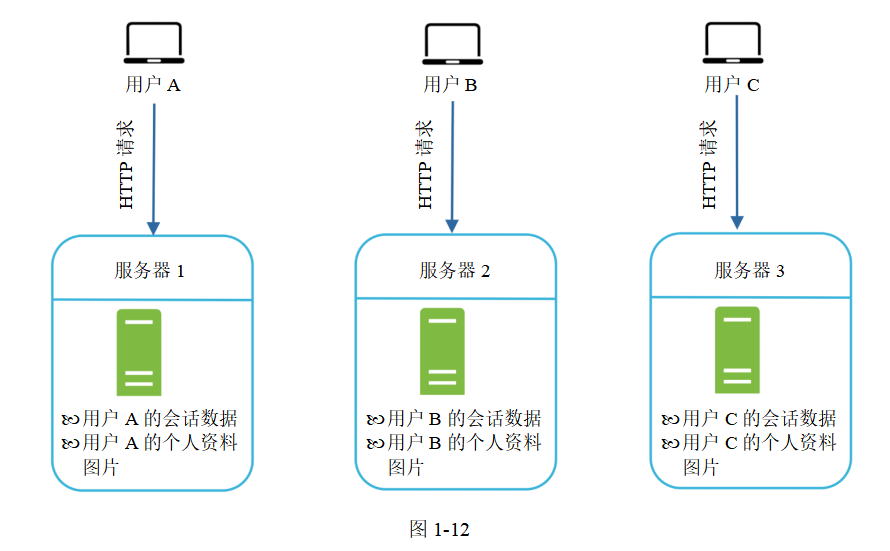
圖1-12展示了一個有狀態架構。
圖片
在圖1-12所示的架構中,用戶A的會話數據和個人資料圖片會被存儲到服務器1上。為了對用戶A進行身份驗證,必須將HTTP請求發給服務器1。如果將請求發給其他服務器,比如服務器2,由于服務器2上沒有用戶A的會話數據,因此身份驗證就會失敗。同理,用戶B的所有HTTP請求必須發給服務器2;用戶C的所有請求必須發給服務器3。
現在的問題是,如何將來自同一客戶端的所有請求都發給同一個服務器。大部分負載均衡器都提供的黏性會話可以解決這個問題,但是會增加成本。這種方法使得添加或者移除服務器變得更加困難,同時也使得應對服務器故障變得更具挑戰性。
無狀態架構
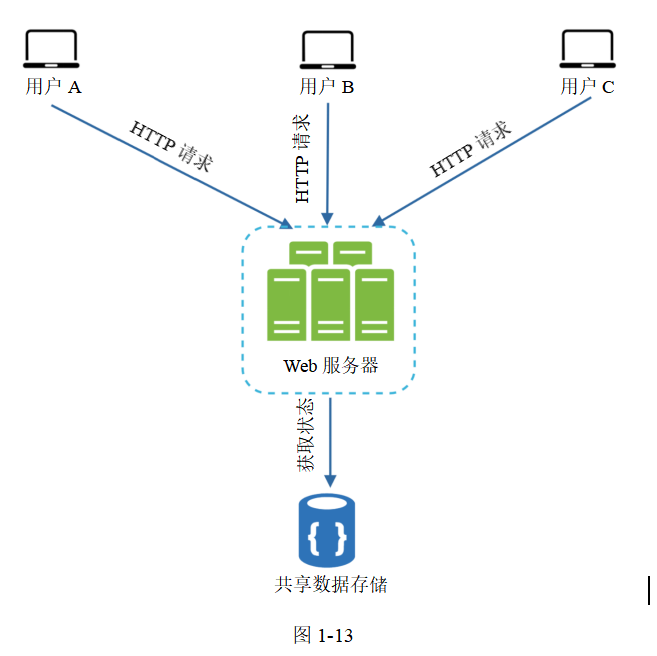
圖1-13展示了一個無狀態架構。
在這個無狀態架構中,用戶的HTTP請求可以發給任意Web服務器,然后Web服務器從共享的數據存儲中拉取數據。狀態數據存儲在共享數據存儲而非Web服務器中。無狀態的系統更加簡單,更健壯,也更容易擴展。
圖1-14展示了加入了無狀態網絡層后的系統設計。
圖片
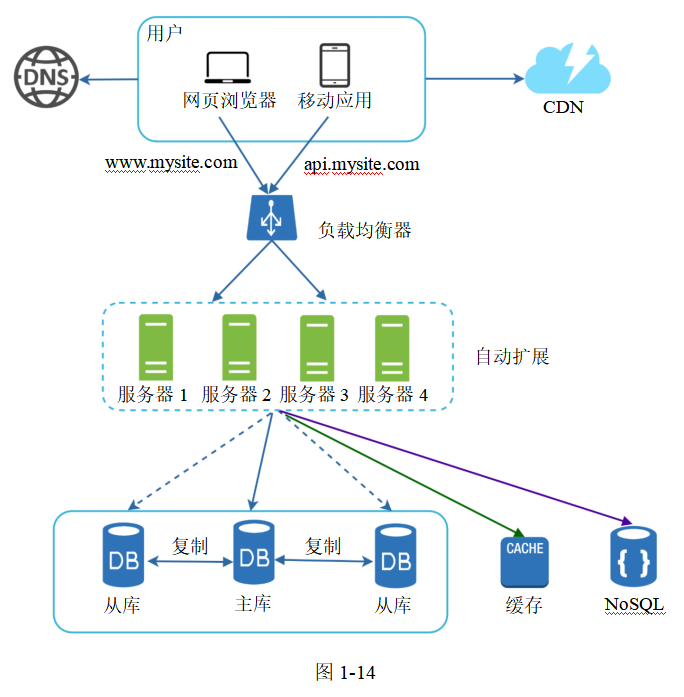
圖片
如圖1-14所示,我們把會話數據從網絡層中移出,放到持久化存儲中保存。共享數據存儲可以是關系型數據庫或者NoSQL(比如,Memcached、Redis)。選擇NoSQL的原因是它容易擴展。自動擴展的意思是,基于網絡流量自動地增加或者減少Web服務器。將狀態數據從Web服務器中移除后,就很容易實現網絡層的自動擴展了。
如果你的網站發展迅速,而且吸引了非常多的國際用戶,要提高可用性以及在更廣的地理區域提供更好的用戶體驗,讓網站支持多數據中心就非常關鍵。
9、數據中心
圖1-15展示了有兩個數據中心的例子。正常情況下,用戶會被基于地理位置的域名服務導流到最近的數據中心,也就是說流量被分散到不同的數據中心,在圖1-15中有美國東部和美國西部兩個數據中心。基于地理位置的域名服務(geoDNS)是一種基于用戶的地理位置將域名解析為不同IP地址的DNS服務。
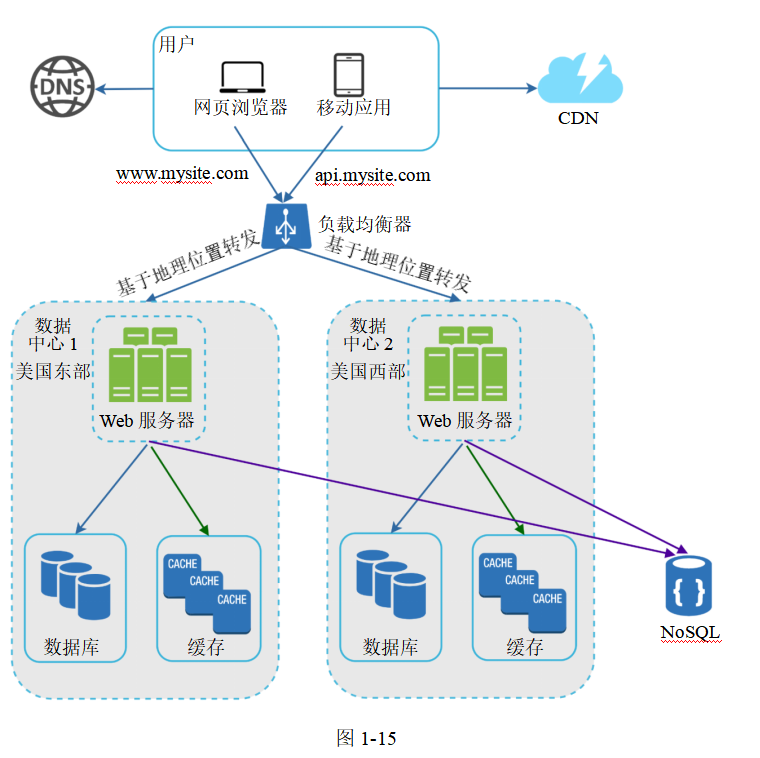
圖片
如果有某個數據中心出現嚴重的故障,可以把所有的流量轉到另一個運轉正常的數據中心。在圖1-16所示的例子中,數據中心2(美國西部)發生了故障,全部流量被轉至數據中心1(美國東部)。
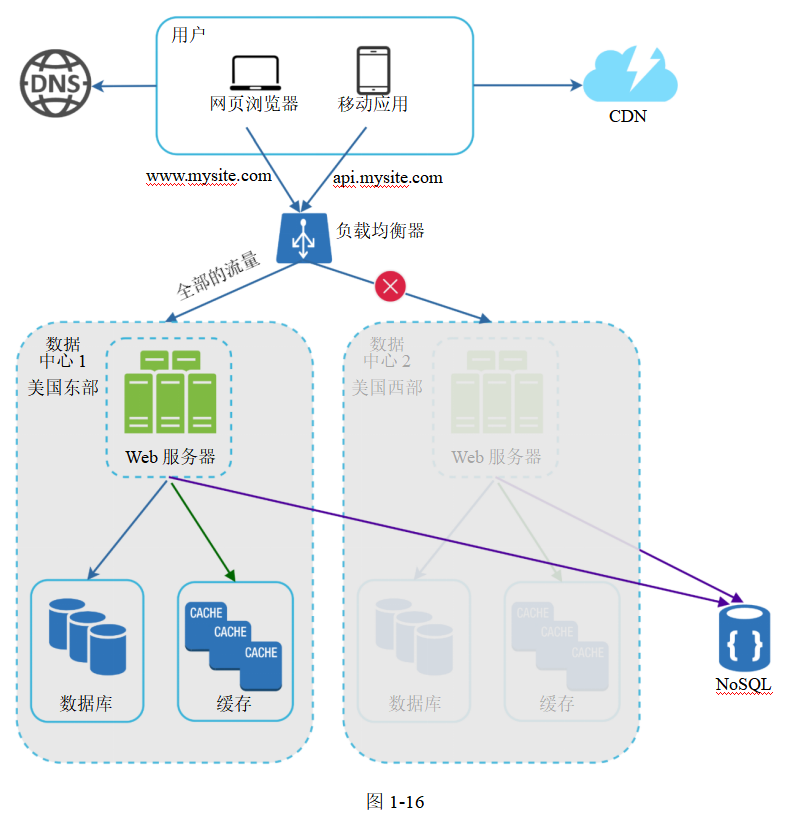
圖片
要設置多數據中心,必須先解決如下技術難題:
—流量重定向。要有能把流量引導到正確數據中心的有效工具。geoDNS可以基于用戶的地理位置把流量引導到最近的數據中心。
—數據同步。不同地區的用戶可以使用不同的本地數據庫或者緩存。在故障轉移的場景中,流量可能被轉到一個數據不可用的數據中心。常用的一個策略是在多個數據中心復制數據。Netflix工程博客上的文章“Active-Active for Multi-Regional Resiliency”說明了Netflix是如何實現多數據中心異步復制的。
—測試和部署:設置多數據中心后,在不同的地點測試你的網站/應用是很重要的。而自動部署工具則對于確保所有數據中心的服務一致性至關重要。
為了進一步擴展我們的系統,我們需要解耦系統中不同的組件,這樣它們就可以單獨擴展了。在現實世界中,很多分布式系統用消息隊列來解決這個問題。
10、消息列隊
消息隊列是一個持久化的組件,存儲在內存中,支持異步通信。它被用作緩沖區,分配異步的請求。消息隊列的基本架構很簡單:輸入服務(也稱為生產者或發布者)創建消息,并把它們發布到消息隊列中;其他服務或者服務器(也稱為消費者或訂閱者)與消息隊列連接,并執行消息所定義的操作。這個模型如圖1-17所示。

圖片
解耦使消息隊列成為構建可擴展和可靠應用的首選架構。有了消息隊列,當消費者無法處理消息時,生產者依然可以將消息發布到隊列中;就算生產者不可用,消費者也可以從隊列中讀取消息。
考慮以下用例:你的應用支持修改圖像,包括裁剪、銳化、模糊化等,這些任務都需要時間來完成。在圖1-18中,Web服務器把圖像處理的任務發布到消息隊列。圖像處理進程或服務(Worker)從消息隊列中領取這個任務,并異步執行。生產者和消費者都可以獨立地擴展。隊列的規模變大以后,可以加入更多的Worker,以減少處理時間。如果隊列在大部分時間中都是空的,就可以減少Worker的數量。
11、錄日志、收集指標與自動化
對于一個只有幾臺服務器的小網站,記錄日志、收集指標和自動化只是錦上添花的實踐而非必需的工作。但是當網站發展成為大企業提供服務的平臺時,這些工作就是必需的了。
記錄日志:監控錯誤日志非常重要,因為它可以幫助識別系統的錯誤和問題。你可以監控每個服務器的錯誤日志,也可以用工具把各個服務器的日志匯總到一個中心化的服務中,方便搜索和查看。
收集指標:收集不同類型的指標數據,有助于獲得商業洞察力和了解系統的健康狀態。
以下幾個指標很有用:
—主機級別指標:CPU、內存、磁盤I/O等。
—聚合級別指標:比如整個數據庫層的性能,整個緩存層的性能等。
—關鍵業務指標:每日活躍用戶數、留存率、收益等。
自動化:當系統變得龐大且復雜時,就需要創建或者使用自動化工具來提高生產力。持續集成是一個很好的做法。在這種做法中,每次代碼檢入(check in)都需要通過自動化工具的審核,使團隊能及時發現問題。同時,將構建、測試和部署等流程自動化,可以顯著提高開發人員的生產力。
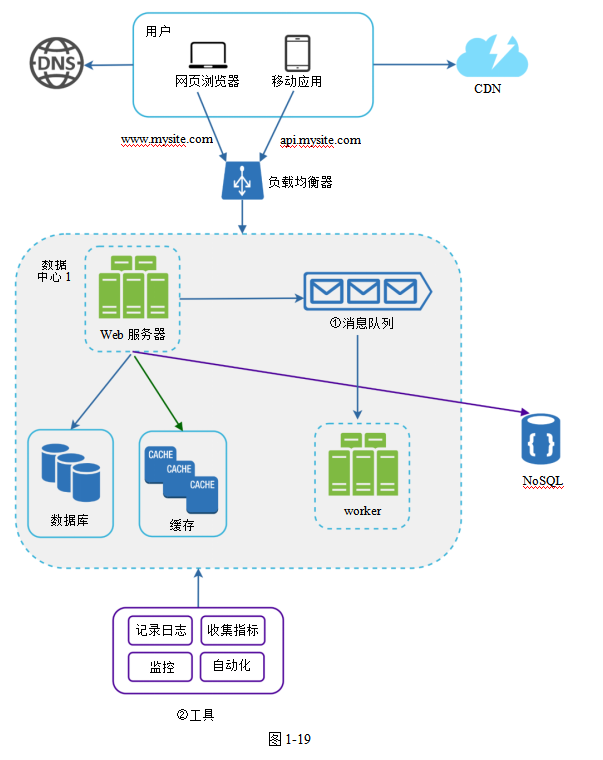
添加消息隊列和各種工具
圖1-19展示了更新后的系統設計,因為圖書版面有限,只畫了一個數據中心。
1.這個系統中包含一個消息隊列,它使系統更加松散地耦合且更容易從故障中恢復。
2.它包含了記錄日志、監控和收集指標的功能,以及自動化工具。
隨著數據與日俱增,你的數據庫過載變得越來越嚴重。是時候擴展數據層了。
12、數據庫擴展
數據庫的擴展有兩種方式:縱向擴展和橫向擴展。
縱向擴展
縱向擴展又叫作向上擴展,就是為已有機器增加算力(CPU、內存、硬盤等)。業界有一些非常強勁的數據庫服務器。亞馬遜的RDS(關系型數據庫服務)可以提供擁有24 TB內存的數據庫服務器。這種性能強勁的數據庫服務器可以存儲和處理非常多的數據。舉個例子,Stack Overflow的網站在2013年每個月有超過1000萬的獨立用戶訪問,但是它只有一個主數據庫。然而,縱向擴展也有一些重大缺點:
—盡管可以給數據庫服務器添加更多的CPU、內存等,但是硬件的能力總是有上限的。如果網站的用戶基數很大,單服務器是不夠的。
—更大的單點故障風險。
—總成本很高。強勁的服務器比一般的服務器貴很多。
橫向擴展
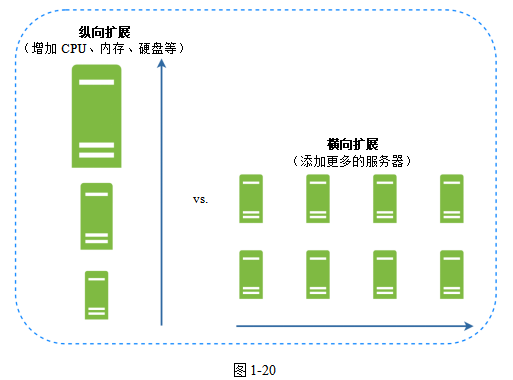
橫向擴展,也叫分片,就是添加更多服務器。圖1-20對比了縱向擴展和橫向擴展。
數據庫分片是指把大數據庫拆分成更小、更容易管理的部分(這些部分叫作Shard,分片)。每個Shard共享同樣的數據庫Schema,但是里面的數據都是這個Shard獨有的。
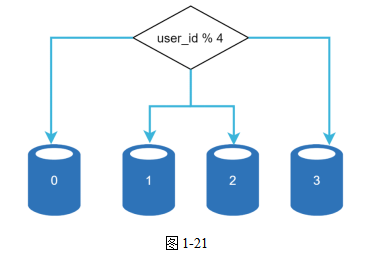
圖1-21展示了一個做了分片的數據庫。根據用戶ID,用戶數據被分配到其中一個數據庫服務器上。每次要訪問數據時,就會用一個哈希函數來找對應的Shard。在我們的例子中,以user_id(用戶ID)對4求余作為哈希函數。如果余數為0,那么Shard 0就被用來存儲和獲取數據;如果余數為1,就用Shard 1,依此類推。
圖片
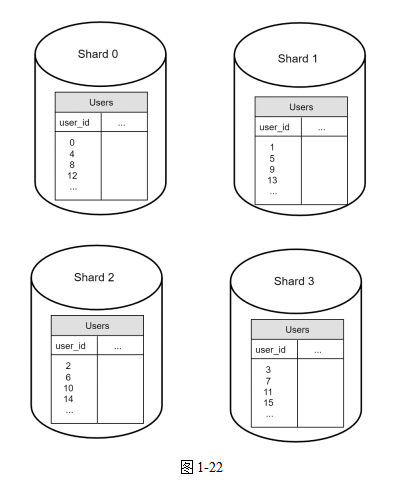
圖1-22展示了做過分片的數據庫中的用戶表示例。
實施分片策略時,要考慮的最重要的問題是選擇什么分片鍵(Sharding Key)。分片鍵(也叫作分區鍵,Partition Key)由一個或者多個數據列組成,用來決定將數據分到哪個Shard。在圖1-22所示的例子中,user_id被用作分片鍵。分片鍵可以把數據庫查詢路由到正確的數據庫,使你高效地檢索和修改數據。在選擇分片鍵時,最重要的標準之一是選擇一個可以讓數據均勻分布的鍵。
分片是一種不錯的擴展數據庫的技術,但它還遠不是一個完美的解決方案。它為系統引入了復雜性和新的挑戰。
重分片數據:出現如下情況時,需要對數據重新分片。第一種是因為數據快速增長,單個Shard無法存儲更多的數據。第二種是因為數據的分布不均勻,有些Shard的空間可能比其他的更快耗盡。當Shard被耗盡時,就需要更新用于分片的哈希函數,然后把數據移到別的地方去。我們會在第5章介紹一致性哈希算法,它是解決這個問題的常用技術。
名人問題:也叫作熱點鍵問題。過多訪問一個特定的Shard可能造成服務器過載。想象一下,把Katy Perry、Justin Bieber和Lady Gaga的數據都放在同一個Shard里,對于社交應用而言,這個Shard會因讀操作太多而不堪重負。為了解決這個問題,我們可能需要為每個名人都分配一個Shard,而且每個Shard可能還需要進一步分區。
連接和去規范化(de-normalization):一旦數據庫通過分片被劃分到多個服務器上,就很難跨數據庫分片執行連接(join)操作了。解決這個問題的常用方法就是對數據庫去規范化,把數據冗余存儲到多張表中,以便查詢可以在一張表中執行。
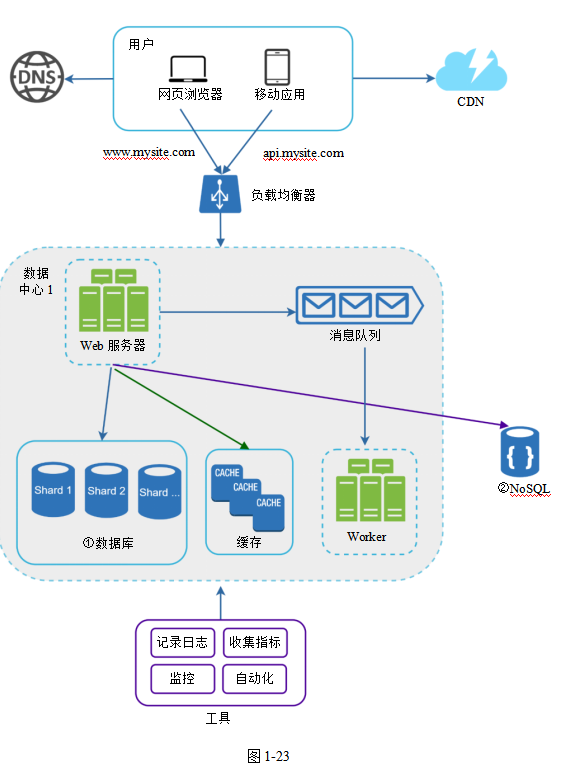
在圖1-23中,我們對數據庫做了分片,以支持數據流量的快速增長;同時,將有些非關系型功能遷移到NoSQL數據庫中,以降低數據庫的負載。High Scalability網站上有一篇文章“What the Heck are You Actually Using NoSQL for?”介紹了很多NoSQL數據庫的使用案例。
圖片
審核編輯:湯梓紅
-
Web
+關注
關注
2文章
1262瀏覽量
69441 -
服務器
+關注
關注
12文章
9123瀏覽量
85324 -
數據庫
+關注
關注
7文章
3794瀏覽量
64362
原文標題:系統設計,被我拿捏了!
文章出處:【微信號:小林coding,微信公眾號:小林coding】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Digi控制臺服務器通過NIST FIPS 140-2認證
如何配置基于Win 2003 的服務器
基于單服務器實現大容量會議服務的系統及方法
租用一臺服務器多少錢?
輕松使用SaltStack管理成千上萬臺服務器(入門教程)

SOLARIS操作系統服務器數據恢復案例
在SecureCRT中讓多臺服務器同時執行同一個命令的方法





 工商網監
工商網監
評論