 教您如何精調出自己的領域大模型
教您如何精調出自己的領域大模型
BERT和 GPT-3 等語言模型針對語言任務進行了預訓練。微調使它們適應特定領域,如營銷、醫療保健、金融。在本指南中,您將了解 LLM 架構、微調過程以及如何為 NLP 任務微調自己的預訓練模型。
介紹
大型語言模型 (LLM) 的特別之處可以概括為兩個關鍵詞——大型和通用。“大”是指它們訓練的海量數據集及其參數的大小,即模型在訓練過程中學習的記憶和知識;“通用”意味著他們具有廣泛的語言任務能力。
更明確地說,LLM 是 ChatGPT 或 Bard 等聊天機器人背后的一種新型 AI 技術,與通常針對單個任務進行訓練的典型神經網絡不同,LLM 是在盡可能大的數據集上訓練的,就像整個互聯網一樣,以學習生成文本、代碼等各種語言技能。

模型尺寸
然而,它們廣泛的非專業基礎意味著它們可能會在利基行業應用中失敗。
例如,在醫學領域,雖然LLM大模型可能擅長通過日常的基礎訓練總結通用文章,但它缺乏專業的醫學知識來準確總結包含復雜技術細節和術語的專業外科手術文件。這就有了微調的用武之地——對LLM進行醫學概述數據的進一步訓練,教給它高質量醫學摘要所需的專業知識和詞匯。
好奇這種微調是如何完成的?嗯,這就是本指南的重點。請繼續閱讀,我們將更深入地研究使這些模型專業化的技術!
根據新技能訓練模型
大型語言模型位于轉換器架構上。近年來,這種結構極大地推動了自然語言處理的進步。在 2017 年的論文“Attention is All You Need”中首次引入,轉換器架構通過其基于注意力的機制來理解語言上下文,標志著 NLP 的轉折點。
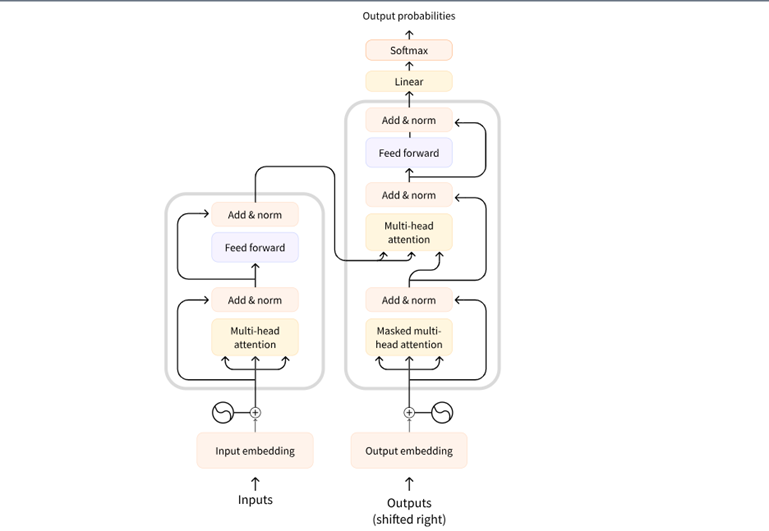
轉換器的核心由編碼器和解碼器組成。編碼器讀取輸入序列(如句子),并創建其抽象表示形式。該向量捕獲單詞背后的上下文和含義,然后解碼器使用該表示來生成輸出。
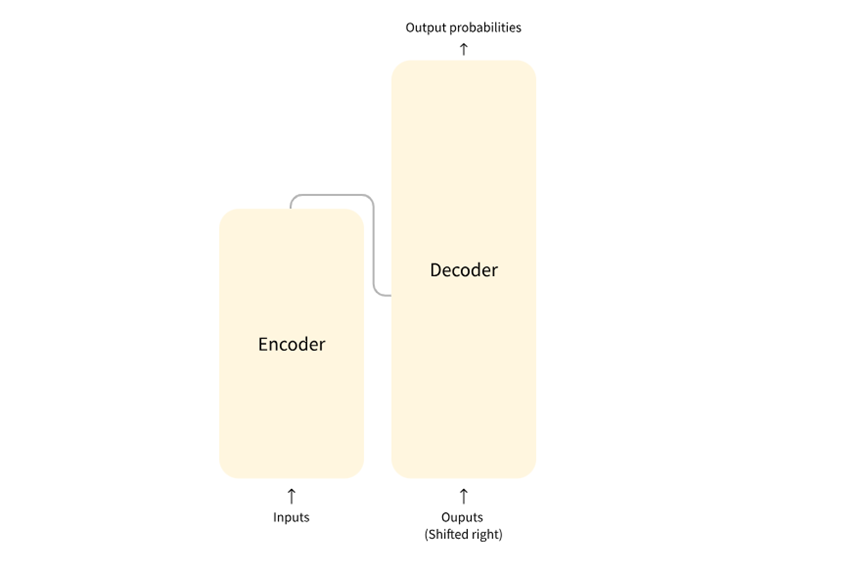
轉換器通過注意力機制工作。允許模型專注于輸入句子中最重要的單詞。該模型根據每個單詞在短語或句子中的上下文為每個單詞分配權重和重要性。了解微調及其工作原理
轉換器架構的突破通過對大量文本數據(包括書籍、網站等)進行訓練,使創建功能非常強大的基礎模型成為可能。T5、Roberta 和 GPT-3 等流行示例通過接觸大量信息來培養強大的通用語言能力。然而,專業領域需要對廣泛培訓所遺漏的內容進行調整。
例如,我最近參與了一個項目,構建了一個Web 應用程序,可以檢測用戶語音中的情感。從語音模式中識別快樂、沮喪或悲傷等感覺,只能通過在情緒數據集上微調預先訓練的模型來實現。
彌合這種從寬到窄的差距是微調的用武之地。就像持續學習一樣,微調可以通過吸收新信息來增強優勢。通過使用特定領域的數據(例如醫學期刊或客戶對話)訓練模型,它們的能力得到了提升,不僅可以匹配,而且可以在這些特定領域表現出色。
現在讓我們來探討一些可用于微調 LLM 的技巧。
微調技術
隨著模型變得越來越大,微調所有模型參數可能效率低下,但有一些先進的方法可以只更新關鍵區域,同時保留有用的知識。讓我們來看看其中的一些:
PEFT
PEFT(Parameter Efficient Fine-Tuning)是一個用于高效適應預訓練語言模型的庫。它可以通過僅更新一小部分內部參數而不是所有權重來適應大型預訓練語言模型。這有選擇地指導定制,大大降低了微調的計算和存儲需求。
LoRA是一種通過僅更新小的關鍵部分而不是直接更新所有大量內部參數來有效微調巨型模型的方法.
它的工作原理是在模型架構中添加薄的可訓練層,將訓練重點放在需要新知識的內容上,同時保留大多數現有的嵌入式學習。
QloRa
QLoRa通過大幅降低內存需求,允許在消費級GPU 上微調具有數十億個參數的巨型模型。
它的工作原理是在訓練期間將模型大小縮小到微小的 4 位精度。壓縮格式顯著減少了計算內存的使用量,確保在必要時將精度重新計算為完整格式。此外,微調過程只關注 LoRA 插入的小適配器層, 而不是直接對整個擴展模型進行更改。
微調的實際運用
現在我們已經了解了微調模型,讓我們通過實際微調預訓練模型來獲得實踐經驗。在本教程中,我們將微調醫學領域命名實體識別任務的模型。
這里使用的模型是xlm-roberta-base(https://huggingface.co/xlm-roberta-base),它是RoBERTa的多語言版本,數據集ncbi_disease(https://huggingface.co/datasets/ncbi_disease)包含NCBI疾病語料庫的疾病名稱和概念注釋。
要繼續操作,您需要一個 Hugging Face 帳戶,這是大型語言模型構建模塊的首選平臺,我們將用于微調和共享我們的模型。如果您還沒有帳戶,可以在此處(https://huggingface.co/)創建一個帳戶。
動手微調:代碼示例
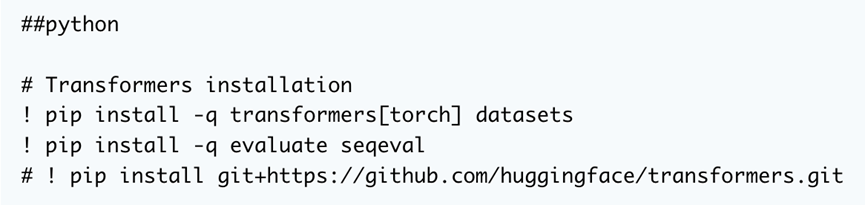
首先是第一件事。我們需要安裝三個常用庫:transformer、datasets 和 evalate。這將使我們能夠訪問將用于訓練的模型和數據集,并在訓練期間獲得模型性能。
我們可以直接從 GitHub 上的源代碼安裝該庫,以便在我們想要使用最新開發時提供靈活性。

然后,加載專門用于命名實體識別 (NER) 的 NCBI 疾病數據集。NCBI(The National Center for Biotechnology Information,美國國家生物技術信息中心) ?
?
如果需要,還可以從中心選擇其他數據集,只需確保任何新數據集都適用于嘗試微調的內容,然后再使用它。
接下來,我們可以檢查測試數據中使用的實際命名實體識別 (NER) 標簽。
這輸出:

測試數據僅使用三個標簽:O 表示超出范圍的單詞,B - Disease用于標記疾病實體的開始,I-Disease 用于疾病名稱后面并構成疾病名稱一部分的單詞。
序列 ['O', 'B-Disease', 'I-Disease'] 是一組常用于命名實體識別 (NER) 任務的標簽。
例如,考慮“患者已被診斷出患有肺癌”這句話。相應的標簽為:
“O O O O B-疾病 I-疾病 I-疾病”
在這里,“O”標記不屬于疾病實體的單詞,“B-疾病”標記開始,“I-疾病”延續實體單詞。
現在,我們需要加載一個分詞器來預處理文本數據。

這將使用 Transformers 庫初始化 xlm-roberta 分詞器。
分詞器將原始文本格式化為 ID 以供模型理解。這為我們的數據準備了微調預訓練模型。
之后,我們需要創建一個函數,該函數將為模型輸入準備文本數據。讓我們將其分解為三個部分:
在這一部分中,我們使用分詞器來處理輸入詞。它將單詞分解成更小的部分,確保模型能夠更好地理解它們。
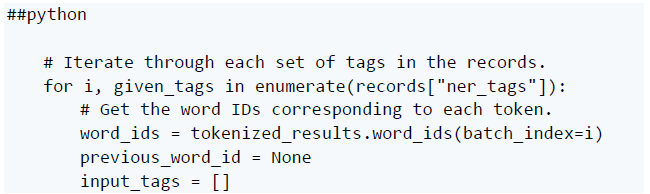
在這里,我們瀏覽記錄中的標簽。對于每組標簽,我們找出它們在標記化輸入中對應的單詞(或子單詞)。

最后一部分確定每個令牌的標記。如果它是一個特殊的令牌,它會得到一個特定的標記。如果它是一個新詞,它會得到適當的標簽。如果它是一個子詞,它就會獲得另一個特定的標簽。接下來,將這些分配的標記添加到標記化結果中。

使用分詞器分解數據集中的輸入詞。此步驟會添加特殊標記,并可能將單個單詞拆分為較小的部分。
然后,您可以打印出鍵和值:
完成此操作后,我們可以使用 id2label 和 label2id 創建預期標記 ID 到其標記名稱的映射:

在此階段,我們可以使用 Transformers 庫加載預訓練模型,提供預期標記的數量和標記映射。

要訓練模型,請使用 Hugging FaceTrainer API。它初始化默認的訓練參數:

然后訓練模型:
此時,我們可以使用默認訓練參數將模型推送到 Hub。但是,讓我們先進行一些推理,然后可以更具體地針對數據自定義訓練參數。

使用管道函數調用模型并對文本進行分類:

由于 Trainer 在訓練過程中不會自動評估模型性能,我們需要給它傳遞一個函數來計算和顯示指標,而Hugging Face評估庫可以提供幫助,它只是提供了準確性函數,你可以用 evaluate.load() 加載。
首先,導入庫:

然后,創建使用它的評估函數:


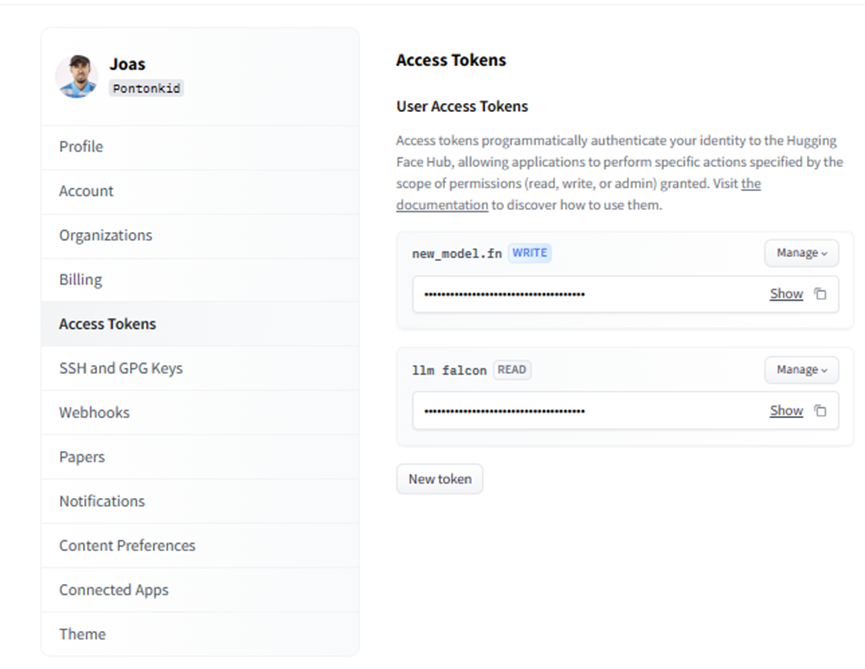
現在可以為模型定義訓練參數了。但首先,登錄到 Hub,以便稍后上傳模型:

我們可以訪問帳戶中的令牌,只需確保它具有“寫入”訪問權限即可。
然后,指定訓練超參數:


到了使用這些計算指標訓練模型的時候了。
首先,重新加載原始的 xlm-roberta 模型和分詞器: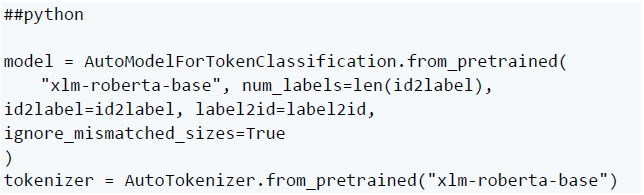
接下來,使用準確性指標和特定的 TrainingArguments 對其進行微調:

完成后,可以將模型推送到 Hub:

現在,我們已使用自定義訓練參數和指標在 NCBI 疾病數據集上成功微調了預訓練模型。
用于微調LLM 的工具
現在使用最小化編碼或使用完全可視化界面的工具,可以更輕松地微調自己的語言模型。
讓我們看看任何人都可以用來微調模型的一些選項:
Lamini
Source:Lamini
微調套件

Source:Cohere
首先,Cohere是一個 NLP 平臺,它為開發人員提供了對預構建的大型語言模型的訪問,用于文本摘要、生成和分類等自然語言任務。
Cohere 現在允許使用新的微調選項輕松自定義模型,例如:
聊天專業化 - 個性化、上下文感知的對話能力
搜索/推薦專業知識 - 精確匹配用戶偏好
多標簽分類 - 跨多個屬性有效地標記內容
它們通過微調 Web UI或Python SDK選項來實現專業訓練。
Autotrain
HuggingFace提供的不僅僅是模型訪問、共享和訓練庫。他們還提供用于無代碼微調的AutoTrain。
它無需編程即可在數據上直觀地自定義最先進的模型,通過端到端平臺處理上傳數據集、訓練、評估和部署量身定制的創作。
Galileo LLM Studio
Galileo公司幫助開發語言 LLM 應用程序,提供跨越項目生命周期的模塊——從原型實驗到生產監控。
Fine-Tune 模塊專注于通過自動標記有問題的訓練數據來最大限度地提高模型定制質量。這樣可以協作識別和解決標簽不正確、覆蓋范圍稀疏或污染專業能力潛力的低質量示例等問題。
當然,除了這里介紹的 Lamini、Cohere 或 AutoTrain 之外,還有許多其他微調工具。但這些選項可以幫助您入門,并隨時將您知道的選項添加到列表中。
有效微調的最佳實踐
在微調大型語言模型時,遵循一些最佳實踐有助于確保獲得所需的結果。
這些指南包括以下步驟:
定義目標和任務
我們可以從精確定義模型擅長的任務開始,例如語言翻譯、文本分類或摘要。然后在這些更廣泛的目標中縮小細節范圍。例如,情緒分析可能涉及產品評論、醫療保健報告、法律文件等,每一項都需要稍作調整。
選擇正確模型
選擇預訓練模型,使功能與定義的目標保持一致。我們可以前往HuggingFace或Kaggle等模型中心開始,然后調查架構基礎知識、訓練數據以及有關候選人的更多信息。
模型選擇還取決于硬件資源,因為盡管效率很高,但較大的模型仍然需要嚴格的硬件。
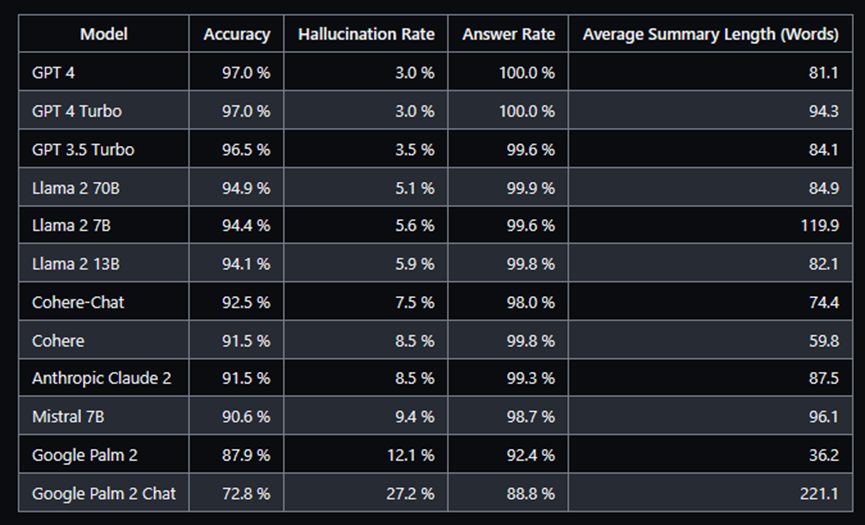
Vectara制作的幻覺(Hallucination)排行榜
如果我們打算微調文本生成或問答任務的模型,可以查看 Vectara 的模型幻覺排行榜或使用他們的模型。
整理高質量的訓練數據
在獲取數據以微調模型時,質量和相關性非常重要。模型從我們提供的確切訓練示例中學習,因此我們必須投喂反映實際需求的有代表性的、準確、干凈的示例。
有用的技術包括分詞tokenization - 將句子拆分為整齊標準化的單詞分組和詞形還原。數據處理過程可確保無縫引入和學習。
監控和可觀測性
在整個監控過程之前,要取得成功,在訓練過程中調整學習率、批量大小和周期等因素非常重要。在開始檢查模型中的偏差之前,這是必要的。
訓練模型后,可以使用以下工具:
Giskard來檢測模型中嵌入的幻覺或事實不準確等問題。解決這些問題至關重要,因為在將模型部署到生產環境時,它們可能會帶來重大風險。
Superwise或Langkit用于大型語言模型監控。
結論
微調模型之后,考慮通過使用Gradio或Streamlit創建用戶友好的應用程序將其提升到一個新的水平。這些框架使應用程序開發變得輕而易舉,但有很多選項可供探索。
我們可能還想密切關注用于微調 LLM 的新技術。一個好的開始可能是查看"Language Models are Super Mario"的論文,所有關于結合專家模型的知識。
原文:(https://bejamas.io/blog/fine-tuning-llms-for-domain-specific-nlp-tasks/)
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100714 -
nlp
+關注
關注
1文章
488瀏覽量
22033 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595 -
大模型
+關注
關注
2文章
2423瀏覽量
2641 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:一步一步教您如何精調出自己的領域大模型
文章出處:【微信號:軟件質量報道,微信公眾號:軟件質量報道】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論