 讓pytorch模型更快速投入生產的方法
讓pytorch模型更快速投入生產的方法
大家好,非常感謝大家的加入。我是馬克,在推理和PyTorch方面有著豐富的經驗。今天我想和大家談談一種讓你的模型快速投入生產的方法。訓練模型的過程非常艱難,你需要花費大量時間和計算資源。但是推理問題似乎相對簡單一些。基本上,你只需要將模型在一個批次上運行即可。這就是推理過程所需要的。然而,如果你更接近真實的場景,可能需要進行一些額外的步驟。比如,你不能每次推理都重新加載模型,而且你可能需要設置一個HTTP服務器,并對其進行推理。然后你需要加載模型權重和相關數據,對于大型模型,這可能需要很長時間。此外,用戶不會發送張量給你,他們可能發送文本或圖像,所以你可能需要對這些輸入進行預處理。然后你就可以運行推理了。
1.SetupanHTTpserver 2.Loadmodelweightsandartifacts 3.Preprocessinputs 4.Runaninference 5.Maketheinferencefast 6.Collectperformancemetrics 7.DeployonDockerorKubernetes 8.Scaletomultipleworkersandmachines
然后你就會想,太好了,我想要運行一個推理,但是這個推理要花很長時間。它需要幾秒鐘的時間。而實時通常不超過10毫秒——這是很多用戶對我們推理的期望。所以至少還有一個10倍的乘數在里面。你需要不斷地對此進行測量,因為你不能等待用戶因為速度太慢而放棄使用你的應用程序。最終你可能需要將其部署在一種可復現的環境中,比如Docker Kubernetes。一旦你完成了所有這些,那么你還需要處理多進程的問題。因為你將會有8個GPU,你需要讓這八個GPU都保持繁忙。你的CPU有數百個核心,你需要讓所有這些核心都保持繁忙。很多時候,我在TorchServe上工作,人們經常問我TorchServe和FastAPI之間的區別,我的回答是,如果你只是做前面其中的四點,FastAPI做得很好,不需要再去使用TorchServe。
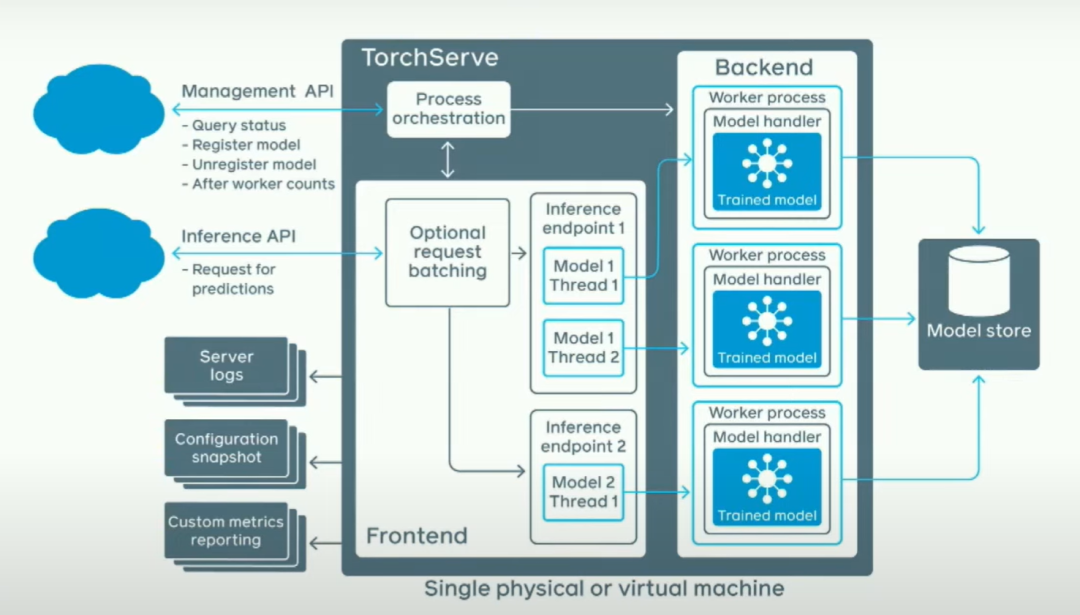
然而,如果你真的擔心推斷速度的快慢并且想讓它在多進程中工作,我們解決了一些比較困難的問題。基本上,我們有一個管理API,在這里你可以說,我想加載這些模型;一個推斷API,在這里你可以說,嘿,我想對這個模型進行請求。這將啟動幾個后端工作器,這些后端工作器實際上是Python進程。你正在啟動Python工作器。堆棧的其余部分大部分是用Java編寫的。人們經常問我的一個問題是,Java不是很慢嗎?為了回答這個問題,這是一個火焰圖。
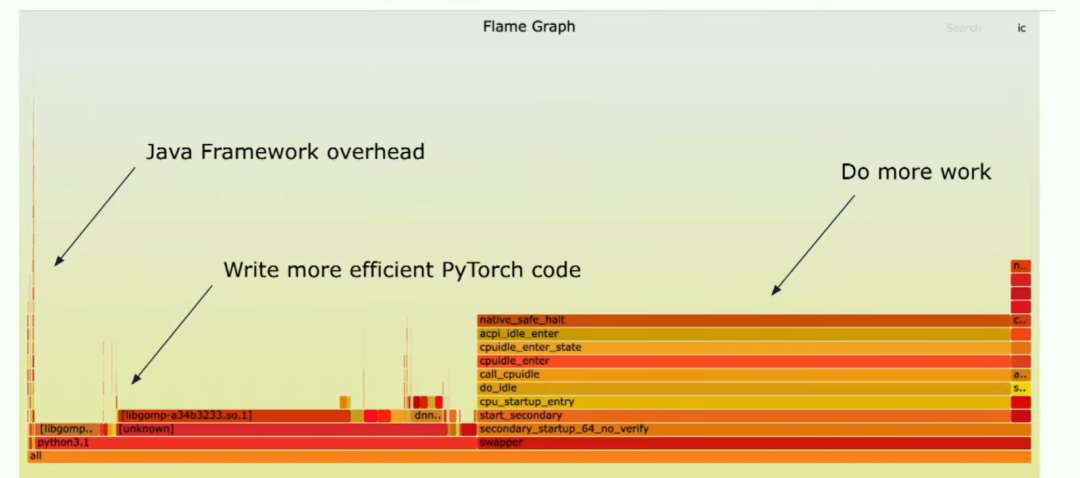
你可以看到這里,基本上你看到了左側的一條線,那是我們的框架開銷。順便說一下,讀這種圖的方式是x軸表示的不是時間,而是持續的消耗,因為這是一個采樣分析器。所以,這就是Java的開銷。還有很多空閑時間,"swapper"的意思是這內核CPU根本不做任何事情。這大約占總運行時間的50%,在我查看的典型客戶模型中如此,另外50%的時間花在Python環境中。所以你看這個,你需要做什么呢?首先,你需要做更多的處理,其次,你需要編寫更高效的PyTorch代碼。讓我們談談這兩件事。
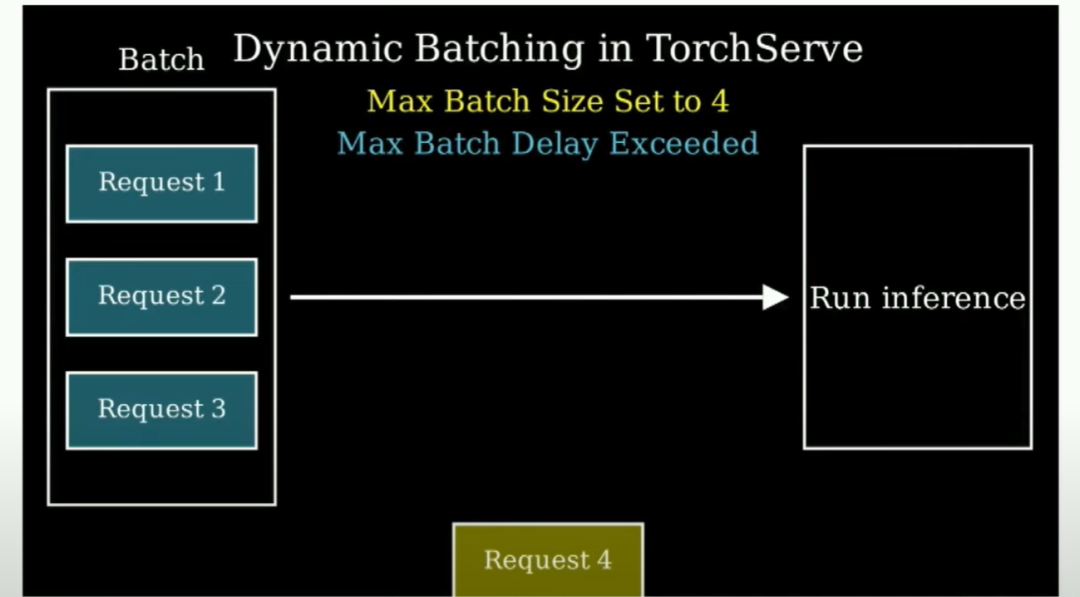
在做更多工作方面,你可用的最重要的優化之一是所謂的動態批處理。動態批處理的本質上是這樣的,你說:嘿,我有一個批次大小為4,但我最多等待30毫秒來獲取這三個元素。然后當30毫秒過去時,只要有可用的數據,你就把它們組成一個批次(當新的推理請求到達時,它們會被加入到當前正在處理的批次中,而不是單獨進行處理)。所以你需要不斷讓你的機器保持忙碌。

您使用產品的用戶體驗就像使用Torch服務一樣,您需要編寫一個被稱為處理程序的東西。這個處理程序是一個Python類,基本上需要學會如何預處理您的數據,并將處理后的數據返回。因此,從根本上講,您希望在純Python中創建一個推斷服務器。這是您需要構建的主要部分。您可以使用類似PDB這樣的工具。
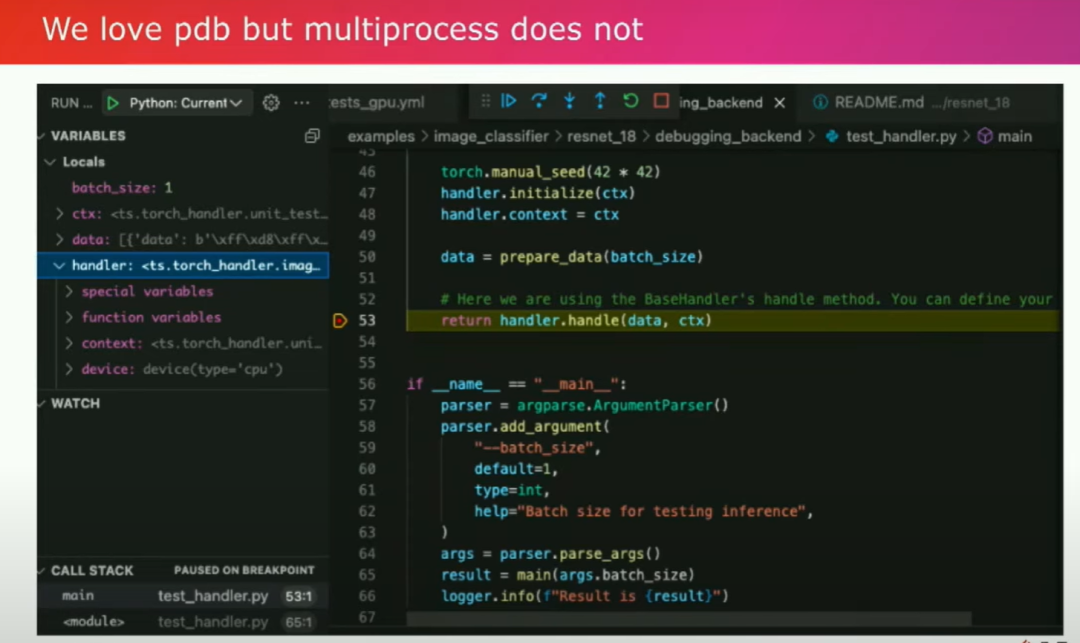
這是我的同事Ankit Gunapal添加的功能。通過這樣的方式,您可以輕松地調試程序,找出錯誤并主動解決崩潰問題。擁有Pythonic的工作流程的好處之一是我們的一些客戶,比如Ryan Avery覺得我們的迭代速度很快,因為您不需要將模型重寫為不同的語言來進行交互。您可以使用同樣的工具進行本地開發和生產部署。
所以,正如我之前提到的,典型程序的一半時間都在一個慢的PyTorch程序中度過。一種非常有用的調試方法是使用PyTorch分析器。你可以通過設置環境變量來啟用它。它的工作原理是顯示一個跟蹤結果。

在跟蹤結果中,你要注意的主要內容是,如果你有類似"stream 7"的標志,那就是你的GPU。(圖中的中間)你要注意的一個主要問題是有很多很小的線。這意味著你的GPU在派發獨立的核函數,這就意味著沒有融合,也就是你沒有充分利用你的GPU,相當于你在浪費錢。所以,你要希望那些線是厚厚的條狀,而不是這些細小的線。接下來,你可能會問,我的模型很慢,我該怎么辦?一種方法是編寫一個更小的模型,但也許這個更小的模型并不夠好。那么,在不改變模型代碼的情況下,你如何減少模型的延遲時間呢?
torch.compile(m,backend="inductor") torch.compile(m,backend="xla") torch.compile(m,backend="onnx") Highlyrecommended:torch.compile(m, mode="reduce-overhead" ButJITshaveastartupoverhead
我一直向人們推薦的主要是Torch編譯。你基本上可以使用Torch編譯你的模型和感應器。但編譯的好處在于它有一個后端參數。例如,如果你想在XLA和TPU上支持Torch服務,我們只需改變一個參數。也許像ONNX對于你正在查看的特定模型有更好的性能特征。所以你可以很容易地進行基準測試和查看。這與pytorch分析器和NVIDIA Insight結合使用,可以幫助你快速找出是什么使得事情變得更快。此外我還推薦了減少開銷這種模式。(reduce-overhead)CUDA圖表很棒,使一切都變得快速。所以,請使用它們。現在它們終于能夠與動態形狀一起工作,因此它們與動態批處理很好地配合。這是一件大事,并且最近在2.1版中才支持,所以我極力推薦。
modelbt=BetterTransformer.transform(model NowforGPUandCPU!
另一件事關于模型,目前非常流行的模型是transformers。但是,你不一定需要改變自己的模型去增加更快的核函數。因此,更好的transformer API在神經網絡模塊級別上工作,可以讓你更換更高效的核函數。最好的是,現在這個API可以加速GPU和CPU的工作負載,最新版本是2.1。另外需要記住的一點是,如果你在編譯代碼,JIT有一定的開銷,這是一個無法回避的開銷,但是如果你使用更多的緩存,可以大大減輕這個開銷。
TORCHINDUCTORCACHEDIR TORCHINDUCTORFXGRAPHCACHE Makesuretocopytheseovertoreduce yourwarmstarttimes
在像TorchServe這樣的推斷框架中,你將會生成多個Python進程,所有這些進程都可以共享同一個緩存,因為推斷是一種尷尬的并行任務。只要你在系統中設置這兩個環境變量,甚至可以將它們復制到多個節點上。這將大大減少您的熱啟動時間。所以我強烈建議您這樣做。只需在Docker命令或其他地方復制即可,沒有什么花哨的東西。
withtorch.device("meta")
model=Llama2
ckpt=torch.load(ckpt,mmap=True)
model.load_state_dict(ckpt,assign=True)
另一件事是在TorchServe中,我們過去推薦人們對模型進行壓縮和解壓縮,因為它可以成為一個獨立的工件。不幸的是,壓縮LLAMA7B大約需要24分鐘,解壓縮需要大約三分鐘,這是不可接受的。所以我們不再建議您進行壓縮。只需直接使用文件夾即可。然后,在加載實際的權重時,將元設備初始化與MMAP加載結合使用,可以大大加快模型的運行速度,在LLAMA7B上可能快約10倍。這基本上應該成為默認設置。
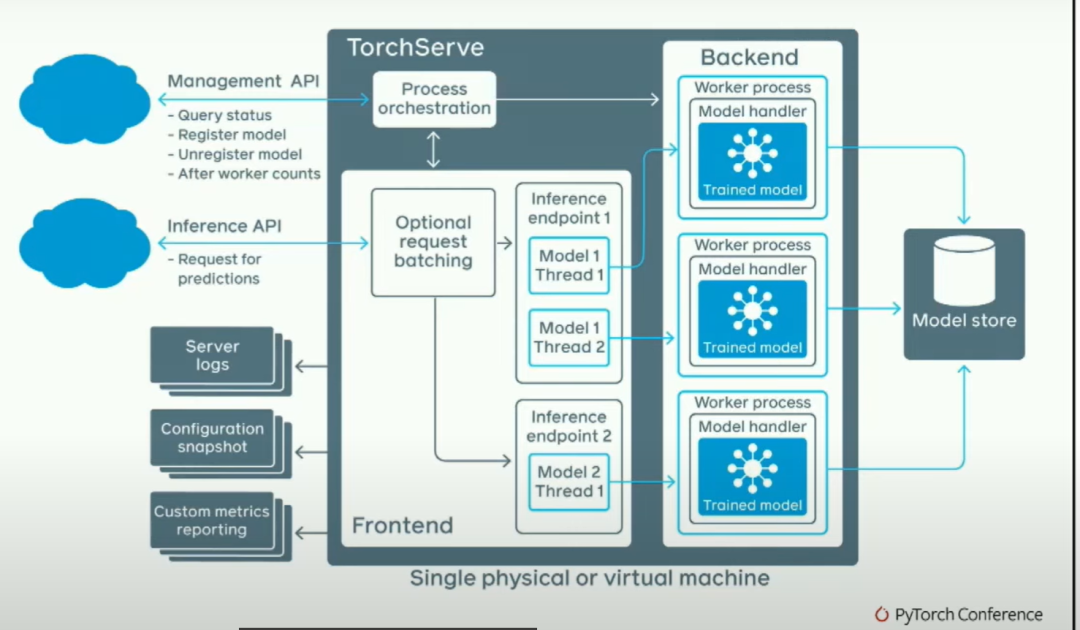
我們架構的一個很酷的地方是,我們可以隨意生成任意的后端工作進程,這些工作進程甚至不需要是Python進程。
Modelhandlercanbeinanylanguage! #includehandle=dlopen("aot.so",RTLDNOW)
所以,例如,像我的同行Matias、Resso和Li Ning一樣,一直在致力于為對延遲極為敏感的人們創建C++進程。另外一件事是,當你從單個Python進程轉向多個進程時,性能會大幅下降。因此,我設置了一個稱為魔法配置的配置變量,將線程數設置為1,很多人可能一直在生產環境中使用這個配置。有一個稍微更好的啟發方法,即將物理核心數除以工作線程的數量,這會給你一個稍微更好的結果。通常你能觀察到,但問題是,隨著核心數量的增加,你會注意到性能并不呈線性增長。所以我非常高興我們團隊有Intel的Minjin Cho加入。 她注意到了一個問題,我們的線程在CPU上的兩個插槽間遷移。因此,如果一個核心正在執行一些工作。然后它會移動到另一個核心,然后又移動回來。所以最終的結果就是你有一個進程,它基本上會不斷地丟失緩存,導致性能大幅度下降。我說的是像5到10倍的時間慢下來。
她注意到了一個問題,我們的線程在CPU上的兩個插槽間遷移。因此,如果一個核心正在執行一些工作。然后它會移動到另一個核心,然后又移動回來。所以最終的結果就是你有一個進程,它基本上會不斷地丟失緩存,導致性能大幅度下降。我說的是像5到10倍的時間慢下來。
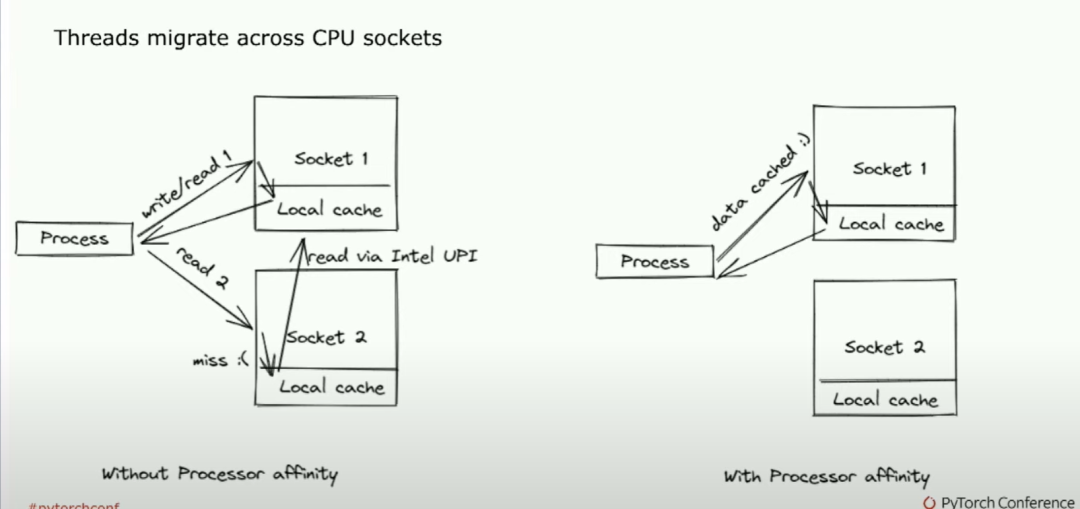
所以關鍵在于當我們啟動Python進程時,我們希望確保它們與特定的進程有一定的關聯性。這是我們默認啟用并且Torch服務作為一個環境變量所實現的。但你所希望看到的是,有一個忙碌的socket塊,而另一個則沒有工作。這是HTOP中你希望看到的良好視圖,以確保CPU推斷是快速的。

這很棒,因為比如Navver就在使用這些優化。他們在博客中提到每年節省了340k,并且通過使用這樣的技術,他們的服務器成本也減少了。
Naver: https://pytorch.org/blog/ml-model-server-re source-saving/ PyTorchGeometric: https://pytorch-geometric.readthedocs.io/en/ latest/advanced/cpuaffinity.html
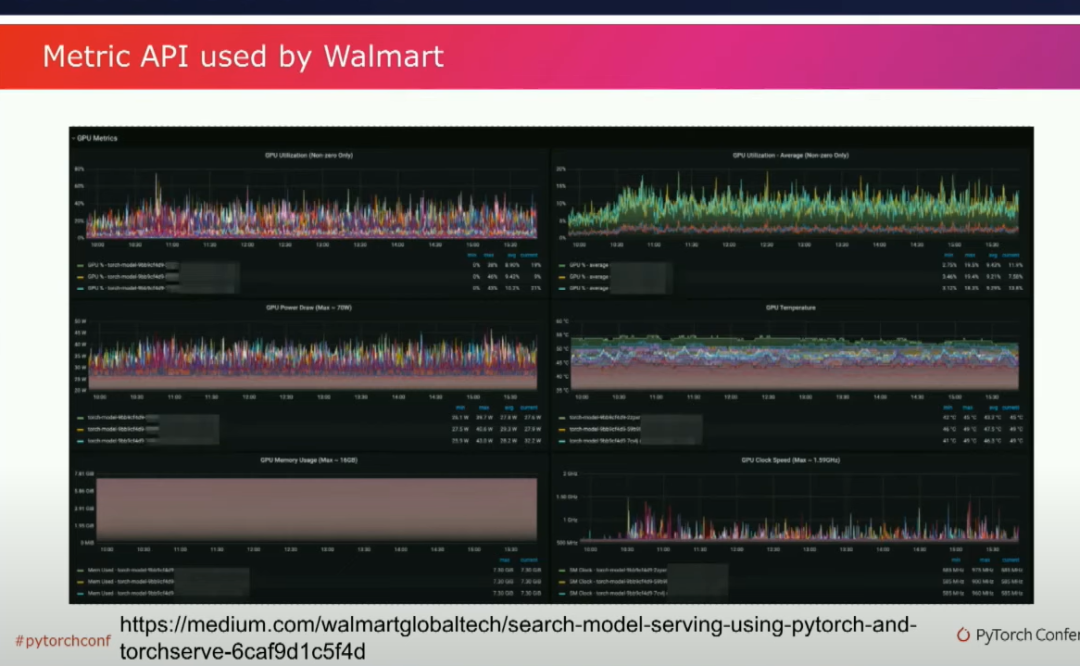
一、你知道的,有一個隱藏的技巧。嗯,PyTorch Geometric也談到了類似的優化方法應用于他們的GNN工作負載中。所以這是我強烈推薦的一點。我們還討論了很多關于主動測量模型性能的事情,最近AWS添加了一個新的指標API。你可以在你的Python代碼中添加一些儀器,指定這是什么樣的指標?是一個計數器嗎?是一個量規嗎?然后你就可以得到一個看起來很酷的科幻儀表盤。

這是一個來自沃爾瑪搜索團隊的儀表盤示例,他們一直在使用TorchServe來擴展他們的搜索,并且效果很好。這很酷,因為沃爾瑪是世界上最大的公司之一,他們是世界上最大的雇主。對于他們來說,使用TorchServe和Python進行擴展工作真的很不錯。
我很高興地看到TorchServe運行得非常順利。所以,現在來做一個總結,我感到很幸運的是,TorchServe現在成為了SageMaker、Vertex、MLflow和Kubeflow這些平臺上服務PyTorch模型的默認方法。它已經成功地為沃爾瑪、Navver和亞馬遜廣告等工作負載提供服務。雖然我站在這里講演,但這真的是META、AWS和最近的英特爾團隊之間的眾多優秀人士的合作成果。謝謝。
審核編輯:湯梓紅
-
gpu
+關注
關注
28文章
4729瀏覽量
128892 -
服務器
+關注
關注
12文章
9123瀏覽量
85331 -
HTTP
+關注
關注
0文章
504瀏覽量
31197 -
模型
+關注
關注
1文章
3226瀏覽量
48809 -
pytorch
+關注
關注
2文章
808瀏覽量
13201
原文標題:《PytorchConference2023 翻譯系列》17-讓pytroch模型更快速投入生產的方法——torchserve
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論