 使用基于Transformers的API在CPU上實現LLM高效推理
使用基于Transformers的API在CPU上實現LLM高效推理
英特爾 Extension for Transformers 是什么?
英特爾 Extension for Transformers是英特爾推出的一個創新工具包,可基于英特爾 架構平臺,尤其是第四代英特爾 至強 可擴展處理器(代號 SapphireRapids,SPR)顯著加速基于Transformers的大語言模型( LargeLanguageModel,LLM)。其主要特性包括:
通過擴展 Hugging Face transformers API 和利用英特爾 Neural Compressor,為用戶提供無縫的模型壓縮體驗; 提供采用低位量化內核(NeurIPS 2023:在 CPU 上實現高效 LLM 推理)的 LLM 推理運行時,支持 Falcon、 LLaMA、MPT、 Llama2、 BLOOM、 OPT、 ChatGLM2、GPT-J-6B、Baichuan-13B-Base、Baichuan2-13B-Base、Qwen-7B、Qwen-14B 和 Dolly-v2-3B 等常見的 LLM; 先進的壓縮感知運行時(NeurIPS 2022:在 CPU 上實現快速蒸餾 和 QuaLA-MiniLM:量化長度自適應 MiniLM;NeurIPS 2021:一次剪枝,一勞永逸:對預訓練語言模型進行稀疏/剪枝)。
本文將重點介紹其中的 LLM 推理運行時(簡稱為“LLM 運行時”),以及如何利用基于 Transformers 的 API 在英特爾 至強 可擴展處理器上實現更高效的 LLM 推理和如何應對 LLM 在聊天場景中的應用難題。
01LLM 運行時 (LLM Runtime)
英特爾 Extension for Transformers 提供的 LLM Runtime 是一種輕量級但高效的 LLM 推理運行時,其靈感源于 GGML ,且與 llama.cpp 兼容,具有如下特性:
內核已針對英特爾 至強 CPU 內置的多種 AI 加速技術(如 AMX、VNNI),以及 AVX512F 和 AVX2 指令集進行了優化 ;
可提供更多量化選擇,例如:不同的粒度(按通道或按組)、不同的組大小(如:32/128);
擁有更優的 KV 緩存訪問以及內存分配策略;
具備張量并行化功能,可助力在多路系統中進行分布式推理。
LLM Runtime 的簡化架構圖如下:
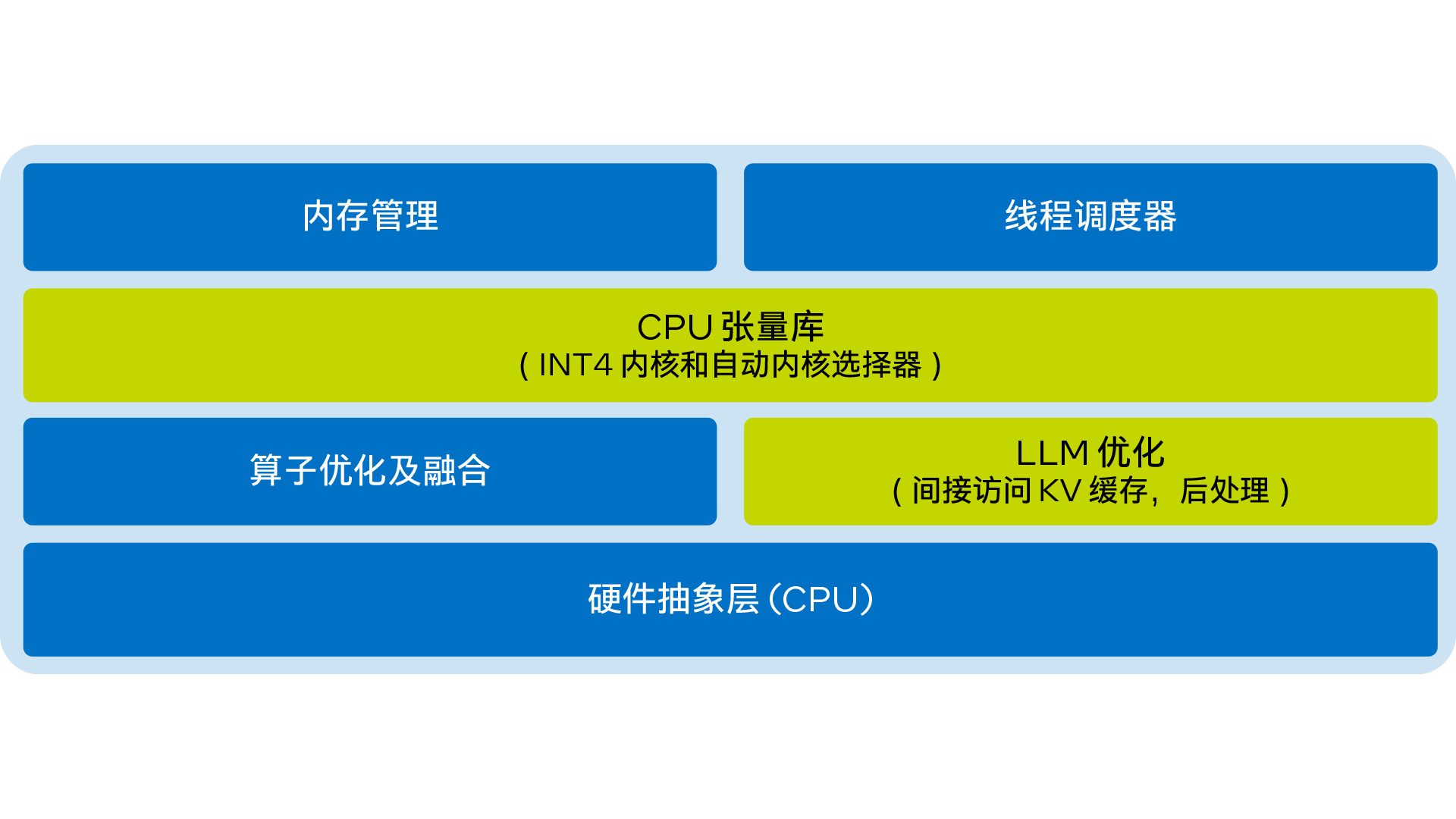
圖 1. 英特爾 Extension for Transformers 的 LLM Runtime 簡化架構圖
02使用基于 Transformers 的 API
在 CPU 上實現 LLM 高效推理
只需不到 9 行代碼,即可讓您在 CPU 上實現更出色的 LLM 推理性能。用戶可以輕松地啟用與 Transformers 類似的 API 來進行量化和推理。只需將 ‘load_in_4bit’ 設為 true,然后從 HuggingFace URL 或本地路徑輸入模型即可。下方提供了啟用僅限權重的 (weight-only) INT4 量化的示例代碼:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM model_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl," tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer) model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True) outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
默認設置為:將權重存儲為 4 位,以 8 位進行計算。但也支持不同計算數據類型 (dtype) 和權重數據類型組合,用戶可以按需修改設置。下方提供了如何使用這一功能的示例代碼:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig model_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl," woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4") tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer) model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=woq_config) outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
03性能測試
經過持續努力,上述優化方案的 INT4 性能得到了顯著提升。本文在搭載英特爾 至強 鉑金 8480+ 的系統上與 llama.cpp 進行了性能比較;系統配置詳情如下:@3.8 GHz,56 核/路,啟用超線程,啟用睿頻,總內存 256 GB (16 x 16 GB DDR5 4800 MT/s [4800 MT/s]),BIOS 3A14.TEL2P1,微代碼 0x2b0001b0,CentOS Stream 8。
當輸入大小為 32、輸出大小為 32、beam 為 1 時的推理性能測試結果,詳見下表:
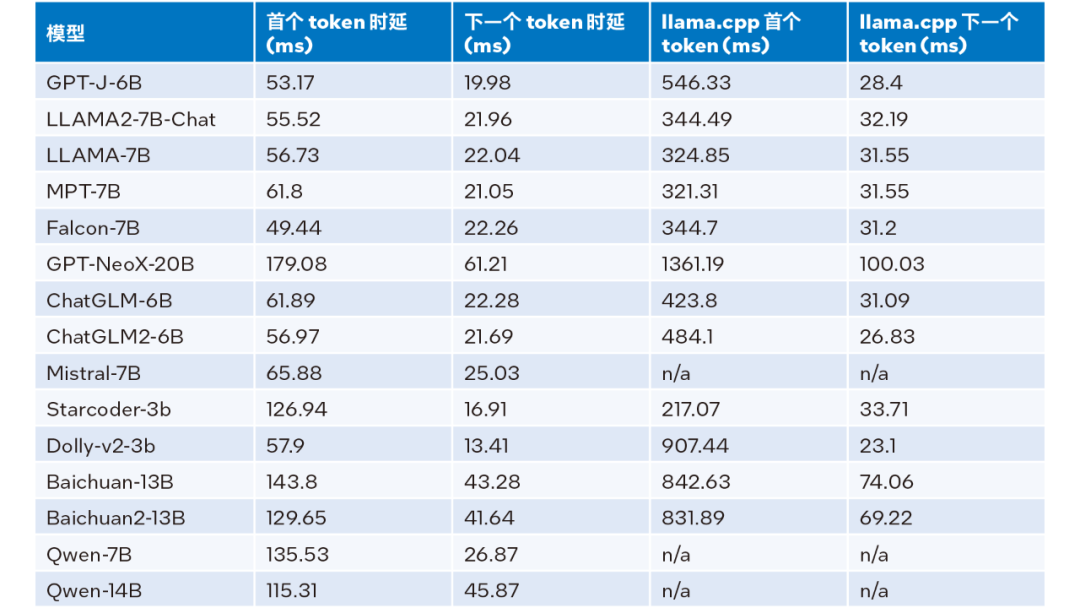
表 1. LLM Runtime 與 llama.cpp 推理性能比較(輸入大小 = 32,輸出大小 = 32, beam = 1)
輸入大小為 1024、輸出大小為 32、beam 為 1 時的推理性能的測試結果,詳見下表:
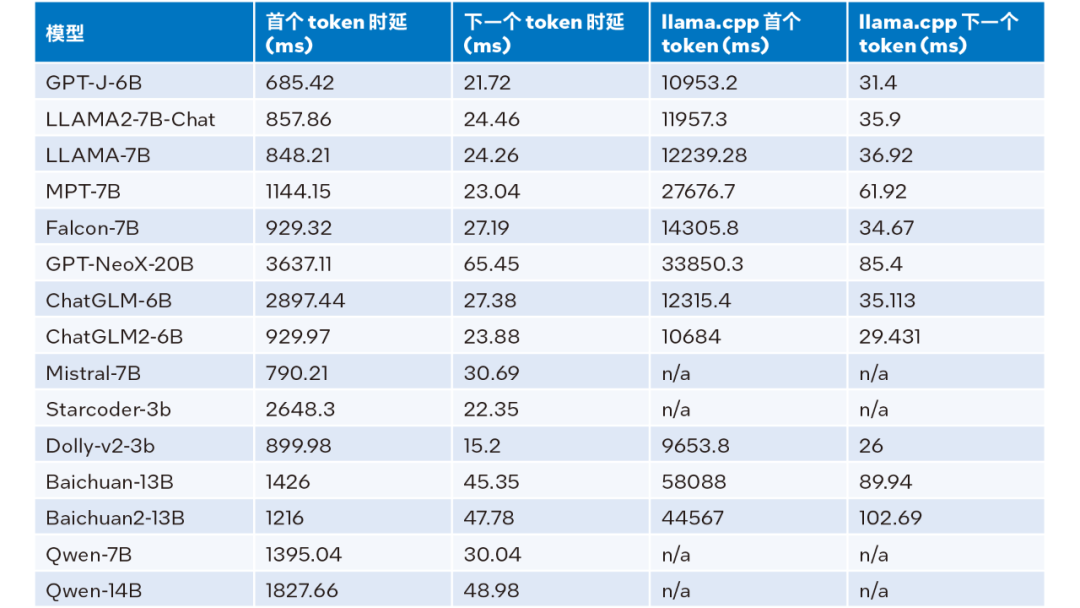
表 2. LLM Runtime 與 llama.cpp 推理性能比較(輸入大小 = 1024,輸出大小 = 32, beam = 1)
根據上表 2 可見:與同樣運行在第四代英特爾 至強 可擴展處理器上的 llama.cpp 相比,無論是首個 token 還是下一個 token,LLM Runtime都能顯著降低時延,且首個 token 和下一個 token 的推理速度分別提升多達 40 倍1(Baichuan-13B,輸入為 1024)和 2.68 倍2(MPT-7B,輸入為 1024)。llama.cpp 的測試采用的是默認代碼庫。
而綜合表 1 和表 2 的測試結果,可得:與同樣運行在第四代英特爾 至強 可擴展處理器上的 llama.cpp 相比,LLM Runtime 能顯著提升諸多常見 LLM 的整體性能:在輸入大小為 1024 時,實現 3.58 到 21.5 倍的提升;在輸入大小為 32 時,實現 1.76 到 3.43 倍的提升3。
04準確性測試
英特爾 Extension for Transformers 可利用英特爾 Neural Compressor 中的 SignRound、RTN 和 GPTQ 等量化方法,并使用 lambada_openai、piqa、winogrande 和 hellaswag 數據集驗證了 INT4 推理準確性。下表是測試結果平均值與 FP32 準確性的比較。
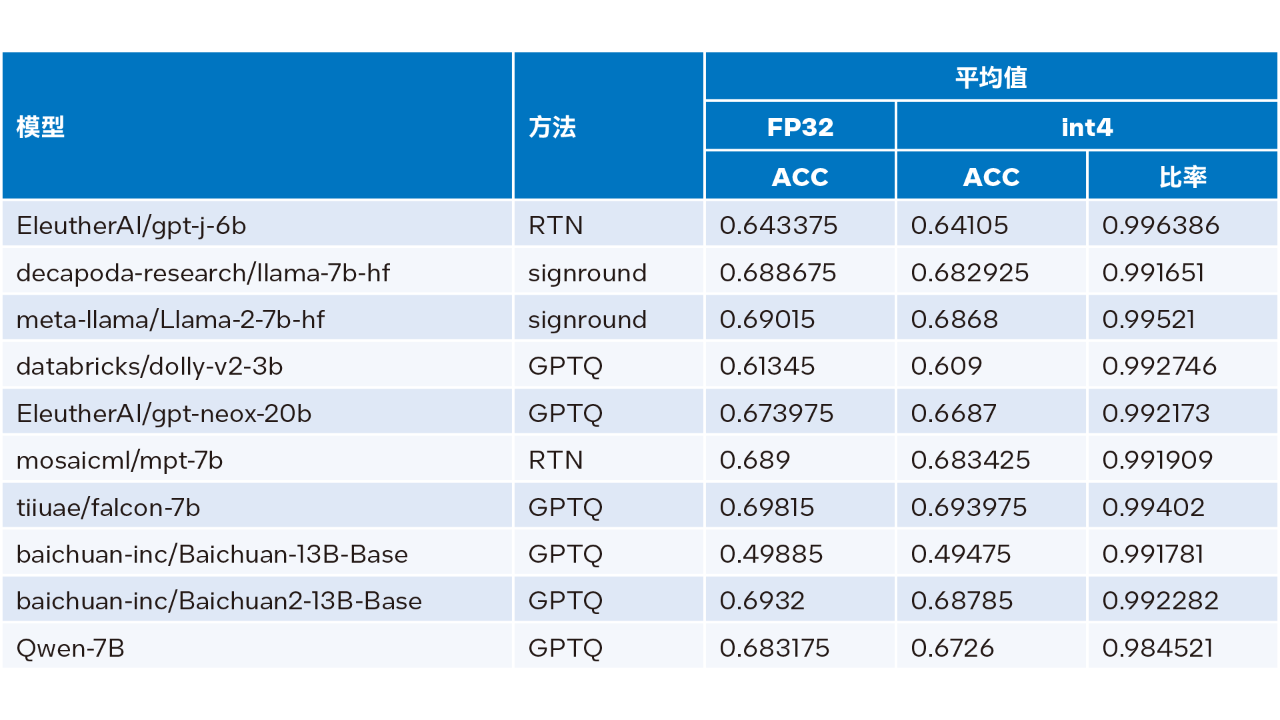
表 3. INT4 與 FP32 準確性對比
從上表 3 可以看出,多個模型基于 LLM Runtime 進行的 INT4 推理準確性損失微小,幾乎可以忽略不記。我們驗證了很多模型,但由于篇幅限制此處僅羅列了部分內容。如您欲了解更多信息或細節,請訪問此鏈接:https://medium.com/@NeuralCompressor/llm-performance-of-intel-extension-for-transformers-f7d061556176。
05更先進的功能:滿足 LLM 更多場景應用需求
同時,LLM Runtime 還具備雙路 CPU 的張量并行化功能,是較早具備此類功能的產品之一。未來,還會進一步支持雙節點。
然而,LLM Runtime 的優勢不僅在于其更出色的性能和準確性,我們也投入了大量的精力來增強其在聊天應用場景中的功能,并且解決了 LLM 在聊天場景中可能會遇到的以下應用難題:
01 對話不僅關乎 LLM 推理,對話歷史也很有用。
02 輸出長度有限:LLM 模型預訓練主要基于有限的序列長度。因此,當序列長度超出預訓練時使用的注意力窗口大小時,其準確性便會降低。
03 效率低下:在解碼階段,基于 Transformers 的 LLM 會存儲所有先前生成的 token 的鍵值狀態 (KV),從而導致內存使用過度,解碼時延增加。
關于第一個問題,LLM Runtime 的對話功能通過納入更多對話歷史數據以及生成更多輸出加以解決,而 llama.cpp 目前尚未能很好地應對這一問題。
關于第二和第三個問題,我們將流式 LLM (Steaming LLM) 集成到英特爾 Extension for Transformers 中,從而能顯著優化內存使用并降低推理時延。
06Streaming LLM
與傳統 KV 緩存算法不同,我們的方法結合了注意力匯聚 (Attention Sink)(4 個初始 token)以提升注意力計算的穩定性,并借助滾動 KV 緩存保留最新的 token,這對語言建模至關重要。該設計具有強大的靈活性,可無縫集成到能夠利用旋轉位置編碼 RoPE 和相對位置編碼 ALiBi 的自回歸語言模型中。
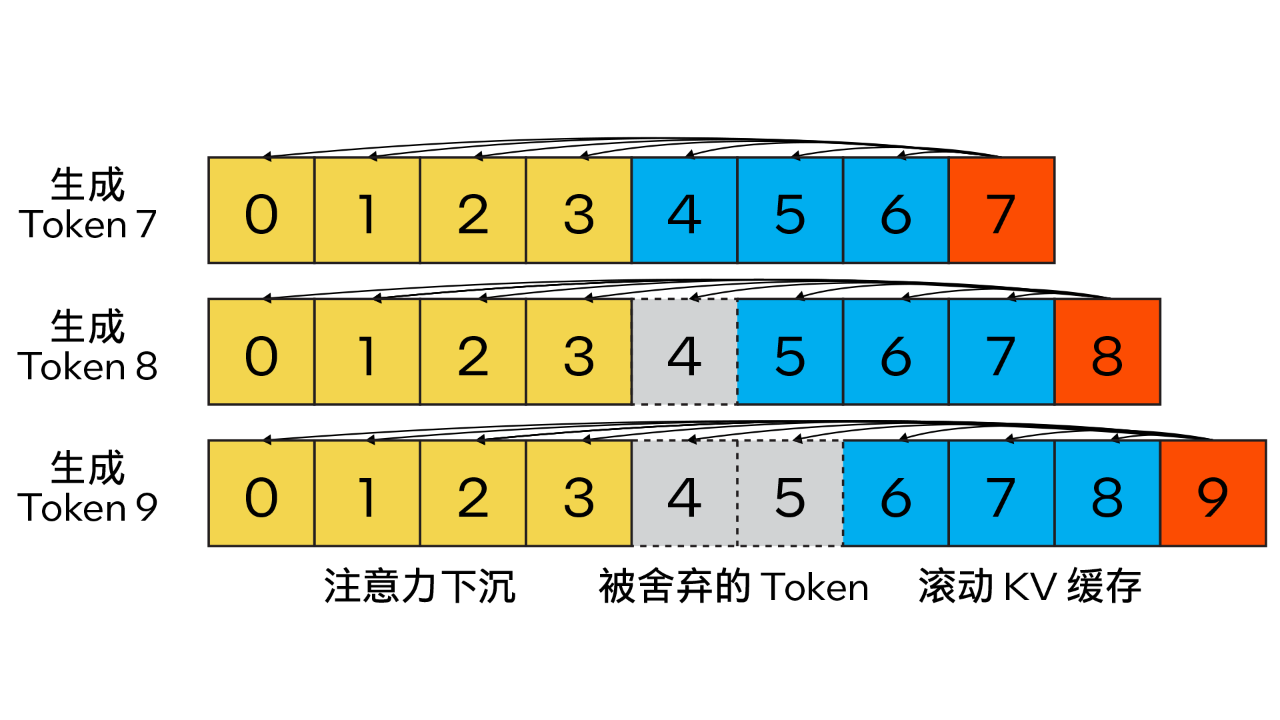
圖 2. Steaming LLM 的 KV 緩存(圖片來源:通過注意力下沉實現高效流式語言模型)
此外,與 llama.cpp 不同,本優化方案還引入了“n_keep”和“n_discard”等參數來增強 Streaming LLM 策略。用戶可使用前者來指定要在 KV 緩存中保留的 token 數量,并使用后者來確定在已生成的 token 中要舍棄的數量。為了更好地平衡性能和準確性,系統默認在 KV 緩存中舍棄一半的最新 token。
同時,為進一步提高性能,我們還將 Streaming LLM 添加到了 MHA 融合模式中。如果模型是采用旋轉位置編碼 (RoPE) 來實現位置嵌入,那么只需針對現有的 K-Cache 應用“移位運算 (shift operation)”,即可避免對先前生成的、未被舍棄的 token 進行重復計算。這一方法不僅充分利用了長文本生成時的完整上下文大小,還能在 KV 緩存上下文完全被填滿前不產生額外開銷。
“shift operation” 依賴于旋轉的交換性和關聯性,或復數乘法。例如:如果某個 token 的 K-張量初始放置位置為 m 并且旋轉了 m×θi for i∈0,d/2 ,那么當它需要移動到 m-1 這個位置時,則可以旋轉回到 -1×θi for i∈0,d/2 。這正是每次舍棄 n_discard 個 token 的緩存時發生的事情,而此時剩余的每個 token 都需要“移動” n_discard 個位置。下圖以 “n_keep = 4、n_ctx = 16、n_discard = 1”為例,展示了這一過程。
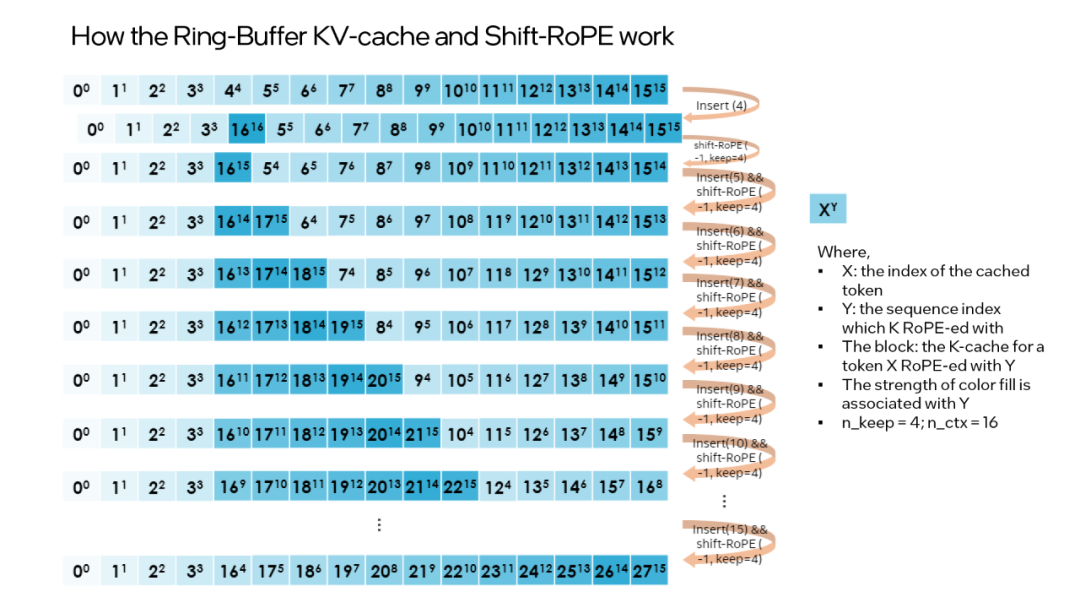
圖 3. Ring-Buffer KV-Cache 和 Shift-RoPE 工作原理
需要注意的是:融合注意力層無需了解上述過程。如果對 K-cache 和 V-cache 進行相同的洗牌,注意力層會輸出幾乎相同的結果(可能存在因浮點誤差導致的微小差異)。
您可通過以下代碼啟動 Streaming LLM:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4") prompt = "Once upon a time, a little girl" tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer) model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=woq_config, trust_remote_code=True) # Recommend n_keep=4 to do attention sinks (four initial tokens) and n_discard=-1 to drop half rencetly tokens when meet length threshold outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300, ctx_size=100, n_keep=4, n_discard=-1)
結論與展望
本文基于上述實踐經驗,提供了一個在英特爾 至強可擴展處理器上實現高效的低位 (INT4) LLM 推理的解決方案,并且在一系列常見 LLM 上驗證了其通用性以及展現了其相對于其他基于 CPU 的開源解決方案的性能優勢。未來,我們還將進一步提升 CPU 張量庫和跨節點并行性能。
歡迎您試用英特爾 Extension for Transformers,并在英特爾 平臺上更高效地運行 LLM 推理!也歡迎您向代碼倉庫 (repository) 提交修改請求 (pull request) 、問題或疑問。期待您的反饋!
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19259瀏覽量
229652 -
英特爾
+關注
關注
61文章
9949瀏覽量
171693 -
cpu
+關注
關注
68文章
10854瀏覽量
211580 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:英特爾? Extension for Transformers 讓 LLM CPU 推理加速達40x + 攻克聊天場景應用難題!
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
對比解碼在LLM上的應用
AI推理CPU當道,Arm驅動高效引擎

RK3399Pro上的Python api與RKNN C api推理速度一樣嗎
基于Tengine實現yolov4的cpu推理

如何實現高效的部署醫療影像推理
mlc-llm對大模型推理的流程及優化方案
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例

怎樣使用Accelerate庫在多GPU上進行LLM推理呢?
自然語言處理應用LLM推理優化綜述

解鎖LLM新高度—OpenVINO? 2024.1賦能生成式AI高效運行
基于CPU的大型語言模型推理實驗

LLM大模型推理加速的關鍵技術
基于Arm平臺的服務器CPU在LLM推理方面的能力
在設備上利用AI Edge Torch生成式API部署自定義大語言模型






 工商網監
工商網監
評論