 高階自動駕駛,需要一顆什么樣的芯片?
高階自動駕駛,需要一顆什么樣的芯片?
與往屆一樣,2024 年 CES 的芯片專區也開啟了神獸亂斗模式。
一個更加顯著的特征是,芯片戰場已經從 PC、智能手機轉移到了智能汽車。
無論是以英偉達為代表的從游戲起家的老牌芯片廠商,還是以安霸為代表的視覺芯片廠商,都在加碼投入到智能汽車自動駕駛芯片的競爭中。
兩年前,在 CES 上芯片廠商的關鍵詞是:期貨、百 Tops 算力。
2022 年 EyeQ Ultra 芯片算力也不過 176 TOPS,英偉達的自動駕駛計算架構 DRIVE Hyperion 9 內置的智能駕駛芯片 Atlan,以跳票告終。
而英偉達發布的另一款算力超 2000TOPS 的 Drive Thor,則要等到 2025 年才投產。
NVIDIA DRIVE Hyperion 9將內置芯片從Atlan換為Thor
兩年后,2024 年汽車市場中的芯片關鍵詞則圍繞高階自動駕駛展開:
性價比,大算力、BEV 算法、集中式架構。既要保證價格要能在紅海中出圈,又要保證硬件冗余、智駕領先,還要為中央集成式計算平臺做好準備。
尤其隨著中國車企卷起城區 NOA 大戰,**BEV+Transformer **成為頭部車企以及自動駕駛廠商最主流的技術方案,更大算力的芯片將承擔技術底座。
一個問題橫亙在前,高階自動駕駛,到底需要一顆什么樣的芯片?僅僅是大算力就夠了嗎?
高階自動駕駛恰好需要一顆「看不見」的芯片。
看不見說的是芯片制程必須更加先進,肉眼可觀察到的芯片體積正在縮小,同時也是芯片必須打通過去分布式架構的隔閡,放大芯片一體化、平臺化的優勢,向****中央計算架構更進一步。
過去,只能看到智駕芯片是算力為王的單邊競爭,堆砌足夠多的算力就能贏下一局,但高階智駕到來,看不見的芯片反而要面臨的挑戰爭奪——單邊競爭變成了關注性能指標、價格、團隊協同的多邊競爭。
一體化、大算力、先進制程決定了自動駕駛芯片的底層技術。
成本、性能、功耗決定了車企采用芯片的商業邏輯。
單芯片、強協同、平臺化決定了芯片廠商未來的技術發展方向。
隨著競爭要素的組合與變化,高階自動駕駛芯片正掀起新一輪競爭范式。
01
一體化、大算力、先進制程:
智駕芯片進入迭代新周期
如果說過去分布式走向域控制器的過程是靠一個復雜的域控黑盒完成的,那么到了高階自動駕駛逐漸向中央計算靠攏時,就得用單顆大算力智駕芯片取代盒子。
過去,由于大多數智駕 SoC 無法滿足高功能等級安全要求,往往還會在智駕域控主板上外掛獨立 MCU,英飛凌、瑞薩、NXP 的 MCU 都是搶手的香餑餑。
現在,多數 SoC 已經內置了 MCU 的功能安全島,而自動駕駛芯片的變化遠不止這一個細節。
業界將自動駕駛芯片的趨勢總結成三個關鍵詞:一體化、大算****力、先進制程。
隨著市場滲透率的快速提升和 ODD 持續拓展,芯片廠商已普遍采用能力均衡的異構計算平臺應對復雜場景考驗。
如果過去廚師做是井然有序的川菜、江浙菜、魯菜,那么今天 GPU、CPU、NPU、ISP 等不同 IP 模塊協同作戰才是主流,相當于廚師做出了「新式融合菜」。
融合就是取不同處理器所長之處組合在一個芯片中,比如 CPU 擅長邏輯控制和通用計算,GPU 適合大規模并行計算和圖像處理,NPU 專注于深度學習算法和人工智能計算,DSP 功耗低,MCU 則安全等級更高。
那么異構計算平臺發揮** 1+1+1>3 **的效果,應對多傳感器數據不同的計算能力和處理方式,滿足路徑規劃、物體識別、決策控制等不同應用和算法的計算需求。
據汽車之心了解,目前算力在 200TOPS 以上的自動駕駛芯片多采用異構計算,尤其是面向深度神經網絡,靠 CPU 一己之力遠遠不夠。
異構計算對芯片帶來的改變可以歸納為「兩降一提」。
一方面,能夠降低整體功耗和散熱需求。
另一方面,由于不同的處理器具有不同的故障模式和可靠性特性,通過組合也可以進一步提升系統容錯性。
在異構計算平臺的背景下,更大算力與更高制程成為必然。
大算力與更高制程呈正相關關系,算力越高也需要制程越先進。
換句話說,算力大小取決于芯片設計,而有著更大算力的芯片能否流片成功,則考驗晶圓和制造、封裝環節。
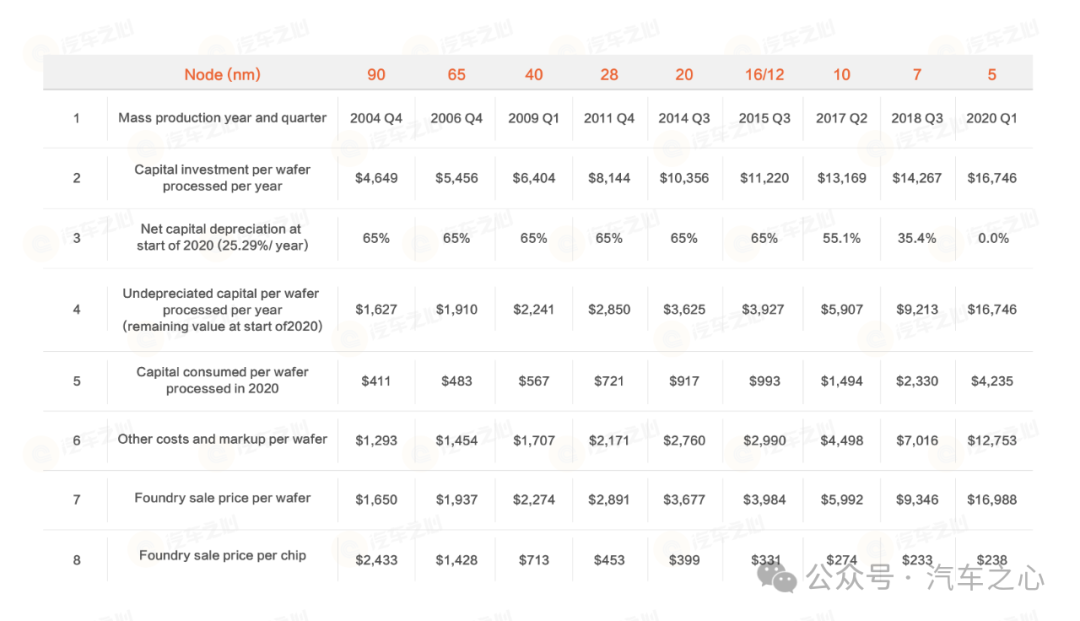
汽車之心梳理了現階段的市場情況,我們發現 2024—2025 年將會集中出現一批算力突破** 1000TOPS **的智駕芯片,相應的,5nm、3nm 乃至更先進制程將成為芯片角力的新戰場。
從目前已經釋放的大算力芯片來看,2025 年戰況焦灼:
英偉達 DRIVE Thor 算力 2000 TOPS,4nm 工藝制程,將于 2025 年投產。
蔚來自研神磯芯片算力預計超過 1000TOPS,5nm 工藝制程,將于 2025 年上車。
特斯拉更為激進,已經準備啟動 3nm 制程芯片代工計劃,在 N3E 基礎上繼續強化速度和功耗表現,預計 2024 年投產。

隨著芯片制程工藝不斷接近物理極限和工程極限,也使得面向 5nm 乃至 3nm 市場的單片晶圓及芯片設計成本同步指數級上升。
據臺積電最新報價,僅芯片流片中的制作晶圓費用 3nm 每片晶圓 19865 美元,折合人民幣** 14.2 萬**元。
而將芯片設計模版復制到半導體硅片上的掩模則更加昂貴。因此,臺積電 5nm 芯片全光罩流片費用過億不足為奇。
數據來源:The Information Network
一顆小小的智駕芯片,已經是車企、芯片廠商同臺秀技術的大舞臺。
往往,誰能造出制程更先進的異構智駕芯片,這意味著開發費用與技術實力都不缺。
02
成本、性能、功耗的平衡:
芯片從「不可能三角」到多要素耦合
一體化、大算力、先進制程說的都是技術命題,但智能芯片作為智能駕駛大腦,要投向商業化市場。
商業化市場最殘酷的命題是技術與成本的平衡。
因此,智駕芯片并不會不計成本地永遠突破性能上限。
以城市 NOA 為代表的 L2++轉而對大算力智駕芯片上車提出了多維度的精細要求。
業界期待高階智駕快速普及的另一面是全行業持續的降本壓力。
現階段,自動駕駛廠商其針對城區 NOA 解決方案也降至萬元以下,更不用提車企已經到了把錢掰兩半花的地步。
高階智能駕駛的前景一路坦途,目前 L2+已處在規模化爆發前夜,亟待在合理的性價比區間達到流暢的駕駛體驗,并在正式進軍城市場景前打好「重感知,輕地圖」的頭陣。
同時,隨著智駕進城,系統不僅需要應對各類復雜場景和偶發情況,脫圖的趨勢也加大了對于激光雷達的需求。
在此背景下,城市 NOA 的芯片方案還需要在高速 NOA 基礎上繼續全面升級。
更高算力的芯片雖呼之欲出,硬件資源搶占引發的更加嚴重的功耗、散熱問題同樣更加不容忽視,芯片的模塊化、拓展性、綜合性價比訴求也開始凸顯。
在行業內真實存在「搞不定散熱」的情況。
一家 Tier1 原來做一體機,后來為車企做行泊一體方案,干了半年發現無法在車企既有車型的預留小空間中搞定散熱,白費了半年時間。
現階段面向 L2+的芯片方案的痛點來源于方方面面,簡單概括是成本、算力、利用率、功耗、散熱、空間布置等要素間的選擇錯位:
算力層面:芯片性能虛高,但在實際應用中會碰到性能瓶頸;單芯片方案算力、ISP 普遍性能不足,導致難以充分調動多 V 傳感器實現 BEV 感知,跑得了 BEV 方案的成本又太高;
性能層面:雙芯片組合方案「貌合神離」,成本高、系統復雜,且難以做到真正的全時行泊一體;芯片就跑不了 BEV 難以最大程度擺脫高精度地圖,無法提升性價比;
結構層面:真實算力強的,功耗居高不下,散熱措施成問題,加風冷水冷不僅費工費時,在正式上車時還要搶占空間布置;
而以上任意≥2 個要素一旦互相組合出現,就非常容易衍生智駕項目開發的各類過程風險。
應對上述多要素耦合的迫切需求,2023 年,安霸在上海車展期間推出 CV72AQ,用這顆 5nm 車規制程芯片,打響高速 NOA 行泊一體之戰。
對一顆智駕芯片來說,最基本的要求是制程先進,算力真實。
CV72AQ 率先發揮 5nm 制程優勢,算力適中同時功耗小于 5 瓦,1 秒鐘處理** 90 幀 800 萬像素**的圖像,并實時處理 6 枚攝像頭輸入;
在芯片結構上改變了過去行業中的「雙芯」,采用單芯片設計,延續 ISP、視頻編碼器等傳統強項,直接面向全時行泊一體,硬件資源深度復用,高效運行各類 BEV;
最后在開發工具鏈上,安霸基于 CVflow AI 開發平臺提供一整套易用的算法開發和優化工具,降低產品設計開發成本的同時最大限度地提高軟件的可復用性。
如果說 SLAM 算法+深度學習技術是第一代自動駕駛技術,在傳感器類型與數量變得更加復雜時,如何持續輸入多模態數據成為第一代自動駕駛技術的挑戰。
隨之 BEV+Transformer 這樣全新的第二代自動駕駛技術襲來。
BEV+Transformer 憑借全局性的表征關聯、空間/時序的融合能力、跨模態的特征級融合效果為城市 NOA 落地敲開大門后,業界對智駕芯片做「多邊形戰士」的要求又增加了極為重要的一條:對先進算法的高效支持。

在芯片和算法都在快速迭代的當下,業界普遍的做法仍然是硬件優先——先確定一個各方面性能均衡的異構計算平臺,再基于硬件部署算法方案,進行優化、調度、通訊部署并逐步解決工程挑戰。
但是,新一輪 BEV+Transformer 帶來的卻是從算法滲透到芯片的變革壓力,解決兩者間耦合的錯配問題,與芯片本身的成本、性能、功耗平衡同樣迫切。
一個業內普遍的困擾是,目前市面上大部分的自動駕駛芯片均是在 Transformer 出現之前設計的,對 Transformer 的支持并不友好。
BEV+Transformer 越熱,就意味著不支持這一技術架構的芯片在未來的競爭中越有可能出局。
芯片廠商及車企接下來很可能在產品開發層面馬上進行適應性調整。
在此之前,業內已經普遍在積極尋求折中方案,包括但不限于算子的重新適配,深度的網絡架構和底層軟件優化,以及改善帶寬要求。
但這樣的針對性優化方案在小網絡上效果尚可,應對更大的算法模型,挑戰仍然不可持續。
安霸半導體副總裁劉清濤則表示,安霸雖然是一家芯片供應商,但一貫遵循「算法優先」策略,尤其是考慮到 AI 算法仍然在快速演進,因此在芯片開發過程中會廣泛測試和評估開源網絡和自研算法,評估當下主流神經網絡的同時超前考慮未來算法方向。
在 AI 域控制器芯片 CV3-AD 的開發過程中,安霸就測試了幾百種的開源算法,甚至整個芯片的開發都是圍繞著通用型算法進行的優化,包括對 Transformer 神經網絡進行了專門的支持。
這也是 CV3-AD 在更早前的 2022 年 CES 上發布,卻能支持后來流行的用于 BEV 的 Transformer 算法的根本原因。
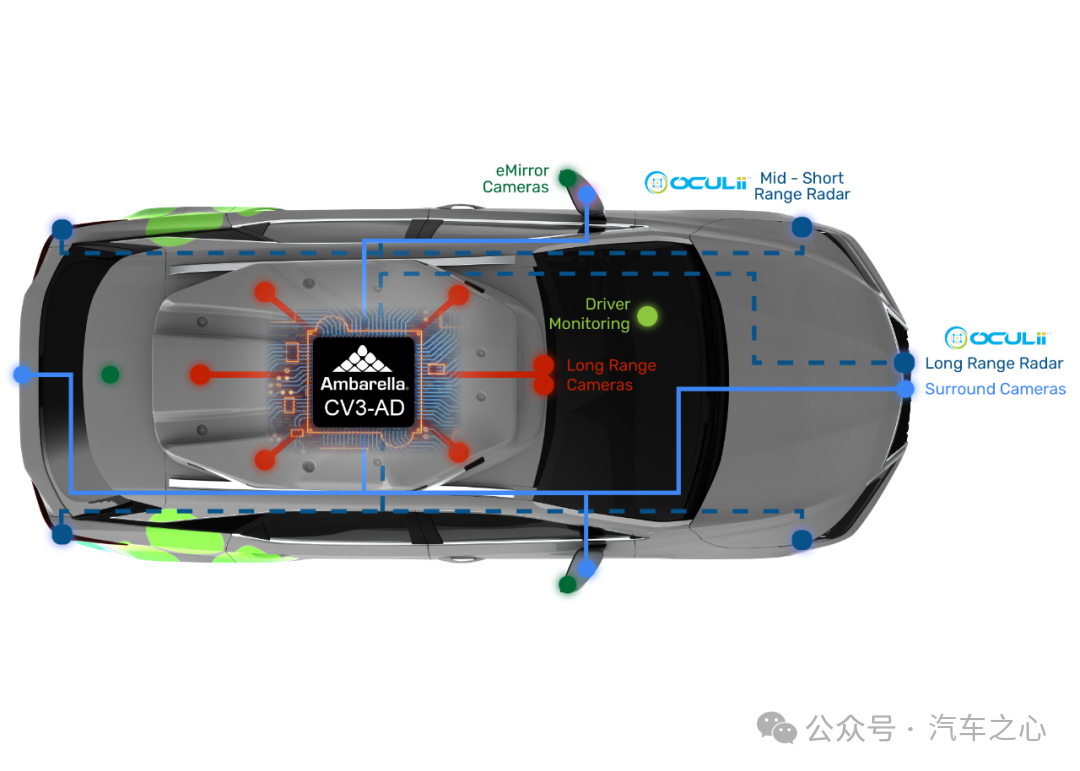
在今年的 CES 上,安霸發布了 CV3-AD 系列芯片的最新產品:
CV3-AD635和CV3-AD655。
其中,CV3-AD635 高效支持多個攝像頭及毫米波雷達,可實現主流的L2+ 自動駕駛功能,如高速公路自適應巡航和自動泊車;
CV3-AD655 支持更高等級的 L2++和城區自動駕駛功能,并高效支持更多的攝像頭、毫米波雷達、激光雷達和其他傳感器。
聯合此前發布的兩款芯片:
適用 L3/L4 自動駕駛系統的旗艦產品 CV3-AD685 和主打中國市場的 CV72AQ,CV3-AD 系列芯片算力覆蓋范圍廣,可以滿足汽車廠商從主流車型到中高端車型的算力要求。
在神經網絡處理能力方面,CV3-AD685 是 CV3-AD655 的** 3 倍**;CV3-AD655 是 CV3-AD635 的2 倍。
據安霸介紹,從 CV72AQ 到 CV3-AD685,芯片的 AI 性能提高到 18 倍,是目前「汽車行業中性能覆蓋范圍最廣的、兼容性最好的 AI 域控芯片系列」。

安霸芯片登上的量產車型
這背后是安霸自研的一套 AI 算法加速硬件引擎 CVflow——采用特殊的流架構、支持非結構化稀疏,內嵌多種非線性運算加速硬件,同時又和 ISP 集成在一起。
這帶來的好處是:在真實環境運行 Transformer 算法時 AI 性能、性能功耗比和內存帶寬效率優勢明顯。
03
單芯片、強協同、平臺化:
高階智駕芯片產業再升級
高階智駕芯片解決要素錯配,不是某一家企業能推動得了,而要靠汽車芯片產業技術路線再升級。
這一技術路線升級可以概括為:
單芯片、強協同、平臺****化。
過去,英偉達和 TI 分別在高算力、低算力芯片上占據多芯片行泊一體方案的半壁江山。
特別是前期面向高階智駕需求,算法的演進路徑尚不清晰的行業現象,車企們普遍先拼配置、做硬件預埋、準備系統冗余,雙 Orin 乃至 4 Orin 的方案率先成為主流方案。
這背后也存在一個原因——高階智駕滲透前期,通用芯片更受歡迎。
從芯片設計理念出發:
通用芯片無法為了沒有固化的業務作出靈活改變,比如 GPU、FPGA 是目前比較成熟的通用型芯片。通用芯片在設計之初會加入預留模塊,優點是通用性高、修改性強,但相應地功耗高、價格也更貴。
專有芯片是針對固化業務進一步「降本增效」,專用芯片針對單一功能設計,速度快、功耗低,相應成本也更低。
在高階智駕滲透前期,需要給芯片留出「試錯空間」,因此英偉達 Orin 系列芯片作為通用芯片大受歡迎。
但隨著高階智駕逐漸走向深水區,專用芯片則會成為必然趨勢。

比如安霸 CV3-AD 系列芯片就是專用芯片,支持各種網絡模型,大到 LLM(多模態大模型),小到各種嵌入式前端的網絡。
但專用芯片只是增本增效的第一步,單芯片方案對算力資源的深度復用及成本優勢,有望使其成為大算力域控的長遠終極方案。
相比于多芯片,單芯片如果匹配充足 AI 的算力支持及多源異構架構設計,可以滿足高階智駕所需的各類傳感器接入,與之匹配各類存儲器和帶寬需求并預留擴充接口,各類 buff 疊滿后相比多芯片有天然優勢:
傳感器深度復用,計算資源完全共享,AI 算力需求可比多芯片大幅降低;
不再需要與各自 SoC 配套的多套電源芯片和存儲芯片,更具成本優勢;
芯片級穩定性天然高于板級穩定性,兩套系統間交互衍生的開發難度和開發成本也不復存在。
安霸半導體副總裁劉清濤表示,多芯片只是權宜之計,從成本上來說雙芯片要兩套電源,從穩定性來說,單芯片級別的穩定性與連接板級別的穩定性不可同日而語。
眼下,以安霸為代表的單芯片行泊一體方案均已陸續登場,志在單顆芯片包打全場景 NOA。
在高階智駕開發中,芯片和算法的關系已完全不同于傳統的邏輯計算架構。
如果說過去兩者的關系是芯片先行,算法在后,那今天,兩者的關系變成了相互定制。
芯片在設計之初,就需要考慮后續實際運行的先進算法架構,算法的設計過程既需要、也有極大機遇根據芯片硬件架構適配升級。
在此背景下,芯片公司做自動駕駛軟件的驅動力不斷凸顯,一方面為下一代 AI 芯片或 AI 引擎進行開展算法預研,更進一步改善芯片架構或微架構,推動部署優化,甚至打通是算法和芯片,提升可擴展性。
以英偉達、安霸為代表的芯片廠商,已經在軟硬協同、全棧優化方面動作頻頻。這些芯片廠商基本上都以「芯片+開發工具鏈」的形式給到客戶。
更有壓力的是,蔚來、理想、比亞迪等車企也都陸續向上游芯片自研摩拳擦掌。
安霸則根植于「算法優先」已先行一步,一方面在芯片開發過程中保持領先架構,同時作為一家 AI 視覺芯片公司,也一直在下一局關于「算法」的棋局。
一家企業的稟賦總是與其誕生背景息息相關。
過去,ISP、圖像處理、視頻壓縮編碼算法是安霸在消費、安防、汽車等領域的一貫長項,這決定了其在自動駕駛圖像視覺上天然的稟賦。
安霸先后的兩次收購動作則增強了其在自動駕駛算法的業務能力。
比如 2015 年收購 VisLab 后,安霸在硬件層面整合了自動駕駛感知算法。在 2021 年收購傲酷后,安霸吸納了大量 4D 毫米波雷達及融合算法。
一個案例是,安霸在 CV3 中就去掉雷達前端 DSP,用 GVP 專門處理雷達信息,實現原始數據集中處理和底層跨模態融合。
CV3 系列芯片是安霸算法先行的代表之作。
安霸的 CV3 系列芯片采用新一代 CVflow 架構,其中神經矢量處理器 NVP 通過對 Transformer 網絡進行硬件加速,支持 BEV+Transformer 算法更快落地。
業界對芯片的期待更是結構性的降本增效,從而系統支持智駕帶來的銷量紅利,在激烈競爭中突出重圍。
這也對芯片的「平臺化」提出了更高要求。
安霸 CV3 全系列統一 SDK,這意味著在一套硬件架構下實現算法、中間件、應用軟件等各層面遷移復用,從而覆蓋不同自動駕駛等級和各個智駕細分領域,釋放芯片的硬件潛力和利用效率,節約投入的同時縮短開發周期。
安霸總裁兼 CEO 王奉民曾表示,安霸已經把中國市場作為全球戰略重點,CV3 系列的首批收入也將來自中國。
現在,智駕芯片更像是智駕技術、車企定制化需求、再帶點營銷詞匯的內卷產物。
就像今天,我們說算力,有的廠商會用 GPU 的乘積累加矩陣運算算力來定義,有的廠商會在這個基礎上加上每秒圖像幀率 FPS 的數據。
但走上城區道路的高階智駕到底需要怎樣的芯片,除了以上總結的多個趨勢外,一個概念也會越發清晰:
高階智駕需要的芯片,不只在于芯片本身,更在于其是否能夠去偽存真,更加標準化深度參與智駕功能的開發。
這考驗的其實是「厚積薄發」的能力。
高階智駕市場是新一輪的牌局,而最適合高階智駕的芯片一定會在最卷的中國市場率先被驗證。
審核編輯:劉清
-
SoC芯片
+關注
關注
1文章
610瀏覽量
34905 -
視覺芯片
+關注
關注
1文章
44瀏覽量
11438 -
自動駕駛
+關注
關注
784文章
13787瀏覽量
166405 -
毫米波雷達
+關注
關注
107文章
1043瀏覽量
64349
原文標題:轉載 | 高階自動駕駛,需要一顆什么樣的芯片?
文章出處:【微信號:AMBARELLA_AMBA,微信公眾號:Ambarella安霸半導體】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
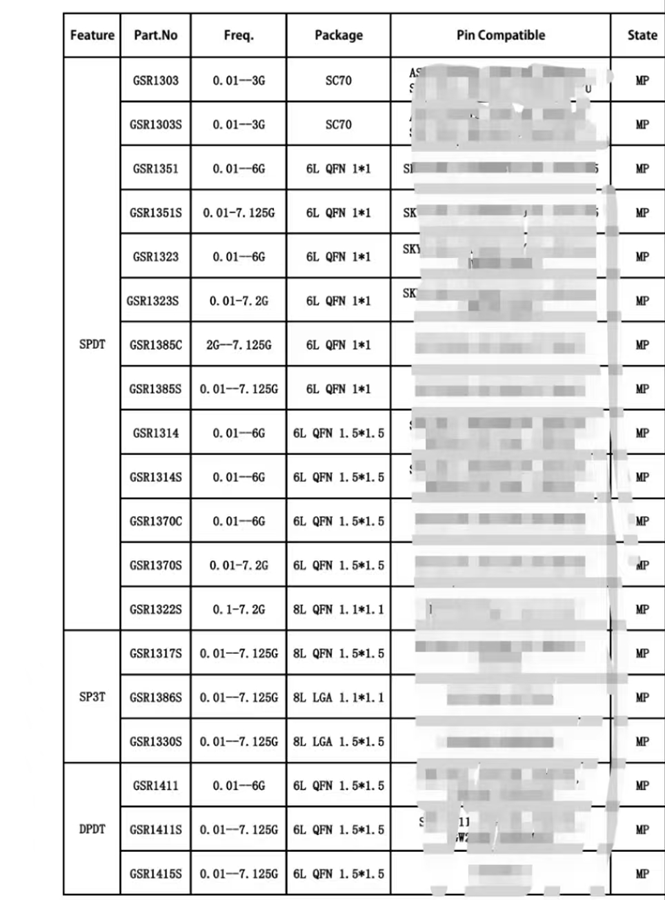
用一顆5G的204B接口DA芯片,DA芯片的輸入時鐘大小和輸入數據的速率是怎么樣的關系?
一文聊聊自動駕駛測試技術的挑戰與創新

一顆射頻開關的獨白

FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
普華基礎軟件與天準科技聯合發布新一代高階自動駕駛域控制器

Momenta推出基于NVIDIA DRIVE Orin芯片的高階智能駕駛解決方案
一顆改變了世界的芯片

未來已來,多傳感器融合感知是自動駕駛破局的關鍵
地平線開啟港交所IPO,加速高階自動駕駛新征程
高通自動駕駛靠軟件開發革新力壓英偉達自動駕駛芯片
華為自動駕駛技術怎么樣?
一顆來自40年前的透明芯片究竟暗藏了哪些奧秘





 工商網監
工商網監
評論