

近年來,我們聽說了很多關(guān)于Transformers的事情,并且在過去的幾年里,它們已經(jīng)在NLP領(lǐng)域取得了巨大成功。Transformers是一種使用注意力機制(Attention)顯著改進深度學習NLP翻譯模型性能的架構(gòu)。它首次在論文Attention is all you need中被引入,并迅速確立為大多數(shù)文本數(shù)據(jù)應(yīng)用的主導架構(gòu)。
自那時以來,包括Google的BERT和OpenAI的GPT系列在內(nèi)的眾多項目已經(jīng)在這個基礎(chǔ)上進行了擴展,并發(fā)布了比現(xiàn)有最先進基準更好的性能結(jié)果。
在一系列的文章中,我將介紹Transformers的基礎(chǔ)知識、其架構(gòu)以及內(nèi)部工作原理。我們將以自上而下的方式了解Transformers的功能。
在后續(xù)的文章中,我們將深入了解系統(tǒng)的運作細節(jié)。我們還將深入研究多頭注意力(multi-head attention)的運作,這是Transformers的核心。
以下是本系列和接下來文章的快速摘要(共計四篇)。我的目標是理解事物的運作方式,而不僅僅是了解它是如何運作的。
功能概述 — 本文(Transformers的用途以及為什么它們比RNN更好。架構(gòu)的組件,以及在訓練和推斷期間的行為)。
工作原理(內(nèi)部操作端到端。數(shù)據(jù)如何流動以及執(zhí)行了哪些計算,包括矩陣表示)。
多頭注意力(貫穿整個Transformers的注意力模塊的內(nèi)部運作)。
為什么注意力提高性能(不僅僅是注意力在做什么,而是為什么它如此有效)。
后面三篇推文進行介紹。
為適合中文閱讀習慣,閱讀更有代入感,原文翻譯后有刪改。
1. 什么是Transformers
Transformers架構(gòu)擅長處理本質(zhì)上是順序(sequential)的文本數(shù)據(jù)。它們將文本序列作為輸入并生成另一個文本序列作為輸出,例如將英語句子翻譯成西班牙語。
(作者提供的圖像)
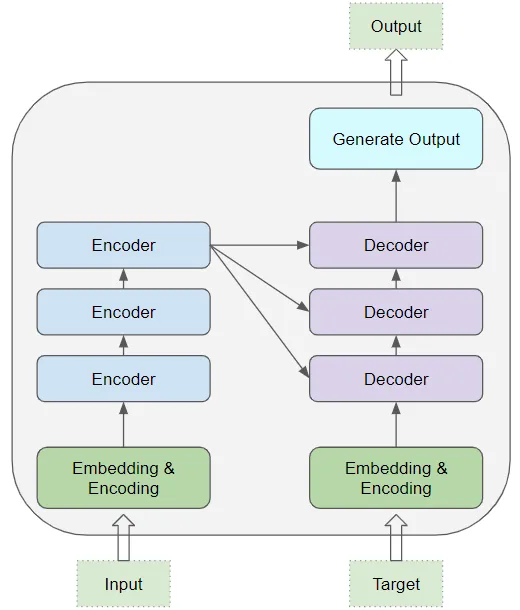
在其核心,它包含堆疊的編碼器層(Encoder layers)和解碼器層(Decoder layers)。
為避免混淆,我們將個體層稱為編碼器(Encoder)或解碼器(Decoder)。
編碼器堆棧和解碼器堆棧分別有相應(yīng)的嵌入層用于它們的輸入。最后,有一個輸出層用于生成最終輸出。
(作者提供的圖像)
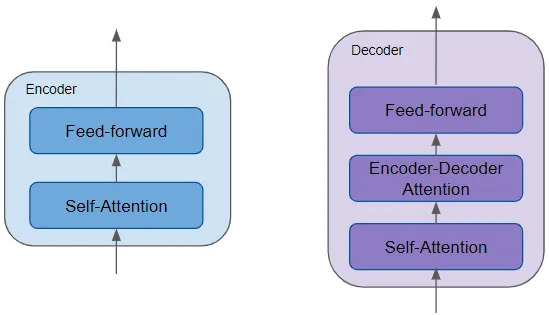
所有編碼器彼此相同。同樣,所有解碼器也是相同的。
(作者提供的圖像)
編碼器包含非常重要的自注意力層,用于計算序列中不同單詞之間的關(guān)系,以及一個前饋層。
解碼器包含自注意力層和前饋層,以及第二個編碼器-解碼器注意力層。
每個編碼器和解碼器都有自己的權(quán)重集。
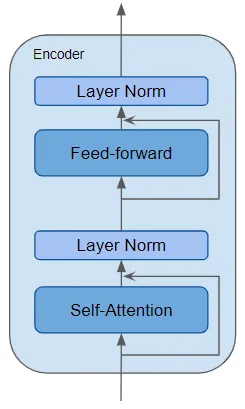
編碼器是所有Transformers架構(gòu)的定義性組件,是可重復使用的模塊。除了上述兩個層外,它還在這兩個層周圍具有殘差跳過連接(Residual skip connections),并帶有兩個LayerNorm層。
(作者提供的圖像)
Transformers架構(gòu)有許多變體。有些Transformers架構(gòu)根本沒有解碼器,完全依賴于編碼器。
2. 注意力的作用是什么?
Transformers取得突破性性能的關(guān)鍵在于它對注意力的使用。
在處理一個單詞時,注意力使模型能夠關(guān)注輸入中與該單詞密切相關(guān)的其他單詞。
例如,ball與blue和holding密切相關(guān)。另一方面,blue與boy無關(guān)。
Transformers架構(gòu)通過將輸入序列中的每個單詞與其他每個單詞相關(guān)聯(lián)來使用自注意力。
例如,考慮兩個句子:
The cat drank the milk because it was hungry.
The cat drank the milk because it was sweet.
在第一個句子中,it指的是cat,而在第二個句子中,它指的是milk。當模型處理it這個詞時,自注意力為模型提供更多關(guān)于其含義的信息,以便它能將it與正確的詞關(guān)聯(lián)起來。

深色表示更高的注意力(作者提供的圖像)
為了使其能夠處理關(guān)于句子意圖和語義的更多細微差別,Transformers為每個單詞包含多個注意力分數(shù)。
例如,在處理it這個詞時,第一個分數(shù)突出顯示cat,而第二個分數(shù)突出顯示hungry。因此,當它將it這個詞解碼成另一種語言時,它將在翻譯的詞中結(jié)合cat和hungry的一些方面。

(作者提供的圖像)
3. 訓練Transformers
在訓練和推斷期間,Transformers的工作稍有不同。
首先,讓我們看看訓練期間數(shù)據(jù)的流動。訓練數(shù)據(jù)包括兩個部分:
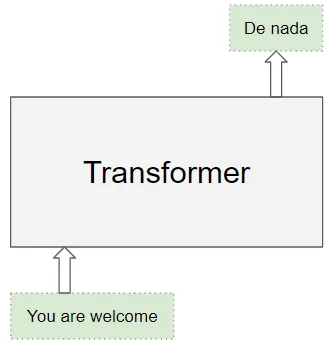
源序列或輸入序列(例如,對于一個翻譯問題,You are welcome是英語的源序列)
目標序列(例如,西班牙語中的De nada是目標序列)
Transformers的目標是通過使用輸入和目標序列來學習如何輸出目標序列。
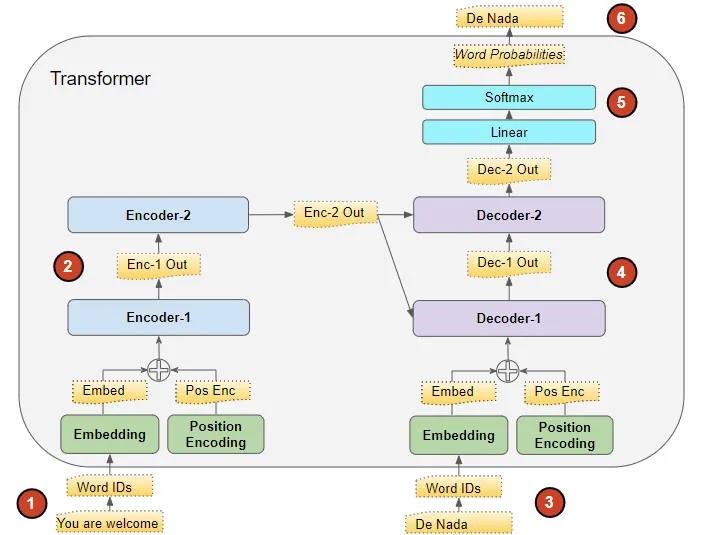
(作者提供的圖像)
Transformers處理數(shù)據(jù)的步驟如下:
將輸入序列轉(zhuǎn)換為嵌入(帶有位置編碼)并饋送到編碼器。
編碼器堆棧處理此數(shù)據(jù)并生成輸入序列的編碼表示。
目標序列以句子開始標記為前綴,轉(zhuǎn)換為嵌入(帶有位置編碼)并饋送到解碼器。
解碼器堆棧處理此數(shù)據(jù)以及編碼器堆棧的編碼表示,生成目標序列的編碼表示。
輸出層將其轉(zhuǎn)換為單詞概率和最終輸出序列。
Transformers的損失函數(shù)將此輸出序列與訓練數(shù)據(jù)中的目標序列進行比較。這個損失用于在反向傳播期間訓練Transformers生成梯度。
4. 推斷
在推斷期間,我們只有輸入序列,并沒有目標序列傳遞給解碼器。Transformers的目標是僅從輸入序列中產(chǎn)生目標序列。
因此,就像在Seq2Seq模型中一樣,我們在一個循環(huán)中生成輸出,并將上一個時間步的輸出序列饋送到下一個時間步的解碼器,直到遇到句子結(jié)束標記。
與Seq2Seq模型的不同之處在于,在每個時間步,我們重新饋送迄今生成的整個輸出序列,而不僅僅是最后一個單詞。
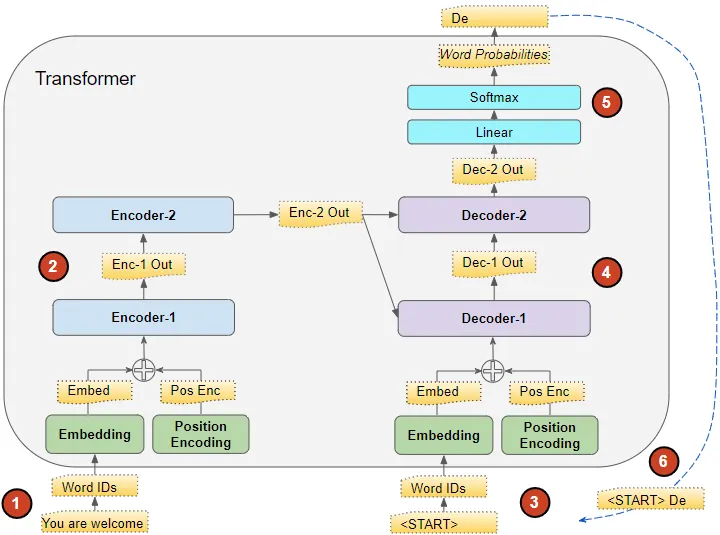
第一時間步后的推斷流程(圖像由作者提供)
推斷期間數(shù)據(jù)的流動如下:
輸入序列被轉(zhuǎn)換為嵌入(帶有位置編碼)并饋送到編碼器。
編碼器堆棧處理此數(shù)據(jù)并生成輸入序列的編碼表示。
與目標序列不同,我們使用一個只有句子開始標記的空序列。這被轉(zhuǎn)換為嵌入(帶有位置編碼)并饋送到解碼器。
解碼器堆棧處理此數(shù)據(jù)以及編碼器堆棧的編碼表示,生成目標序列的編碼表示。
輸出層將其轉(zhuǎn)換為單詞概率并生成輸出序列。
我們將輸出序列的最后一個詞視為預(yù)測的詞。該詞現(xiàn)在填入解碼器輸入序列的第二個位置,其中現(xiàn)在包含一個句子開始標記和第一個單詞。
返回到步驟#3。與以前一樣,將新的解碼器序列饋送到模型。然后取輸出的第二個詞并將其附加到解碼器序列。重復此過程,直到預(yù)測到句子結(jié)束標記。請注意,由于編碼器序列在每次迭代中不變,因此我們不必每次重復步驟#1和#2(感謝Michal Ku?írka指出這一點)。
5. Teacher Forcing(強制教師)
在訓練期間將目標序列饋送到解碼器的方法被稱為強制教師。我們?yōu)槭裁匆@樣做,這個術(shù)語是什么意思?
在訓練期間,我們本可以使用與推斷期間相同的方法。換句話說,循環(huán)運行Transformers,取輸出序列的最后一個詞,將其附加到解碼器輸入并在下一次迭代中饋送給解碼器。最終,當預(yù)測到句子結(jié)束標記時,損失函數(shù)將比較生成的輸出序列與目標序列,以便訓練網(wǎng)絡(luò)。
這種循環(huán)會導致訓練時間更長,而且使訓練模型變得更加困難。模型必須基于可能錯誤的第一個預(yù)測單詞來預(yù)測第二個單詞,依此類推。
相反,通過將目標序列饋送到解碼器,我們可以說是在給予它一些提示,就像老師會做的一樣。即使它預(yù)測了錯誤的第一個單詞,它仍然可以使用正確的第一個單詞來預(yù)測第二個單詞,以防這些錯誤不斷累積。
此外,Transformers能夠在沒有循環(huán)的情況下并行輸出所有單詞,從而大大加快訓練速度。
6. Transformers用于什么?
Transformers非常靈活,用于大多數(shù)NLP任務(wù),如語言模型和文本分類。它們經(jīng)常用于序列到序列模型,適用于機器翻譯、文本摘要、問答、命名實體識別和語音識別等應(yīng)用。
有不同類型的Transformers架構(gòu)用于解決不同的問題。基本的編碼器層被用作這些架構(gòu)的通用構(gòu)建塊,具體取決于正在解決的問題,使用不同的應(yīng)用特定的頭(heads)。
7. Transformers分類架構(gòu)
例如,情感分析應(yīng)用將接受文本文檔作為輸入。分類頭采用Transformers的輸出,并生成類標簽的預(yù)測,如積極或消極情感。
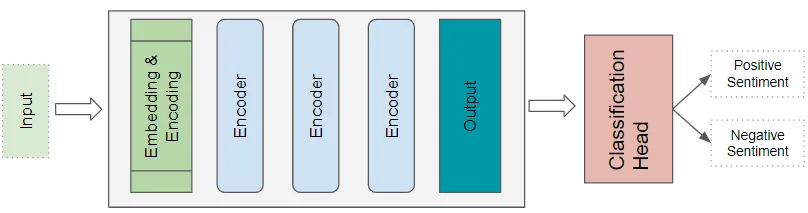
(作者提供的圖像)
8. Transformers語言模型架構(gòu)
語言模型架構(gòu)將輸入序列的初始部分,如文本句子,作為輸入,并通過預(yù)測將跟隨的句子生成新文本。語言模型頭采用Transformers的輸出,并為詞匯表中的每個單詞生成概率。概率最高的單詞成為下一個句子中的預(yù)測輸出。
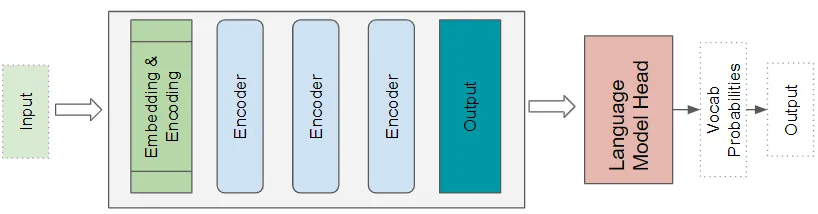
(作者提供的圖像)
9. 它們?yōu)槭裁幢妊h(huán)神經(jīng)網(wǎng)絡(luò)(RNNs)更好?
在Transformers出現(xiàn)并取代它們之前,基于RNN的序列到序列模型是所有NLP應(yīng)用的事實標準,而且表現(xiàn)良好。
基于RNN的序列到序列模型表現(xiàn)不錯,當注意機制首次引入時,它被用于增強其性能。
然而,它們有兩個限制:
難以處理在長句中分散分開的單詞之間的長程依賴關(guān)系。
它們按照順序逐個單詞地處理輸入序列,這意味著在完成時間步t-1的計算之前,它不能進行時間步t的計算。這減緩了訓練和推斷的速度。
順便提一下,使用CNN,所有輸出可以并行計算,這使得卷積速度更快。然而,它們在處理長程依賴性方面也有局限性:
在卷積層中,只有能夠適應(yīng)內(nèi)核大小的圖像的部分(如果應(yīng)用于文本數(shù)據(jù),則是單詞)可以相互交互。對于相距較遠的項,您需要具有許多層的更深的網(wǎng)絡(luò)。Transformers架構(gòu)解決了這兩個限制。它完全摒棄了RNN,并僅依賴于注意力的好處。
它并行處理序列中的所有單詞,從而大大加快了計算速度。
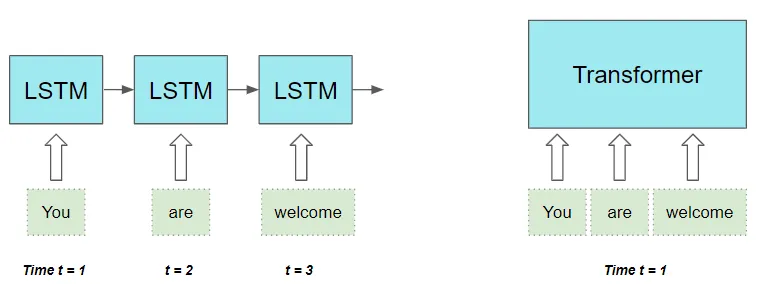
(作者提供的圖像)
輸入序列中單詞之間的距離不重要。它在計算相鄰單詞和相距較遠單詞之間的依賴性方面同樣出色。
現(xiàn)在我們對Transformers有了一個高層次的了解,我們可以在下一篇文章中深入了解其內(nèi)部功能,了解它的工作細節(jié)。
來源:新機器視覺
審核編輯:湯梓紅
-
編碼器
+關(guān)注
關(guān)注
45文章
3731瀏覽量
136179 -
模型
+關(guān)注
關(guān)注
1文章
3441瀏覽量
49648 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22343 -
OpenAI
+關(guān)注
關(guān)注
9文章
1191瀏覽量
7116
原文標題:【光電智造】Transformers圖解(第1部分):功能概述
文章出處:【微信號:今日光電,微信公眾號:今日光電】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
使用基于Transformers的API在CPU上實現(xiàn)LLM高效推理
長按鍵處理功能概述
W601的RTC時鐘功能概述
GPIO多功能復用引腳概述
GPIO的功能概述用途簡析
CS5202AN功能概述
BJDEEN PULSE TRANSFORMERS
深度學習:transformers的近期工作成果綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論