 Transformers.js 2.13、2.14 發布,新增8個新的架構
Transformers.js 2.13、2.14 發布,新增8個新的架構
8 個新的架構!這個版本支持了很多新的多模態架構,能夠支持的架構總數達到了 80 個!1.支持超過 1000 種語言的多語種文本轉語音的 VITS!(#466)
import { pipeline } from '@xenova/transformers';
// Create English text-to-speech pipeline
const synthesizer = await pipeline('text-to-speech', 'Xenova/mms-tts-eng');
// Generate speech
const output = await synthesizer('I love transformers');
// {
// audio: Float32Array(26112) [...],
// sampling_rate: 16000
// }
請參閱此處了解可用模型的列表。首先,我們在 Hugging Face Hub 上轉換了約 1140 個模型中的 12 個。如果其中沒有你想要的,可以使用我們的轉換腳本自行轉換。2. CLIPSeg 用于零樣本圖像分割。(#478)
import { AutoTokenizer, AutoProcessor, CLIPSegForImageSegmentation, RawImage } from '@xenova/transformers';
// Load tokenizer, processor, and model
const tokenizer = await AutoTokenizer.from_pretrained('Xenova/clipseg-rd64-refined');
const processor = await AutoProcessor.from_pretrained('Xenova/clipseg-rd64-refined');
const model = await CLIPSegForImageSegmentation.from_pretrained('Xenova/clipseg-rd64-refined');
// Run tokenization
const texts = ['a glass', 'something to fill', 'wood', 'a jar'];
const text_inputs = tokenizer(texts, { padding: true, truncation: true });
// Read image and run processor
const image = await RawImage.read('https://github.com/timojl/clipseg/blob/master/example_image.jpg?raw=true');
const image_inputs = await processor(image);
// Run model with both text and pixel inputs
const { logits } = await model({ ...text_inputs, ...image_inputs });
// logits: Tensor {
// dims: [4, 352, 352],
// type: 'float32',
// data: Float32Array(495616)[ ... ],
// size: 495616
// }
您可以按如下方式可視化預測結果:
const preds = logits
.unsqueeze_(1)
.sigmoid_()
.mul_(255)
.round_()
.to('uint8');
for (let i = 0; i < preds.dims[0]; ++i) {
const img = RawImage.fromTensor(preds[i]);
img.save(`prediction_${i}.png`);
}
| Original |
"a glass" |
"something to fill" |
"wood" |
"a jar" |
|---|---|---|---|---|
 |
 |
 |
 |
 |
請查看此處以獲取可用模型列表。
3. SegFormer 用于語義分割和圖像分類。(#480)
import { pipeline } from '@xenova/transformers';
// Create an image segmentation pipeline
const segmenter = await pipeline('image-segmentation', 'Xenova/segformer_b2_clothes');
// Segment an image
const url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/young-man-standing-and-leaning-on-car.jpg';
const output = await segmenter(url);

4. Table Transformer 用于從非結構化文檔中提取表格。(#477)
import { pipeline } from '@xenova/transformers';
// Create an object detection pipeline
const detector = await pipeline('object-detection', 'Xenova/table-transformer-detection', { quantized: false });
// Detect tables in an image
const img = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/invoice-with-table.png';
const output = await detector(img);
// [{ score: 0.9967531561851501, label: 'table', box: { xmin: 52, ymin: 322, xmax: 546, ymax: 525 } }]
5. DiT用于文檔圖像分類。(#474)
import { pipeline } from '@xenova/transformers';
// Create an image classification pipeline
const classifier = await pipeline('image-classification', 'Xenova/dit-base-finetuned-rvlcdip');
// Classify an image
const url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/coca_cola_advertisement.png';
const output = await classifier(url);
// [{ label: 'advertisement', score: 0.9035086035728455 }]
6. SigLIP用于零樣本圖像分類。(#473)
import { pipeline } from '@xenova/transformers';
// Create a zero-shot image classification pipeline
const classifier = await pipeline('zero-shot-image-classification', 'Xenova/siglip-base-patch16-224');
// Classify images according to provided labels
const url = 'http://images.cocodataset.org/val2017/000000039769.jpg';
const output = await classifier(url, ['2 cats', '2 dogs'], {
hypothesis_template: 'a photo of {}',
});
// [
// { score: 0.16770583391189575, label: '2 cats' },
// { score: 0.000022096000975579955, label: '2 dogs' }
// ]
7. RoFormer 用于蒙版語言建模、序列分類、標記分類和問題回答。(#464)
import { pipeline } from '@xenova/transformers';
// Create a masked language modelling pipeline
const pipe = await pipeline('fill-mask', 'Xenova/antiberta2');
// Predict missing token
const output = await pipe('? Q V Q ... C A [MASK] D ... T V S S');
8.分段任意模型 (SAM)
分段任意模型(SAM)可以在給定輸入圖像和輸入點的情況下,用于生成場景中對象的分割蒙版。請查看此處以獲取完整的預轉換模型列表。對該模型的支持已在#510中添加。
例子+源碼:https://huggingface.co/spaces/Xenova/segment-anything-web
示例:使用 Xenova/slimsam-77-uniform 執行掩模生成。
import { SamModel, AutoProcessor, RawImage } from '@xenova/transformers';
const model = await SamModel.from_pretrained('Xenova/slimsam-77-uniform');
const processor = await AutoProcessor.from_pretrained('Xenova/slimsam-77-uniform');
const img_url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/corgi.jpg';
const raw_image = await RawImage.read(img_url);
const input_points = [[[340, 250]]] // 2D localization of a window
const inputs = await processor(raw_image, input_points);
const outputs = await model(inputs);
const masks = await processor.post_process_masks(outputs.pred_masks, inputs.original_sizes, inputs.reshaped_input_sizes);
console.log(masks);
// [
// Tensor {
// dims: [ 1, 3, 410, 614 ],
// type: 'bool',
// data: Uint8Array(755220) [ ... ],
// size: 755220
// }
// ]
const scores = outputs.iou_scores;
console.log(scores);
// Tensor {
// dims: [ 1, 1, 3 ],
// type: 'float32',
// data: Float32Array(3) [
// 0.8350210189819336,
// 0.9786665439605713,
// 0.8379436731338501
// ],
// size: 3
// }
這樣可以將這三個預測蒙板可視化:
const image = RawImage.fromTensor(masks[0][0].mul(255));
image.save('mask.png');
| Input image | Visualized output |
|---|---|
|
|
|


接下來,選擇 IoU 分數最高的通道,在本例中是第二個(綠色)通道。將其與原始圖像相交,我們得到了該主題的孤立版本:
| Selected Mask | Intersected |
|---|---|
|
|
|


其他改進
-
修復了@Lian1230在#461中提交的關于Next.js Dockerfile的HOSTNAME 問題。
-
在#467中,在 README 中添加了空模板的鏈接。
-
在 #503 中添加對使用 ConvNextFeatureExtractor 處理非方形圖像的支持
-
通過 #507 對遠程 URL 中的修訂進行編碼
-
@Lian1230 在 #461 中進行了他們的首次貢獻。
改進#485中的pipeline函數的類型。感謝@wesbos提出的建議!
意味著當您將鼠標懸停在類名稱上時,您將獲得示例代碼來幫助您。
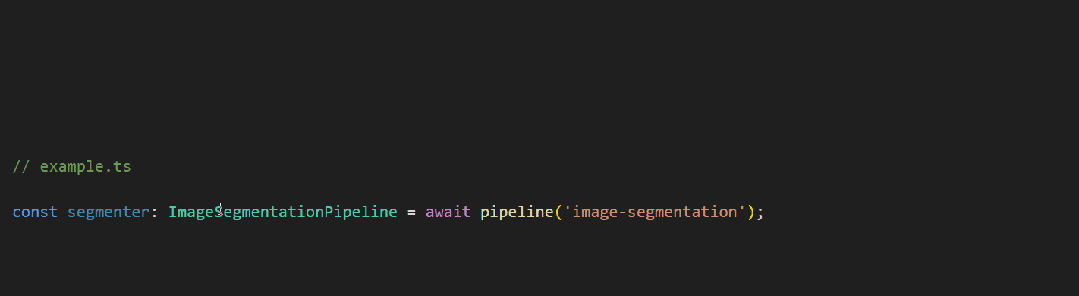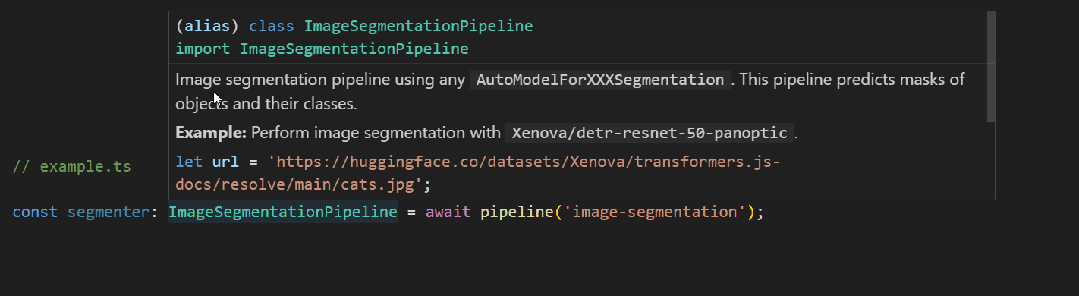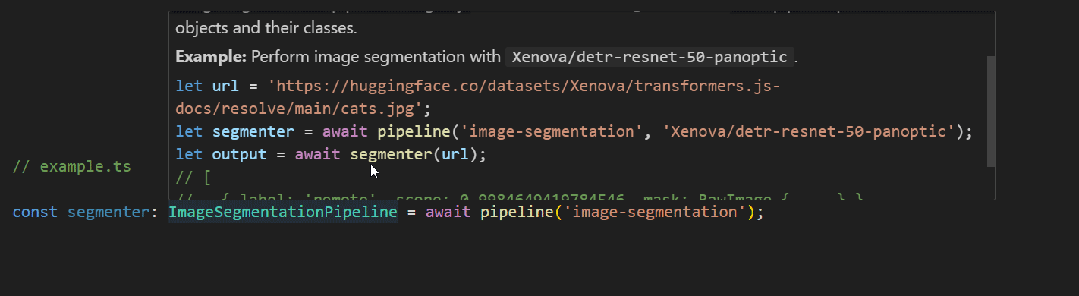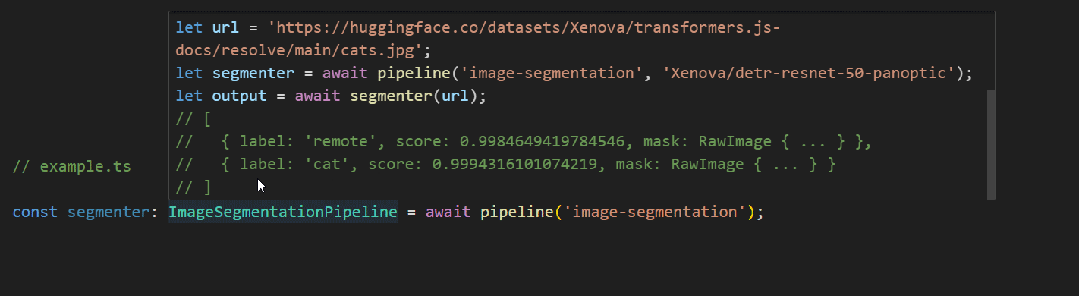
此版本是 #485 的后續版本,具有額外的以智能感知為中心的改進(請參閱 PR)。
添加對跨編碼器模型的支持(+修復令牌類型 ID)(#501)
示例:使用 Xenova/ms-marco-TinyBERT-L-2-v2 進行信息檢索。
import { AutoTokenizer, AutoModelForSequenceClassification } from '@xenova/transformers';
const model = await AutoModelForSequenceClassification.from_pretrained('Xenova/ms-marco-TinyBERT-L-2-v2');
const tokenizer = await AutoTokenizer.from_pretrained('Xenova/ms-marco-TinyBERT-L-2-v2');
const features = tokenizer(
['How many people live in Berlin?', 'How many people live in Berlin?'],
{
text_pair: [
'Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.',
'New York City is famous for the Metropolitan Museum of Art.',
],
padding: true,
truncation: true,
}
)
const { logits } = await model(features)
console.log(logits.data);
// quantized: [ 7.210887908935547, -11.559350967407227 ]
// unquantized: [ 7.235750675201416, -11.562294006347656 ]
-
源碼
+關注
關注
8文章
639瀏覽量
29185 -
模型
+關注
關注
1文章
3229瀏覽量
48810 -
架構
+關注
關注
1文章
513瀏覽量
25468
原文標題:Transformers.js 2.13、2.14 發布,新增 8 個新的架構
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
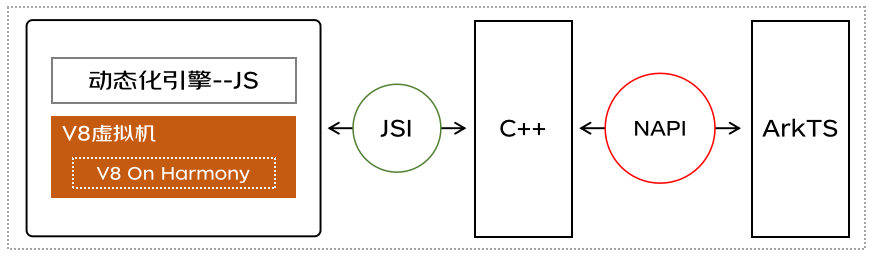
鴻蒙跨端實踐-JS虛擬機架構實現
使用基于Transformers的API在CPU上實現LLM高效推理
用戶管理-動態調用VI(新增用戶插件)
OpenHarmony 3.0 LTS 新增特性功能
94個JS/eTS開源組件首發上新,肯定有你要用的一款!
HarmonyOS 3.0 Beta版本說明
面向開發者的HarmonyOS 3.0 Beta發布
OpenHarmony 3.2 Beta2 版本發布:支持電源管理重啟恢復機制等
DevEco Studio 3.1 Beta1版本發布——新增六大關鍵特性,開發更高效
BJDEEN PULSE TRANSFORMERS
node.js的js要點總結
GPU-Z 2.26.0正式發布 新增對部分假冒顯卡核心的支持
安徽省已累計建設完成5G基站2.14萬個
Transformers的功能概述





 工商網監
工商網監
評論