


Prometheus 監(jiān)控業(yè)務指標
在 Kubernetes 已經(jīng)成了事實上的容器編排標準之下,微服務的部署變得非常容易。但隨著微服務規(guī)模的擴大,服務治理帶來的挑戰(zhàn)也會越來越大。在這樣的背景下出現(xiàn)了服務可觀測性(observability)的概念。
在分布式系統(tǒng)里,系統(tǒng)的故障可能出現(xiàn)在任何節(jié)點,怎么能在出了故障的時候快速定位問題和解決問題,甚至是在故障出現(xiàn)之前就能感知到服務系統(tǒng)的異常,把故障扼殺在搖籃里。這就是可觀測性的意義所在。
可觀測性
可觀測性是由 logging, metrics, tracing 構(gòu)建的, 簡稱為可觀測性三支柱。
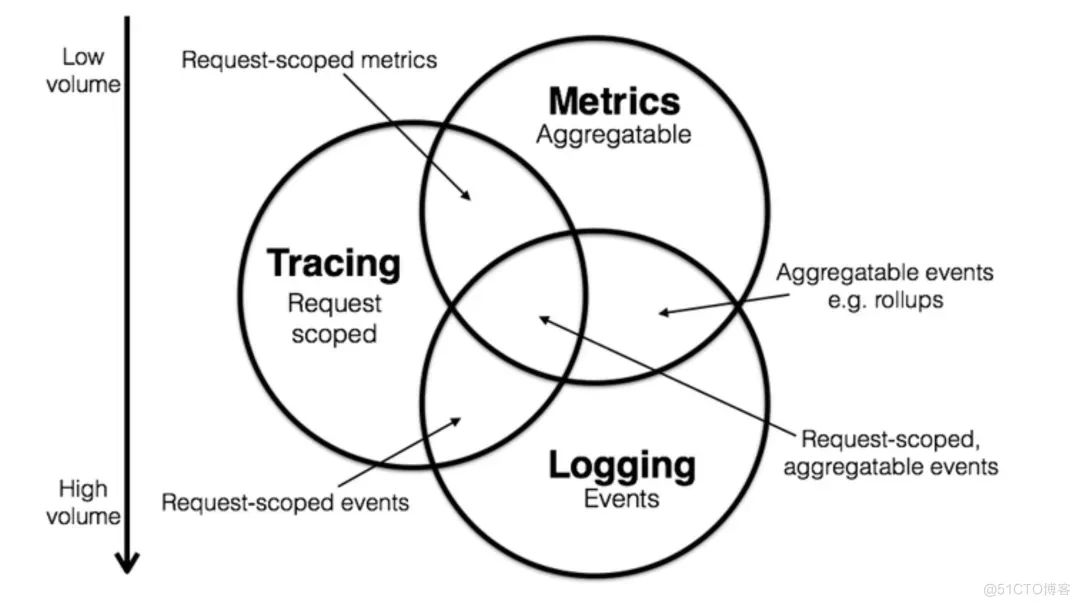
Lgging,展現(xiàn)的是應用運行而產(chǎn)生的事件或者程序在執(zhí)行的過程中間產(chǎn)生的一些日志,可以詳細解釋系統(tǒng)的運行狀態(tài),但是存儲和查詢需要消耗大量的資源。所以往往使用過濾器減少數(shù)據(jù)量。
Metrics,是一種聚合數(shù)值,存儲空間很小,可以觀察系統(tǒng)的狀態(tài)和趨勢,但對于問題定位缺乏細節(jié)展示。這個時候使用等高線指標等多維數(shù)據(jù)結(jié)構(gòu)來增強對于細節(jié)的表現(xiàn)力。例如統(tǒng)計一個服務的 TBS 的正確率、成功率、流量等,這是常見的針對單個指標或者某一個數(shù)據(jù)庫的。
Tracing,面向的是請求,可以輕松分析出請求中異常點,但與 logging 有相同的問題就是資源消耗較大。通常也需要通過采樣的方式減少數(shù)據(jù)量。比如一次請求的范圍,也就是從瀏覽器或者手機端發(fā)起的任何一次調(diào)用,一個流程化的東西,我們需要軌跡去追蹤。
這篇文章討論的主題就是可觀測性中的 metrics。在 k8s 作為基礎設施的背景下,我們知道 K8s 本身是個復雜的容器編排系統(tǒng),它本身的穩(wěn)定運行至關重要。與之相伴的指標監(jiān)控系統(tǒng) Promethues 也已經(jīng)成為了云原生服務下監(jiān)控體系的事實標準。
相信大家對資源層面比如 CPU,Memory,Network;應用層面比如 Http 請求數(shù),請求耗時等指標的監(jiān)控都有所了解。那么業(yè)務層面的指標又怎么利用 Prometheus 去監(jiān)控和告警呢?這就是這篇文章的核心內(nèi)容。
以我們一個業(yè)務場景為例,在系統(tǒng)中有多種類型的 task 在運行,并且 task 的運行時間各異,task 本身有各種狀態(tài)包括待執(zhí)行、執(zhí)行中、執(zhí)行成功、執(zhí)行失敗等。如果想確保系統(tǒng)的穩(wěn)定運行,我們必須對各個類型的 task 的運行狀況了如指掌。比如當前是否有任務擠壓,失敗任務是否過多,并且當超過閾值是否告警。
為了解決上述的監(jiān)控告警問題,我們先得了解一下 Prometheus 的指標類型
指標
指標定義
在形式上,所有的指標(Metric)都通過如下格式標示:
{
指標的名稱(metric name)可以反映被監(jiān)控樣本的含義(比如,http_request_total- 表示當前系統(tǒng)接收到的HTTP請求總量)。指標名稱只能由ASCII字符、數(shù)字、下劃線以及冒號組成并必須符合正則表達式[a-zA-Z_:][a-zA-Z0-9_:]*。
標簽(label)反映了當前樣本的特征維度,通過這些維度Prometheus可以對樣本數(shù)據(jù)進行過濾,聚合等。標簽的名稱只能由ASCII字符、數(shù)字以及下劃線組成并滿足正則表達式[a-zA-Z_][a-zA-Z0-9_]*。
指標類型
Prometheus定義了4種不同的指標類型(metric type):Counter(計數(shù)器)、Gauge(儀表盤)、Histogram(直方圖)、Summary(摘要)。
Counter
Counter類型的指標其工作方式和計數(shù)器一樣,只增不減(除非系統(tǒng)發(fā)生重置)。常見的監(jiān)控指標,如http_requests_total,node_cpu都是 Counter 類型的監(jiān)控指標。一般在定義Counter類型指標的名稱時推薦使用_total作為后綴。
通過 counter 指標我們可以和容易的了解某個事件產(chǎn)生的速率變化。
例如,通過rate()函數(shù)獲取HTTP請求量的增長率:
rate(http_requests_total[5m])
Gauge
Gauge類型的指標側(cè)重于反應系統(tǒng)的當前狀態(tài)。因此這類指標的樣本數(shù)據(jù)可增可減。常見指標如:node_memory_MemFree(主機當前空閑的內(nèi)容大小)、node_memory_MemAvailable(可用內(nèi)存大小)都是Gauge類型的監(jiān)控指標。
通過Gauge指標,我們可以直接查看系統(tǒng)的當前狀態(tài)
node_memory_MemFree
Summary
Summary 主用用于統(tǒng)計和分析樣本的分布情況。比如某 Http 請求的響應時間大多數(shù)都在 100 ms 內(nèi),而個別請求的響應時間需要 5s,那么這中情況下統(tǒng)計指標的平均值就不能反映出真實情況。而如果通過 Summary 指標我們能立馬看響應時間的9分位數(shù),這樣的指標才是有意義的。
例如
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 3.98e-05 go_gc_duration_seconds{quantile="0.25"} 5.31e-05 go_gc_duration_seconds{quantile="0.5"} 6.77e-05 go_gc_duration_seconds{quantile="0.75"} 0.0001428 go_gc_duration_seconds{quantile="1"} 0.0008099 go_gc_duration_seconds_sum 0.0114183 go_gc_duration_seconds_count 85
Histogram
Histogram 類型的指標同樣用于統(tǒng)計和樣本分析。與 Summary 類型的指標相似之處在于 Histogram 類型的樣本同樣會反應當前指標的記錄的總數(shù)(以_count作為后綴)以及其值的總量(以_sum作為后綴)。不同在于 Histogram 指標直接反應了在不同區(qū)間內(nèi)樣本的個數(shù),區(qū)間通過標簽len進行定義。同時對于Histogram的指標,可以通過histogram_quantile()函數(shù)計算出其值的分位數(shù)。
例如
# HELP prometheus_http_response_size_bytes Histogram of response size for HTTP requests.
# TYPE prometheus_http_response_size_bytes histogram
prometheus_http_response_size_bytes_bucket{handler="/",le="100"} 1
prometheus_http_response_size_bytes_bucket{handler="/",le="1000"} 1
prometheus_http_response_size_bytes_bucket{handler="/",le="10000"} 1
prometheus_http_response_size_bytes_bucket{handler="/",le="100000"} 1
prometheus_http_response_size_bytes_bucket{handler="/",le="1e+06"} 1
prometheus_http_response_size_bytes_bucket{handler="/",le="+Inf"} 1
prometheus_http_response_size_bytes_sum{handler="/"} 29
prometheus_http_response_size_bytes_count{handler="/"} 1
應用指標監(jiān)控
暴露指標
Prometheus 最常用的方式是通過 pull 去抓取 metrics。所以我們首先在服務通過/metrics接口暴露指標,這樣 Promethues server 就能通過 http 請求抓取到我們的業(yè)務指標。
接口示例
server := gin.New()
server.Use(middlewares.AccessLogger(), middlewares.Metric(), gin.Recovery())
server.GET("/health", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{ "message": "ok",
})
})
server.GET("/metrics", Monitor)func Monitor(c *gin.Context) {
h := promhttp.Handler()
h.ServeHTTP(c.Writer, c.Request)
}
定義指標
為了方便理解,這里選取了三種類型和兩種業(yè)務場景的指標
示例
var (
//HTTPReqDuration metric:http_request_duration_seconds
HTTPReqDuration *prometheus.HistogramVec
//HTTPReqTotal metric:http_request_total
HTTPReqTotal *prometheus.CounterVec
// TaskRunning metric:task_running
TaskRunning *prometheus.GaugeVec
)
func init() {
// 監(jiān)控接口請求耗時
// 指標類型是 Histogram
HTTPReqDuration = prometheus.NewHistogramVec(prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "http request latencies in seconds",
Buckets: nil,
}, []string{"method", "path"})
// "method"、"path" 是 label
// 監(jiān)控接口請求次數(shù)
// 指標類型是 Counter
HTTPReqTotal = prometheus.NewCounterVec(prometheus.CounterOpts{
Name: "http_requests_total",
Help: "total number of http requests",
}, []string{"method", "path", "status"}) // "method"、"path"、"status" 是 label
// 監(jiān)控當前在執(zhí)行的 task 數(shù)量
// 監(jiān)控類型是 Gauge
TaskRunning = prometheus.NewGaugeVec(prometheus.GaugeOpts{
Name: "task_running",
Help: "current count of running task",
}, []string{"type", "state"})
// "type"、"state" 是 label
prometheus.MustRegister(
HTTPReqDuration,
HTTPReqTotal,
TaskRunning,
)
}
通過上述的代碼我們就定義并且注冊了我們的想要監(jiān)控的指標。
生成指標
示例
start := time.Now() c.Next() duration := float64(time.Since(start)) / float64(time.Second) path := c.Request.URL.Path // 請求數(shù)加1 controllers.HTTPReqTotal.With(prometheus.Labels{ "method": c.Request.Method, "path": path, "status": strconv.Itoa(c.Writer.Status()), }).Inc() // 記錄本次請求處理時間 controllers.HTTPReqDuration.With(prometheus.Labels{ "method": c.Request.Method, "path": path, }).Observe(duration) // 模擬新建任務 controllers.TaskRunning.With(prometheus.Labels{ "type": shuffle([]string{"video", "audio"}), "state": shuffle([]string{"process", "queue"}), }).Inc() // 模擬任務完成 controllers.TaskRunning.With(prometheus.Labels{ "type": shuffle([]string{"video", "audio"}), "state": shuffle([]string{"process", "queue"}), }).Dec()
抓取指標
Promethues 抓取 target 配置
# 抓取間隔
scrape_interval: 5s
# 目標
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['prometheus:9090']
- job_name: 'local-service'
metrics_path: /metrics
static_configs:
- targets: ['host.docker.internal:8000']
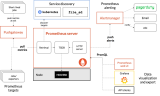
在實際應用中靜態(tài)配置 target 地址不太適用,在 k8s 下 Promethues通過與 Kubernetes API 集成目前主要支持5種服務發(fā)現(xiàn)模式,分別是:Node、Service、Pod、Endpoints、Ingress。
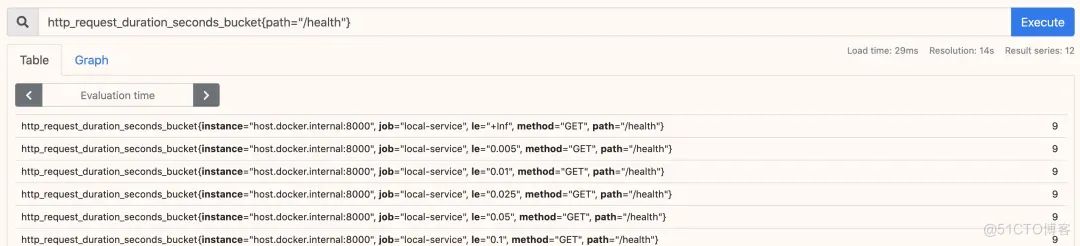
指標展示如下圖:

審核編輯:湯梓紅
-
cpu
+關注
關注
68文章
11090瀏覽量
217314 -
程序
+關注
關注
117文章
3827瀏覽量
83082 -
容器
+關注
關注
0文章
512瀏覽量
22481 -
Prometheus
+關注
關注
0文章
30瀏覽量
1904
原文標題:輕松駕馭!Prometheus 如何監(jiān)控指標,快速定位故障
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Prometheus的架構(gòu)原理從“監(jiān)控”談起
Prometheus的基本原理與開發(fā)指南

prometheus做監(jiān)控服務的整個流程介紹

使用Thanos+Prometheus+Grafana構(gòu)建監(jiān)控系統(tǒng)
監(jiān)控神器:Prometheus
關于Prometheus監(jiān)控系統(tǒng)相關的知識體系
prometheus下載安裝教程
基于kube-prometheus的大數(shù)據(jù)平臺監(jiān)控系統(tǒng)設計
40個步驟安裝部署Prometheus監(jiān)控系統(tǒng)
基于Prometheus開源的完整監(jiān)控解決方案

從零入門Prometheus:構(gòu)建企業(yè)級監(jiān)控與報警系統(tǒng)的最佳實踐指南
使用Prometheus與Grafana實現(xiàn)MindIE服務可視化監(jiān)控功能
詳解Prometheus的數(shù)據(jù)類型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論