

進入21世紀以來,移動通信、光通信、云計算、大數據等ICT技術蓬勃發展,推動了企業的數字化轉型。數據,變成了企業最核心的資產。
企業將這些數據資產全部存儲并運行在數據中心之上。隨著數字化的不斷深入,數據規模變得越來越龐大。
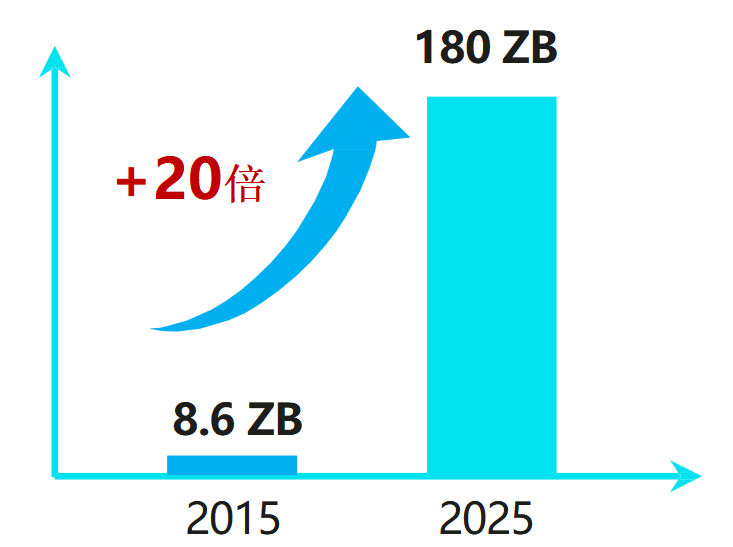
2025年新增的數據量將達到180ZB
(數據來源:華為GIV)
傳統的軟件算法,根本無法處理如此海量的數據(更何況,其中95%以上都是語音、視頻等非機構化數據)。于是,我們找來了能力更強的幫手,那就是——AI(人工智能)。
AI可以完成海量無效數據的篩選和有用信息的自動重組,從而大幅提升數據價值的挖掘效率,幫助用戶更高效地進行決策。
然而,想要利用好這個神器,我們需要三大要素的支持,那就是算法、算力和數據。
AI算法強不強,訓練是關鍵。深度學習的算法訓練,離不開海量的樣本數據,以及高性能的計算能力。
在存儲能力方面,從HDD(機械硬盤)到SSD(高速閃存盤),再到SCM(存儲級內存),介質時延降低了100倍以上,可以滿足高性能數據實時存取需求。
在計算能力方面,從CPU到GPU,再到專用的AI芯片,處理數據的能力也提升了100倍以上。
那么,這是否意味著數據中心能夠完全滿足AI規模應用的要求呢?
別急著說是,我們不能忘了一個重要的性能制約因素,那就是——網絡通信能力。

事實上,網絡通信能力確實拖了存儲能力和計算能力的后腿。數據顯示,在存儲介質和計算處理器演進之后,網絡通信時延已經成為了數據中心性能提升的瓶頸。通信時延在整個存儲E2E(端到端)時延中占比,已經從10%躍遷到60%以上。
也就是說,寶貴的存儲介質有一半以上的時間是在等待通信空閑;而昂貴的處理器,也有一半時間在等待通信同步。
網絡通信能力,已經在數據中心形成了木桶效應,變成了木桶的短板。
█ 數據中心通信網絡,到底出了什么問題?
上世紀70年代,TCP/IP和以太網技術相繼誕生。
它們成本低廉、結構簡單,為互聯網的早期發展做出了巨大貢獻。
但是,隨著網絡規模的急劇膨脹,傳統TCP/IP和以太網技術已經跟不上時代的步伐,它們落后的架構設計,反而制約了互聯網的進一步發展。
2010年后,數據中心的業務類型逐漸聚焦為三種,分別是高性能計算業務(HPC),存儲業務和一般業務。
這三種業務,對于網絡有不同的訴求。比如HPC業務的多節點進程間通信,對于時延要求非常高;而存儲業務,對通信可靠性的要求非常高,網絡需要實現絕對的0丟包;一般業務的規模巨大,擴展性強,要求網絡低成本易擴展。
傳統以太網可以適用于一般業務,但是無法應對高性能計算和存儲業務。于是,業界發展出了Infiniband(直譯為“無限帶寬”技術,縮寫為IB)網絡,應對有低時延要求的網絡IPC通信;發展出了FC(Fibre Channel,光纖通道)網絡,提供高可靠0丟包的存儲網絡。
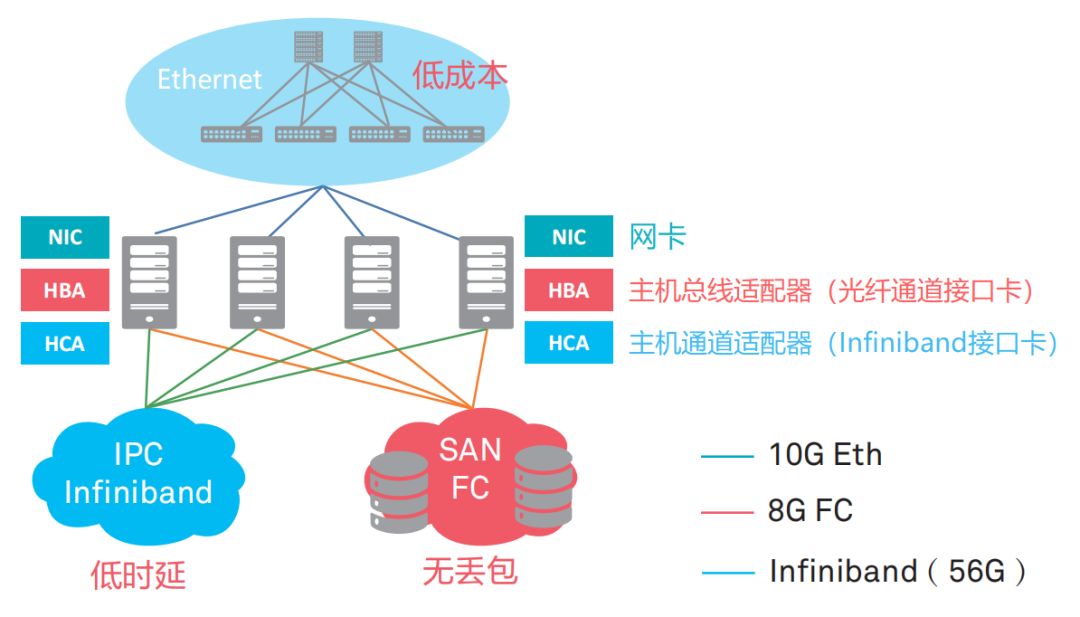
IB專網和FC專網的性能很強,但是價格昂貴,是以太網的數倍。而且,兩種專網需要專人運維,會帶來更高的維護成本。
是不是有辦法,將三種網絡的優勢進行結合呢?有沒有一種網絡,可以同時實現高吞吐、低時延和0丟包?
這里,我先賣個關子,不揭曉答案。我們回過頭來,看看TCP/IP協議棧的痛點。
傳統的TCP/IP協議棧,實在是太老了。它的很多致命問題,都是與生俱來的。比如說它的時延,還有它對CPU的占用。
為了解決問題,專家們提出了一種新型的通信機制——RDMA(Remote Direct Memory Access,遠程直接數據存取),用于取代TCP/IP。
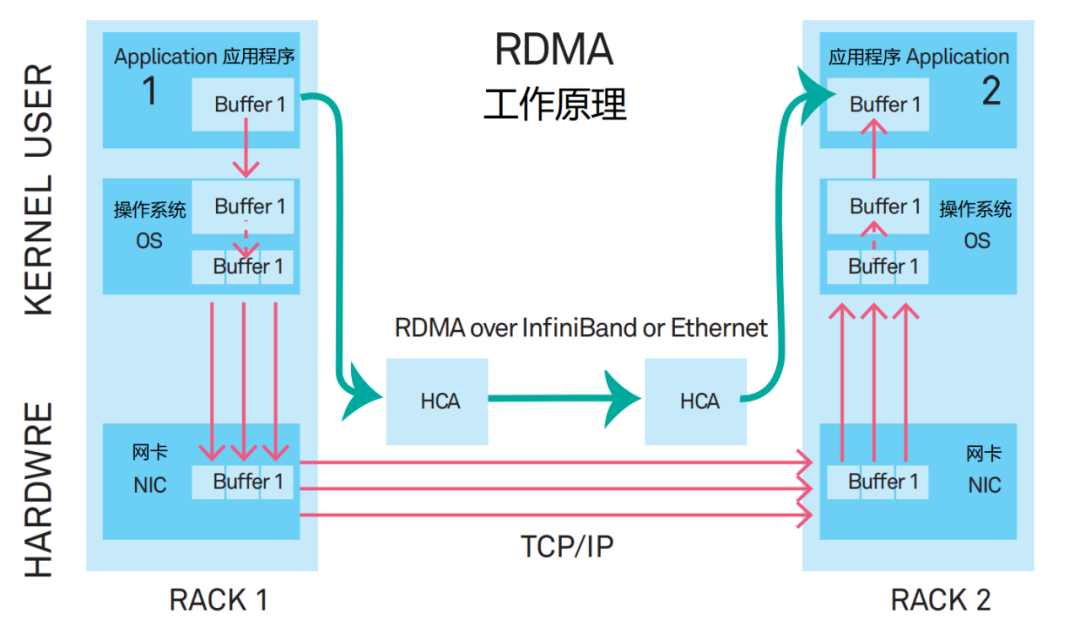
RDMA相當于是一個快速通道技術,在數據傳輸時延和CPU占用率方面遠遠強于TCP/IP,逐漸成為主流的網絡通信協議棧。
RDMA有兩類網絡承載方案,分別是專用InfiniBand和傳統以太網絡。

InfiniBand是一種封閉架構,交換機是特定廠家提供的專用產品,采用私有協議,無法兼容現網,加上對運維的要求過于復雜,并不是用戶的合適選擇。
除了InfiniBand之外,那就只剩下傳統以太網了。
那比較尷尬的是,RDMA對丟包率的要求極高。0.1%的丟包率,將導致RDMA吞吐率急劇下降。2%的丟包率,將使得RDMA的吞吐率下降為0。
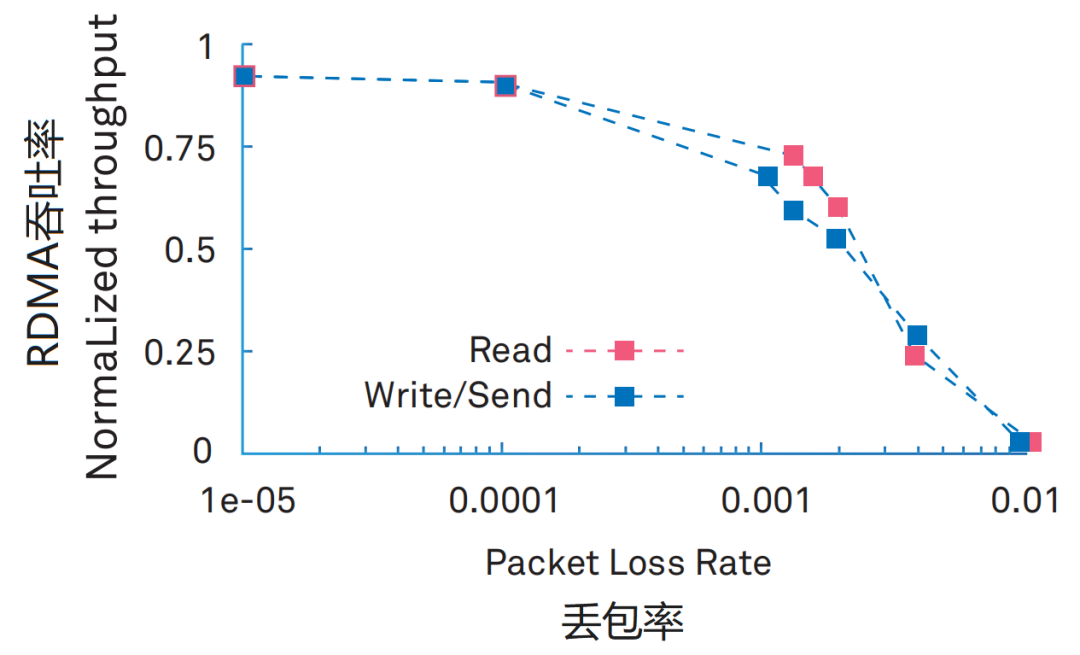
而傳統以太網,工作機制是“盡力而為”,丟包是家常便飯。
又回到了前面那個問題:我們究竟有沒有0丟包、高吞吐的新型開放以太網,用于支撐低延時RDMA的高效運行呢?
Duang!答案揭曉——
辦法當然是有的,那就是來自華為的超融合數據中心網絡智能無損技術。
█ 華為的零丟包秘技
華為的智能無損技術到底有何神通,可以解決困擾傳統以太網已久的丟包問題?
其實,想要實現零丟包,首先要搞清楚網絡為什么會產生丟包。
網絡丟包的基本原因其實很簡單,就是發生了溢出——網絡流量超過了數據中心交換機的處理和緩存能力。
應對溢出,業界通用的做法,就是控制發送端的發送速度,從而避免超過交換機處理能力的擁塞形成。
具體來說,就是在交換機端口設置報文緩存隊列,一旦隊列長度超過某一個閾值(擁塞水線),對擁塞報文進行擁塞標記,流目的端向源端發送降速信號,即顯式擁塞通知ECN(Explicit Congestion Notification)。
源端收到通知,從而降低發送速度,規避擁塞。
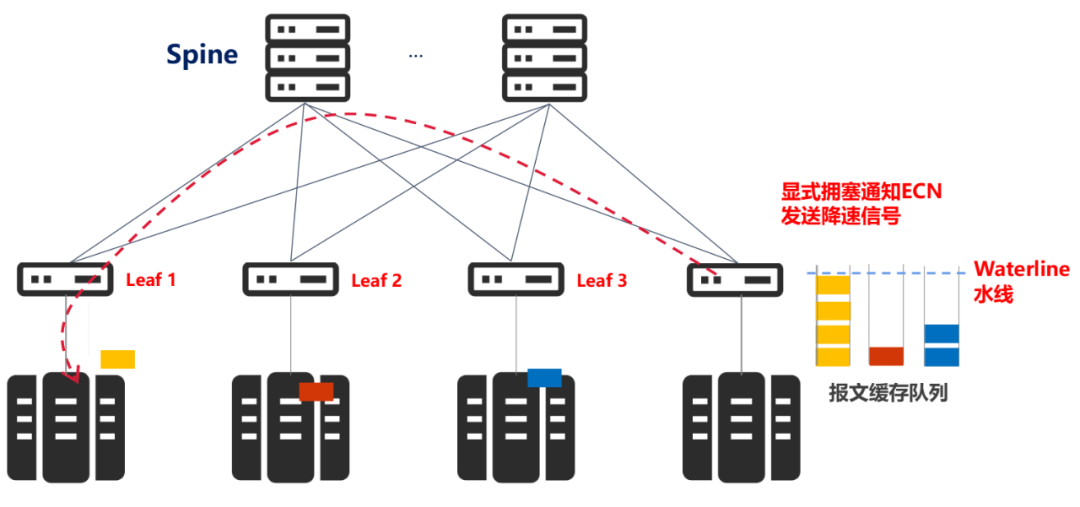
我們可以看出,這個閾值的設置非常關鍵。它決定了對報文進行擁塞標記的時機,是網絡中是否會發生擁塞的決定性因素。
閾值的設置,是一門非常深的學問。
如果設置太保守,就會降速太多,影響系統吞吐能力。如果設置太激進,則無法達到無損的效果。
更關鍵的是,網絡的業務類型是多樣且變化的,有時候需要高吞吐,有時候又需要低時延。即便是有經驗的專家,好不容易花了幾天的時間,設置好了最佳水線位置,結果它又變了,咋整?
于是,華為想到了最適合干這個活的角色,那就是——AI。
早在2012年,華為為了應對未來數據洪水挑戰,投入了數十個科學家,啟動新一代無損網絡的研究。
經過多年的潛心鉆研和探索,他們搞出了獨具創新的iLossless智能無損算法方案。這是一個通過人工智能實現網絡擁塞調度和網絡自優化的AI算法。
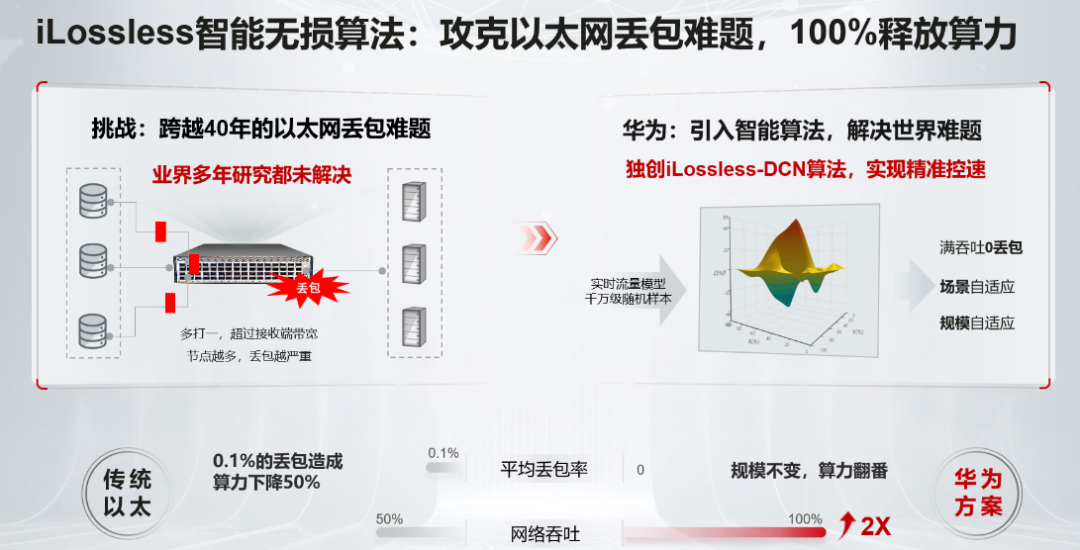
華為iLossless智能無損算法以Automatic ECN為核心,并首次在超高速數據中心交換機引入深度強化學習DRL(Deep Reinforcement Learning)。
對比傳統靜態閾值配置僵化,無法動態適應網絡變化的缺點,Automatic ECN為以太網的流量調度提供了智能預測能力,可以根據當前流量狀態精準預測下一刻的擁塞狀態,提前做好預留和準備。
基于iLossless智能無損算法,華為發布了超融合數據中心網絡CloudFabric 3.0解決方案,引領智能無損進入1.0時代。
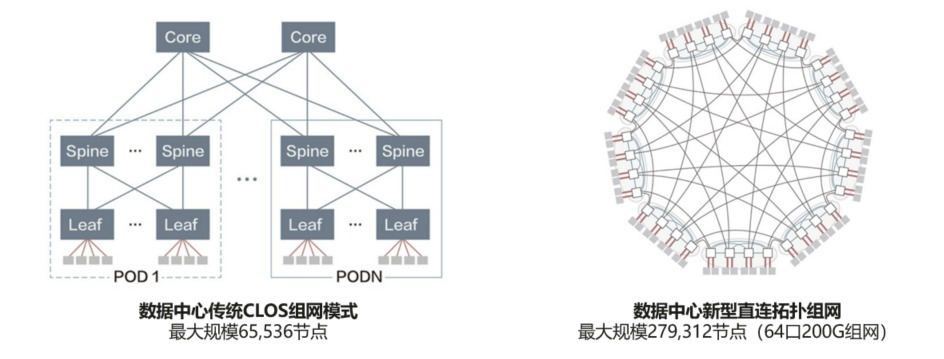
2022年,華為超融合數據中心網絡繼續探索,提出了更強大的智能無損網算一體技術和創新直連拓撲架構,可實現270k大規模算力樞紐網絡(組網規模4倍于業界,可助力構建E級和10E級大型和超大型算力樞紐),時延在智能無損1.0的基礎上,可進一步降低25%。
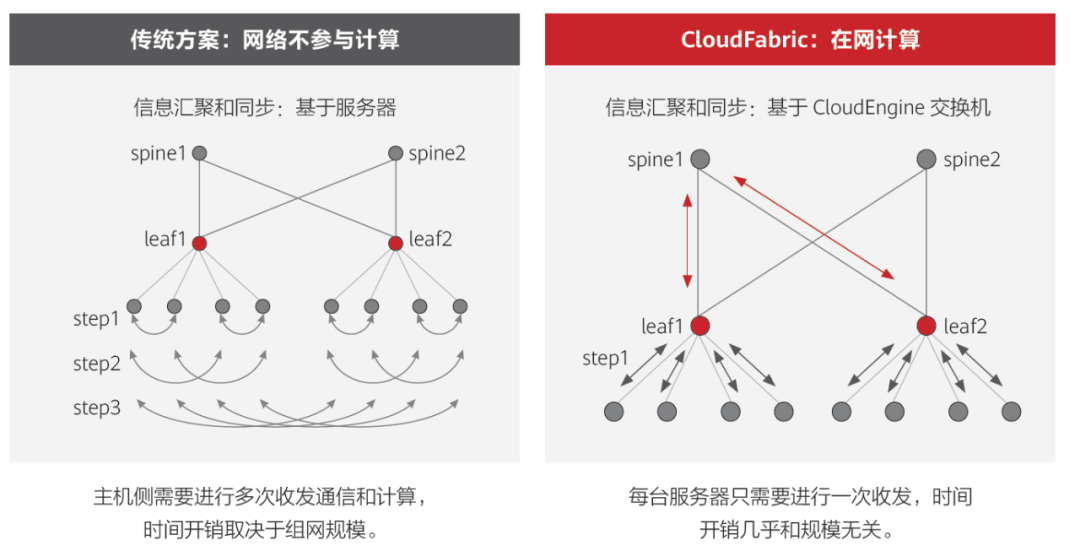
華為的智能無損2.0,基于在網計算(In-network computing)和拓撲感知(Topology-Aware Computing)實現網絡和計算協同。一方面,網絡參與計算信息的匯聚和同步,減少計算信息同步的次數;另一方面,通過調度確保計算節點就近完成計算任務,減少通信跳數,進一步降低應用時延。
以MPI_allreduce為例,相比傳統網絡僅做數據轉發不參與計算過程,華為超融合數據中心網絡可有效降低時延,提升計算效率27%。
華為超融合數據中心網絡解決方案,為數據中心構建了統一融合網絡,取代了此前的三種不同類型網絡(LAN、SAN、IPC),大幅減少了網絡建設成本和運維成本,總成本TCO下降了53%。AI業務的運行效率,則提升了30%以上。
█ 智能無損技術的積累沉淀
近年來,華為圍繞智能無損網絡和iLossless智能無損算法,接連發布了多個產品和解決方案。
2018年10月,華為就發布了AI Fabric極速以太網解決方案,幫助客戶構建與傳統以太網兼容的RDMA網絡,引領數據中心網絡進入極速無損的高性能時代。
2019年1月,華為又發布了業界首款面向AI時代的數據中心交換機CloudEngine 16800,承載了iLossLess智能無損交換算法,實現流量模型自適應自優化,從而在零丟包的基礎上,獲得更低時延和更高吞吐的網絡性能。
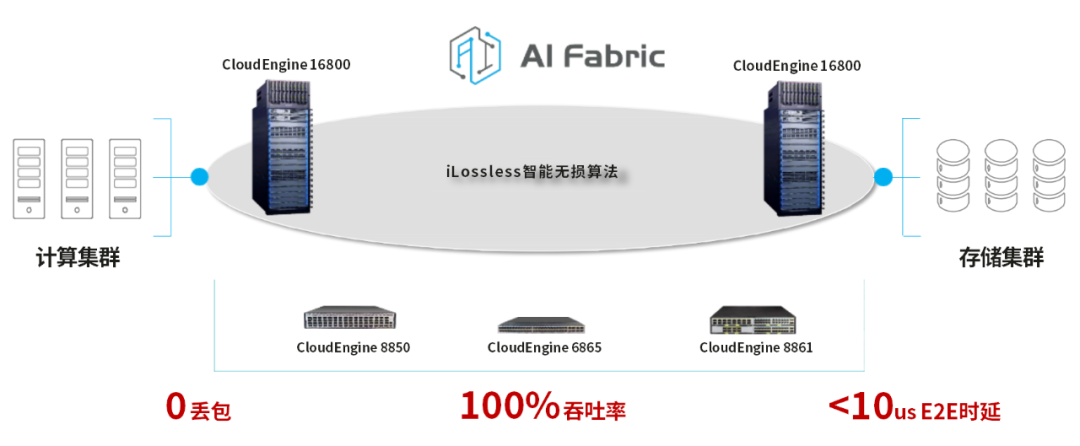
2021年6月,華為發布全無損以太存儲網絡解決方案(NoF+)。該方案基于OceanStor Dorado全閃存存儲系統和CloudEngine數據中心存儲網絡交換機構建,可實現存儲場景端到端數據加速,充分釋放全閃存性能潛力。
除了自身積極進行技術研究和產品化之外,華為還積極推動相關技術標準的成熟。
2021年8月,華為發布的智能無損技術論文《ACC: Automatic ECN Tuning for High-Speed Datacenter Networks》(高性能數據中心網絡中的ECN動態調優)入選全球網絡通信頂級會議ACM SIGCOMM 2021,得到業界專家的一致認可,具有世界級技術影響力。
在華為主導下,IEEE 802成立了Nendica(“Network Enhancements for the Next Decade” Industry Connections Activity)工作組,聯合業界共同探討以太網技術標準發展的新方向,為智能無損網絡技術發展提供了理論研究的開放土壤。
█ 智能無損技術的落地實踐
經過實際項目驗證并獲得客戶認可的技術,才是可靠的技術。
華為的超融合數據中心網絡CloudFabric 3.0解決方案,已經在金融、政府、超算中心、智算中心等客戶廣泛應用。包括中國銀行、云南農信、華夏銀行、湖北移動、中科院高能物理研究所、武漢人工智能計算中心、鵬城實驗室等在內的眾多高端用戶,都是華為智能無損技術的使用者。
中國銀行聯合華為打造的新一代智能無損存儲網絡“RoCE-SAN”,結合中行具體的應用場景,實現了智能緩存管理、逐流精準控速、故障高可用秒級切換的技術創新突破,滿足金融級高可用存儲網絡要求。
中科院高能物理研究所通過與華為的聯合創新,采用零丟包以太網技術,構建了由數萬顆CPU核構成的跨地域的高性能計算環境,很好地滿足了高能物理領域對算力的需求。
某互聯網巨頭布局無人駕駛,無人駕駛技能的訓練涉及到大量的AI計算:1天采集的數據,需要幾百的GPU服務器7天才能訓練完,嚴重影響無人駕駛的上市時間。通過華為的智能無損技術,最終使得整體訓練的時長縮短40%,加速無人駕駛的商用進程。
除了豐富的行業落地案例,華為智能無損技術還獲得了大量的行業獎項:
2018年6月,日本Interop展Best of Show Award金獎
2020年12月,中國銀行業金融科技應用成果大賽“最佳解決方案獎”
2021年4月,日本Interop展Best of Show Award 2020銀獎
2021年5月,2021數博會領先科技成果獎之“黑科技”類別
2021年10月,高性能計算領域 “融合架構創新獎”
2022年3月,中國通信學會科學技術獎特等獎
……
這些來自專業領域的認可,更加證明了華為基于智能無損技術的超融合數據中心網絡解決方案,在領導力和先進性方面居于行業領先地位。
█ 結語
從邏輯上來看,華為基于智能無損技術的超融合數據中心網絡解決方案,是將AI技術在數據中心進行落地,用AI賦能數據中心,再用數據中心,去支撐AI應用。這是一種非常有趣的良性循環,引領了整個ICT行業的智能化潮流。
這個方案是為算力時代量身定制的,可以很好地滿足算力時代計算、存儲、業務等多種場景數據流通的需要。
放眼未來,AI與數據中心的深度融合,將完美支撐企業數字化轉型所需的算力需求,加速數據存儲和處理過程,幫助企業快速決策,加快邁入數智時代。
本著“將通信科普到底”的原則,今天,我再繼續聊一下這個話題。
故事還是要從頭開始說起。
1973年夏天,兩名年輕的科學家(溫頓·瑟夫和羅伯特卡恩)開始致?于在新?的計算機?絡中,尋找?種能夠在不同機器之間進行通訊的?法。
不久后,在一本黃?的便簽本上,他們畫出了TCP/IP協議族的原型。
幾乎在同時,施樂公司的梅特卡夫和博格思,發明了以太網(Ethernet)。
我們現在都知道,互聯網的最早原型,是老美搞出來的ARPANET(阿帕網)。
ARPANET最開始用的協議超爛,滿足不了計算節點規模增長的需求。于是,70年代末,大佬們將ARPANET的核心協議替換成了TCP/IP(1978年)。
進入80年代末,在TCP/IP技術的加持下,ARPANET迅速擴大,并衍生出了很多兄弟姐妹。這些兄弟姐妹互相連啊連啊,就變成了舉世聞名的互聯網。
可以說,TCP/IP技術和以太網技術,是互聯網早期崛起的基石。它們成本低廉,結構簡單,便于開發、部署,為計算機網絡的普及做出了巨大貢獻。
但是后來,隨著網絡規模的急劇膨脹,傳統TCP/IP和以太網技術開始顯現疲態,無法滿足互聯網大帶寬、高速率的發展需求。
最開始出現問題的,是存儲。
早期的存儲,大家都知道,就是機器內置硬盤,通過IDE、SCSI、SAS等接口,把硬盤連到主板上,通過主板上的總線(BUS),實現CPU、內存對硬盤數據的存取。
后來,存儲容量需求越來越大,再加上安全備份的考慮(需要有RAID1/RAID5),硬盤數量越來越多,若干個硬盤搞不定,服務器內部也放不下。于是,就有了磁陣。
磁陣就是專門放磁盤的設備,一口子插幾十塊那種。
硬盤數據存取,一直都是服務器的瓶頸。開始的時候,用的是網線或專用電纜連接服務器和磁陣,很快發現不夠用。于是,就開始用光纖。這就是FC通道(Fibre Channel,光纖通道)。
2000年左右,光纖通道還是比較高大上的技術,成本不低。
當時,公共通信網絡(骨干網)的光纖技術處于在SDH 155M、622M的階段,2.5G的SDH和波分技術才剛起步,沒有普及。后來,光纖才開始爆發,容量開始迅速躍升,向10G(2003)、40G(2010)、100G(2010)、400G(現在)的方向發展。
光纖不能用于數據中心的普通網絡,那就只能繼續用網線,還有以太網。
好在那時服務器之間的通信要求還沒有那么高。100M和1000M的網線,勉強能滿足一般業務的需求。2008年左右,以太網的速率才勉強達到了1Gbps的標準。
2010年后,又出幺蛾子。
除了存儲之外,因為云計算、圖形處理、人工智能、超算還有比特幣等亂七八糟的原因,人們開始盯上了算力。
摩爾定律的逐漸疲軟,已經無法支持CPU算力的提升需求。牙膏越來越難擠,于是,GPU開始崛起。使用顯卡的GPU處理器進行計算,成為了行業的主流趨勢。
得益于AI的高速發展,各大企業還搞出了AI芯片、APU、xPU啊各自五花八門的算力板卡。
算力極速膨脹(100倍以上),帶來的直接后果,就是服務器數據吞吐量的指數級增加。
除了AI帶來的變態算力需求之外,數據中心還有一個顯著的變化趨勢,那就是服務器和服務器之間的數據流量急劇增加。
互聯網高速發展、用戶數猛漲,傳統的集中式計算架構無法滿足需求,開始轉變為分布式架構。
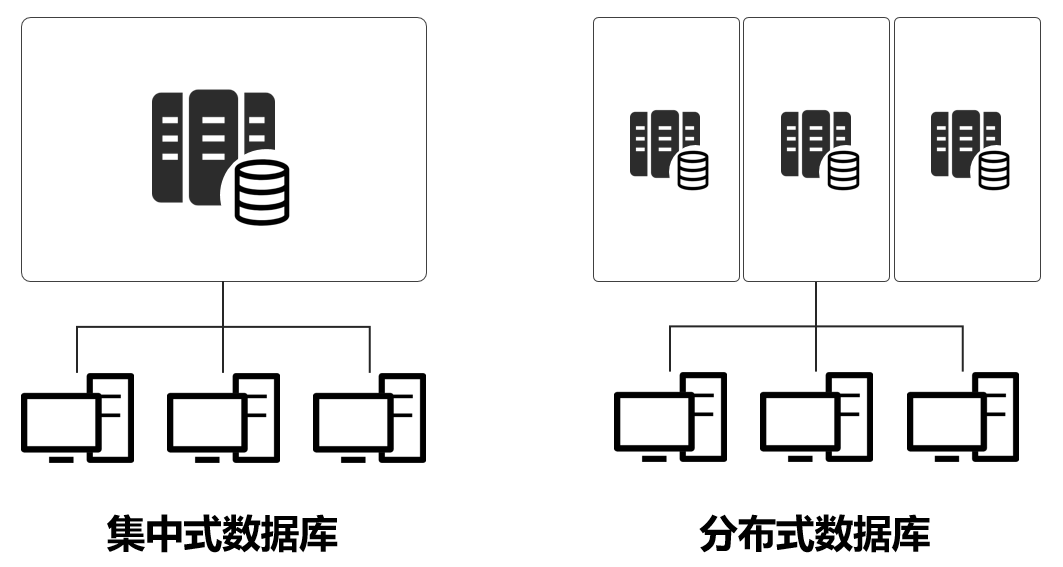
舉例來說,現在618,大家都在血拼。百八十個用戶,一臺服務器就可以,千萬級億級,肯定不行了。所以,有了分布式架構,把一個服務,放在N個服務器上,分開算。
分布式架構下,服務器之間的數據流量大大增加了。數據中心內部互聯網絡的流量壓力陡增,數據中心與數據中心之間也是一樣。
這些橫向(專業術語叫東西向)的數據報文,有時候還特別大,一些圖形處理的數據,包大小甚至是Gb級別。
綜上原因,傳統以太網根本搞不定這么大的數據傳輸帶寬和時延(高性能計算,對時延要求極高)需求。所以,少數廠家就搞了一個私有協議的專用網絡通道技術,也就是Infiniband網絡(直譯為“無限帶寬”技術,縮寫為IB)。
FCvsIBvs 以太網
IB技術時延極低,但是造價成本高,而且維護復雜,和現有技術都不兼容。所以,和FC技術一樣,只在特殊的需求下使用。
算力高速發展的同時,硬盤不甘寂寞,搞出了SSD固態硬盤,取代機械硬盤。內存嘛,從DDR到DDR2、DDR3、DDR4甚至DDR5,也是一個勁的猥瑣發育,增加頻率,增加帶寬。
處理器、硬盤和內存的能力爆發,最終把壓力轉嫁到了網卡和網絡身上。
學過計算機網絡基礎的同學都知道,傳統以太網是基于“載波偵聽多路訪問/沖突檢測(CSMA/CD)”的機制,極容易產生擁塞,導致動態時延升高,還經常發生丟包。
TCP/IP協議的話,服役時間實在太長,都40多年的老技術了,毛病一大堆。
舉例來說,TCP協議棧在接收/發送報文時,內核需要做多次上下文切換,每次切換需要耗費5us~10us左右的時延。另外,還需要至少三次的數據拷貝和依賴CPU進行協議封裝。
這些協議處理時延加起來,雖然看上去不大,十幾微秒,但對高性能計算來說,是無法忍受的。
除了時延問題外,TCP/IP網絡需要主機CPU多次參與協議棧內存拷貝。網絡規模越大,帶寬越高,CPU在收發數據時的調度負擔就越大,導致CPU持續高負載。
按照業界測算數據:每傳輸1bit數據需要耗費1Hz的CPU,那么當網絡帶寬達到25G以上(滿載)的時候,CPU要消費25GHz的算力,用于處理網絡。大家可以看看自己的電腦CPU,工作頻率是多少。
那么,是不是干脆直接換個網絡技術就行呢?
不是不行,是難度太大。
CPU、硬盤和內存,都是服務器內部硬件,換了就換了,和外部無關。
但是通信網絡技術,是外部互聯技術,是要大家協商一起換的。我換了,你沒換,網絡就嗝屁了。
全世界互聯網同時統一切換技術協議,你覺得可不可能?
不可能。所以,就像現在IPv6替換IPv4,就是循序漸進,先雙棧(同時支持v4和v6),然后再慢慢淘汰v4。
數據中心網絡的物理通道,光纖替換網線,還稍微容易一點,先小規模換,再逐漸擴大。換了光纖后,網絡的速度和帶寬上的問題,得以逐漸緩解。
網卡能力不足的問題,也比較好解決。既然CPU算不過來,那網卡就自己算唄。于是,就有了現在很火的智能網卡。某種程度來說,這就是算力下沉。
搞5G核心網的同事應該很熟悉,5G核心網媒體面網元UPF,承擔了無線側上來的所有業務數據,壓力極大。
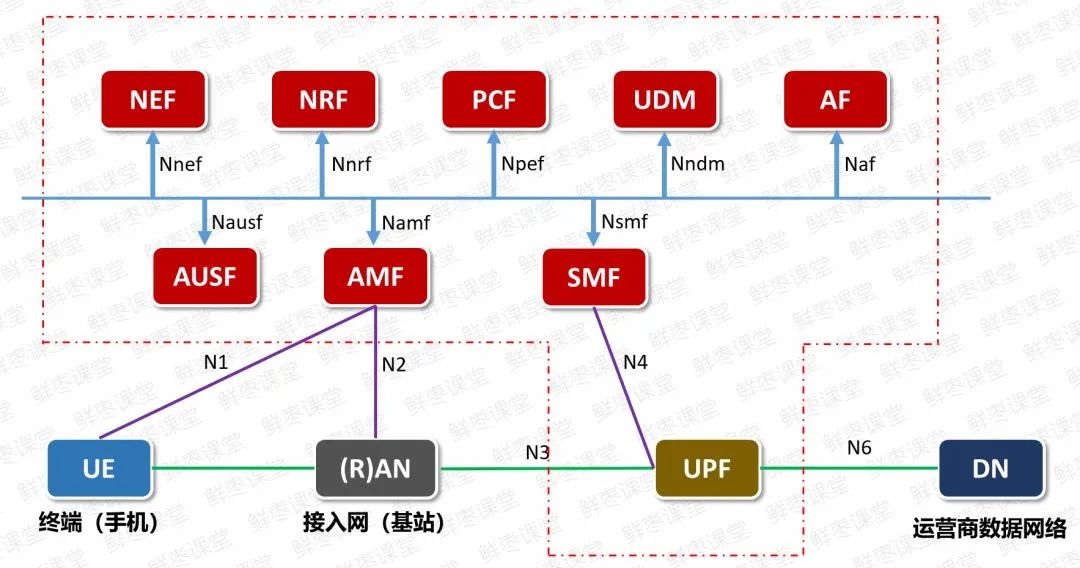
現在,UPF網元就采用了智能網卡技術,由網卡自己進行協議處理,緩解CPU的壓力,流量吞吐還更快。
如何解決數據中心通信網絡架構的問題呢?專家們想了半天,還是決定硬著頭皮換架構。他們從服務器內部通信架構的角度,重新設計一個方案。
在新方案里,應用程序的數據,不再經過CPU和復雜的操作系統,直接和網卡通信。
這就是新型的通信機制——RDMA(Remote Direct Memory Access,遠程直接數據存取)。
RDMA相當于是一個“消滅中間商”的技術,或者說“走后門”技術。
RDMA的內核旁路機制,允許應用與網卡之間的直接數據讀寫,將服務器內的數據傳輸時延降低到接近1us。 同時,RDMA的內存零拷貝機制,允許接收端直接從發送端的內存讀取數據,極大的減少了CPU的負擔,提升CPU的效率。 RDMA的能力遠遠強于TCP/IP,逐漸成為主流的網絡通信協議棧,將來一定會取代TCP/IP。
RDMA有兩類網絡承載方案,分別是專用InfiniBand和傳統以太網絡。
RDMA最早提出時,是承載在InfiniBand網絡中。
但是,InfiniBand是一種封閉架構,交換機是特定廠家提供的專用產品,采用私有協議,無法兼容現網,加上對運維的要求過于復雜,并不是用戶的合理選擇。
于是,專家們打算把RDMA移植到以太網上。
比較尷尬的是,RDMA搭配傳統以太網,存在很大問題。
RDMA對丟包率要求極高。0.1%的丟包率,將導致RDMA吞吐率急劇下降。2%的丟包率,將使得RDMA的吞吐率下降為0。
InfiniBand網絡雖然貴,但是可以實現無損無丟包。所以RDMA搭配InfiniBand,不需要設計完善的丟包保護機制。 現在好了,換到傳統以太網環境,以太網的人生態度就是兩個字——“擺爛”。以太網發包,采取的是“盡力而為”的原則,丟包是家常便飯,丟了就再傳。
于是,專家們必須解決以太網的丟包問題,才能實現RDMA向以太網的移植。再于是,就有了前天文章提到的,華為的超融合數據中心網絡智能無損技術。
說白了,就是讓以太網做到零丟包,然后支撐RDMA。有了RDMA,就能實現超融合數據中心網絡。
關于零丟包技術的細節,我不再贅述,大家看前天那篇文章(再給一遍鏈接:這里)。
值得一提的是,引入AI的網絡智能無損技術是華為的首創,但超融合數據中心,是公共的概念。除了華為之外,別的廠家(例如深信服、聯想等)也講超融合數據中心,而且,這個概念在2017年就很熱了。
什么叫超融合?
準確來說,超融合就是一張網絡,通吃HPC高性能計算、存儲和一般業務等多種業務類型。處理器、存儲、通信,全部都是超融合管理的資源,大家平起平坐。
超融合不僅要在性能上滿足這些低時延、大帶寬的變態需求,還要有低成本,不能太貴,也不能太難維護。
未來,數據中心在整體網絡架構上,就是葉脊網絡一條路走到黑(到底什么是葉脊網絡?)。路由交換調度上,SDN、IPv6、SRv6慢慢發展。微觀架構上,RDMA技術發展,替換TCP/IP。物理層上,全光繼續發展,400G、800G、1.2T…
我個人臆測,目前電層光層的混搭,最終會變成光的大一統。光通道到全光交叉之后,就是滲透到服務器內部,服務器主板不再是普通PCB,而是光纖背板。芯片和芯片之間,全光通道。芯片內部,搞不好也是光。
光通道是王道
路由調度上,以后都是AI的天下,網絡流量啊協議啊全部都是AI接管,不需要人為干預。大量的通信工程師下崗。
審核編輯:劉清
-
SSD
+關注
關注
21文章
2952瀏覽量
119132 -
人工智能
+關注
關注
1804文章
48726瀏覽量
246630 -
SCM
+關注
關注
2文章
67瀏覽量
15463 -
ICT技術
+關注
關注
0文章
44瀏覽量
10327 -
AI芯片
+關注
關注
17文章
1968瀏覽量
35696
原文標題:為了實現零丟包,數據中心網絡到底有多拼?
文章出處:【微信號:CloudBrain-TT,微信公眾號:云腦智庫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
適用于數據中心和AI時代的800G網絡
數據中心子系統的組成
數據中心的健康檢查(電氣篇)
銳捷助互聯網數據中心網絡自動化、可視化運維
飛速(FS)數據中心級交換機為什么受歡迎?
請問光學模塊如何進化以滿足數據中心需求?
數據中心的建設也看重風水
數據中心光互聯解決方案
未來數據中心與光模塊發展假設
數據中心是什么
什么是數據中心
數據中心UPS系統的選擇與規模
適用于數據中心和 AI 時代的網絡






 工商網監
工商網監

評論