 Transformers內部運作原理研究
Transformers內部運作原理研究
Ketan Doshi | 作者 羅伯特
在第一篇文章中,我們了解了Transformer的功能、使用方式、其高級架構以及優勢。 前一篇文章,移步:Transformers圖解(第1部分):功能概述 在這篇文章中,我們將深入了解它的內部運作,詳細研究它是如何工作的。我們將看到數據如何通過系統流動,以及它們的實際矩陣表示和形狀,理解每個階段執行的計算。 以下是本系列中之前和接下來文章的快速摘要。整個系列中的目標是不僅了解某物是如何運作的,而且為什么它以這種方式運作。
功能概述(Transformer的使用方式以及為什么它們比RNN更好。架構的組成部分,以及在訓練和推理期間的行為)。
工作原理 — 本文(內部操作端到端。數據如何流動以及在每個階段執行的計算,包括矩陣表示)。
多頭注意力(Transformer中注意力模塊的內部工作)。
為什么注意力提升性能(注意力不僅做什么,還為什么它如此有效。注意力如何捕捉句子中單詞之間的關系)。
1. 架構概述 正如我們在第一部分中看到的,架構的主要組件包括:
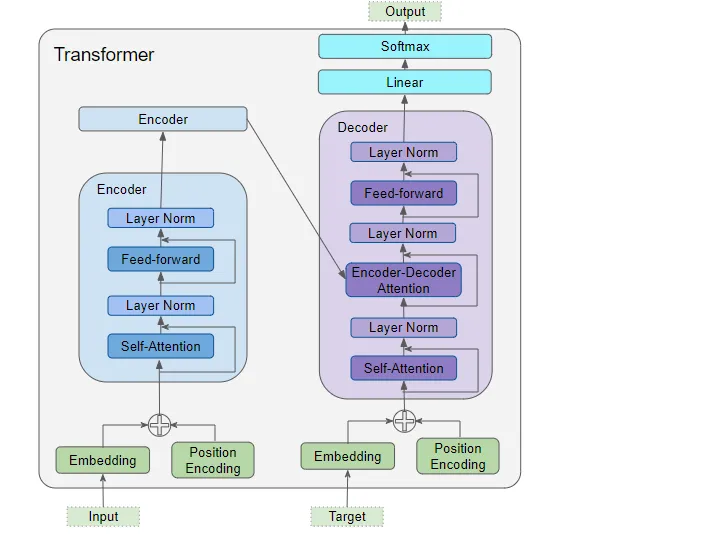
(作者提供的圖像)
編碼器和解碼器的數據輸入,其中包括:
嵌入層(Embedding layer)
位置編碼層(Position Encoding layer)
解碼器堆棧包含多個解碼器。每個解碼器包含:
兩個多頭注意力層(Multi-Head Attention layer)
前饋層(Feed-forward layer)
輸出(右上方)—生成最終輸出,并包含:
線性層(Linear layer)
Softmax層(Softmax layer)
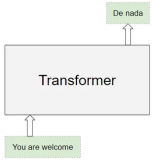
為了理解每個組件的作用,讓我們通過訓練Transformer解決翻譯問題的過程,逐步了解Transformer的工作原理。我們將使用訓練數據的一個樣本,其中包含輸入序列(英語中的'You are welcome')和目標序列(西班牙語中的'De nada')。
2. 嵌入和位置編碼
與任何自然語言處理模型一樣,Transformer需要了解有關每個單詞的兩個方面:單詞的含義以及它在序列中的位置。 嵌入層編碼單詞的含義。位置編碼層表示單詞的位置。Transformer通過將這兩種編碼相加來組合它們。
2.1 嵌入(embedding)
Transformer有兩個嵌入層。輸入序列被送入第一個嵌入層,稱為輸入嵌入。
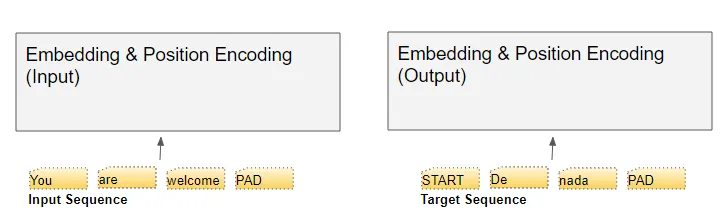
(作者提供的圖像) 目標序列在將目標向右移一個位置并在第一個位置插入起始標記后,被送入第二個嵌入層。請注意,在推理期間,我們沒有目標序列,我們將輸出序列循環饋送到這第二層,正如我們在第一部分中學到的。這就是為什么它被稱為輸出嵌入。 文本序列使用我們的詞匯表映射為數值單詞ID。然后,嵌入層將每個輸入單詞映射到一個嵌入向量,這是該單詞含義的更豐富表示。
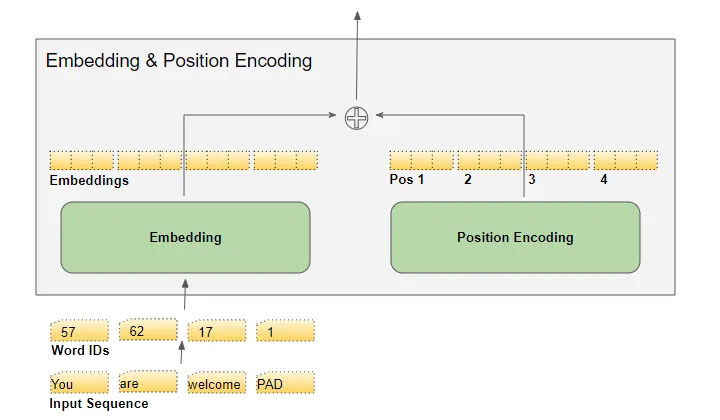
(作者提供的圖像)
2.2 位置編碼
由于RNN實現了一個循環,每個單詞都按順序輸入,它隱式地知道每個單詞的位置。 然而,Transformer不使用RNN,序列中的所有單詞都是并行輸入的。這是它相對于RNN架構的主要優勢,但這意味著位置信息丟失了,必須單獨添加。 就像有兩個嵌入層一樣,有兩個位置編碼層。位置編碼是獨立于輸入序列計算的。這些是僅依賴于序列的最大長度的固定值。例如,
第一項是指示第一個位置的常數代碼,
第二項是指示第二個位置的常數代碼,
以此類推。
這些常數是使用下面的公式計算的,其中:
pos是單詞在序列中的位置
d_model是編碼向量的長度(與嵌入向量相同)
是該向量中的索引值。
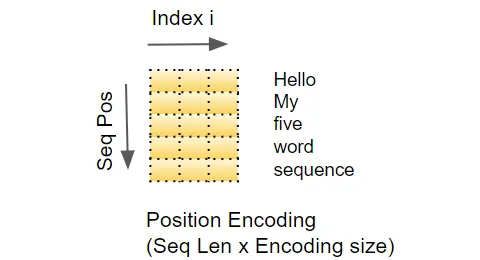
(作者提供的圖像) 換句話說,它交替使用正弦曲線和余弦曲線,對于所有偶數索引使用正弦值,對于所有奇數索引使用余弦值。例如,如果我們對一個包含40個單詞的序列進行編碼,我們可以看到下面是一些(單詞位置,編碼索引)組合的編碼數值。
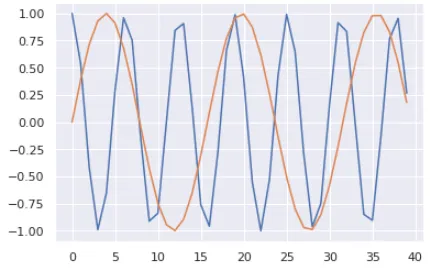
(作者提供的圖像) 藍色曲線顯示了所有40個單詞位置的第0個索引的編碼,橙色曲線顯示了所有40個單詞位置的第1個索引的編碼。對于其余的索引值,將會有類似的曲線。
3. 矩陣維度
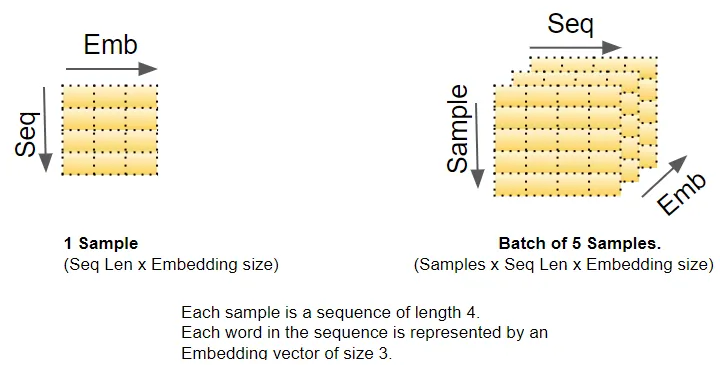
正如我們所知,深度學習模型一次處理一個批次的訓練樣本。嵌入層和位置編碼層操作的是表示一批序列樣本的矩陣。嵌入層接收一個形狀為(樣本數,序列長度)的單詞ID矩陣。它將每個單詞ID編碼成一個長度為嵌入大小的單詞向量,從而產生一個形狀為(樣本數,序列長度,嵌入大小)的輸出矩陣。位置編碼使用與嵌入大小相等的編碼大小。因此,它產生一個形狀類似的矩陣,可以添加到嵌入矩陣中。
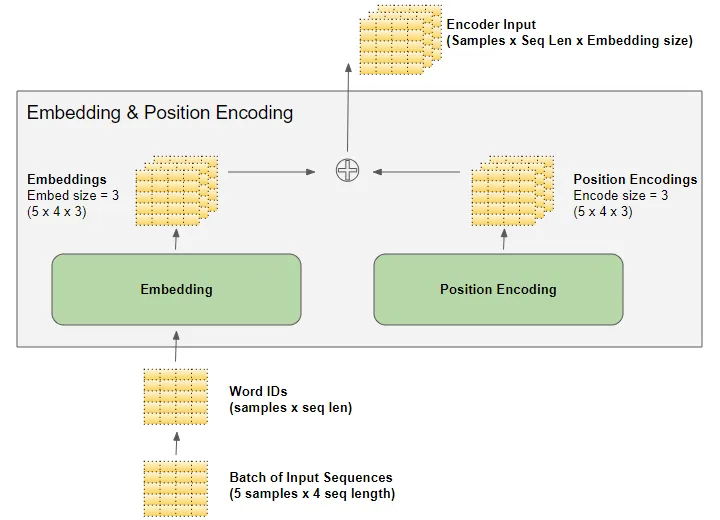
(作者提供的圖像) 由嵌入層和位置編碼層產生的形狀為(樣本數,序列長度,嵌入大小)的矩陣在整個Transformer中得以保留,因為數據通過編碼器和解碼器堆棧流動,直到被最終的輸出層重新整形。 這給出了Transformer中3D矩陣維度的概念。然而,為了簡化可視化,從這里開始我們將放棄第一個維度(樣本數),并使用單個樣本的2D表示。
(作者提供的圖像) 輸入嵌入將其輸出發送到編碼器。類似地,輸出嵌入饋入解碼器。
4. 編碼器(Encoder)
編碼器和解碼器堆棧由若干(通常為六個)編碼器和解碼器連接而成。
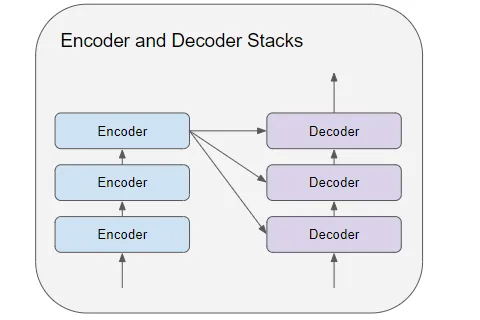
(作者提供的圖像) 堆棧中的第一個編碼器從嵌入和位置編碼接收其輸入。堆棧中的其他編碼器從前一個編碼器接收其輸入。 編碼器將其輸入傳遞到多頭自注意力層。自注意力輸出傳遞到前饋層,然后將其輸出向上傳遞到下一個編碼器。
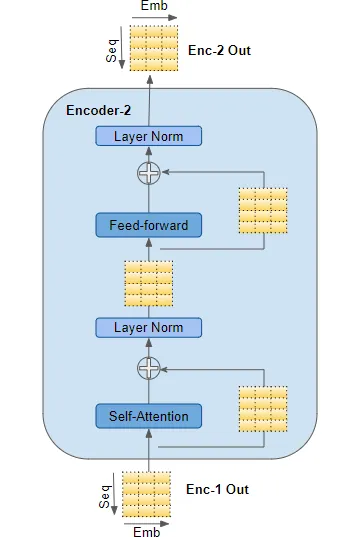
(作者提供的圖像) 自注意力和前饋子層都有繞過它們的殘差跳連接,然后是一層歸一化。 最后一個編碼器的輸出被饋送到解碼器堆棧中的每個解碼器,如下所述。
5. 解碼器(Decoder)
解碼器的結構與編碼器非常相似,但有一些區別。 與編碼器一樣,堆棧中的第一個解碼器從輸出嵌入和位置編碼接收其輸入。堆棧中的其他解碼器從前一個解碼器接收其輸入。 解碼器將其輸入傳遞到多頭自注意力層。這個自注意力層的運作方式略有不同于編碼器中的自注意力層。它只允許關注序列中較早的位置。這是通過屏蔽未來位置來實現的,我們將很快討論。
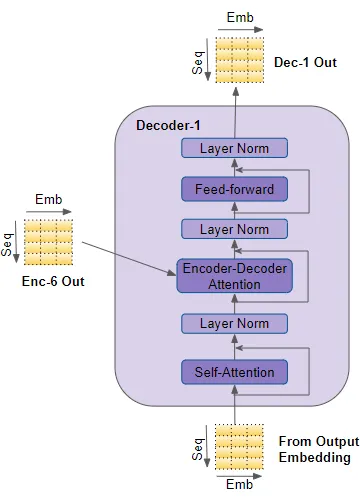
(作者提供的圖像) 與編碼器不同,解碼器有第二個多頭注意力層,稱為編碼器-解碼器注意力層。編碼器-解碼器注意力層的工作方式類似于自注意力,只是它結合了兩個輸入源 —— 在它下面的自注意力層以及編碼器堆棧的輸出。 自注意力輸出傳遞到前饋層,然后將其輸出向上傳遞到下一個解碼器。 這些子層,自注意力、編碼器-解碼器注意力和前饋,都有繞過它們的殘差跳連接,然后是一層歸一化。
6. 注意力
在第一部分中,我們談到了在處理序列時為什么注意力非常重要。在Transformer中,注意力在三個地方使用:
編碼器的自注意力 — 輸入序列關注自身
解碼器的自注意力 — 目標序列關注自身
解碼器的編碼器-解碼器注意力 — 目標序列關注輸入序列
注意力層以三個參數的形式接收其輸入,稱為Query(查詢)、Key(鍵)和Value(值)。
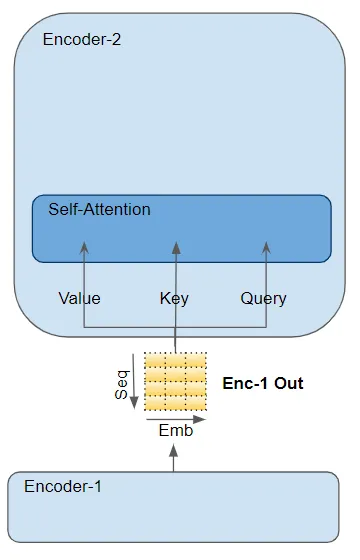
在編碼器的自注意力中,編碼器的輸入傳遞給所有三個參數:Query、Key 和 Value。
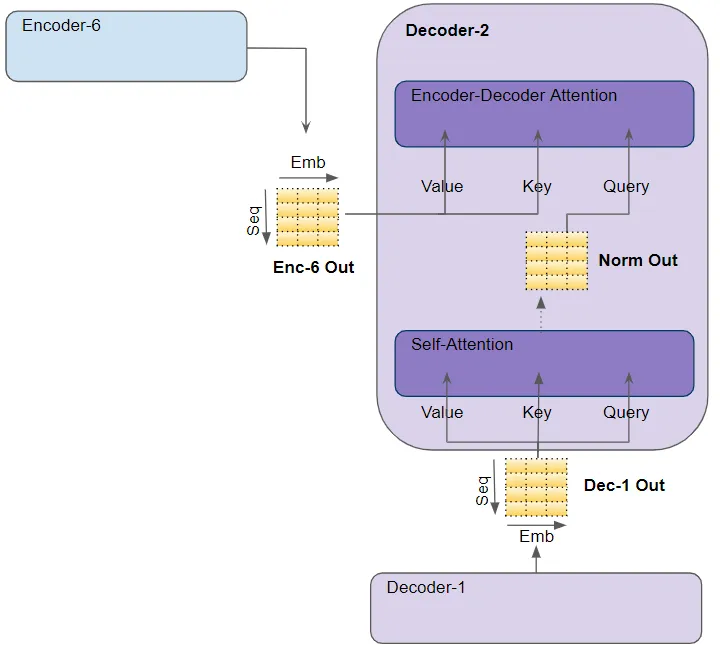
(作者提供的圖像) 在解碼器的自注意力中,解碼器的輸入傳遞給所有三個參數:Query、Key 和 Value。在解碼器的編碼器-解碼器注意力中,堆棧中最后一個編碼器的輸出傳遞給 Value 和 Key 參數。下面的自注意力(和層歸一化)模塊的輸出傳遞給 Query 參數。
(作者提供的圖像)
7. 多頭注意力
Transformer將每個注意力處理器稱為一個注意力頭,并并行地重復多次。這被稱為多頭注意力。它通過組合多個類似的注意力計算,使得注意力具有更強的判別力。
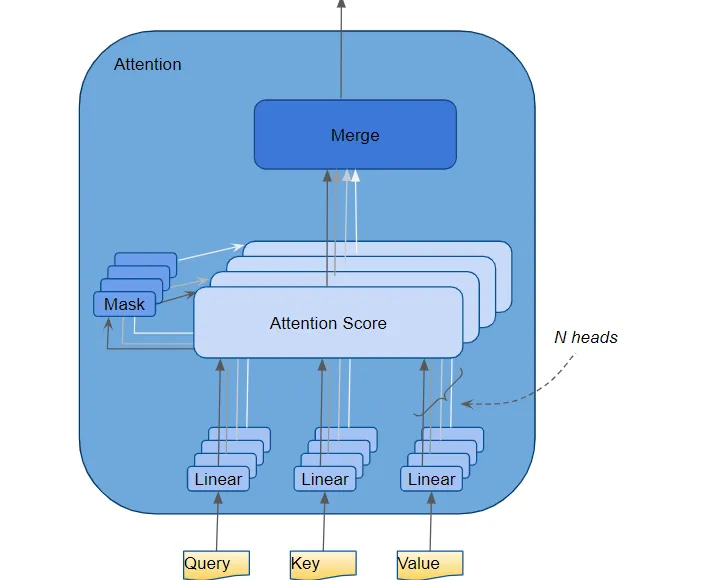
(作者提供的圖像) Query、Key 和 Value 分別通過單獨的線性層傳遞,每個層都有自己的權重,產生三個結果分別稱為 Q、K 和 V。然后,它們使用如下所示的注意力公式結合在一起,產生注意力分數。
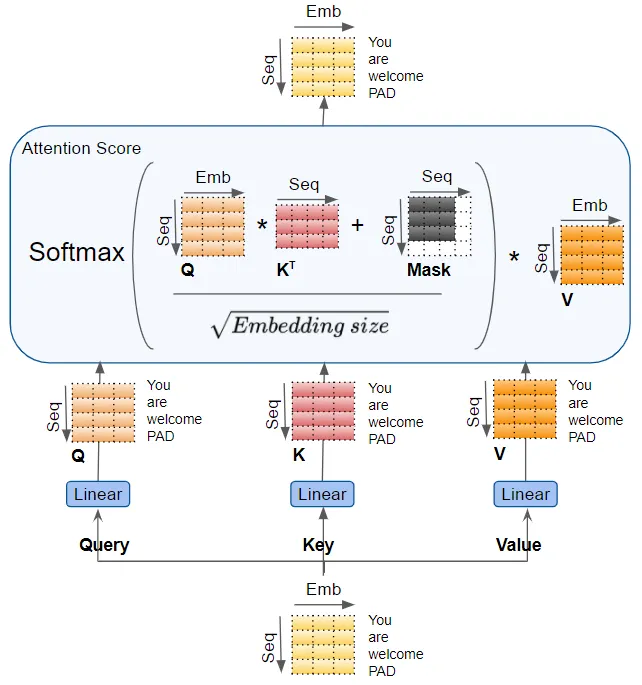
(作者提供的圖像)
這里需要意識到的重要一點是,Q、K 和 V 值攜帶了序列中每個單詞的編碼表示。注意力計算然后將每個單詞與序列中的每個其他單詞結合在一起,使得注意力分數為序列中的每個單詞編碼了一個分數。 在稍早前討論解碼器時,我們簡要提到了掩碼。上述注意力圖中也顯示了掩碼。讓我們看看它是如何工作的。
8. 注意力掩碼
在計算注意力分數時,注意力模塊實施了一個掩碼步驟。掩碼有兩個目的: 在編碼器自注意力和編碼器-解碼器注意力中:掩碼用于將輸入句子中的填充位置的注意力輸出置零,以確保填充不會影響自注意力。(注意:由于輸入序列的長度可能不同,它們被擴展為帶有填充標記的固定長度向量,就像大多數NLP應用程序一樣。)
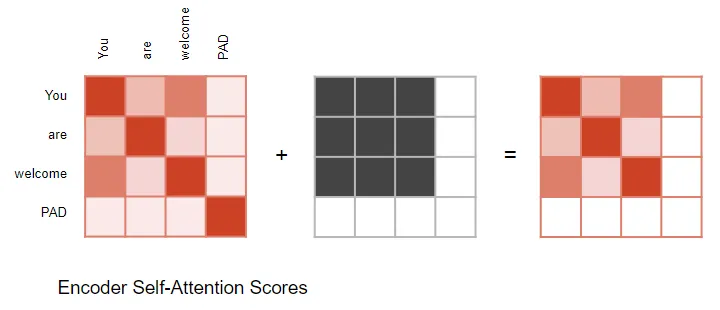
(作者提供的圖像) 編碼器-解碼器注意力同樣如此。
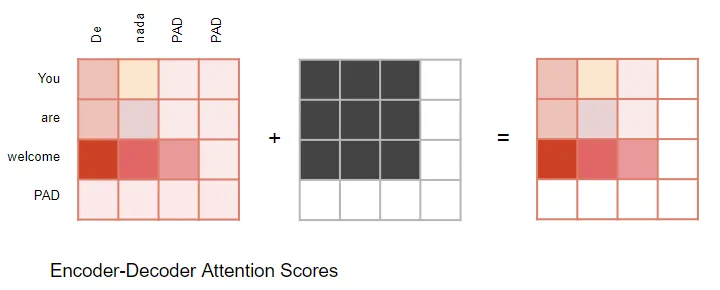
(作者提供的圖像) 在解碼器的自注意力中:掩碼用于防止解碼器在預測下一個單詞時偷看目標句子的其余部分。 解碼器處理源序列中的單詞,并使用它們來預測目標序列中的單詞。在訓練期間,通過教師強制(teacher forcing),完整的目標序列被作為解碼器的輸入傳遞。因此,在預測某個位置的單詞時,解碼器可以使用該單詞之前以及之后的目標單詞。這使得解碼器可以通過使用未來‘時間步’中的目標單詞來‘作弊’。 例如,在預測‘Word 3’時,解碼器應該只參考目標中的前3個輸入單詞,而不是第4個單詞‘Ketan’。
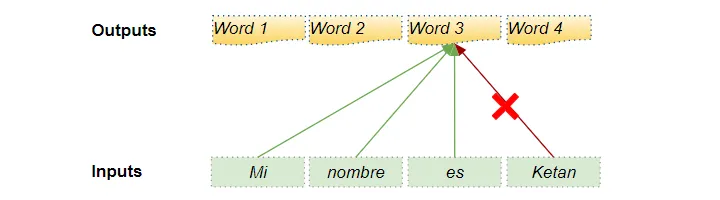
(作者提供的圖像) 因此,解碼器屏蔽了序列中稍后出現的輸入單詞。
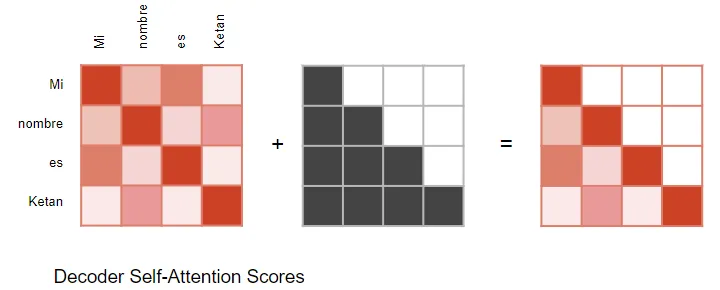
(作者提供的圖像) 在計算注意力分數時(參考前面顯示計算的圖片),掩碼應用于 Softmax 之前的分子部分。被屏蔽的元素(白色方塊)被設置為負無窮,以便 Softmax 將這些值轉換為零。
9. 生成輸出
堆棧中的最后一個解碼器將其輸出傳遞給輸出組件,將其轉換為最終的輸出句子。 線性層將解碼器向量投影為單詞分數,每個位置的句子中目標詞匯表中的每個唯一單詞都有一個分數值。例如,如果我們的最終輸出句子有7個單詞,而目標西班牙語詞匯表中有10000個唯一單詞,我們將為這7個單詞生成10000個分數值。分數值指示了每個單詞在該句子位置的出現概率。 然后,Softmax層將這些分數轉換為概率(總和為1.0)。在每個位置,我們找到具有最高概率的單詞的索引,然后將該索引映射到詞匯表中相應的單詞。這些單詞然后形成Transformer的輸出序列。
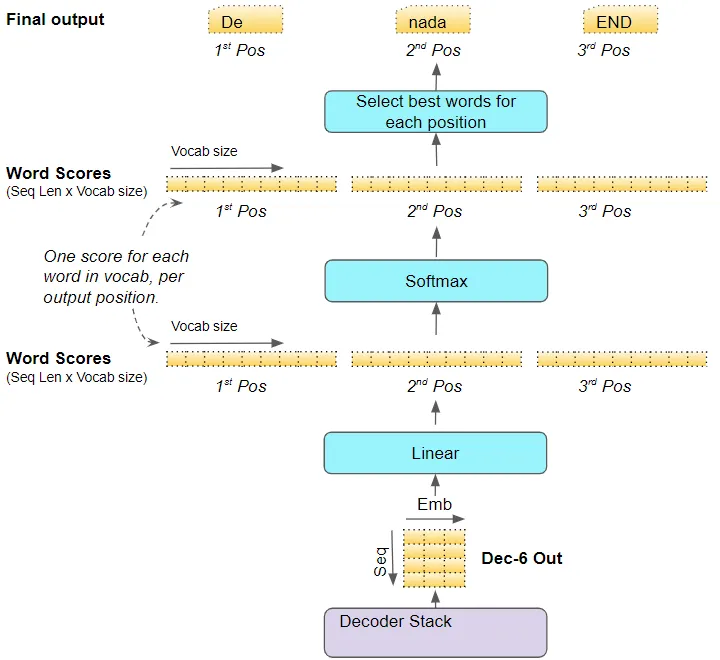
(作者提供的圖像)
10. 訓練和損失函數
在訓練過程中,我們使用交叉熵損失等損失函數來比較生成的輸出概率分布與目標序列。概率分布給出了每個單詞在該位置出現的概率。
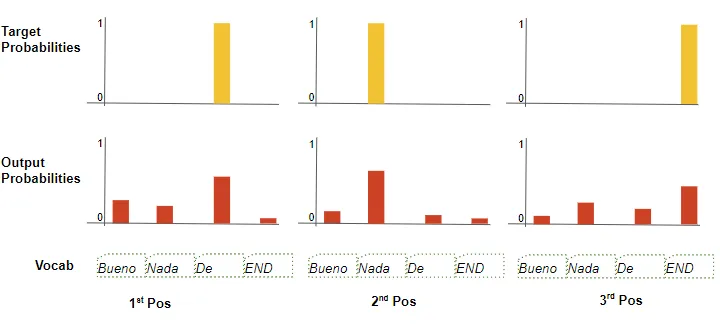
(作者提供的圖像) 假設我們的目標詞匯表只包含四個單詞。我們的目標是生成一個概率分布,與我們期望的目標序列“De nada END”相匹配。 這意味著第一個單詞位置的概率分布應該對“De”有一個概率為1,而對詞匯表中所有其他單詞的概率為0。同樣,“nada”和“END”在第二和第三個單詞位置的概率應分別為1。 與往常一樣,損失用于計算梯度,通過反向傳播來訓練Transformer。
11. 結論
希望這能讓你對Transformer在訓練過程中的內部運作有所了解。正如我們在前一篇文章中討論的那樣,在推理過程中,它運行在一個循環中,但大部分處理方式保持不變。 多頭注意力模塊是賦予Transformer強大能力的關鍵。
審核編輯:黃飛
-
解碼器
+關注
關注
9文章
1143瀏覽量
40718 -
Transformer
+關注
關注
0文章
143瀏覽量
5995 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13552 -
rnn
+關注
關注
0文章
89瀏覽量
6886
原文標題:Transformers圖解(第2部分):它是如何工作的,逐步說明
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用基于Transformers的API在CPU上實現LLM高效推理
若想使用ADS8422IBPFBT是要怎么替換或運作?
汽車車身內部布置方法研究與總結
生產運作管理培訓教材
BJDEEN PULSE TRANSFORMERS
通關安全檢查系統的運作模式與仿真研究綜述
電子濾波器對于智能手機和其他無線設備的內部運作至關重要
深度學習:transformers的近期工作成果綜述
永磁同步電機運作

永磁同步電機運作

Transformers是什么意思?人工智能transformer怎么翻譯?
微軟內部對亞洲研究院的未來持有不同看法
Transformers的功能概述






 工商網監
工商網監
評論