 亞馬遜發布史上最大文本轉語音模型BASE TTS
亞馬遜發布史上最大文本轉語音模型BASE TTS
亞馬遜的人工智能研究團隊近日宣布,他們成功開發出了迄今為止規模最大的文本轉語音模型——BASE TTS。這款新模型擁有高達9.8億個參數,不僅在規模上超越了之前的所有版本,還在能力上實現了質的飛躍。
BASE TTS模型在訓練過程中使用了超過10萬小時的錄音數據,涵蓋了多種語言,包括英語、德語、荷蘭語和西班牙語等。這種跨語言的訓練方法使模型能夠更好地處理復雜的語言結構,并提高了單詞發音的自然度和準確度。
據研究人員介紹,BASE TTS在處理語言時表現出了驚人的能力,尤其是在處理長句子和復雜語法結構時,其表現遠超過之前的模型。此外,該模型還能準確模擬人類語音中的細微差別,如語調、重音和語速等,從而為用戶帶來更加自然、流暢的語音體驗。
亞馬遜表示,BASE TTS模型的發布將為其語音技術產品帶來巨大的推動力,并有望推動整個語音識別和語音合成領域的發展。未來,這一技術可能會被廣泛應用于智能助手、電子書閱讀器、語音導航系統等眾多領域,為用戶帶來更加便捷、高效的人機交互體驗。
隨著人工智能技術的不斷發展,我們有理由相信,BASE TTS模型將為用戶帶來更多驚喜和便利。同時,這一技術的廣泛應用也將推動語音技術的不斷創新和進步。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238265 -
模型
+關注
關注
1文章
3226瀏覽量
48809 -
亞馬遜
+關注
關注
8文章
2650瀏覽量
83321
發布評論請先 登錄
相關推薦
谷歌正式發布Gemini 2.0 性能提升近兩倍
2.0在關鍵基準測試中相比前代產品Gemini 1.5 Pro的性能提升了近兩倍。該模型支持圖像、視頻和音頻等多種輸入與輸出形式,例如可以實現文本與圖像的混合生成以及自定義的多語言文本轉語音
TMS320C6000 MCBSP轉語音帶音頻處理器(VBAP)接口
電子發燒友網站提供《TMS320C6000 MCBSP轉語音帶音頻處理器(VBAP)接口.pdf》資料免費下載
發表于 10-26 10:17
?0次下載

語音提示器-WT3000A離在線TTS方案-打破語種限制/AI對話多功能支持
TTS(Text To Speech )技術作為智能語音領域的重要組成部分,能夠將文本信息轉化為逼真的語音輸出,為各類硬件設備提供便捷的語音

語音提示器-WT3000A離在線TTS方案-打破語種限制/AI對話多功能支持
前言forewordTTS(TextToSpeech)技術作為智能語音領域的重要組成部分,能夠將文本信息轉化為逼真的語音輸出,為各類硬件設備提供便捷的語音提示服務。本方案正是基于唯創知

WT2605C TTS在線語音合成芯片:賦能多行業領域,引領產品智能化
在當今科技日新月異的時代,語音技術正逐步滲透到我們生活的方方面面,而TTS(Text-To-Speech,文本到語音)技術作為其中的重要一環,更是以其獨特的魅力改變了人機交互的方式。W
收款機TTS語音芯片新方案:WT3000T8,雙語合成流暢,字庫解碼多樣!
一:方案背景概述隨著科技的飛速發展,人工智能和語音識別技術在各個領域都得到了廣泛應用。其中,文本轉語音(TTS)技術以其獨特的優勢,在收款機語音
【算能RADXA微服務器試用體驗】+ GPT語音與視覺交互:4,文字轉語音
文字轉語音使用的技術簡稱為TTS。一般情況下我用的都是在線的EDGE-TTS服務。但非常幸運的是,BM1684X上居然有適配好的本地運行TTS,那自然是要體驗一番。
先轉到projec
發表于 07-15 23:18
Jacob:從ElevenLabs解決的行業問題來看,AI創業的思路與互聯網時代并不相同
人聲是最原始、最個性的表達方式之一,為了提高效率,很多時候我們會使用合成語音來代替人聲,涉及到的商業場景有很多,例如虛擬智能助理、客戶呼叫中心、有聲讀物和媒體內容創作。文本轉語音(TTS

整合離線語音識別ASR和TTS,內存映射時發生內存不足怎么解決?
start==end;,如果不加識別模型,TTS能正常和喚醒模型工作,這個問題怎么解決,希望樂鑫給個方案。字典和模型的大小應該都在3M左右吧,具體語
發表于 06-28 07:34
收款機TTS語音芯片新方案:WT3000T8,雙語合成流暢,字庫解碼多樣!
不同播報要求下語音占用大量資源空間的問題。可以實現低成本低功耗的文本轉語音,支持中英文兩種功能,實現播報語音自由配置無需通過升級方式替換語音
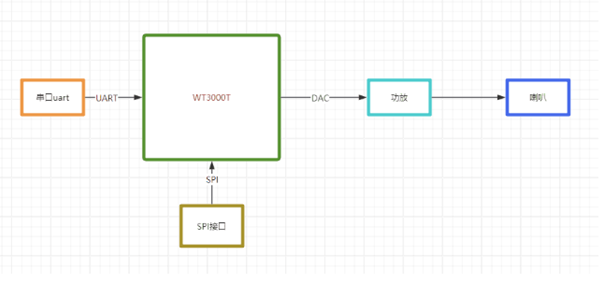
中英文語音合成芯片(TTS芯片)WT3000T8-在ETC上的應用案例
隨著智能化浪潮的推進,ETC(電子不停車收費)系統已逐漸成為現代交通的重要組成部分。在這一背景下,唯創知音自主研發的WT3000T8中文轉語音合成芯片(TTS芯片)以其卓越的性能和廣泛的應用前景,為ETC系統帶來了前所未有的智能體驗。
【解讀】VTX316 TTS語音合成芯片幾個很實用的應用技巧
? 前言 VTX316是北京宇音天下科技有限公司最新推出的一款更具性價比的中文TTS語音合成芯片,采用QFN32(4*4mm)封裝,體積更加精巧,文本合成一次高達500字節數據(250個漢字),支持
WT3000T8-TTS語音合成芯片及應用場景介紹
TTS語音合成芯片是一種能夠將文本信息轉化為自然語音的專用芯片。它通過內置的語音合成算法和音頻處理單元,實現了
【Longan Pi 3H 開發板試用連載體驗】給ChatGPT裝上眼睛,并且還可以語音對話:6,FastAPI服務器搭建與TTS播放
Longan Pi完成全部處理后,需要將文字轉回語音返回給PC,那么這一步就需要用到TTS,文本轉語音。我使用的是EDGE-TTS庫,這個庫
發表于 04-16 12:54
玩轉語音合成芯片(TTS芯片),看這一篇就夠了
什么是語音合成芯片:語音合成芯片也稱為TTS芯片,即文字轉語音芯片,是一種能夠將輸入的文字信息轉換為語音輸出的芯片。通過






 工商網監
工商網監
評論