 數倉中搭建細粒度容災應用的主要步驟
數倉中搭建細粒度容災應用的主要步驟
前言
適用版本:【8.2.1.210及以上】
當前數倉承載的客戶業務越來越多,從而導致客戶對于數倉的可靠性要求不斷增加。尤其在金融領域,容災備份機制是信息系統必須提供的能力之一。本文介紹了在云上環境的雙集群(不跨Region不跨VPC)后臺手動部署并使用細粒度容災的主要步驟,使得用戶能快速方便得搭建起細粒度容災。
2. 細粒度容災簡介
對于MPPDB集群的容災而言,目前業界的常見方案要么是部署兩套規格配置同等的集群,要么通過邏輯雙加載方式去實現,這兩個方案缺點比較明顯,存在架構復雜、建設成本高等問題,不僅使得災備部署難度增大,還導致資源浪費。在此背景下,GaussDB(DWS)基于列存表實現細粒度容災能力,既滿足核心分析型業務在極端場景的業務連續性要求,同時也能大幅降低容災方案的建設成本,而且容災架構輕量化,容災系統易運維、易操作、易演練,從而幫助用戶迅捷、經濟、按需構建核心業務的容災系統。
相比于傳統的容災方案,細粒度容災有以下優勢:
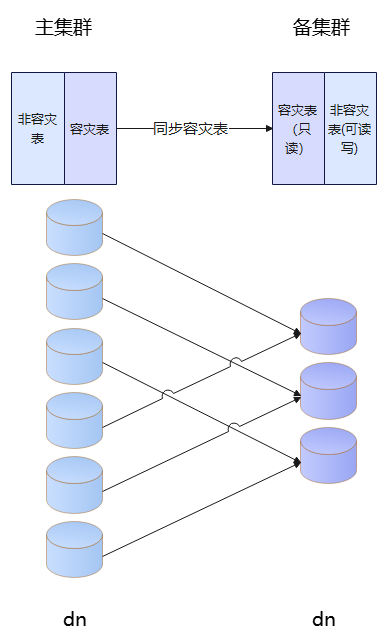
主集群和備集群雙活(Active-Active)(備集群除災備表只讀外,其余表可讀寫)
主備集群只需滿足DN整數倍關系,降低備集群建設資源,方便靈活部署
利用列存表的數據和元數據分離的特點,通過元數據邏輯同步 + 數據物理同步的方式,同步增量,結合UDF的增量抽取/回放接口,保障表級數據一致性
粒度可控,支持表級、schema級、庫級容災
支持表DDL,部分DCL元數據同步,達到切換可用
細粒度容災示意圖
3. 容災前準備
3.1 配置互信
前提條件
確保ssh服務打開。
確保ssh端口不會被防火墻關閉。
確保所有機器節點間網絡暢通。
配置互信
依次登錄主備集群各節點沙箱外,執行步驟2-4。
將主集群和備集群所有節點ip和hostname添加到/home/Ruby/.ssh/authorized_keys和/var/chroot/home/Ruby/.ssh/authorized_keys的from列表中。
將主集群和備集群所有節點ip和hostname的映射添加到/etc/hosts和/var/chroot/etc/hosts文件中。
遍歷主集群和備集群所有節點ip和hostname,執行以下命令。
ssh-keyscan -t rsa -T 120 ${ip/hostname} >> /home/Ruby/.ssh/known_hosts ssh-keyscan -t rsa -T 120 ${ip/hostname} >> /var/chroot/home/Ruby/.ssh/known_hosts
校驗互信
從主集群任一節點能免密ssh到備集群任一節點且從備集群任一節點能免密ssh到主集群任一節點,即代表互信已配置成功。
3.2 配置容災配置文件
Ruby用戶分別登錄主備集群主節點沙箱內。
創建容災目錄,假設目錄為/DWS/data2/finedisaster。mkdir -p /DWS/data2/finedisaster
在/DWS/data2/finedisaster目錄下,創建容災配置文件backupRestore.ini和主備集群倒換配置文件sw_backupRestore.ini。
注意:
細粒度容災的容災備份過程支持與物理細粒度備份業務并行執行。可通過以下措施隔離:
兩個備份任務指定不同的metadata目錄和media目錄,實現備份數據隔離。容災備份目錄通過容災配置文件(backupRestore.ini和sw_backupRestore.ini)中的參數primary-media-destination和primary-metadata-destination指定。
細粒度容災的容災備份端口與物理細粒度備份的master-port指定為不同的值,實現備份進程端口的隔離。容災的備份端口通過容災配置文件(backupRestore.ini和sw_backupRestore.ini)中的參數backup-port指定。
容災配置文件backupRestore.ini
以下是backupRestore.ini文件示例,可根據具體業務場景修改配置參數值。
# Configuration file for SyncDataToStby tool # The backup life cycle life-cycle=10m # The table that records backups info backuprestoreinfo-file=backuprestoreinfo.csv # The cluster user name for cluster username=Ruby # The primary cluster env set primary-env= # The standby cluster env set standby-env= # Time interval between each full backup, uint: min full-backup-exec-time-interval=N/A # Time interval between each backup backup-exec-time-interval=2 # One of the backup hosts primary-host-ip=XXX.XXX.XXX.XX # The media type that restore backup files, DISK media-type=disk # The number of process that should be used. Range is (1~32) parrallel-process=4 # The compression level that should be used for backup. Range(0~9) compression-level=1 compression-type=2 # Media destination where the backup must be stored primary-media-destination=/DWS/data2/finedisaster/mediadata # Metadata destination where the metadata must be stored primary-metadata-destination=/DWS/data2/finedisaster/metadata # The master-port in which the backup must be executed backup-port=XXXX # Logging level for the log contents of backup:FATAL,ERROR,INFO,DEBUG primary-cluster-logging-level=INFO # Time interval between each restore, uint: min restore-interval=2 # One of the restore hosts restore-host-ip=XXX.XXX.XXX.XX # Media destination where the backup contents must be stored in the standby cluster restore-media-destination=/DWS/data2/finedisaster/mediadata # Metadata destination where the backup contents must be stored in the standby cluster restore-metadata-destination=/DWS/data2/finedisaster/metadata # The master-port in which the restore must be executed restore-port=XXXX # Logging level for the log contents of restore standby-cluster-logging-level=INFO # The maximum number of log files that should be created. Range is (5~1024). log-file-count=50 # The retry times of checking cluster balance for resuem backup or double clusters check-balance-retry-times=0 # cluster id primary-cluster-id=11111111-1111-1111-1111-111111111111 standby-cluster-id=22222222-2222-2222-2222-222222222222 # Processes tables for which fine-grained disaster recovery is no longer performed # Value should be 'none', 'log-desync-table', 'drop-desync-table' desync-table-operation=drop-desync-table # Number of CPU cores that can be used by each DR process. Range is (1~1024). cpu-cores=8 # The max number of rch files that can be reserved on master cluster before sent to standby cluster. 0 means no limit. local-reserve-file-count=160
主備集群倒換配置文件sw_backupRestore.ini相比于backupRestore.ini只需顛倒下列參數
primary-host-ip / restore-host-ip
backup-port / restore-port
primary-media-destination / restore-media-destination
primary-metadata-destination / restore-metadata-destination
primary-cluster-id / standby-cluster-id
配置文件主要參數說明
| 參數名 | 參數含義 |
|---|---|
| username | 執行雙集群腳本的OS用戶,設置成GaussDB(DWS)集群相同的OS用戶 |
| primary-env | 主集群的環境變量存儲文件的絕對路徑 |
| standby-env | 備集群的環境變量存儲文件的絕對路徑 |
| backup-exec-time-interval | 增量備份周期 |
| primary-host-ip | 主集群執行備份的節點ip |
| compression-type | 備份文件的壓縮算法類型 |
| compression-level | 備份文件的壓縮級別 |
| primary-media-destination | 主集群上存放備份文件的絕對路徑 |
| primary-metadata-destination | 主集群上備份元數據的絕對路徑 |
| backup-port | Roach主代理備份進程的執行端口 |
| restore-interval | 恢復周期 |
| restore-host-ip | 備集群執行恢復的節點ip |
| restore-media-destination | 備集群存放主集群同步的備份文件的路徑 |
| restore-metadata-destination | 備集群存放主集群同步的元數據信息的路徑 |
| restore-port | 恢復進程執行端口 |
| primary-cluster-id | 指定主集群的UUID |
| standby-cluster-id | 指定備集群的UUID |
| new-disaster-recovery-suppressed-time-windows | 指定主集群不發起新一輪備份的時間窗口 |
| desync-table-operation | 指定不再進行細粒度容災的表,在備集群上的處理方式 |
| cpu-cores | 指定容災每個進程能使用的cpu核數 |
| local-reserve-file-count | 在發送到備用群集之前,可以在主群集上保留的最大rch文件數。0表示無限制。 |
3.3 主備集群準備
Ruby用戶登錄主集群主節點沙箱內。
設置集群GUC參數。
local-dn-num為本集群DN數,remote-dn-num為對方集群DN數,可替換為實際值。
python3 $GPHOME/script/DisasterFineGrained.py -t prepare --local-dn-num 6 --remote-dn-num 3 --config-file /DWS/data2/finedisaster/backupRestore.ini
3.4 容災表數據準備
主集群連接數據庫,準備容災表數據。
新建容災表
create table schema1.table_1(id int, name text) with (orientation = column, colversion="2.0", enable_disaster_cstore="on", enable_delta=false) DISTRIBUTE BY hash(id);
存量表(非容災表)轉為容災表
alter table schema1.table_1 set (enable_disaster_cstore='on');
--查詢表的分布方式
select pclocatortype from pg_catalog.pgxc_class where pcrelid = 'schema1.table_1'::oid limit 1;
--若表的分布方式為H(HASH分布),獲取一個hash表的分布列,后續以'id'列分布為例
select pg_catalog.getdistributekey('schema1.table_1');
--對表做重分布
alter table schema1.table_1 DISTRIBUTE BY HASH(id);
--若表的分布方式為N(ROUNDROBIN分布),對表做重分布
alter table schema1.table_1 DISTRIBUTE BY ROUNDROBIN;
--若表的分布方式為R(REPLICATION分布),對表做重分布
alter table schema1.table_1 DISTRIBUTE BY REPLICATION;
4. 細粒度容災操作
4.1 定義發布
Ruby用戶登錄主集群主節點沙箱,以下操作均在沙箱內進行。
連接數據庫,通過發布語法指定需要容災的主表,語法如下:
--發布所有表 CREATE PUBLICATION _pub_for_fine_dr FOR ALL TABLES; --發布schema CREATE PUBLICATION _pub_for_fine_dr FOR ALL TABLES IN SCHEMA schema1, schema2; --發布表和schema CREATE PUBLICATION _pub_for_fine_dr FOR ALL TABLES IN SCHEMA schema1, TABLE schema2.table_1; --增加一個發布表 ALTER PUBLICATION _pub_for_fine_dr ADD TABLE schema1.table_1; --增加發布SCHEMA ALTER PUBLICATION _pub_for_fine_dr ADD ALL TABLES IN SCHEMA schema2;
定義發布后,將容災publication放到參數文件中,以dbname.pubname形式,例如:
echo 'dbname._pub_for_fine_dr' > /DWS/data2/finedisaster/pub.list
若需要解除發布,通過DisasterFineGrained.py腳本下發cancel-publication命令
# 1、創建需要取消的容災對象列表文件 # 解除發布表 echo 'db_name.schema_name.table_name' > /DWS/data2/finedisaster/config/disaster_object_list.txt # 解除發布SCHEMA echo 'db_name.schema_name' > /DWS/data2/finedisaster/config/disaster_object_list.txt # 2、下發cancel-publication命令 python3 $GPHOME/script/DisasterFineGrained.py -t cancel-publication --disaster-object-list-file /DWS/data2/finedisaster/config/disaster_object_list.txt --config-file /DWS/data2/finedisaster/backupRestore.ini # 3、取消全部發布 python3 $GPHOME/script/DisasterFineGrained.py -t cancel-publication --config-file /DWS/data2/finedisaster/backupRestore.ini --all-cancel
4.2 啟動容災
注意:
云上集群沙箱內無法啟動crontab任務,需要在主備集群沙箱外手動添加定時備份恢復任務
HCS 8.3.0及以上環境,沙箱外crontab設置ssh到沙箱內的定時任務,為了防止沙箱逃逸,ssh前需要加上"sudo python3 /rds/datastore/dws/XXXXXX/sudo_lib/checkBashrcFile.py && source /etc/profile && source ~/.bashrc && ",否則定時任務不生效。checkBashrcFile.py文件路徑與版本號有關。
主集群主節點沙箱外設置定時任務,crontab -e。注意替換主節點IP。
*/1 * * * * nohup ssh XXX.XXX.XXX.XXX "source /etc/profile;if [ -f ~/.profile ];then source ~/.profile;fi;source ~/.bashrc;nohup python3 /opt/dws/tools/script/SyncDataToStby.py -t backup --config-file /DWS/data2/finedisaster/backupRestore.ini --disaster-fine-grained --publication-list /DWS/data2/finedisaster/pub.list >>/dev/null 2>&1 &" >>/dev/null 2>&1 &
備集群主節點沙箱外設置定時任務,crontab -e。注意替換主節點IP。
*/1 * * * * nohup ssh XXX.XXX.XXX.XXX "source /etc/profile;if [ -f ~/.profile ];then source ~/.profile;fi;source ~/.bashrc;nohup python3 /opt/dws/tools/script/SyncDataToStby.py -t restore --config-file /DWS/data2/finedisaster/backupRestore.ini --disaster-fine-grained >>/dev/null 2>&1 &" >>/dev/null 2>&1 &
成功啟動備份確認。
Ruby用戶分別登錄主備集群主節點沙箱,查詢SyncDataToStby.py進程是否存在。
ps ux | grep SyncDataToStby | grep -v grep
Ruby用戶登錄主/備集群主節點沙箱,使用roach的show-progress監控工具,查看備份/恢復進度。show-progress命令提供主備集群備份恢復進度等信息, 顯示結果為json格式,各字段含義請參考產品文檔。
python3 $GPHOME/script/SyncDataToStby.py -t show-progress --config-file /DWS/data2/finedisaster/backupRestore.ini
系統回顯:
{
"primary cluster": {
"key": "20231109_212030",
"priorKey": "20231109_211754",
"actionType": "Backup",
"progress": "100.00%",
"backupRate": {
"producerRate": "0MB/s",
"compressRate": "0MB/s",
"consumerRate": "0MB/s"
},
"currentStep": "FINISH",
"unrestoreKeys": "N/A",
"failedStep": "INIT",
"errorMsg": "",
"errorCode": "",
"actionStartTime": "2023-11-09 2128",
"actionEndTime": "2023-11-09 2149",
"updateTime": "2023-11-09 2150"
},
"standby cluster": {
"key": "20231109_175002",
"priorKey": "N/A",
"actionType": "Restore",
"progress": "100.00%",
"backupRate": {
"producerRate": "0MB/s",
"compressRate": "0MB/s",
"consumerRate": "0MB/s"
},
"currentStep": "FINISH",
"unrestoreKeys": "20231109_211754,20231109_212030",
"failedStep": "INIT",
"errorMsg": "",
"errorCode": "",
"actionStartTime": "2023-11-09 1707",
"actionEndTime": "2023-11-09 1715",
"updateTime": "2023-11-09 1715"
},
"apply": {
"backupState": "waiting",
"restoreState": "waiting",
"backupSuccessTime": "2023-11-09 2124",
"restoreSuccessTime": "2023-11-09 1755"
},
"latestBarrierTime": "",
"recovery point objective": "317",
"failover recovery point time": ""
}
show-progress命令顯示的主要字段釋義如下
priorKey:該備份集是基于這個backup key生成的。
actionType:備份集當前的操作類型。
取值包括如下:
Backup,表示備份階段。
Restore,表示恢復階段。
progress:備份或恢復操作的進度。
currentStep:備份或恢復正在執行的步驟。
unrestoreKeys:待恢復的key列表。
failedStep:備份或恢復失敗的步驟,初始值默認為INIT。
errorMsg:備份或恢復失敗的錯誤信息,如果成功,該字段則顯示成功的信息。
errorCode:備份或恢復的錯誤碼,該字段為預留字段,暫未使用。
actionStartTime:當前操作的開始時間。
actionEndTime:當前操作的結束時間。
updateTime:當前操作進度的刷新時間。
backupState:當前備份狀態(backuping/stopped/waiting/abnormal)。
restoreState:當前恢復狀態(restoring/stopped/waiting/abnormal)。
backupSuccessTime:上次成功備份結束的時間。
restoreSuccessTime:上次成功恢復結束的時間。
latestBarrierTime:上次主備集群一致點時間。
recovery point objective:rpo時間(當前主集群時間到最后一個恢復成功的備份集備份開始時間)。
failover recovery point time:failover未同步時間點。
4.3 結果驗證
4.3.1 功能驗證
同步前后進行數據一致性校驗,主表、備表數據進行checksum校驗,檢查是否同步正確(需排除由于接入業務導致的差異)。
4.3.2 性能驗證
通過show-progress監控工具可以看到最近一次備份、恢復耗時。
5. 解除容災
5.1 停止容災
# 主備集群取消沙箱外的定時容災任務,在備份/恢復任務前添加注釋符“#”,取消定時任務 crontab -e # 主集群Ruby用戶登錄主節點沙箱,停止備份 python3 $GPHOME/script/SyncDataToStby.py -t stop-backup --config-file /DWS/data2/finedisaster/backupRestore.ini --disaster-fine-grained # 備集群Ruby用戶登錄主節點沙箱,停止恢復 python3 $GPHOME/script/SyncDataToStby.py -t stop-restore --config-file /DWS/data2/finedisaster/backupRestore.ini --disaster-fine-grained
5.2 刪除容災
警告
當不再需要容災任務的時候,可以解除主備關系,恢復備集群的讀寫能力。刪除容災前需要先停止容災。
Ruby用戶登錄主集群主節點的沙箱內。
python3 $GPHOME/script/SyncDataToStby.py -t set-independent --config-file /DWS/data2/finedisaster/backupRestore.ini --disaster-fine-grained
系統回顯:
Delete csv file. Delete roachbackup file from XXX.XXX.XXX.XX Delete roachbackup file from XXX.XXX.XXX.XX Clear cluster disaster state.
6. 總結
本文介紹了在云上環境的雙集群(不跨Region不跨VPC)后臺手動部署并使用細粒度容災的主要步驟,分為容災前準備、細粒度容災操作和解除容災,使得用戶能快速方便得搭建起細粒度容災。
審核編輯:黃飛
-
容災系統
+關注
關注
0文章
4瀏覽量
5351
原文標題:詳解如何在數倉中搭建細粒度容災應用
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
細粒度圖像分析技術詳解

一種細粒度的面向產品屬性的用戶情感模型
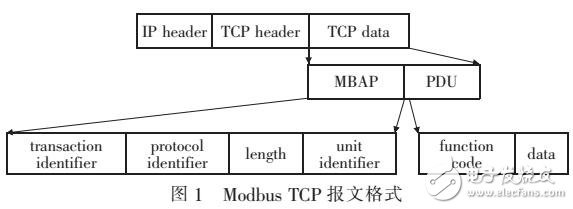
基于Modbus功能碼細粒度過濾算法的研究
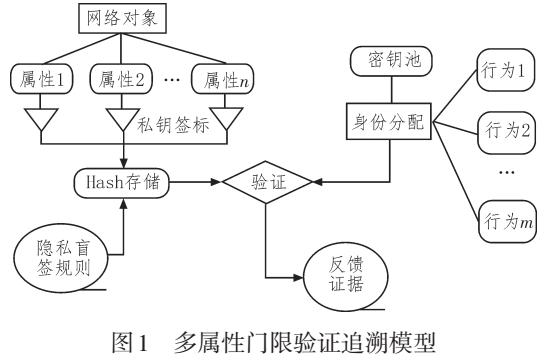
基于ABS細粒度隱私隔絕的身份追溯研究
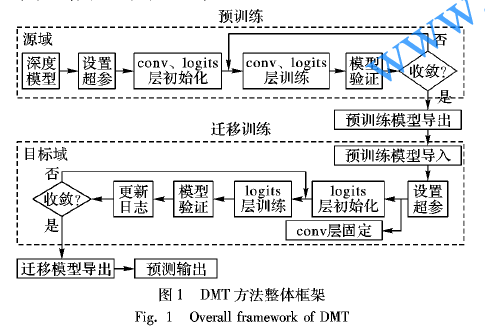
使用深度模型遷移進行細粒度圖像分類的方法說明
細粒度圖像分析任務在發展過程中面臨著獨特的挑戰
紹華為云在細粒度情感分析方面的實踐
結合非局部和多區域注意力機制的細粒度識別方法
基于文本的細粒度美妝圖譜視覺推理問題
基于BiLSTM-CRF的細粒度知識圖譜問答模型
機器翻譯中細粒度領域自適應的數據集和基準實驗
通過對比學習的角度來解決細粒度分類的特征質量問題





 工商網監
工商網監
評論