 FusionCompute集群重點知識點梳理
FusionCompute集群重點知識點梳理
智能內存復用
內存復用的定義:
通過內存復用技術將物理內存虛擬出更多的內存供虛擬機使用,使虛擬機內存規格總和可以大于主機物理內存。最終提高主機的虛擬機密度。
內存復用的三種技術∶
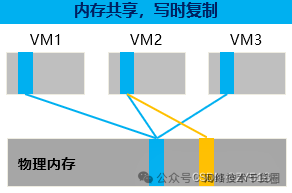
1)內存共享:虛擬機之間共享同一物理內存空間,此時虛擬機僅對內存做只讀操作。當虛擬機需要對內存進行寫操作時,開辟另一內存空間,并修改映射。
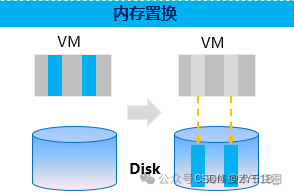
2)內存置換:虛擬機長時間未訪間的內存內容被置換到存儲(內存置換盤)中,并建立映射,當虛擬機再次訪間該內存內容時再置換回來。
3)內存氣泡:Hypervisor 通過內存氣泡將較為空閑的虛擬機內存釋放給內存使用率較高的虛擬機。從而提升內存利用率。
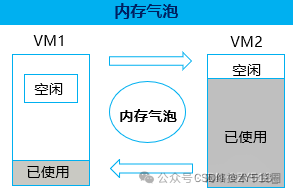
內存氣泡實現的原理和在虛擬機之問具體是如何操作?
Hypervisor對虛擬機進行監控,并主動回收虛擬機暫時不用的物理內存,分配給需要復用內存的虛擬機,內存的回收和分配均為系統動態執行,虛擬機上的應用無感知。
物理內存上的0頁和虛擬機內部0頁形成一個對應關系。從而實現所有VM在調用0頁時,調用的同一個物理內存。
內存復用限制?
嚴格意義來說沒有一個明確的限制,根據實際復用情況而定,官方要求一般不超過150%,最多不超過400%。實際企業業務場景下一般不打開內存復用。
1)主機需要配置足夠的交換空間才能保證內存復用功能的穩定運行。主機最大內存復用率依賴于swap 空間大小配置。具體計算公式如下:
主機支持的最大內存復用率=1+(主機 swap空間大小-虛擬化域物理內存大小和0.1)/虛擬化域物理內存大小。
2)內存交換分區默認與HostOS同盤配置.默認大小=主機物理內存大小粕60%,最大支持150%的復用率,當手動配置時要求最小30G。
3)內存復用與SR-IOV直通、GPU直通、SSD盤直通特性互斥。直通設備的虛擬機必須內存獨占,內存獨占后虛擬機的內存不會被交換到交換空間。內存復用(非100%內存預留)的虛擬機不能直通設備。
注意:內存復用的三個功能不能單獨使用,人為不可干預,當在集群中打開內存復用的開關,正常情況下內存復用將啟動,三個技術之間由hypervisor互相協同,共同保證了內存超分配的穩定。
虛擬機內存Qos :
提供虛擬機內存智能復用功能,依賴內存預留比。通過內存氣泡等內存復用技術將物理內存虛擬出更多的虛擬內存供虛擬機使用,每個虛擬機都能完全使用分配的虛擬內存。該功能可最大程度的復用內存資源,提高資源利用率,且保證虛擬機運行時至少可以獲取到預留大小的內存,保證業務的可靠運行。
系統管理員可根據用戶實際需求設置虛擬機內存預留。內存復用的主要原則是:優先使用物理內存。
包含以下幾個參數:
內存預留∶虛擬機預留的最低物理內存。預留的內存被會虛擬機獨占。即,一旦內存被某個虛擬機預留。即使虛擬機實際內存使用量不超過預留量。其他虛擬機也無法搶占該虛擬機的空閑內存資源;
內存份額:適用資源復用場景,按比例分配內存資源。如VM1和VM2的內存份額分別是20480,40960,物理資源總共為3G內存。那么在競爭情況下VIM1使用的內存為1G,VM2使用的內存為2G。
內存資源限領:控制虛擬機占用物理內存資源的上限。在開啟多個虛擬機時,虛擬機之間會相互競爭內存資源,為了使虛擬機的內存得到充分利用,盡量減少空閑內存。用戶可以在創建虛擬機時設置虛擬機配置文件中的內存上限參數,使服務器分配給該虛擬機的內存大小不超過內存上限值。
注意:IT管理員可以對虛擬機設定資源的使用上限,包括CPU、內存、網絡、磁盤IOPS等,防止非關鍵應用和惡意用戶爭搶共享資源。
集群計算資源調度:DRS、DPM
DRS ( Dynamic Resource Scheduler動態資源調度)∶
根據智能負載均衡算法。周期性檢查集群內主機的負載(CPU和內存)情況,在不同的主機之間遷移虛擬機,從而達到集群內主機間的負載均衡目的,保證系統良好的用戶體驗。
DPM ( Dynamic Power Management動態電源管理)∶
動態電源管理根據業務情況,智能地將部分物理機上下電,配置主機BMC參數之后,電源管理才生效,系統才可按照電源管理閾值對主機進行調度。電源管理依賴于計算資源調度。因此電源管理只有在開啟計算資源調度。并且遷移閾值的設置不為"保守"時生效。
Drs閾值配置操作流程︰
集群——配置——計算資源調度配置——可以設置自動化級別、閾值、調度基線。
虛擬機規則組∶
1)聚集虛擬機∶列出的虛擬機必須在同一主機上運行。一個虛擬機只能被加入一條聚集虛擬機規則中。
2)互斥虛擬機∶列出的虛擬機必須在不同主機上運行,一個虛擬機只能被加入一條互斥虛擬機規則中。
3)虛擬機到主機:關聯一個虛擬機組和主機組并設置關聯規則。指定所選的虛擬機組的成員是否能夠在特定主機組的成員上運行。
虛擬機 HA
虛擬機HA定義:是一種高可用特性,當物理機或虛擬機故障時,會根據集群HA策略將宕掉的虛擬機在正常工作的主機上開啟,從而減少業務中斷時間。
虛擬機HA實現原理:VRM或者集群的Master節點檢測到某計算節點故障或者虛擬機故障,或者設定的預留資源得不到保障時,主動根據自身記錄的虛擬機信息,在正常的節點上重新啟動故障虛擬機。
虛擬機HA流程:
1)當VM故障或者物理節點故障,VRM查詢VM狀態,發現VM故障。
2) VRM節點判斷VM有HA特性,則根據保存的VM信息(規格,卷等信息)選
擇可用的CNA主機啟動VM;
3)CNA節點收到HA請求,根據VM規格,卷信息創建新的VM;啟動過程中,
將VM之前的卷重新掛載,包括用戶卷。
虛擬機HA約束條件:
1)VM層面:安裝tools且運行正常,沒有外設綁定;
2)FC層面:必須為共享存儲。目標主機和源主機在同一集群且網絡相通,集群開啟HA功能。目標端有足夠的資源開啟VM。
主機故障控制策略︰
VM集群內恢復;VM原主機恢復;VM停止。
設置方法:集群——配置——HA配置——集群資源控制。
虛擬機HA屬性設置:虛擬機——選項———HA。
三種資源預留方式:
1)集群內所有節點均預留資源
2)指定集群內特定主機進行HA
3)集群內最多允許壞多少臺主機。
集群自治HA機制︰
即不依賴VRM實現虛擬機EA功能,而是在集群創建時自動推選出Master節點,由Master節點根據集群內各slave節點和Master節點之間的管理心跳和存儲心跳來判斷是否需要啟動虛擬機A機制(管理心跳是心跳包,存儲心跳通過在文件中寫數據來實現).根據需要由Master節點啟動A機制;自治場景下,E啟動的前提是管理心跳和存儲心跳都失效。用戶可以設置管理心跳走管理平面還是非管理平面。可以根據各網絡平面的負荷來確定。
注意:并不是集群中打開 HA開關,故障發生集群里的虛擬機就一定會執行HA策略,還需要在集群配置中配置虛擬機替代項來選擇需要HA的虛擬機。
審核編輯:黃飛
-
cpu
+關注
關注
68文章
10882瀏覽量
212237 -
虛擬機
+關注
關注
1文章
919瀏覽量
28286 -
CNA
+關注
關注
0文章
11瀏覽量
7098
原文標題:FusionCompute集群知識點
文章出處:【微信號:網絡技術干貨圈,微信公眾號:網絡技術干貨圈】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論