

來源:DeepHub IMBA
2023年是大語言模型和穩定擴散的一年,時間序列領域雖然沒有那么大的成就,但是卻有緩慢而穩定的進展。Neurips、ICML和AAAI等會議都有transformer 結構(BasisFormer、Crossformer、Inverted transformer和Patch transformer)的改進,還出現了將數值時間序列數據與文本和圖像合成的新體系結構(CrossVIVIT), 也出現了直接應用于時間序列的可能性的LLM,以及新形式的時間序列正則化/規范化技術(san)。
我們這篇文章就來總結下2023年深度學習在時間序列預測中的發展和2024年未來方向分析
Neurips 2023
在今年的NIPs上,有一些關于transformer 、歸一化、平穩性和多模態學習的有趣的新論文。但是在時間序列領域沒有任何重大突破,只有一些實際的,漸進的性能改進和有趣的概念證明。1、Adaptive Normalization for Non-stationary Time Series
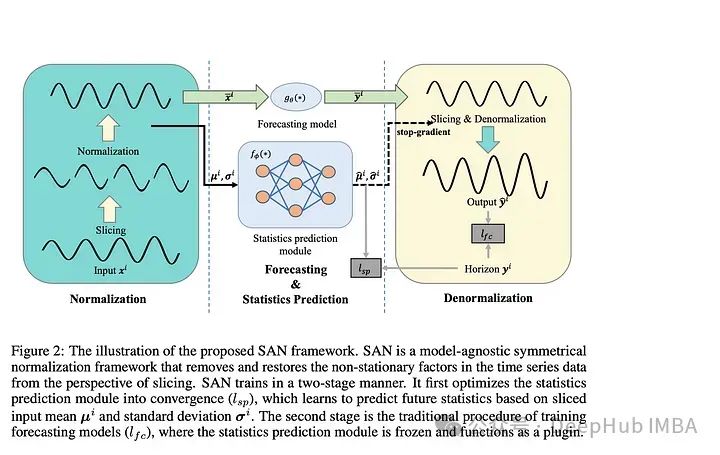
論文介紹了一種“模型不可知的歸一化框架”來簡化非平穩時間序列數據的預測。作者讓SAN分兩步操作:訓練一個統計預測模型(通常是ARIMA),然后訓練實際的深度時間序列基礎模型(使用統計模型對TS數據進行切片、歸一化和反歸一化)。統計模型對輸入時間序列進行切片,以便學習更健壯的時間序列表示并去除非平穩屬性。作者指出:“通過對切片級特性進行建模,SAN能夠消除局部區域的非平穩性。”SAN還顯式地預測目標窗口的統計信息(標準差/平均值)。這使得它在處理非平穩數據時,與普通模型相比,能夠更好地適應隨時間的變化。采用transformer 模型作為基本預測模型,對典型的時間序列預測基準(如電力、交換、交通等)進行指標驗證。作者發現SAN在這些基準數據集上持續提高了基本模型的性能(盡管他們沒有測試Inverted Transformer,因為這篇論文是在Inverted Transformer之前發布的)。由于該模型結合了一個統計模型(通常是ARIMA)和一個普通的transformer ,我認為調優和調試(特別是在新的數據集上)可能會很棘手和麻煩。因為幾乎所有的時間序列模型都將序列輸入長度作為超參數。另外就是“切片”的切片與普通的序列窗口有何不同?作者還是沒有說清楚。總的來說,我認為這仍然是一個相當強大的貢獻,因為它的實驗結果和即插即用屬性。2、BasisFormer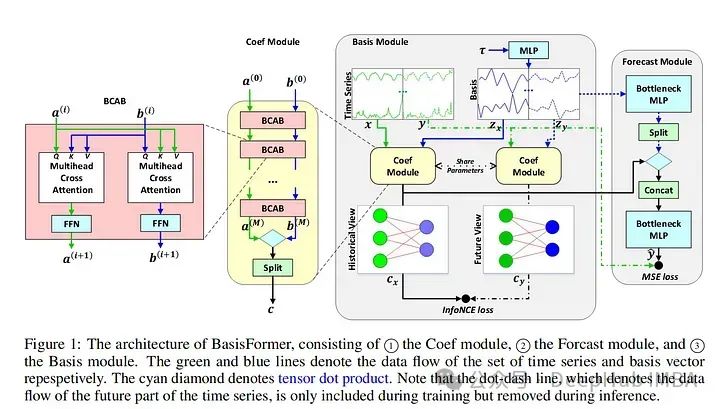 BasisFormer使用可學習和可解釋的“basis”來改進一般的transformer 體系結構。這里的“basis”指的是創建一個類似于NBeats的神經“basis”(例如,為基于多項式的函數學習趨勢、季節性等的系數)。該模型分為三個部分:基礎模塊、系數模塊和預測模塊。基模塊試圖以自監督的方式確定一組適用于歷史和未來時間序列數據的數據基礎趨勢。basis模塊通過對比學習和一個名為InfoNCE loss的特定損失函數(該函數試圖學習未來和過去時間序列之間的聯系)。coef模型試圖“模擬時間序列和一組基礎趨勢之間的相似性”。對于coef模型,作者使用了一個交叉注意力模塊,該模塊將basis和時間序列作為輸入。然后將輸出輸入到包含多個MLP的預測模塊中。作者在典型的時間序列預測數據集(ETH1, ETH, weather, exchange)上評估他們的論文。發現BasisFormer比其他模型(Fedformer、Informer等)的性能提高了11-15%。BasisFormer還沒有被拿來和Inverted Transformer比較,因為它還沒有發布。似乎Inverted Transformer和可能的Crossformer 可能會略優于BasisFormer。還記的去年我們看到了“Are Transformers Effective for Time Series Forecasting?”這篇論文批評了許多Transformers 模型,并展示了一個簡單的模型“D-Linear”如何超越它們。在2023年從BasisFromer開始,已經開始緩慢的解決這些問題,并超越上面提到的基準模型。這篇論文模型的技術是可靠的,但這篇論文優點難理解。因為作者介紹了學習“basis”的概念,但并沒有真正解釋這種方法的新穎性以及它與其他模型的不同之處。
BasisFormer使用可學習和可解釋的“basis”來改進一般的transformer 體系結構。這里的“basis”指的是創建一個類似于NBeats的神經“basis”(例如,為基于多項式的函數學習趨勢、季節性等的系數)。該模型分為三個部分:基礎模塊、系數模塊和預測模塊。基模塊試圖以自監督的方式確定一組適用于歷史和未來時間序列數據的數據基礎趨勢。basis模塊通過對比學習和一個名為InfoNCE loss的特定損失函數(該函數試圖學習未來和過去時間序列之間的聯系)。coef模型試圖“模擬時間序列和一組基礎趨勢之間的相似性”。對于coef模型,作者使用了一個交叉注意力模塊,該模塊將basis和時間序列作為輸入。然后將輸出輸入到包含多個MLP的預測模塊中。作者在典型的時間序列預測數據集(ETH1, ETH, weather, exchange)上評估他們的論文。發現BasisFormer比其他模型(Fedformer、Informer等)的性能提高了11-15%。BasisFormer還沒有被拿來和Inverted Transformer比較,因為它還沒有發布。似乎Inverted Transformer和可能的Crossformer 可能會略優于BasisFormer。還記的去年我們看到了“Are Transformers Effective for Time Series Forecasting?”這篇論文批評了許多Transformers 模型,并展示了一個簡單的模型“D-Linear”如何超越它們。在2023年從BasisFromer開始,已經開始緩慢的解決這些問題,并超越上面提到的基準模型。這篇論文模型的技術是可靠的,但這篇論文優點難理解。因為作者介紹了學習“basis”的概念,但并沒有真正解釋這種方法的新穎性以及它與其他模型的不同之處。
3、Improving day-ahead Solar Irradiance Time Series Forecasting by Leveraging Spatio-Temporal Context論文提出了一種基于混合(視覺和時間序列)深度學習的架構,用于預測第二天的太陽能產量。太陽能的生產經常受到云層覆蓋的影響,這在衛星圖像數據中可以看到,但在數值數據中沒有很好地體現出來。除了模型本身外,論文的另外貢獻是研究人員構建并開源的多模態衛星圖像數據集。作者描述了一個多級Transformers 架構,同時關注數值時間序列和圖像數據。時間序列數據通過時間Transformers 圖像通過視覺Transformers 。然后,交叉注意力模塊將前兩個模塊的圖像數據綜合起來。最后數據進入一個輸出預測的最終時態Transformers 。作者在論文中提到的另一個有用的想法被稱為ROPE或旋轉位置編碼。這將在編碼/位置嵌入中創建坐標對。這是用來描述從云層到太陽能站的距離。作者對他們的新數據集進行評估和基準測試,比較了Informer、Reformer、Crossformer和其他深度時間序列模型的性能。作者還在整合圖像數據方面區分了困難和容易的任務,他們的方法優于其他模型。這篇論文提供了一個有趣的框架,ROPE的概念也很有趣,對于任何使用坐標形式的地理數據的人都有潛在的幫助。數據集本身對于多模態預測的持續工作非常有用,這是一項非常有益的貢獻。
4、Large Language Models Are Zero-Shot Time Series Forecasters這篇論文探討了預訓練的llm能否直接以整數形式輸入時間序列數據,并以零樣本的方式預測未來數據。作者描述了使用GPT-3和GPT-4和開源LLMs不進一步修改結構直接與時間序列值交互的情況。最后還描述了他們對模型零樣本訓練行為起源的思考。作者假設,這種行為是提取知識的預訓練的普遍通用性的結果。在上面提到的標準時間序列基準數據集評估他們的模型。雖然模型沒有達到SOTA性能,但考慮到它完全是零樣本并且沒有額外的微調,所以表現還是很好的。
llm可以開箱即用地進行TS預測,因為它們都是在文本數據上訓練的。這一領域可能值得未來進一步探索,這篇論文是一個很好的一步。但是該模型目前只能處理單變量時間序列
ICML 、ICLR 2023
除了Neurips之外,ICML和ICLR 2023還重點介紹了幾篇關于時間序列預測/分析的深度學習的論文。以下是一些我覺得很有趣的,并且對未來一年仍有意義的建議:1、Crossformer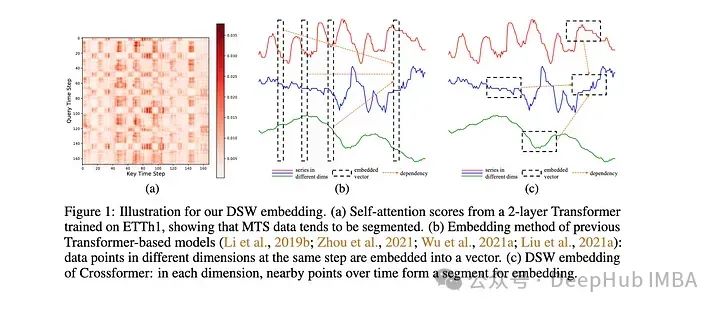
該模型是專門為多元時間序列預測(MTS)開發的。該模型采用維度分段嵌入(DSW)機制。DSW嵌入與傳統嵌入的不同之處在于它采用二維格式的數據。并且跨變量和時間維度顯式地從MTS數據生成段。該模型在標準MTS數據集(ETH, exchange等)上進行了評估:在發布時時優于大多數其他模型,例如Informer和DLinear。作者還對dSW進行了消融研究。這篇來自ICLR的關于的論文在預測河流流量時表現不錯,但是是在一次預測多個目標時,性能似乎會下降很多。也就是說,它的表現肯定比Informer和相關的Transformers 模型要好。
2、Learning Perturbations to Explain Time Series Predictions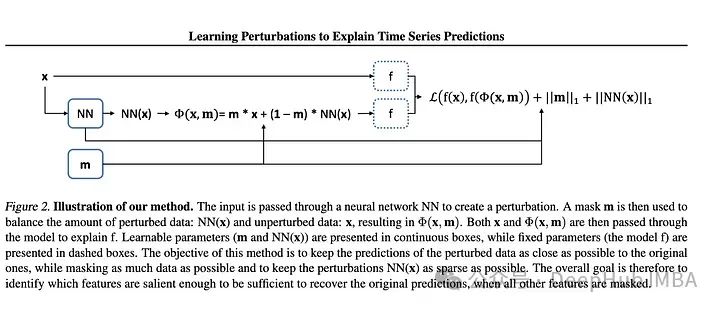
大多數用于深度學習解釋的擾動技術都是面向靜態數據(圖像和文本)的。但是對于時間序列特別是多元TS需要更大范圍的擾動來學習隨機影響。作者提出了一種基于深度學習的方法,可以學習數據的掩碼和相關的擾動,更好地解釋特征的重要性。然后將掩碼和擾動的輸入傳遞給模型,并將輸出與未擾動數據的輸出進行比較。據兩個輸出之間的差值計算損失。越來越多的研究人員正在深入研究解釋深度學習模型這是件好事。本文概述了現有的方法及其不足,并提出了一種改進的方法。我認為使用額外的神經網絡來學習擾動的想法增加了不必要的復雜性,因為每當我們增加更多的層和額外的網絡時,就會增加發生問題的概率,特別是在已經很大的網絡上。別忘了奧卡姆剃刀定律如無必要,勿增實體
3、Learning Deep Time Index Models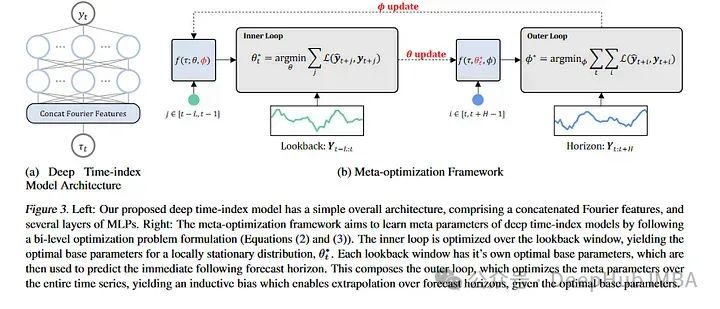
本文通過光流和元學習來討論預測,描述了學習如何預測非平穩時間序列。對于那些不熟悉的人來說,元學習通常被應用在計算機視覺數據集上,像MAML這樣的論文可以對新的圖像類進行少量的學習。MAML和其他模型都有一個內部循環和一個外部循環,其中外部循環教模型如何學習,內部循環對其進行微調以適應特定的任務。論文的作者采用了這一思想,并將其應用于幾乎將每個非平穩性視為一個新的學習任務。新的“任務”是長時間序列序列的塊。作者在ETH,temperature和exchange 數據集上測試了他們的模型。盡管他們的模型沒有達到SOTA的結果,但它與當前的SOTA體系結構具有競爭力。這篇論文為時間序列預測提供了一個有趣的角度,相對于常規方法有了一個新的突破,我想就是他雖然沒有超過SOTA但是還是被錄用的原因之一吧。
4、Inverted Transformers are Effective for Time Series Forecasting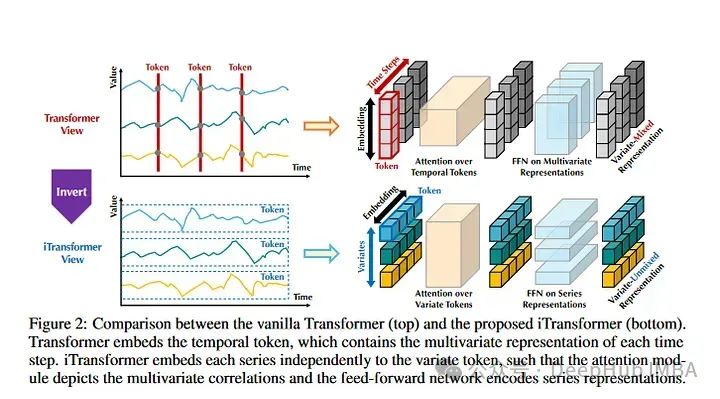
《Inverted Transformers》是2024年發表的一篇論文。這也是目前時間序列預測數據集上的SOTA。基本上,Inverted Transformers采用時間序列的Transformers架構并進行了翻轉。整個時間序列序列用于創建令牌。然后,時間序列彼此獨立進行嵌入表示。注意力對多個時間序列嵌入進行操作。它有點類似于Crossformer,但它的不同之處在于,它遵循標準Transformers架構。作者在標準時間序列數據集上評估模型目前優于所有其他模型,包括Informer, Reformer, Crossformer等。
這是一篇強大的論文,因為模型的表現優于現有的模型。但是在某些情況下,它優于模型的數值并不是那么顯著。所以可以優先看看這篇論文并且進行測試。
TimeGPT
最后說說TimeGPT,它沒有在任何主要會議上被接受,而且它的評估方法也優點可疑,由于它不幸地在互聯網上獲得了相當多的介紹,所以我們要再提一下:
1、作者沒有將他們的結果與其他SOTA類型模型進行比較,只是引用“測試集包括來自多個領域的30多萬個時間序列,包括金融、網絡流量、物聯網、天氣、需求和電力。”并且沒有提供測試集的鏈接,也沒有在他們的論文中說明這些數據集是什么。
2、論文中架構圖和模型體系結構的描述非常糟糕。這看起來就像是作者復制了其他論文的圖表,強加上注意力的定義和LLM相關的流行詞匯。
3、作者的Nixtla公司非常小,可能是一家小型初創公司,它是否有足夠的計算資源來完全訓練一個“成功的時間序列基礎模型”。雖然這樣說法優點歧視,但是如果我說我一個人用一周訓練了一個LLM,那估計都沒人相信,對吧。OpenAI、谷歌、亞馬遜、Meta等公司提供足夠的計算資源來創建龐大的模型。如果TimeGPT真的是一個簡單的Transformers 模型,并在大量的時間序列數據上訓練它,為什么其他機構,甚至個人不能用它的大量gpu做到這一點呢?答案是,事情肯定沒那么簡單。時間序列創建“基礎模型”的能力目前還不夠完善。多元時間序列預測的一個重要組成部分是學習協變量之間的依賴關系。MTS的維度在不同的數據集之間差異很大。對于具有文本數據的Transformers ,我們總是將一個單詞映射到一個數字id,然后創建一個特定維度的嵌入。對于MTS,不僅值可以更改,而且在一個數據集上可能有100個變量,而在另一個數據集上只有10個變量。這使得幾乎不可能設計所有用途的映射層來將不同大小的MTS數據集映射到公共嵌入維度。所以還記得我們前幾天發的Lag-Llama,也只是單變量的預測。
在其他時間序列(即使是那些具有相同數量變量的時間序列)上預訓模型不會產生改進的結果(至少在當前架構下不會)。
總結及未來方向分析
在2023年,我們看到了Transformers 在時間序列預測中的一些持續改進,以及llm和多模態學習的新方法。隨著2024年的進展,我們將繼續看到在時間序列中使用Transformers 架構的進步和改進。可能會看到在多模態時間序列預測和分類領域的進一步發展。
作者:Isaac Godfried
-
AI
+關注
關注
88文章
34421瀏覽量
275750 -
語言模型
+關注
關注
0文章
560瀏覽量
10695 -
深度學習
+關注
關注
73文章
5555瀏覽量
122538
發布評論請先 登錄
使用BP神經網絡進行時間序列預測
時空引導下的時間序列自監督學習框架






 工商網監
工商網監

評論