") 黑馬Groq單挑英偉達(dá),AI芯片要變天?
黑馬Groq單挑英偉達(dá),AI芯片要變天?
科技云報(bào)道原創(chuàng)。
近一周來(lái),大模型領(lǐng)域重磅產(chǎn)品接連推出:OpenAI發(fā)布“文字生視頻”大模型Sora;Meta發(fā)布視頻預(yù)測(cè)大模型 V-JEPA;谷歌發(fā)布大模型 Gemini 1.5 Pro,更毫無(wú)預(yù)兆地發(fā)布了開(kāi)源模型Gemma......
難怪網(wǎng)友們感嘆:“一開(kāi)年AI發(fā)展的節(jié)奏已經(jīng)如此炸裂了么!”
但更令人意想不到的是,AI芯片領(lǐng)域處于絕對(duì)霸主地位的英偉達(dá),竟然也遇到了挑戰(zhàn),而且挑戰(zhàn)者還是一家初創(chuàng)公司。
在這家名叫Groq的初創(chuàng)芯片及模型公司官網(wǎng)上,它號(hào)稱(chēng)是世界最快大模型,比GPT-4快18倍,測(cè)試中最快達(dá)到破紀(jì)錄的每秒吞吐500 tokens。
這閃電般的速度,來(lái)源于Groq自研的LPU(語(yǔ)言處理單元),是一種名為張量流處理器(TSP)的新型處理單元,自然語(yǔ)言處理速度是英偉達(dá)GPU 10倍,做到了推理的最低延遲。
“快”字當(dāng)頭,Groq可謂賺足眼球。Groq還喊話各大公司,揚(yáng)言在三年內(nèi)超越英偉達(dá)。
事實(shí)上,在這一波AI熱潮中,“天下苦英偉達(dá)久矣”。英偉達(dá)GPU芯片價(jià)格一再被炒高,而Groq的LPU架構(gòu)能“彎道超車(chē)”,顯然是眾望所歸。
因此,不少輿論驚呼Groq要顛覆英偉達(dá),也有業(yè)內(nèi)人士認(rèn)為Groq想要“平替”英偉達(dá)還有很長(zhǎng)的路要走。
但無(wú)論持哪種觀點(diǎn),Groq的出現(xiàn)不僅是對(duì)現(xiàn)有芯片架構(gòu)和市場(chǎng)格局的挑戰(zhàn),也預(yù)示著AI芯片及其支撐的大模型發(fā)展方向正在發(fā)生變化——聚焦AI推理。
Groq LPU:快字當(dāng)頭
據(jù)介紹,Groq的芯片采用14nm制程,搭載了230MB大靜態(tài)隨機(jī)存儲(chǔ)器(SRAM)以保證內(nèi)存帶寬,片上內(nèi)存帶寬達(dá)80TB/s。在算力方面,該芯片的整型(8位)運(yùn)算速度為750TOPs,浮點(diǎn)(16位)運(yùn)算速度為188TFLOPs。
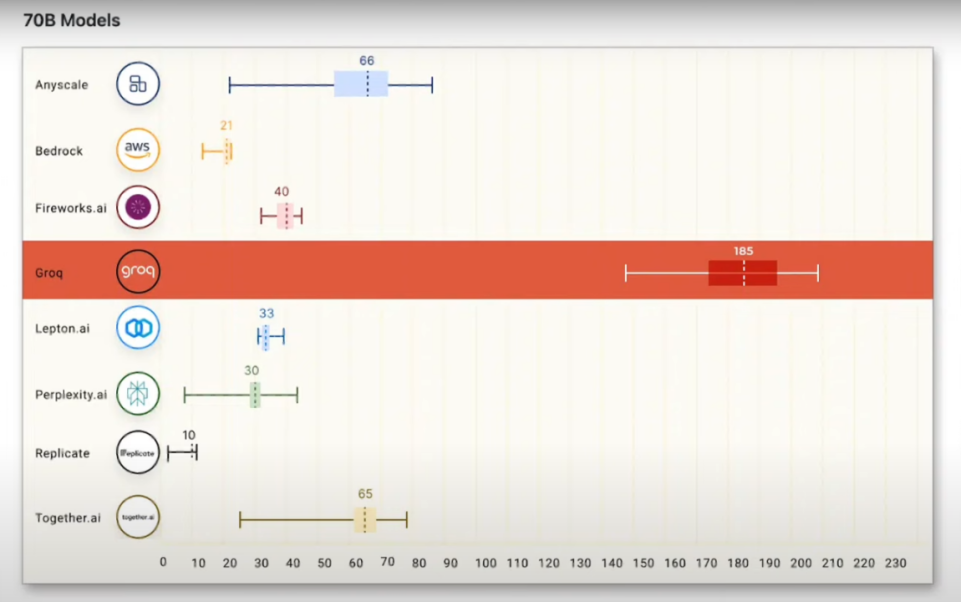
Anyscale的LLMPerf排行顯示,在Groq LPU推理引擎上運(yùn)行的Llama 2 70B,輸出tokens吞吐量快了18倍,優(yōu)于其他所有云推理供應(yīng)商。
據(jù)網(wǎng)友測(cè)試,面對(duì)300多個(gè)單詞的“巨型”prompt(AI模型提示詞),Groq在不到一秒鐘的時(shí)間里,就為一篇期刊論文創(chuàng)建了初步大綱和寫(xiě)作計(jì)劃。此外,Groq還完全實(shí)現(xiàn)了遠(yuǎn)程實(shí)時(shí)的AI對(duì)話。
電子郵件初創(chuàng)企業(yè)Otherside AI的首席執(zhí)行官兼聯(lián)合創(chuàng)始人馬特·舒默(Matt Shumer)在體驗(yàn)Groq后稱(chēng)贊其快如閃電,能夠在不到一秒鐘的時(shí)間內(nèi)生成數(shù)百個(gè)單詞的事實(shí)性、引用性答案。
更令人驚訝的是,其超過(guò)3/4的時(shí)間用于搜索信息,而生成答案的時(shí)間卻短到只有幾分之一秒。
Groq之所以“快如閃電”,其創(chuàng)新的核心在于LPU。
據(jù)官方信息顯示,LPU推理引擎是一種新型的端到端處理單元系統(tǒng),它為計(jì)算密集型應(yīng)用提供最快的推理能力,這些應(yīng)用具有序列組件,例如AI語(yǔ)言應(yīng)用程序(LLM)。
LPU旨在克服LLM的兩個(gè)瓶頸:計(jì)算密度和內(nèi)存帶寬。
就LLM而言,LPU比GPU和CPU具有更大的計(jì)算能力。這減少了每個(gè)單詞的計(jì)算時(shí)間,從而可以更快地生成文本序列。
同時(shí),與利用高帶寬內(nèi)存(HBM)的GPU不同,Groq的LPU利用SRAM進(jìn)行數(shù)據(jù)處理,比HBM快約20倍,從而顯著降低能耗并提高效率。
GroqChip的獨(dú)特架構(gòu)與其時(shí)間指令集相結(jié)合,可實(shí)現(xiàn)自然語(yǔ)言和其他順序數(shù)據(jù)的理想順序處理。
消除外部?jī)?nèi)存瓶頸,不僅使LPU推理引擎能夠在LLM上提供比GPU高幾個(gè)數(shù)量級(jí)的性能。
而且由于LPU只進(jìn)行推理計(jì)算,需要的數(shù)據(jù)量遠(yuǎn)小于模型訓(xùn)練,從外部?jī)?nèi)存讀取的數(shù)據(jù)更少,消耗的電量也低于GPU。
此外,LPU芯片設(shè)計(jì)實(shí)現(xiàn)了多個(gè)TSP的無(wú)縫連接,避免了GPU集群中的瓶頸問(wèn)題,顯著地提高了可擴(kuò)展性。
因此,Groq公司宣稱(chēng),其LPU所帶來(lái)的AI推理計(jì)算是革命性的。
在AI推理領(lǐng)域挑戰(zhàn)GPU
盡管Groq高調(diào)喊話,但想要“平替”英偉達(dá)GPU并不容易。從各方觀點(diǎn)來(lái)看,Groq的芯片還無(wú)法與之分庭抗禮。
原Facebook人工智能科學(xué)家、原阿里技術(shù)副總裁賈揚(yáng)清算了一筆賬,因?yàn)镚roq小得可憐的內(nèi)存容量,在運(yùn)行Llama 2 70B模型時(shí),需要305張Groq卡才足夠,而用英偉達(dá)的H100則只需要8張卡。
從目前的價(jià)格來(lái)看,這意味著在同等吞吐量下,Groq的硬件成本是H100的40倍,能耗成本是10倍。
但跳出單純的價(jià)格對(duì)比,Groq LPU的解決方案依然展現(xiàn)出了不小的應(yīng)用潛力。
根據(jù)機(jī)器學(xué)習(xí)算法步驟,AI芯片可以劃分為訓(xùn)練AI芯片和推理AI芯片。
訓(xùn)練芯片是用于構(gòu)建神經(jīng)網(wǎng)絡(luò)模型,需要高算力和通用性,追求的是高計(jì)算性能(高吞吐率)、低功耗。
推理芯片是對(duì)訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)模型進(jìn)行運(yùn)算,利用輸入的新數(shù)據(jù)來(lái)一次性獲得正確結(jié)論。
因此完成推理過(guò)程的時(shí)間要盡可能短、低功耗,更關(guān)注用戶體驗(yàn)方面的優(yōu)化。
雖然現(xiàn)階段GPU利用并行計(jì)算的優(yōu)勢(shì)在AI領(lǐng)域大獲全勝,但由于英偉達(dá)GPU的獨(dú)有架構(gòu),英偉達(dá)H100等芯片在推理領(lǐng)域算力要求遠(yuǎn)不及訓(xùn)練端,這也就給Groq等競(jìng)爭(zhēng)對(duì)手留下了機(jī)會(huì)。
因此,專(zhuān)注于AI推理的Groq LPU,得以在推理這個(gè)特定領(lǐng)域挑戰(zhàn)英偉達(dá)GPU的地位。從測(cè)試結(jié)果上看,Groq能夠達(dá)到令人滿意的“秒回”效果。
這也在一定程度上顯示了通用芯片與專(zhuān)用芯片的路徑分歧。
隨著AI和深度學(xué)習(xí)的不斷發(fā)展,對(duì)專(zhuān)用芯片的需求也在增長(zhǎng)。
各種專(zhuān)用加速器如FPGA、ASIC以及其他初創(chuàng)公司的AI芯片已經(jīng)不斷涌現(xiàn),它們?cè)诟髯陨瞄L(zhǎng)的領(lǐng)域內(nèi)展現(xiàn)出了挑戰(zhàn)GPU的可能性。
相比于英偉達(dá)通用型AI芯片,自研AI芯片也被稱(chēng)作ASIC,往往更適合科技公司本身的AI工作負(fù)載需求且成本較低。
比如,云巨頭AWS就推出了為生成式AI和機(jī)器學(xué)習(xí)訓(xùn)練而設(shè)計(jì)全新自研AI芯片AWS Trainium2,性能比上一代芯片提高到4倍,可提供65ExaFlops超算性能。
微軟也推出第一款定制的自研CPU系列Azure Cobalt和AI加速芯片Azure Maia,后者是微軟首款A(yù)I芯片,主要針對(duì)大語(yǔ)言模型訓(xùn)練,預(yù)計(jì)將于明年初開(kāi)始在微軟Azure數(shù)據(jù)中心推出。
谷歌云也推出了新版本的TPU芯片TPU v5p,旨在大幅縮減訓(xùn)練大語(yǔ)言模型時(shí)間投入。
無(wú)論是大廠自研的AI芯片,還是像Groq LPU這樣的專(zhuān)用芯片,都是為了優(yōu)化特定AI計(jì)算任務(wù)的性能和成本效率,同時(shí)減少對(duì)英偉達(dá)等外部供應(yīng)商的依賴(lài)。
作為GPU的一個(gè)重要補(bǔ)充,專(zhuān)用芯片讓面對(duì)緊缺昂貴的GPU芯片的企業(yè)有了一個(gè)新的選擇。
AI芯片聚焦推理
隨著AI大模型的快速發(fā)展,尤其是Sora以及即將推出的GPT-5,都需要更強(qiáng)大高效的算力。但GPU在推理方面的不夠高效,已經(jīng)影響到了大模型業(yè)務(wù)的發(fā)展。
從產(chǎn)業(yè)發(fā)展趨勢(shì)來(lái)看,AI算力負(fù)載大概率將逐步從訓(xùn)練全面向推理端遷移。
華爾街大行摩根士丹利在2024年十大投資策略主題中指出,隨著消費(fèi)類(lèi)邊緣設(shè)備在數(shù)據(jù)處理、存儲(chǔ)端和電池續(xù)航方面的大幅改進(jìn),2024年將有更多催化劑促使邊緣AI這一細(xì)分領(lǐng)域迎頭趕上,AI行業(yè)的發(fā)展重點(diǎn)也將從“訓(xùn)練”全面轉(zhuǎn)向“推理”。
高通CEO Amon也指出,芯片制造商們的主要戰(zhàn)場(chǎng)不久后將由“訓(xùn)練”轉(zhuǎn)向“推理”。
Amon在采訪時(shí)表示:“隨著AI大模型變得更精簡(jiǎn)、能夠在設(shè)備上運(yùn)行并專(zhuān)注于推理任務(wù),芯片制造商的主要市場(chǎng)將轉(zhuǎn)向‘推理’,即模型應(yīng)用。預(yù)計(jì)數(shù)據(jù)中心也將對(duì)專(zhuān)門(mén)用于已訓(xùn)練模型推理任務(wù)的處理器產(chǎn)生興趣,一切都將助力推理市場(chǎng)規(guī)模超越訓(xùn)練市場(chǎng)。”
在最新的財(cái)報(bào)電話會(huì)上,英偉達(dá)CFO Colette Kress表示,大模型的推理場(chǎng)景已經(jīng)占據(jù)英偉達(dá)數(shù)據(jù)中心40%的營(yíng)收比例。這也是判斷大模型行業(yè)落地前景的重要信號(hào)。
事實(shí)上,巨頭們的一舉一動(dòng)也在印證這一趨勢(shì)的到來(lái)。
據(jù)路透社報(bào)道,Meta將推新款自研AI推理芯片Artemis。預(yù)計(jì)Meta可于年內(nèi)完成該芯片在自有數(shù)據(jù)中心的部署,與英偉達(dá)GPU協(xié)同提供算力。
而英偉達(dá)也通過(guò)強(qiáng)化推理能力,鞏固自身通用GPU市占率。
在下一代芯片H200中,英偉達(dá)在H100的基礎(chǔ)上將存儲(chǔ)器HBM進(jìn)行了一次升級(jí),為的也是提升芯片在推理環(huán)節(jié)中的效率。
不僅如此,隨著各大科技巨頭、芯片設(shè)計(jì)獨(dú)角獸企業(yè)都在研發(fā)更具效率、部分替代GPU的芯片,英偉達(dá)也意識(shí)到這一點(diǎn),建立起了定制芯片的業(yè)務(wù)部門(mén)。
總的來(lái)說(shuō),以現(xiàn)在AI芯片供不應(yīng)求的現(xiàn)狀,GPU的增長(zhǎng)暫時(shí)還不會(huì)放緩。但隨著AI發(fā)展趨勢(shì)的快速變化,英偉達(dá)不可能是永遠(yuǎn)的王者,而Groq也絕對(duì)不是唯一的挑戰(zhàn)者。
【關(guān)于科技云報(bào)道】
專(zhuān)注于原創(chuàng)的企業(yè)級(jí)內(nèi)容行家——科技云報(bào)道。成立于2015年,是前沿企業(yè)級(jí)IT領(lǐng)域Top10媒體。獲工信部權(quán)威認(rèn)可,可信云、全球云計(jì)算大會(huì)官方指定傳播媒體之一。深入原創(chuàng)報(bào)道云計(jì)算、大數(shù)據(jù)、人工智能、區(qū)塊鏈等領(lǐng)域。
審核編輯 黃宇
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3770瀏覽量
90984 -
AI芯片
+關(guān)注
關(guān)注
17文章
1879瀏覽量
34990 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
刷屏的Groq芯片,速度遠(yuǎn)超英偉達(dá)GPU!成本卻遭質(zhì)疑
英偉達(dá)加速認(rèn)證三星新型AI存儲(chǔ)芯片
AI芯片巨頭英偉達(dá)漲超4% 英偉達(dá)市值暴增7500億
英偉達(dá)回應(yīng)AI芯片推遲發(fā)布傳聞

英偉達(dá)TITAN AI顯卡曝光,性能狂超RTX 4090達(dá)63%!# 英偉達(dá)# 顯卡
英偉達(dá)AI芯片需求激增,封測(cè)廠訂單量或翻倍
英偉達(dá)Blackwell芯片已投產(chǎn),預(yù)告未來(lái)AI芯片發(fā)展
英偉達(dá)首席執(zhí)行官黃仁勛:AI模型推動(dòng)英偉達(dá)AI芯片需求
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
英偉達(dá)最新AI芯片售價(jià)將超3萬(wàn)美元
英偉達(dá)要小心了!爆火的Groq芯片能翻盤(pán)嗎?AI推理速度「吊打」英偉達(dá)?
英偉達(dá)被控延遲出貨,阻礙競(jìng)爭(zhēng)
“網(wǎng)紅”芯片Groq讓英偉達(dá)蒸發(fā)5600億






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論