 7萬張H100打造的OpenAI文生視頻Sora功能原理詳解|Sora注冊全攻略
7萬張H100打造的OpenAI文生視頻Sora功能原理詳解|Sora注冊全攻略
近日,OpenAI發布的基于Transformer架構的文生視頻Sora,可謂是在AI圈掀起新的熱潮。該模型具有強大的視頻生成能力,可產生高達一分鐘的高清視頻,并且用戶可以自由指定視頻時間長度、分辨率和寬高比。據OpenAI的觀點,Sora的誕生可能預示著物理世界通用模擬器的重大突破。
360集團創始人兼董事長周鴻祎在2024年亞布力中國企業家論壇第二十四屆年會上分享了其對Sora模型的觀察。“Sora的推出預示AI視頻生成能力的突破,不僅推動了AI的發展,而且為企業的未來指明新的發展方向。通用人工智能的發展可能未來兩三年內就能實現。”
他鼓勵中國企業全面投身AI應用和研究,挖掘AI潛力,以尋找業務和工作流程中可能實現效益提升的機會。建議大型互聯網公司應在通用大模型領域持續加大投入,而企業家則應構建企業級、產業級、場景化的垂直大模型;呼吁所有企業在AI的發展過程中積極參與,以適應和引領時代的變革。
周鴻祎對Sora模型的贊揚不僅限于其出色的視頻生成能力,還深入到Sora模型的本質,強調其在模型理解世界的特別之處,解決了過去AI只能通過語言表達的局限,使得AI在認知層面有了"眼睛"。
他還以Sora模型為例,總結了人工智能的五個發展階段:傳統AI,人機交互,機器對世界的理解(基本實現通用AI),強人工智能,以及如果AI能總結出像愛因斯坦相對論那樣的公式,就進入超級人工智能階段。對于AI發展越來越快速的未來充滿了期待和信心。
本文將深入探討Sora文生視頻技術的原理,做一個全面的視頻大模型回顧及Sora與其他 AI 文本視頻模型性能對比,對SORA模型的算力空間進行測算分析。讓我們一起深入研究這個令人振奮的主題。
附:Sora賬號一站式申請注冊全攻略
關鍵詞:Transformer;Sora;強人工智能;周鴻祎;AI服務器;A100;H100;A800;A100;算力空間;文本視頻大模型Sora;Sora大模型;Sora AI
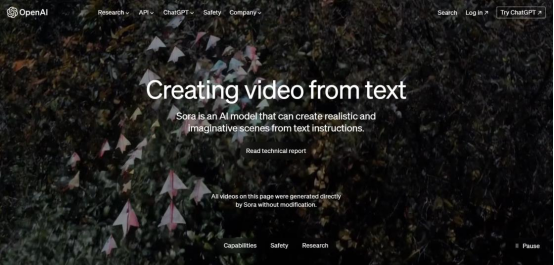
OpenAI 發布文生視頻大模型 Sora
Sora文生視頻技術原理
Sora是一款基于文本生成視頻的新產品,被認為是首個達到基礎模型等級品質的影片生成模型。其高品質的生成能力使其在影視娛樂、創作和廣告等領域有著巨大的應用潛力。該模型的重要性在于它能夠根據簡單的文字描述生成各種類型的影片,包括電影預告片、寫實影片和虛擬影片,其品質令人驚嘆。Sora的發布標志著影片生成領域的一次革命,提供高度可控的模擬器,用于學習影片生成的各個方面,包括3D和4D的生成,以及物理性質和材質的模擬。技術上,Sora采用diffusion transformer模型,結合傳統的Summator和DALL-E模型,并使用recaptioning技術和大量的合成數據進行訓練。未來,Sora可能會面臨一些挑戰,比如開源和產品端結合等,但它在影片生成領域的潛力是巨大的,對AR/VR/MR等領域也有著廣闊的應用前景。
通過Sora,我們可以想象到一個新的世界,一個充滿無限可能性的世界。Sora的聯想力越豐富,就能夠產生更多、更豐富的時空碎塊,這將為影片生成領域帶來更多的創新和可能性。Diffusion作為一個畫師,根據關鍵詞特征值對應的可能性概率,在視頻庫中尋找合適的素材,從而為Sora提供更多的靈感和創意。通過Diffusion和Transformer的共同聯想,Sora可以從巨大的視頻庫中生拉硬拽,將一張張碎塊拼接成一部完整的影片,每秒播放幾十張,呈現出令人驚嘆的效果。
Sora的超高生成能力與廣告界和娛樂領域的無窮可能性聯系緊密,不容忽視的是Sora創新融合藝術與技術,致力于完美的光線追蹤渲染效果,使創意成為藝術家的畫布。揮灑自如的同時,更要強調Sora的巨大突破,那就是其"超大的時長"能力,能夠連續生成高達一分鐘的高清視頻。在保持視角和風格一致性的同時,呈現的影片如同杰出藝術家在畫布上精心調色,呼之欲出。
一、功能解讀
OpenAI發布的Sora視頻大模型主要具有生成視頻、編輯視頻以及從文本生成圖像三項核心功能。其中,從文本生成視頻和視頻編輯是其最主要的AI功能。這些功能通過確保“物理世界常識”始終存在,以實現通用模擬工具的作用。換言之,Sora利用其核心AI功能,為用戶提供一個能夠持續應用物理世界常識的通用模擬工具。
1、文生視頻
Sora基于DALL·E圖像生成和視頻生成技術,可根據用戶提示詞在一分鐘以內生成各種分辨率和寬高比的視頻。其3D一致性確保每個連續鏡頭中,物體間的空間關系維持一致,符合物理邏輯。遠距離的相干性和物體的持久性也在其中,即便在視角變化或物體被遮擋的情況下,被遮擋的物體仍能保持其存在。Sora精細呈現物體與世界的互動性,無論是畫布上的筆跡還是食物上的咬痕都不會被忽視,以此確保與真實世界的交互始終真實有效。不僅如此,Sora還能模擬數字世界,例如像Minecraft這類的虛擬環境,展現出對實際世界和虛擬世界的雙重模擬能力,這讓Sora有望成為通用的世界模擬工具。
2、視頻編輯
Sora擁有時空視頻擴展能力,能夠精準分析視頻中的時間線和空間關系。其具有強大的場景和風格改變能力,一鍵設置和風格化渲染使視頻制作更為簡便。Sora甚至可以無縫連接不同主題的場景視頻,展現出創新的鏡頭語言和IP重組。值得一提的是,Sora能通過插值技術,實現兩個截然不同主題和場景的視頻之間的平滑過渡,這為視頻創作提供無限可能。
3、掌控三維空間與視頻連貫性的物理引擎
Sora模型的一大亮點是其對三維空間中物體的運動和交互的連貫性和邏輯性的掌控。該模型通過直接處理大量訓練視頻,無需預處理或調整,從而成功地學習物理世界建模。該技能使得Sora能生成在數字世界中的視頻,其中物體和角色在三維空間中的移動和互動都非常連貫,即使物體被遮擋或離開畫面,也能保持一致性。
從Sora到Lumiere等先進的視頻模型,其關鍵性的轉變在于不再過度依賴空間關聯,而是加強對時間關聯的理解。這些模型通過海量的視頻數據學習和表征狀態空間的動態性并處理非馬爾可夫性。
然而,僅通過時間和空間的碎片往往無法理解底層規則,我們需要更深入的挖掘。科學家們可以將他們在物理、化學、生物等領域的長期研究以圖像或視頻的形式輸入到這些視頻生成的大模型中,進一步助力發掘潛在規律。
Sora的獨特之處在于將視頻生成模型泛化為物理引擎。如果我們能夠將它和LLM GPT整合并實時運用,則可以接近或甚至達到人類感知的水平。然而,感知到概念的轉換需要處理好生成過程中的采樣和變分推斷。
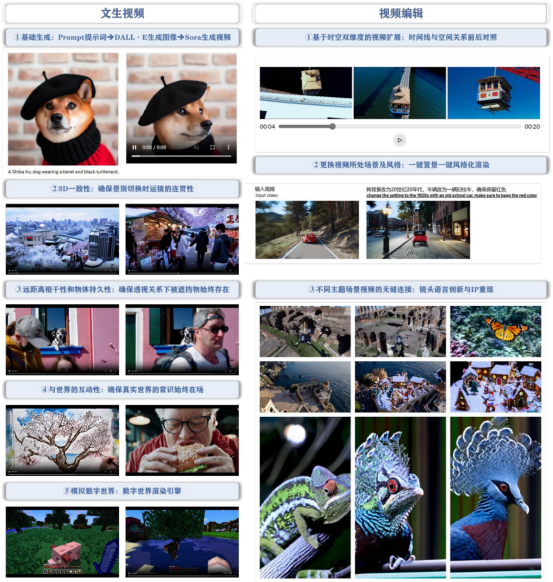
Sora 功能一覽:文生視頻+視頻編輯,確保“物理世界常識”始終在場
二、Spacetime Latent Patches 潛變量時空碎片, 建構視覺語言系統
對視覺數據建模,Sora采用類似的Token Embedding策略,即通過高效且易于擴展的視覺數據表示模型碎片(Patch),為各種類型的視頻和圖像提供精準的表征。在這個過程中,視頻被壓縮并映射到一個低維的潛在變量空間,然后拆解成時空碎片。
在此基礎上,Sora展示了其多樣的能力:
1、理解自然語言
通過將DALLE3生成的視頻文本描述和GPT生成的豐富文本prompts結合,Sora在訓練過程中確立與GPT之間更精準的語言關系,使Token和Patch之間的“文字”達成統一。
2、將圖像和視頻作為prompts
用戶提供圖像或視頻可以被自然地編碼成時空碎片,以此進行各種圖像和視頻編輯任務,如生成動態圖像、視頻生成擴展、視頻連接或編輯等。
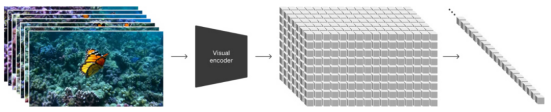
三、基于 Patches 視覺特征標記的 Diffusion Transformer 模型
OpenAI將Sora定義為Diffusion Transformer,該概念源自伯克利的研究成果Diffusion Transformer (DiT),并以此作為Sora設計架構的重要基礎。這項工作名為"采用Transformer的可擴展擴散模型Scalable diffusion models with transformers",在AI研究領域有著廣泛影響。
擴散模型的核心工作原理包括在訓練數據中添加高斯噪聲,然后學習反向去噪過程及恢復數據。當訓練完成后,模型通過已學習的去噪過程將隨機抽取的噪聲轉化為數據。在模型工作過程中,通過逐漸添加噪聲,使圖像向純高斯噪聲轉化。訓練擴散模型的目標是學習逆向過程,進而生成新數據。從信息熵角度看,原始的結構化信息熵較低,通過多次添加高斯噪聲,信息熵會提高,逐漸掩蓋原始結構信息。而在非結構化部分,即使只添加少量噪聲也會使得信息變得混亂。學習目標就是找到這些原始結構化信息,可以理解為對“底片”的提取。
基本的擴散模型在處理過程中,不進行降維或壓縮,保持較高的還原度,其學習過程主要參數化概率分布并用KL散度來衡量概率分布之間的距離。而Diffusion Transformer(DiT)模型則引入Transformer,對信息進行降維和壓縮,并采用多層多頭注意力和歸一化技術,這使得它在擴散方式下提取“底片”信息的原理與LLM的重整化保持一致。
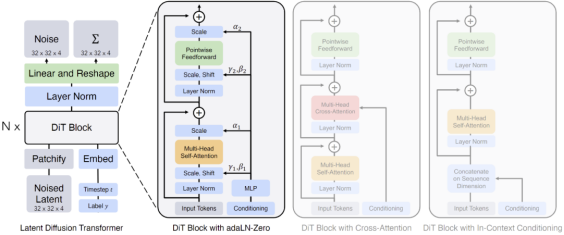
Sora是一個基于Patches視覺特征標記的Diffusion Transformer模型,其靈感源自于有著統一的代碼、數學等自然語言文本模式的Tokens文本特征標記。其核心包括以下四個步驟:
1、視覺數據轉化
將視覺數據,如視頻和圖像,壓縮到低維潛在空間,并將其分解為帶有時空特征的Patches。
2、視頻壓縮網絡構建
訓練一個視頻壓縮網絡,將原始視頻壓縮成潛在特征,并在此壓縮空間中進行訓練生成視頻。同時,訓練一個解碼器模型,將生成的潛在特征映射回像素空間。
3、提取視覺數據的時空潛在特征
從已壓縮的輸入視頻中提取時空特征Patches。因為圖像可以被看做是單幀視頻,所以這個方案也適用于圖像。基于Patches的表達使Sora對不同分辨率、視頻時間和寬高比的視頻和圖像進行訓練,且在推理階段,可通過以正確大小的網格來排列隨機初始化的Patches控制生成視頻的大小。
4、推廣Transformer模型到視頻生成領域
Sora是一個Diffusion Transformer模型,接受輸入嘈雜Patches,通過訓練預測原始干凈Patches,生成高清視頻。隨著訓練計算量的增加,樣本質量也有顯著提高。
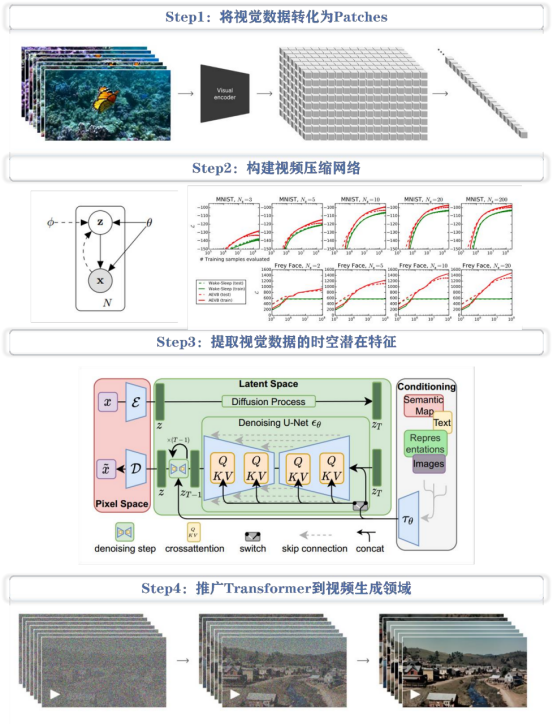
Sora 技術路徑:基于 Patches 視覺特征標記的 Diffusion Transformer 模型
四、Patches 實現更靈活采樣+更優化構圖
Patches的使用提供更靈活采樣和更優化視頻構圖兩大優勢。
1、訓練角度
利用Patches進行原生視頻采樣擴大樣本規模并避免標準化樣本的步驟。在過去,處理不同分辨率和寬高比的視頻通常需要進行剪輯或調整至標準格式。
2、推理角度
根據原生視頻訓練模型在生成新視頻時,其構圖和取景更為優化。舉例來說,采樣標準化樣本生成視頻在敘事主體部分被硬性分割開,而原生樣本生成視頻則保證敘事主體完整地出現在中間位置。

Why Patches?——更靈活的采樣+更優化的構圖
Sora通過結合DALL·E 3 DCS的描述性標題重述和GPT標題擴寫方法,提高語言理解能力。為了訓練文本到視頻的生成系統,OpenAI使用DALL·E 3生成描述性的文本字幕,應用于訓練集中的所有視頻。同時,OpenAI還使用GPT將用戶的短小提示轉化為更長、更詳細字幕,以提高視頻輸出質量。簡言之,Sora通過利用DALL·E 3和GPT特性,實現對語言的深度理解和高質量的視頻輸出。

基于 DALL·E 3 DCS 的描述性標題重述與基于 GPT 的標題擴寫
五、Sora 有局限性,但未來可期
盡管 Sora 在模擬能力方面已經取得了顯著的進展,但它目前仍然存在許多局限性。例如,它不能準確 地模擬許多基本相互作用的物理過程,如玻璃破碎等。此外,在某些交互場景中,比如吃東西時,Sora 并不能總是產生正確的對象狀態變化,包括在長時間樣本中發展的不一致性或某些對象不受控的出現等。
我們相信隨著技術的不斷進步和創新,Sora 所展現出的能力預示著視頻模型持續擴展的巨大潛力。未來, 期待看到更加先進的視頻生成技術,能夠更準確地模擬現實世界中的各種現象和行為,并為人們帶來更加逼真、自然的視覺體驗。

現有視頻大模型對比
一、Runway-Gen2:綜合實力最強的文生視頻應用,內部訓練數據集含2.4億張圖像和640萬個視頻剪輯
Gen2底層建立在擴散模型之上,能夠支持包括文本到視頻、圖片到視頻和圖片+文字到視頻在內的多種視頻生成方式。默認情況下,Gen2可以生成4秒的視頻,但用戶可以通過輸入已生成的圖片來延長視頻的播放時長。此外,Gen2提供一系列參數調整功能,如基礎設置、攝像機運動以及運動畫刷,讓用戶可以實現更多的個性化配置。其中最亮眼的功能,便是Gen2能精細控制生成內容的運動狀態,甚至一鍵設置不同視頻風格,為視頻創作提供了極大的便利性。
盡管Gen2具有諸多顯著的優點,但目前還存在一些不足之處。首先,Gen2的視頻幀率相對較低,導致其呈現效果更像是連續的PPT播放。其次,當視頻內容處在移動狀態時,圖片容易出現掉幀、模糊,甚至扭曲的現象。最后,從理解語義信息的角度來看,Gen2還有較大的提升空間,特別是在處理包含多元素提示詞時,其能力相對較弱。盡管如此,對于Gen2來說,這些問題只是暫時的挑戰,讓我們一起期待它未來的表現。

Gen2一鍵生成不同風格圖像
二、Stable Video Diffusion(SVD):開源文生視頻平臺,Stability.AI基于Stable Diffusion的演進
SVD模型不僅支持文本、圖像生成視頻,還支持多視角渲染和幀插入提升視頻幀率。用戶可以調整模型選擇、視頻尺寸、幀率及鏡頭移動距離等參數。其由Stability.AI基于大規模數據集進行多層訓練,具備開源屬性和優秀的圖像生成能力,是Stability.AI產品家族中的一員,形成完整的多模態解決方案。
SVD的天花板主要由于硬件性能要求較高,限制平常用戶使用。其支持的圖片尺寸較小,限制了它的應用場景。此外,相機視角無法調節,且生成視頻內容的精細控制能力有待提升。生成的視頻清晰度和幀率也存在一些問題,表現在物體移動過程中有明顯掉幀和形變。
盡管SVD與其他商用產品在幀率、分辨率、內容控制、風格選擇和視頻生成時長等方面存在差距,但其開源屬性和對大規模數據的有效利用構成其獨特優勢。
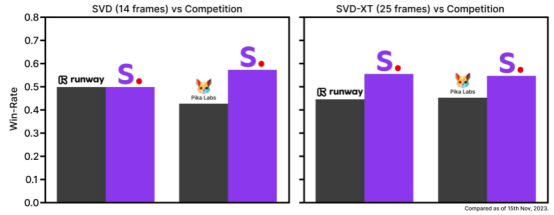
SVD與Runway2&Pika的比較
三、Pika:視頻版Mid-journey
Pika支持從文本、圖像和視頻生成視頻,時長默認為3秒,分辨率為24幀。提供用于調整攝像機運動、視頻尺寸、幀數的參數,并提供會員特權如增長視頻時長、提升分辨率和局部修改視頻等。Pika獨特之處在于其能產生背景穩定的視頻,并能在視頻中添加元素,如為人物添加眼鏡等。
然而該模型在場景泛化和理解語義信息方面表現一般,例如無法正確區分“熊貓”和“貓”。此外,視頻運鏡過程中可能出現掉幀現象,人物的審美展示以及肢體細節展現尚有不足。
與Runway Gen2和SVD相比,該模型在卡通風格等特定場景下的表現突出,不過需要精準的提示詞輸入,而且對泛化場景的處理能力較弱。
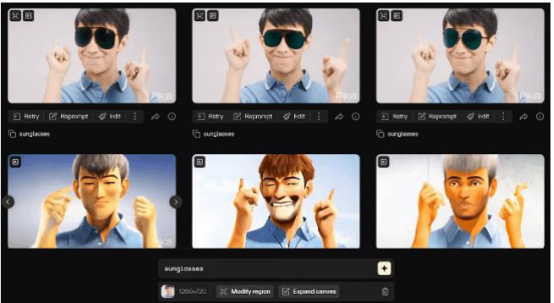
通過Pika給視頻中的人像添加墨鏡
四、Sora 與其他 AI 文本視頻模型性能對比

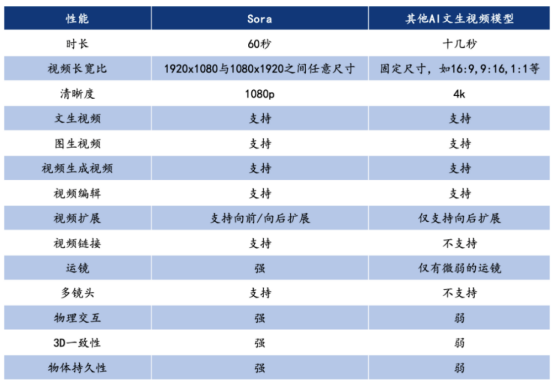
Sora 與其他 Al 文生視頻模型性能對比
1、超長生成時間
Sora 支持 60s 視頻生成,而且一鏡到底,不僅主人物穩定,背景中的人物表現也十分穩定,可以從大中景無縫切換到臉部特寫。 在此之前,AI 視頻工具都還在突破幾秒內的連貫性,即使是 Runway 和 Pika 這樣的“明星模型”,生成的視頻長度也僅有 3 到 4 秒,Sora 的時常可以說已經達到了史詩級的記錄。
2、單視頻多角度鏡頭
Sora 可以在單個生成的視頻中創建多個鏡頭,模擬復雜的攝像機運鏡,同時準確地保持角色和視覺風格。在 OpenAI 的展示視頻中一只狼對著月亮嚎叫,感到孤獨,直到它找到狼群,多鏡頭無縫切換都保持了主體的一致。
3、理解物理世界
重要的是,Sora 不僅理解用戶在提示中要求的內容,還能自己理解這些事物在現實世界中的存在方式。比如畫家在畫布上留下筆觸,或者人物在吃食物時留下痕跡。火車穿過東京郊區,隨著車窗內外光線環境和物體的變化,車窗上倒影的變化也幾乎被按照現實世界的物理規律完美還原了出來。而在技術方面,Sora 打破了此前擴散模型局限性。Sora 采用的是 DALL·E3 的重標注技術,通過為視 覺訓練數據生成詳細描述的標題,使模型更加準確地遵循用戶的文本指令生成視頻,還能夠為現有圖片賦予動態效果或延伸視頻內容的長度。
Sora模型算力空間測算
Sora模型性能強大,與其訓練數據的高質量和多樣性密切相關。通過大量吸取不同長度、分辨率和長寬比的視頻和圖像,Sora模型深度理解復雜的動態過程,并且有能力生成多種類型的高質量內容。仿照大語言模型的訓練方式,Sora模型將取樣多樣性應用于視覺數據,從而實現全面的視頻生成能力。
此外,Sora模型通過利用時空片段技術將多個視頻片段打包進一個序列中,極大地提升視頻生成的效率。該方法讓模型更高效地學習大型數據集,從而提高生成高質量視頻的能力,同時在計算資源使用上,相比其他模型架構,節省相當多的資源。
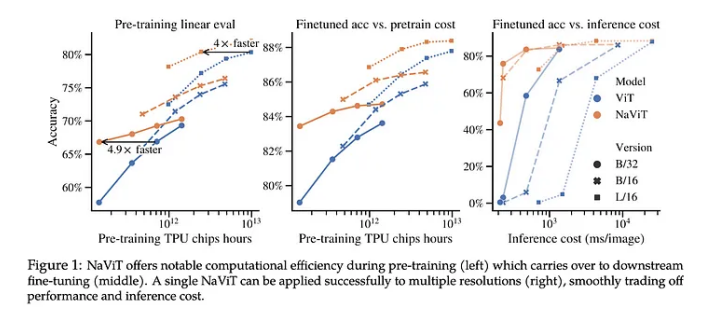
使用可變 patches 的 NaVit vs. 傳統的 Vision Transformers
一、SORA模型訓練與傳統大模型的訓練相比,為什么需要更多的算力?
SORA架構需要處理訓練數據種類比較多,包括文本、圖像以及視頻,各種類型數據都需要單獨的處理方式,分別進行處理之后再進行整合。圖像和視頻數據量大、復雜度高,特別消耗計算資源。例如,在處理圖像數據時,每張圖片需要被分解成許多面元(patch),而這個過程需要大量的計算資源。
二、ChatGPT-3和SORA模型的訓練參數和數據量有什么區別?
對比GPT-3與SORA模型,兩者在訓練參數和數據量方面有許多不同。
1、訓練參數
GPT-3和SORA的參數數量具有顯著差距。GPT-3已經非常大,擁有1750億個參數,而SORA模型對參數的需求更高。
2、訓練數據
兩者存在較大差異。GPT-3主要使用各種網絡文本作為訓練數據,包括網頁、圖書、文章等等。而SORA模型則需要處理多種類型的訓練數據,包括文本、圖像以及視頻等。這意味著SORA在數據預處理以及訓練過程中都需要做更多的工作。
總的來說,SORA模型在訓練參數和數據量等方面都要比GPT-3更為復雜和龐大,需要更多計算資源。
三、SORA模型算力空間測算
Sora模型的出色性能與其訓練數據的多樣性與質量緊密相關。它吸納大量不同長度、分辨率及長寬比的影像與圖像,從而提升對復雜動態過程的理解,并具備生成多種類型高質量內容能力。模仿大型語言模型訓練方式,Sora模型將取樣多樣性應用于視覺數據,完成全面的視頻生成能力。
在效率方面,通過打包多個視頻片段進一個序列中,Sora模型利用時空片段技術顯著提升視頻生成效率,既能高效學習大型數據集,又提高生成高質量視頻的能力,節約了相較其他模型更多的計算資源。
謝賽寧在《Scalable Diffusion Models with Transformers》一文中測算結果表明,Sora模型參數量約為30億,訓練過去五年的YouTube所有視頻需要約7.09萬張H100運算一個月時間。當考慮到算力消耗,視頻生成目前可能表現為試用狀態。然而,未來技術優化或降低算力需求,有利于視頻模型在推理應用中的廣泛實施。
一文《An Image is Worth 16x16 Words Transformers for Image Recognition at Scale》中,一張圖片大約等同于256個詞,1分鐘視頻的生成大約需要超過一次文字問答的1000倍的算力。在預計訓練期為10天的情況下,可能需要約368張英偉達H100顯卡才能滿足訓練需求,展示訓練頂級AI模型需求巨大的計算資源。
Sora模型將輸入圖像表示為16x16x3(3表示三原色)的數據塊,而每個數據塊實際上就是一串tokens。假設每張圖片的分辨率為1920x1080,每個視頻為30秒30FPS,那么patch的總大小約為3.73x10^16,可轉化為約有4.86x10^13個tokens的數量。
Transformer模型架構參數量可能增加,假設SORA Transformer與ChatGPT-3相同,則可能需要約59500張英偉達H100顯卡才能滿足訓練需求。這意味著,相較于目前的大語言模型,SORA的訓練可能需要近百倍的算力。

模型訓練算力需求測算
四、藍海大腦AI服務器:驅動Sora模型訓練的強大動力
探討Sora等大規模深度學習模型訓練,不可避免的話題便是AI服務器。尤其是在面臨如此龐大和復雜的訓練任務時,AI服務器重要性就尤為凸顯。
藍海大腦AI服務器是專為訓練大規模深度學習模型而設計的專用服務器。平臺采用A100、H100、A800、H800、B200等GPU顯卡,為用戶提供高度并行化和分布式計算能力,以應對大型神經網絡的復雜訓練任務。采用先進的硬件加速器,如GPU(圖形處理單元)和TPU(張量處理單元),快速處理大規模數據集和復雜模型的訓練過程。高效的任務調度和資源管理功能使用戶能夠輕松提交、監控和管理訓練作業。創新的液冷散熱技術,不僅滿足靜音、高效、節能基礎需求,更在確保機器穩定運行的同時,提升服務器算力,實現了高算力和高效散熱之間的完美結合。廣泛應用于人工智能、自然語言處理、計算機視覺等領域。

Sora一站式申請注冊流程
要想使用Sora,首先要確保您已經注冊OpenAI賬戶并升級到ChatGPT Plus,Sora目前仍處于早期訪問或測試階段,還沒有進入公測階段,請耐心關注和等待。但是,據官方透露的消息,OpenAI近期大概率會宣布將Sora首批開放給Chatgpt Plus用戶申請使用。所以,請務必提前準備好Chatgpt Plus。
一、打開openAI的官網:https://openai.com
二、點擊官網search按鈕:
三、輸入apply,點擊搜索
四、點擊Pages,選擇Red Teaming
五、填寫表單

1.建議用英文填寫資料。
2.帶*是必填,如果自己不會寫,可以參考案例,注意輸入框有字數限制,別超過,否則會顯示不全,影響申請。
3.參考下圖表單填寫:



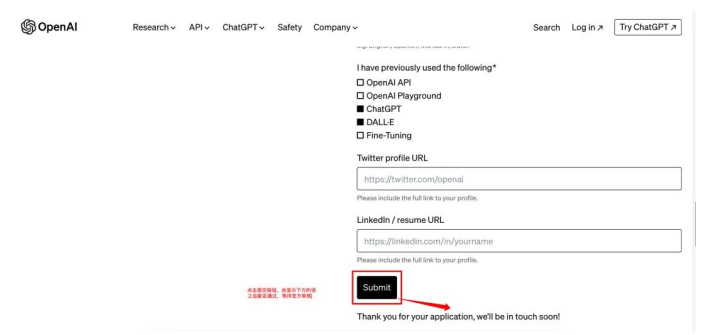
4.整個頁面全是是英文,如果看不懂,用瀏覽器自帶的翻譯軟件即可,但回答不能是中文。
5.回答問題不知道選擇哪個答案,或者寫什么,用谷歌翻譯、百度翻譯,甚至可以直接問chatGPT得到答案。
6.回答“Why are you interested in joining the OpenAl Red TeamingNetwork?”參考示例:
Dear OpenAI Team,
I am reaching out with great enthusiasm for the opportunity to join OpenAI's Red Team. The idea of contributing to a group dedicated to rigorously testing and challenging AI models across various domains sparks immense excitement within me. My passion for joining OpenAI is driven by multiple facets, and I am confident in the value I can add to the team.
My conviction in the transformative power of AI fuels my desire to be part of this journey. I am deeply invested in exploring how AI can tackle challenges of inequality, aiming to foster a more just and equitable society. This ambition resonates with my core values and propels me to leverage my skills in this revolutionary field.
My interest in AI technology is not just a passing curiosity but a devoted pursuit. I've invested considerable time in understanding its fundamentals, which boosts my confidence in critiquing and evaluating AI models with clarity and depth.
Moreover, I am eager to bring a fresh perspective to OpenAI. My insights into the needs and concerns of my community equip me to contribute to the development of AI solutions that are not only innovative but also profoundly impactful.
Thank you for considering my application. I am eager to contribute to OpenAI's mission and be part of a team that stands at the forefront of AI research and application.
Best regards,
xxx xxx
7.回答“What do you think is an important area for OpenAl to be redteaming?”的參考示例:
I am convinced that a critical focus for OpenAI's red teaming efforts should be the exploration of the ethical and societal dimensions of AI technology. As AI becomes more pervasive and integral to different facets of daily life, it's imperative to conduct deep analyses of its impacts on individuals and entire communities. This scrutiny should cover the examination of biases and fairness within AI algorithms, address privacy issues, and consider the implications of job automation. Through meticulous red teaming in these domains, OpenAI has the opportunity to guide the development and implementation of AI technologies in a manner that is both ethical and responsible. Achieving this would not only cultivate trust and acceptance among the wider population but also ensure OpenAI's pioneering role in an era increasingly influenced by AI. Such proactive measures are crucial for navigating the evolving landscape where AI's influence on society is profound and far-reaching.
六、點擊submit按鈕
高性能計算群,聚焦算法、開發、科研及求職等話題。群里大咖云集,歡迎添加小助手微信18911232010,快快加入吧~
審核編輯 黃宇
-
AI
+關注
關注
87文章
30728瀏覽量
268886 -
OpenAI
+關注
關注
9文章
1079瀏覽量
6481 -
Sora
+關注
關注
0文章
81瀏覽量
195
發布評論請先 登錄
相關推薦
OpenAI暫不推出Sora視頻生成模型API
OpenAI開放Sora視頻生成模型
OpenAI發布文生視頻大模型Sora、英偉達市值超谷歌
sora模型怎么使用 sora模型對現實的影響
OpenAI文生視頻模型Sora要點分析






 工商網監
工商網監
評論