

作者:Keepin
1、cuda是英偉達開發的一套應用軟件接口(API)。其主要應用于英偉達GPU顯卡的調用。
2、云計算可以簡單的理解為是通過網絡組合成的計算機集群,用于各種加速,其中以CPU為主,GPU為輔。所以CUDA可以成為云計算的一個支柱。
3、神經網絡能加速的有很多,當然使用硬件加速是最可觀的了,而目前除了專用的NPU(神經網絡加速單元),就屬于GPU對神經網絡加速效果最好了:
3.1、Cuda的整套軟件非常完善,所以早期很多廠家用cuda能快速搭建神經網絡加速軟件框架,所以cuda也被廣泛應用于神經網絡加速。(當然英偉達還專門開發了一套神經網絡套件,叫做tensorrt,在神經網絡推理部署的時候更為廣泛應用)
3.2、從開發api來說,神經網絡的加速不僅僅可以用cuda加速,還可以用其他API,例如GPU開發API很多,包括opencl,opengl,vulkan都可以在英偉達的GPU上加速神經網絡,只不過在英偉達顯卡上整體來說開發復雜,這些API優化效率不如cuda,畢竟cuda是英偉達自家開發的,自然適配地非常好
3.3、從硬件角度來說,AMD的顯卡也可以用于加速神經網絡,只不過軟件生態做得不如英偉達,自然應用程度也不如英偉達。事實上,AMD也開發一套Miopen的神經網絡加速套件,類似于tensorrt;還開發了一套rocm套件,類似于cuda,只不過市場占有率較低而已。
3.4、amd和nvidia都是以桌面端的GPU為主,在移動端,例如手機芯片,高通、蘋果和arm的GPU也可以用于加速神經網絡,主要使用opencl,vulkan,metal等開發API來實現。
cuda的官方文檔:https://docs.nvidia.com/cuda/
學習路線
sazc
入門CUDA
說到入門,個人比較推薦《CUDA C編程權威指南》,雖然這本書年代比較久,原版書2014年出版的,使用的GPU最新也僅僅是2012年的CC3.X的Kepler,但這些基礎知識仍然是掌握CUDA最新特性必不可少的,因此還是值得當作入門學習讀物的。
進階CUDA
要想Coding出高質量的Kernel,那么官方最新的《CUDA C++ Programming Guide》便是讓我們可以全面了解到CUDA特性的最直接的辦法,目前最新的版本是12.2。
注:此手冊個人認為適合隨時查閱,用到啥查啥,從頭開始閱讀學習,會耗費巨大的精力,效果甚微。
CUDA Samples
如果想利用CUDA特性,快速搭建“簡單”的Kernel原型,那么官方的《CUDA Samples》便是再好不過的參考資料。

注:筆者曾經簡單過了一遍這個repo,后面有任務需要編寫分類算法、理解CUDA特性、學習CUDA 擴展庫等,均從中找到了合適的Demo,快速搭建原型。
CUDA: NEW FEATURES AND BEYOND
如果對每代CUDA最新特性感興趣,那么每年一次或兩次的官方GTC發布的《CUDA: NEW FEATURES AND BEYOND》便是可以從宏觀層面快速了解到該特性的最好方法之一。
注:觀看視頻,下載PDF需要注冊,比較老的版本 Google可以搜到下載鏈接。
CUDA Library
cuDNN、cuBlas、cuDLA...。
GPU架構
搞CUDA的要不理解一些GPU的特性,那么永遠寫不出優質的代碼,學習GPU架構可以從白皮書、GTC、官方Blog以及論壇的暗示入手。
SASS
官方的Binary Utilities與論壇的暗示、開源的Assembler、泄漏的SASS規格書、工具分析。
性能分析工具
Nsight System、Nsight Compute、Nsight VS Code等。
專業CUDA
答主目前還沒到這個階段,暫且挖坑。
最近有讀者伙伴在問我關于GPU的資料,這里分享三本電子書。僅作臨時學習使用,請購買正版書籍,支持原創作者。
公眾號回復獲取電子書:GPU
GPU CUDA 編程的基本原理是什么?
作者:董鑫
想學好 CUDA 編程, 第一步就是要理解 GPU 的硬件結構, 說到底,CUDA 的作用就是最大程度壓榨出 NVIDIA GPU 的計算資源.
想要從零理解起來, 還有有些難度. 這里希望能夠用最簡單的方式把一些最基本的內容講清楚. 所以, 本文以易懂性為主, 犧牲了一些完全準確性.
GPU 結構
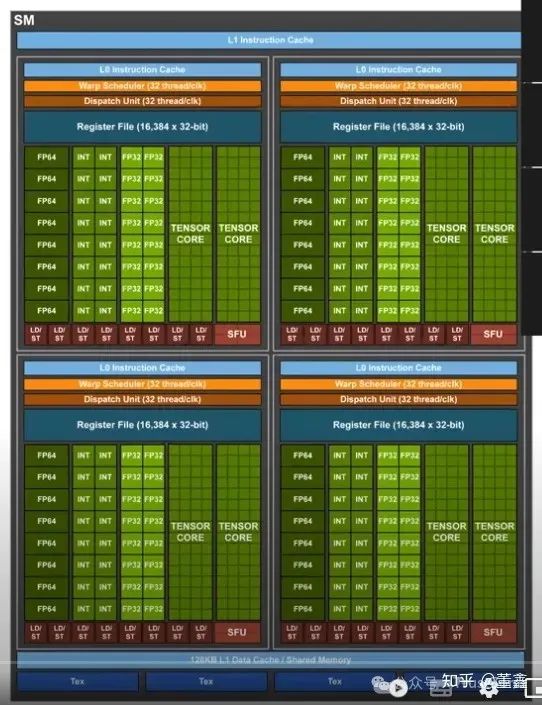
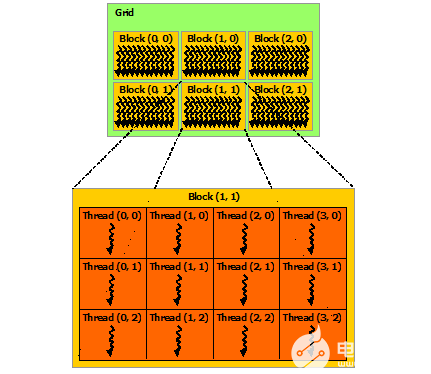
這是 GPU 的基本結構. CUDA 編程主打一個多線程 thread.
多個 thread 成為一個 thread block, 而 thread block 就是由這么一個 Streaming Multiprocessor (SM) 來運行的.
CUDA 編程中有一個 "同一個 block 內的 thread 共享一段內存". 這恰好對應上圖下面的那段 "Shared Memory".
另外, 一個 SM 里面有多個 subcore (本圖中有 4 個), 每個 subcore 有一個 32 thread 的 warp scheduler 和 dispatcher, 這個是跟 CUDA 編程中 warp 的概念有關的.
另外, 我們還要理解 GPU 的金字塔狀的 Memory 結構.
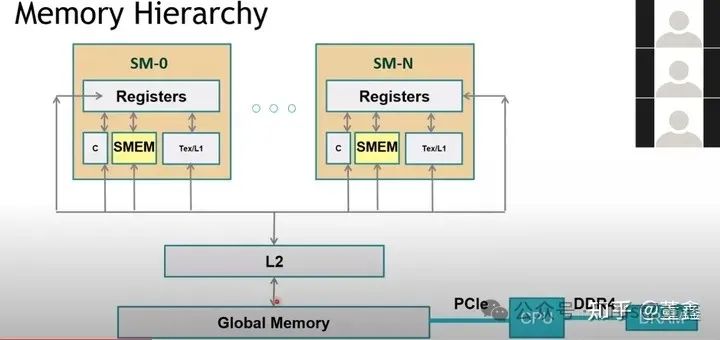
最快的是 register, 但是非常小.
其次是 l1 cache, 也就是前面提到的 shared memory.
Global memory 就是我們常說的 顯存 (GPU memory). 其實是比較慢的.
Global memory 和 shared memory 之間是 L2 cache, L2 cache 比 global memory 快. 每次 shared memory 要到 global memory 找東西的時候, 會去看看 l2 cache 里面有沒有, 有的話就不用去 global memory 了.
有的概率越大, 我們說 memory hit rate 越高,CUDA 編程的一個目的也是要盡可能提高 hit rate. 總的來說,
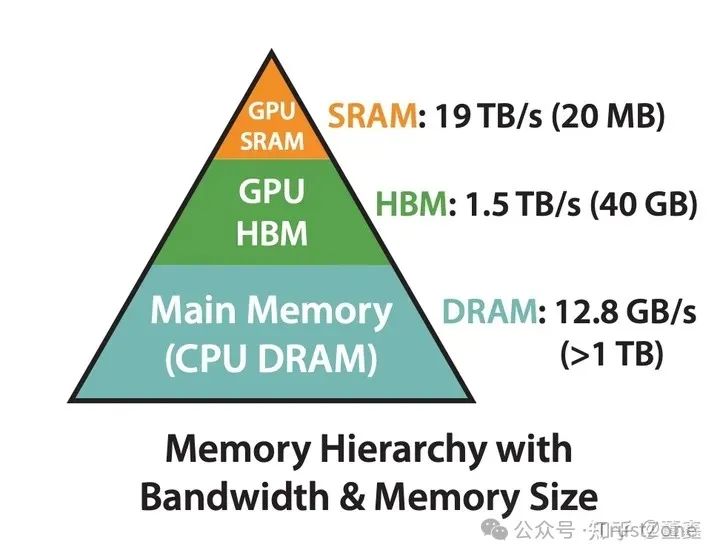
我們就是希望能夠盡可能多的利用比較快的 SRAM (shared memory). 但是因為 SRAM 比較小, 所以基本原則就是: 每次往 SRAM 移動數據的, 都可能多的用這個數據. 避免來來回回的移動數據.
其實, 這種 idea 直接促成了最近大火的 FlashAttention. FlashAttention 發現很多操作計算量不大, 但是 latency 很高, 那肯定是不符合上述的 "每次往 SRAM 移動數據的". 怎么解決呢?
Attention 基本上是由 matrix multiplication 和 softmax 構成的. 我們已經知道了 matrix multiplication 是可以分塊做的, 所以就剩下 softmax 能不能分塊做? softmax 其實也是可以很簡單的被分塊做的. 所以就有了 FlashAttention. 關于 GPU Architecture 更進一步細節推薦大家看這個:
https://www.youtube.com/watch?v=Na9_2G6niMw&t=1166s
一些跟 CUDA 有關的庫
首先先理一下 NVIDIA 那么多庫, 他們之間到底是什么關系?
這里以三個庫為例 CuTLASS , CuBLAS, CuDNN .
從名字看, 他們都是用 CUDA 寫出來的.總結起來, 他們之間的區別就是封裝程度不同, 專注的領域不同.
CuTLASS 和 CuBLAS 都是比較專注于最基本的線性代數的運算的, 比如 矩陣乘法, 矩陣加法, 等等.
而 CuDNN 則是更進一步, 將關注點落在了 Deep Neural Network 上面了. 比如, DNN 中非常常見的 convolution 操作, 是通過 矩陣乘法 來實現的.
那么, CuDNN 做的工作更像是, 完成從 convolution 到 矩陣乘法 的轉換, 轉換之后, 就可以復用 CuTLASS 或者 CuBLAS 來做.
當前, DNN 里面不全都是矩陣乘法, 遇到一些特殊的算子, CuDNN 也會自己實現一些.而 CuTLASS 和 CuBLAS 之間的區別, 更像是”傻瓜程度” 不同.
CuBLAS 可以理解成 英偉達 給你找了一堆傻瓜相機, 每個相機都針對某個非常非常具體的場景優化到了極致, 你唯一要做的就是根據你的場景找到最適合相機.
因為每個相機已經被寫死了, 你不知道英偉達到底做了什么黑魔法優化, 你也沒辦法去根據想法進一步修改.
雖然 CuBLAS 閉源, 不靈活, 但是只要場景找對了, 效果確實拔群.
而 CuTLASS 是一個模板庫, 相當于有這么一些不同 系列 的相機, 有拍夜景, 拍近景的, 等等. 當然, 就夜景而言, 肯定還有各種不同場景, 對應不同配置可以嘗試. 在 CuTLASS 你可以嘗試不同的配置, 直到你滿意為止.
矩陣乘法 (CuTLASS)
假設做 GEMM (general matrix multiplication), 我們以 CuTLASS 里面的實現來講解
C = A * B
A 是 M x K
B 是 K x N
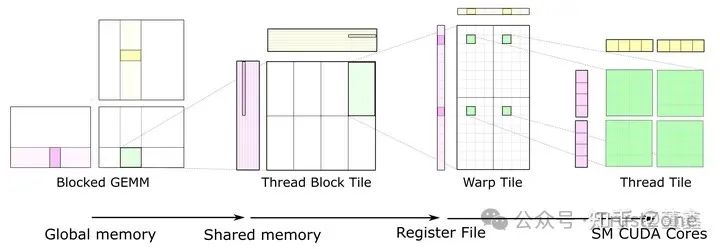
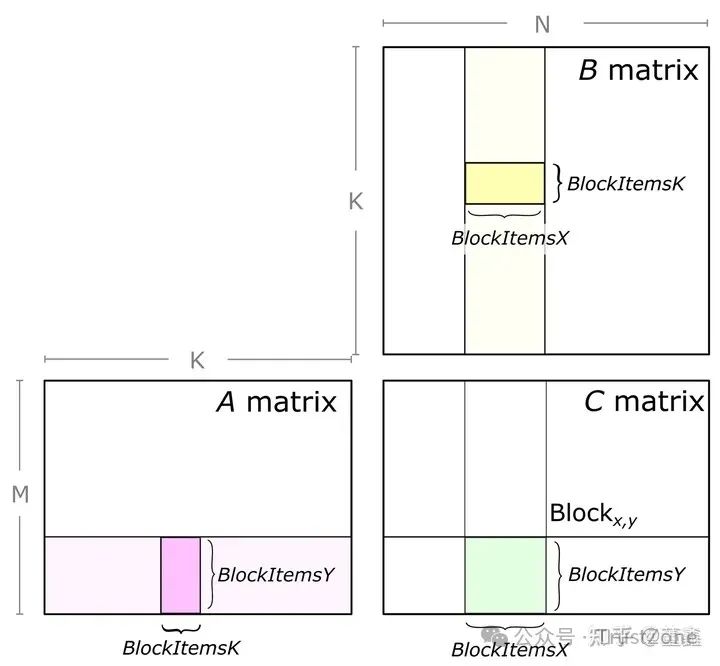
這張圖的信息量很大.
1. 第一部分:
是關于如何拆分一個大矩陣乘法到多個小矩陣乘法. 也就是說, 這段時間我們就 focus on 某個小矩陣的計算. 其他部分我們不管.
這樣, 因為不同小矩陣之間是完全獨立的, 就可以很容易實現并行.
具體來說 也是需要多次紫色和黃色部分的矩陣乘法. 紫色從左到右滑動, 黃色從上到下滑動. 他們的滑動的次數是完全一樣.
他們每滑動一次, 就是一次矩陣乘法(及加法, 因為要把乘出來的結果加到之前的結果之上). 下圖是滑動到某個位置的情況.
之所以綠色部分沒有高亮, 是因為要把所有都滑動完, 才能得到最終綠色部分的結果.
2. 第二部分:
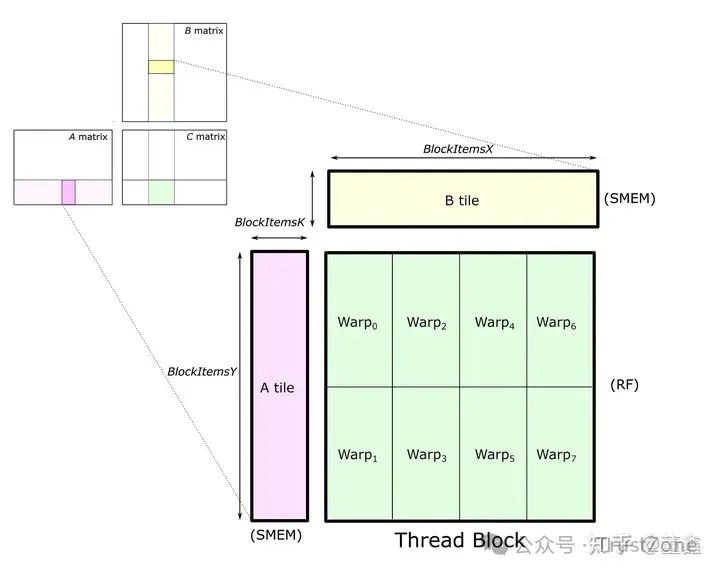
先忽略綠色部分.注意, 這紫色的一整行和黃色的一整列都是由一個 thread block 處理的.為什么? 因為他們都要在同一塊 C tile 上面累加.
如果切換 thread block 的話, 就會比較麻煩.理論上來說, 紫色的一整行和黃色的一整列都要被 load 到 shared memory.
但是, 因為我們每次只會用到 紫色高亮部分 和 黃色高亮部分, 所以完全可以聲明一塊小內存, 每次只 load 一小塊 (A tile and B tile), 用完之后就可以覆蓋掉, 用來 load 下一個滑動位置.具體到某一次滑動,
把 紫色高亮部分 (A tile) 和 黃色高亮部分 (B tile) 從 global memory 移動到 shared memory (SMEM).接下來要做的就是計算 A tile * B tile, 然后把結果累加到 C tile 上面.好了, 現在我們明確兩點:A tile 和 B tile 都在 shared memory 了.
也就是說, thread block 里面的每一個 thread 都可以看到 A tile 和 B tile.A tile 和 B tile 每次窗口滑動是需要重新 load 的,
但是 C tile 每次窗口滑動是需要在原來的基礎上更新的.因為 C tile 一直需要更新, 而且這個更新是計算驅動的 (不是 load 驅動的),
所以我們最好把 C tile 放到 register (RF) 里面去. register 是一種比 shared memory 更快的內存, 而且 register 是跟 thread 相關的.
其實計算的時候, A tile 和 B tile 也必須從 shared memory 被 load 到 register. 只是 C tile 一直待在 register 里面等待被更新.
3. 第三部分:
剛剛講了, 我們需要把 C tile held 在 register, 而 register 有是跟具體某個 thread 是關聯的. 所以我們自然需要根據 thread 再來劃分 C tile.
但是, CUDA 其實在 thread 和 thread block 還有一層叫做 warp. 我們可以暫時理解把 warp 一種計量單位: 1 warp = 32 thread.在上述例子中, 一個 thread block 被分成了八個 warp.每個 warp 承擔了 C tile 中的 16*8 個數字.
假設每個數字是 32bit, 那么恰好是一個 register 的容量.那么, 也就是說, 我們需要 16*8 個 registers. 前面講了一個 warp 是 32 thread. 這并不矛盾. 因為一個 thread 可以配有多個 registers.
但是, 某個 thread 是不定訪問 其他 thread 的 register 的. CUDA 之所以這么限制, 主要原因還是 thread 之間做 sync 太復雜.這里, 要算一個 warp 對應的結果, 還是跟前面的講的一樣. 橫向滑動紫色高亮塊, 縱向滑動黃色高亮塊,
每次滑動, 都是將當前高亮塊從 shared memory load 到 register 中, 計算矩陣乘法 (雖然看著像向量, 但是不一定是向量), 然后累加到 C warp tile 上面. 正如前面所說, C warp tile 一直都是在 register 上面的.
4. 第四部分:
最終, 還是要落到單個 thread 上面.
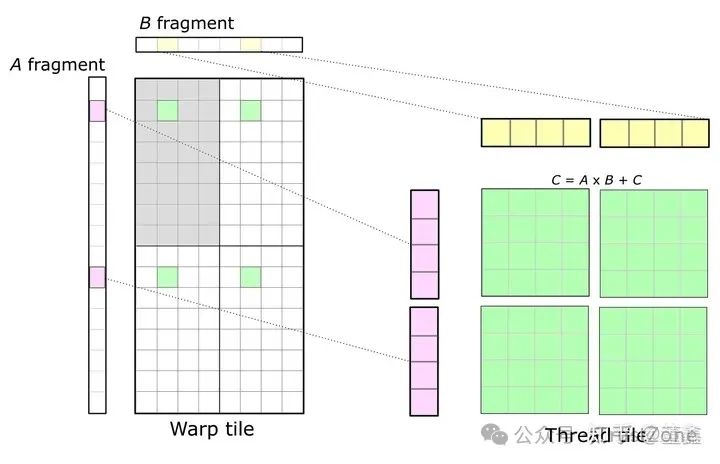
這里的 Warp tile 代表這一整個 tile 都是由一個 Warp 完成的.先看左上角灰色的部分, 后面的內容也是在這個灰色的部分.數一下, 恰好是 32 個格子.
而我們知道一個 Warp 是 32 個 thread. 也就是說, 一個 thread 處理一個灰色的格子. 這 32 個格子中, 有一個綠色的格子 (先不要看另外三個綠色的),
這個綠色的格子就是我們現在要討論的 32 個 thread 中的某個 thread.實際上, 這個綠色的格子里面有 16 個數, 也就說是一個 44 的迷你矩陣.
也就說, 一個 thread 要處理這樣一個 44 的矩陣. 那么, 既然想得到這樣 44 的矩陣, 就需要讀入 41 的紫色部分, 1*4 的黃色部分.
好, 現在我們可以跳出左上角灰色部分了. 我們發現這個 Warp tile 還有剩下三個部分, 但是在左上角灰色部分我們已經這個 Warp 中 32 個 thread 用過一遍了, 怎么辦?
誰說 Warp 只能用一遍? 完全可以讓這個 Warp keep alive, 再如法炮制地去分別按順序處理 (所以這里其實在時間上不是并行的) 剩下的三個部分.這個時候, 我們再看一個thread的工作量.
首先, 一個 thread 要被用 4 次, 然后每次要處理 4x4 的迷你矩陣,
所以總的來看, 一個 thread 相當于處理了一個 8x8 的矩陣. 這就是上圖右邊想表達的意思.
審核編輯:黃飛
-
神經網絡
+關注
關注
42文章
4814瀏覽量
104342 -
gpu
+關注
關注
28文章
4975瀏覽量
131992 -
sram
+關注
關注
6文章
789瀏覽量
116308 -
多線程
+關注
關注
0文章
279瀏覽量
20519 -
CUDA
+關注
關注
0文章
124瀏覽量
14170
原文標題:GPU與CUDA的一點資料知識整理
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
在K520上能使用兩個GPU進行CUDA作業嗎
線性電源的基本原理是什么
無線充電的基本原理是什么
CUDA簡介: CUDA編程模型概述





 工商網監
工商網監

評論