

01
ResNeXt網(wǎng)絡(luò)詳解
一、ResNeXt—VGG、ResNeXt、Inception的結(jié)合體
ResNeXt網(wǎng)絡(luò)可以看作基于VGG、ResNeXt和Inception的一個經(jīng)典神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),目前已經(jīng)被廣泛應(yīng)用于各種視覺任務(wù)。它結(jié)合了以上三種網(wǎng)絡(luò)的特點:
堆疊多個重復(fù)的block(基于VGG)
每個block中包含了多種變換(基于Inception)
使用殘差進行跨層連接(基于ResNet)
1、VGG
VGG是基于AlexNet進行改進得到的網(wǎng)絡(luò)模型結(jié)構(gòu)。AlexNet使用如11*11、7*7、5*5等較大卷積核,而VGG則采用連續(xù)的3*3卷積核進行堆疊。在VGG中,使用3個3*3的卷積核代替7*7的卷積核,使用2個3*3卷積核代替5*5的卷積核,在保證相同感知野的前提下,增加網(wǎng)絡(luò)深度來處理較為復(fù)雜的問題。同時,較小卷積核的引入也降低了參數(shù)量。VGG16家族網(wǎng)絡(luò)結(jié)構(gòu)如圖。
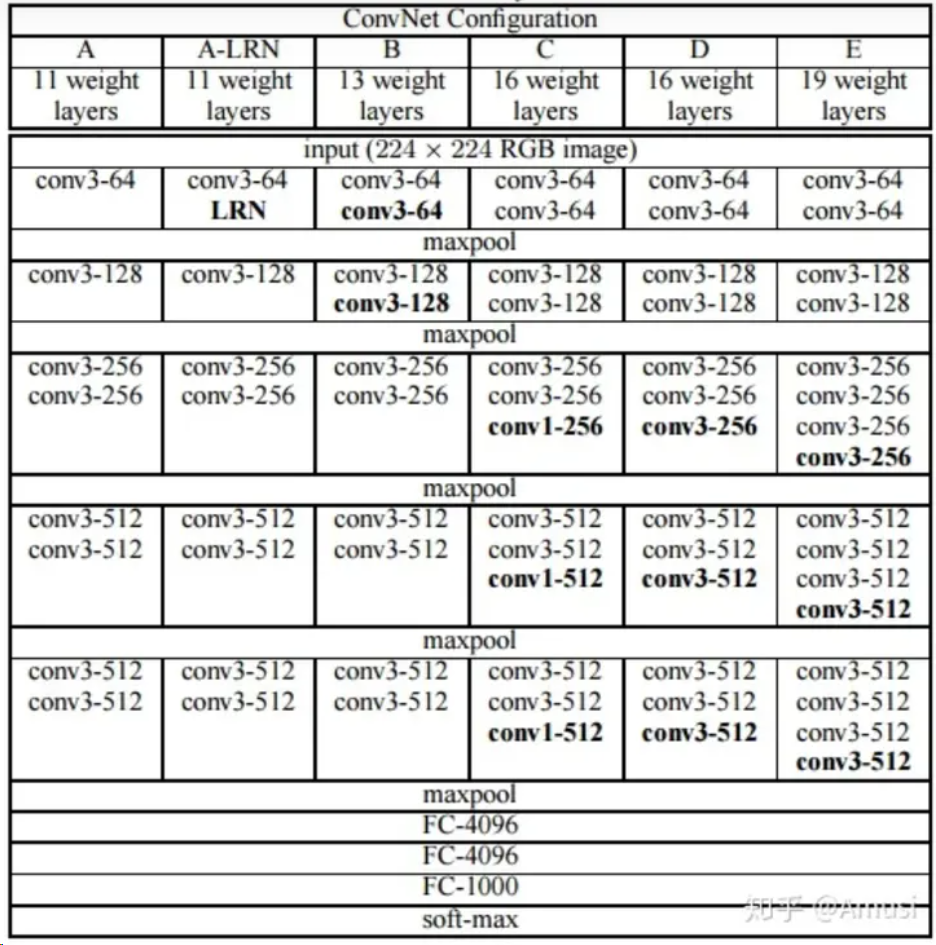
可以看到,VGG家族網(wǎng)絡(luò)采用多個block堆疊的方式進行構(gòu)建,每一個block中包含若干個3*3的卷積核,block之間使用maxpool進行下采樣。
ResNeXt延續(xù)了VGG這種相同block堆疊的方式,使用ResNeXt block堆疊的方式構(gòu)建ResNeXt網(wǎng)絡(luò)。
2、Inception
對于神經(jīng)網(wǎng)絡(luò)來說,增加網(wǎng)絡(luò)性能一般通過增加網(wǎng)絡(luò)的深度和寬度來實現(xiàn)。增加深度及增加網(wǎng)絡(luò)層數(shù),增加寬度代表增加每一層特征圖的通道數(shù)。但是一味地增加深度和寬度會導(dǎo)致網(wǎng)絡(luò)的參數(shù)量過于龐大,很可能產(chǎn)生過擬合。有研究表明,增加網(wǎng)絡(luò)的稀疏性可以解決以上問題,Inception正是基于此邏輯進行設(shè)計的。
Inception的核心思想是,在一層中同時使用不同尺寸的卷積核,提取不同尺寸的特征,然后再將結(jié)果通過concact進行連接。于是有了如下的Inception模塊的第一版設(shè)計。
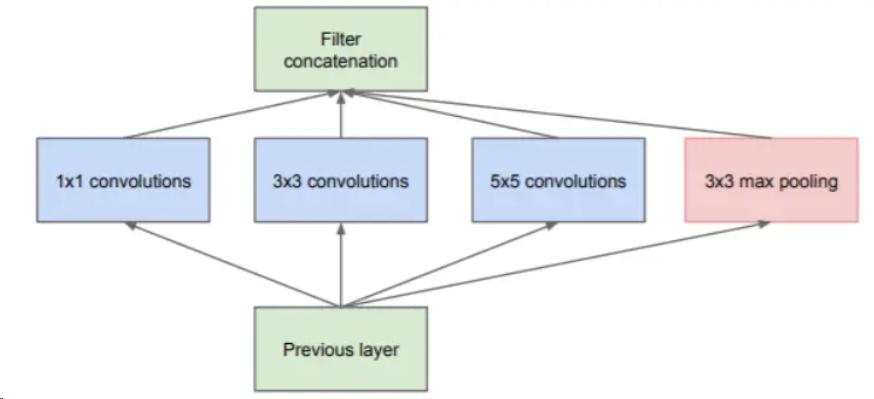
在該模塊中,使用1*1、3*3、5*5三種不同尺寸大小的卷積核,和一個3*3的最大池化,增加了網(wǎng)絡(luò)在不同尺度上的感知能力。為了減少計算資源消耗,后續(xù)對該模塊進行改進,在卷積前使用1*1的卷積核對特征圖進行降維,然后再對通道數(shù)減少的特征圖進行卷積操作。Inception-v1最終的模塊如下圖。
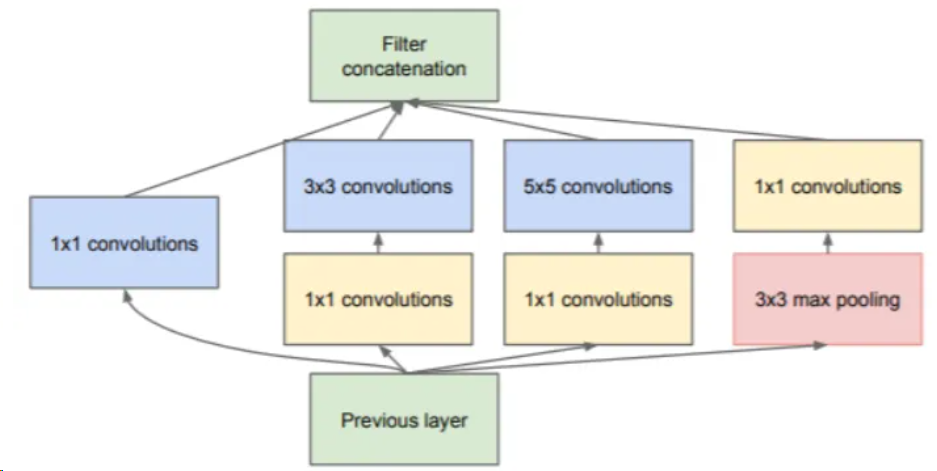
這種在一層中使用不同尺寸卷積核進行卷積的方式,被稱為split-transform-merge策略。簡單來說就是,針對輸入先進行特征分離(split),然后分別進行不同的處理(transform),最后再將所有結(jié)果進行合并(merge)。使用這種策略構(gòu)建起的網(wǎng)絡(luò),雖然能使用較小的參數(shù)實現(xiàn)較多的特征提取,但是該網(wǎng)絡(luò)的每一個分支都需要經(jīng)過精心的設(shè)計,導(dǎo)致模型結(jié)構(gòu)復(fù)雜、泛化能力不強。
ResNeXt在設(shè)計上沿用了split-transform-merge策略,同時對該策略進行了一定程度的改進,規(guī)避了模型結(jié)構(gòu)復(fù)雜這一弱點。
3、ResNet
回到頂部
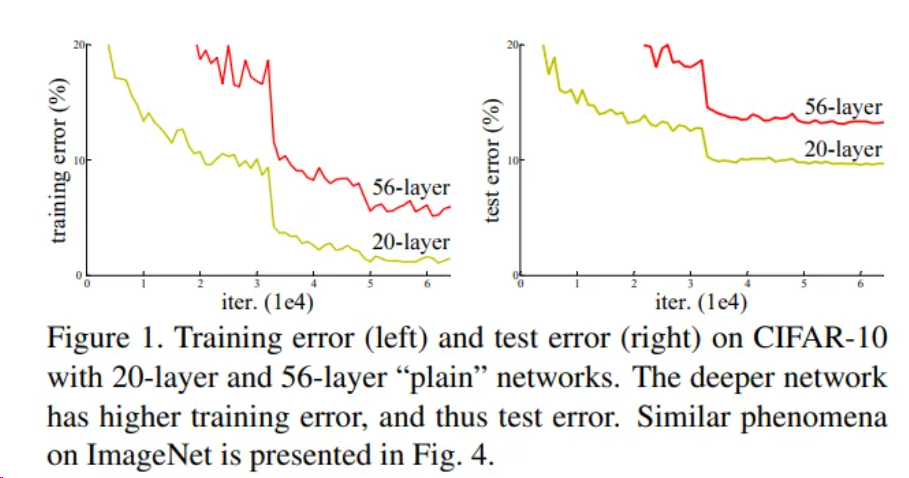
是否網(wǎng)絡(luò)層數(shù)不斷增加,模型準確率就能不斷增加呢?ResNet的作者做了一個實驗,實驗結(jié)果表明,隨著網(wǎng)絡(luò)層數(shù)不斷增加,模型準確率先是上升,之后卻開始下降。也就是說,層數(shù)較多的網(wǎng)絡(luò)效果有可能不如層數(shù)較少的網(wǎng)絡(luò)。如圖,作者在CIFAR-10數(shù)據(jù)集上進行了實驗,實驗結(jié)果表明,56層網(wǎng)絡(luò)的準確率反而不如20層網(wǎng)絡(luò)。作者將這一現(xiàn)象稱之為模型退化,同時提出了ResNet網(wǎng)絡(luò)以解決模型退化問題,使得神經(jīng)網(wǎng)絡(luò)的深度首次突破了100層。
ResNet的核心思想是,在每一個block中加入shortcut connection(快捷連接),如下圖。在每一個ResNet塊中,輸入x經(jīng)過一系列變換得到F(x),然后再將F(x)和x加在一起得到最終輸出H(x)=F(x)+x。這種網(wǎng)絡(luò)結(jié)構(gòu)也叫做殘差網(wǎng)絡(luò)。
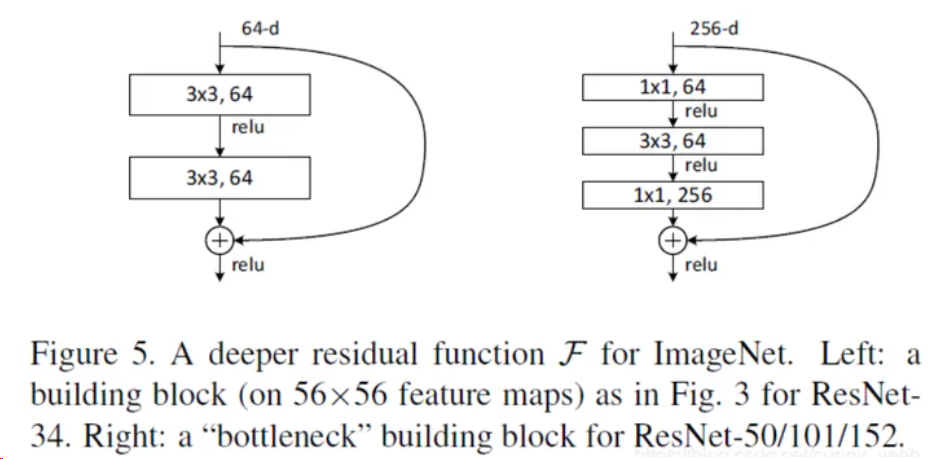
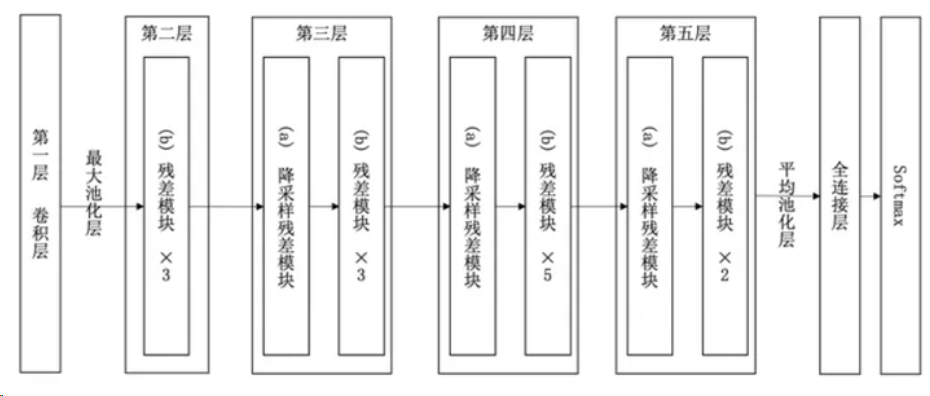
實驗表明,ResNet在上百層的網(wǎng)絡(luò)結(jié)構(gòu)中也有著很好的表現(xiàn)。以34層ResNet為例,網(wǎng)絡(luò)結(jié)構(gòu)如下圖。
ResNeXt網(wǎng)絡(luò)是對ResNet網(wǎng)絡(luò)進行改造,借鑒了VGG中block堆疊的設(shè)計原則和Inception中split-transform-merge的策略并對其進行改進。ResNeXt基本結(jié)果如圖所示,可以看到,該模塊在ResNet模塊的基礎(chǔ)上,使用了Inception的策略,但是所有分支結(jié)構(gòu)相同,簡化網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計。
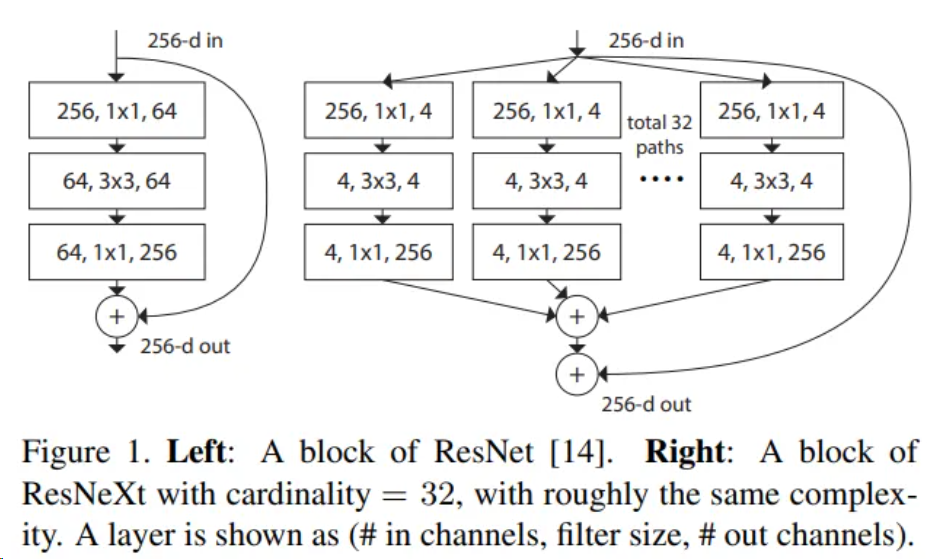
二、ResNeXt系列網(wǎng)絡(luò)結(jié)構(gòu)
ResNeXt block一共有三種表現(xiàn)形式,這三種形式完全等價。
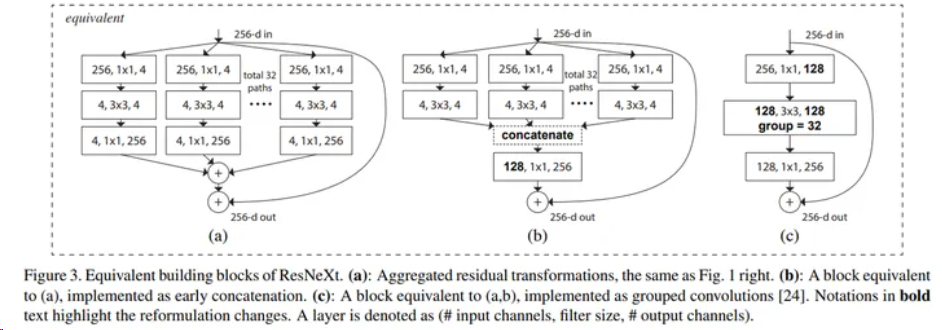
其中最基本的形式為圖中的(a),一共設(shè)計了32個分支,先使用1*1的卷積核對輸入特征圖進行降維,然后使用3*3卷積核進行卷積操作,最后使用1*1卷積核進行升維,然后將所有分支結(jié)果相加,然后進行殘差操作,再與輸入相加,最終得到輸出結(jié)果。
為了方便工程化實現(xiàn),作者將(a)中的結(jié)構(gòu)轉(zhuǎn)化為(b),及先將32個分支卷積結(jié)果進行concact連接,然后使用1*1卷積進行升維,最后和輸入相加得到輸出。
經(jīng)過研究,作者發(fā)現(xiàn)(b)中的結(jié)構(gòu)可以使用分組卷積進行替代。及先使用1*1卷積核對輸入特征圖進行降維,得到128個通道的特征圖,然后將128個通道分為32組,每組4個通道,使用3*3卷積核分別對每組的4個通道進行卷積操作,然后再將32組結(jié)果在通道維度進行聚合,獲得最終的128通道的特征圖。之后進行同樣的1*1卷積升維以及殘差操作,得到最終輸出。
基于上述ResNeXt block構(gòu)建整體網(wǎng)絡(luò),以ResNeXt-50為例,和ResNet-50對比如下。
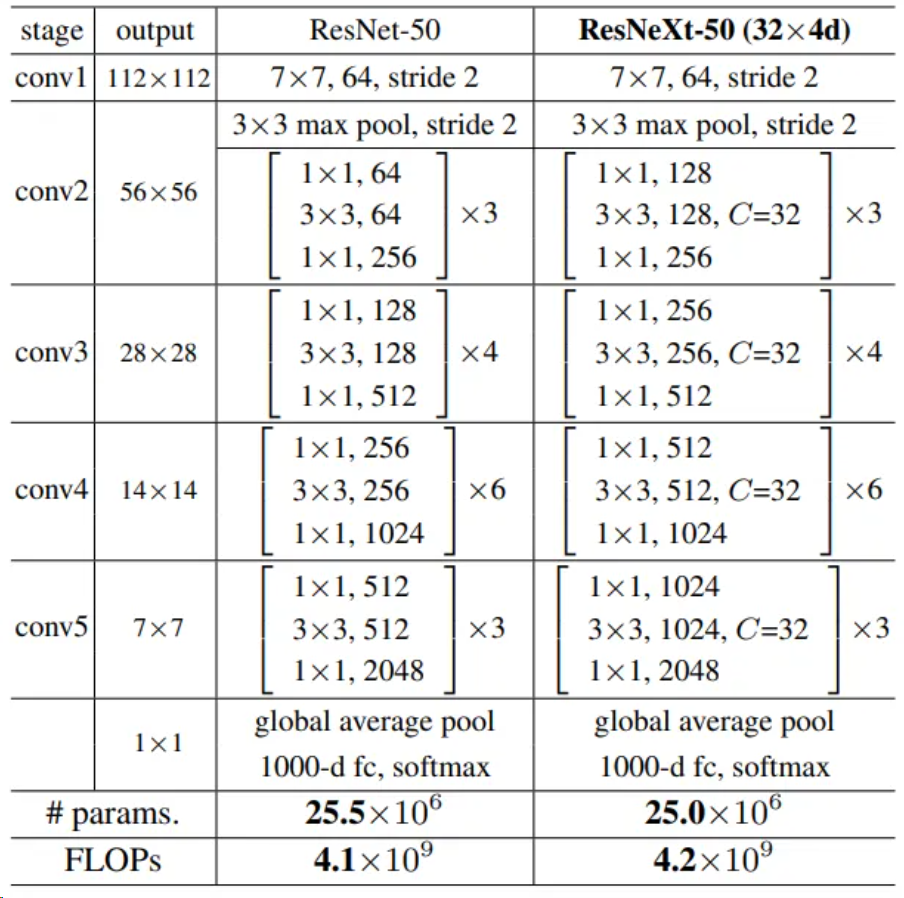
可以看到ResNeXt集合了VGG、Inception和ResNet的特點,整體結(jié)構(gòu)和ResNet類似,參數(shù)量(params)和計算量(FLOPs)也與ResNet基本相等,其中網(wǎng)絡(luò)細節(jié)如下:
conv3、conv4、conv5三個block的第一個3*3卷積核的stride=2,實現(xiàn)下采樣功能
當feature map進行下采樣操作后,通道數(shù)變?yōu)樵瓉淼?倍
每一個卷積后面附帶一個Batch Normalization層和Relu激活層,BN層用于加快模型收斂速度,保證模型訓(xùn)練過程中的穩(wěn)定性,一定程度上消除梯度消失或者梯度爆炸問題。
和ResNet一樣,ResNeXt也可以進行拓展,比較常用的有ResNeXt-50、ResNeXt-101、ResNeXt-152。在下文中,將使用ResNeXt-101完成手勢識別任務(wù)。
三、ResNeXt性能分析
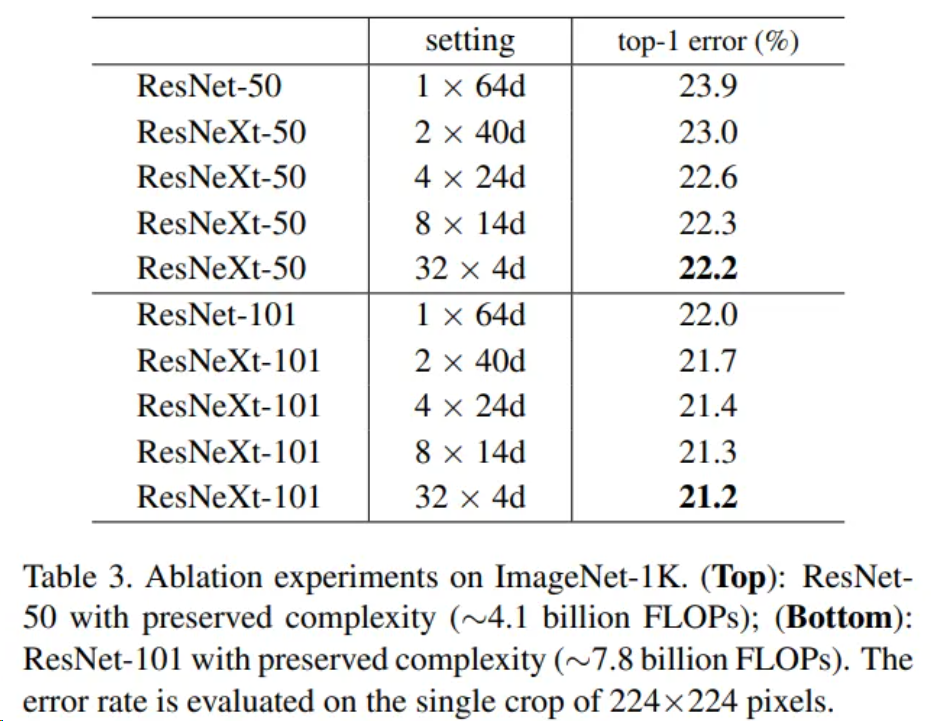
ResNeXt作者在ImageNet數(shù)據(jù)集上對不同配置的ResNeXt-50網(wǎng)絡(luò)和ResNeXt-101的性能進行了評估,并且和同等層數(shù)的ResNet網(wǎng)絡(luò)進行了對比,結(jié)果如下,其中setting表示conv2中3*3卷積核的配置情況,“*”前的數(shù)字表示分組數(shù)量,之后的數(shù)字表示每組通道數(shù)。如2*40d表示分2組、每組通道數(shù)為40。top-1 error為錯誤率。可以看到,隨著分組數(shù)的增加,網(wǎng)絡(luò)性能會逐步提高。
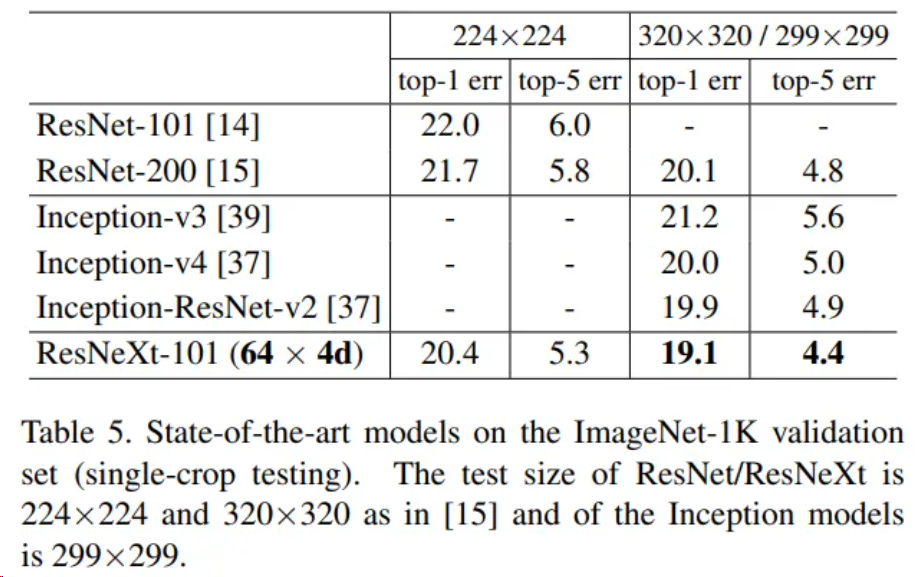
作者還將ResNeXt-101網(wǎng)絡(luò)在ImageNet數(shù)據(jù)集上和其余網(wǎng)絡(luò)進行了對比,包括ResNet和Inception家族中的部分網(wǎng)絡(luò)結(jié)構(gòu),結(jié)果如圖。可以看到,和這些網(wǎng)絡(luò)相比,ResNeXt-101都表現(xiàn)出了更高的性能。
審核編輯:黃飛
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4808瀏覽量
102797 -
網(wǎng)絡(luò)結(jié)構(gòu)
+關(guān)注
關(guān)注
0文章
48瀏覽量
11473 -
vgg
+關(guān)注
關(guān)注
1文章
11瀏覽量
5314
原文標題:基于ResNeXt網(wǎng)絡(luò)實現(xiàn)基于視覺的動態(tài)手勢識別 之 ResNeXt網(wǎng)絡(luò)詳解
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于BP神經(jīng)網(wǎng)絡(luò)的手勢識別系統(tǒng)

基于毫米波雷達的手勢識別神經(jīng)網(wǎng)絡(luò)
基于毫米波雷達的手勢識別算法
ELMOS用于手勢識別的光電傳感器E527.16
基于BP神經(jīng)網(wǎng)絡(luò)的手勢識別系統(tǒng)
基于肌電信號和加速度信號的動態(tài)手勢識別方法
基于加鎖機制的靜態(tài)手勢識別運動中的手勢
基于視覺的手勢識別系統(tǒng)的設(shè)計與研究

手勢識別產(chǎn)品特性和主要應(yīng)用領(lǐng)域







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論