 英偉達要小心了!爆火的Groq芯片能翻盤嗎?AI推理速度「吊打」英偉達?
英偉達要小心了!爆火的Groq芯片能翻盤嗎?AI推理速度「吊打」英偉達?
隨著科技的飛速發展,人工智能公司Groq挑戰了英偉達的王者地位,其AI芯片不僅展現出卓越的實力,還擁有巨大的潛力。Groq設計了一種獨特的推理代幣經濟學模式,該模式背后牽動著眾多因素,卻也引發了深度思考:新的技術突破來自何處?中國該如何應對并抓住變革中的機遇?Groq成本如何評估?這些都是值得研究和思考的問題。
Groq芯片的實力與潛力
近期AI芯片領域嶄Groq可謂是火爆全球,其在處理大型模型token生成上所展示出的表現令人驚嘆。這意味著我們可以在與GPT等復雜聊天機器人互動時,實時獲得回應,無需等待機器人逐個生成答案。
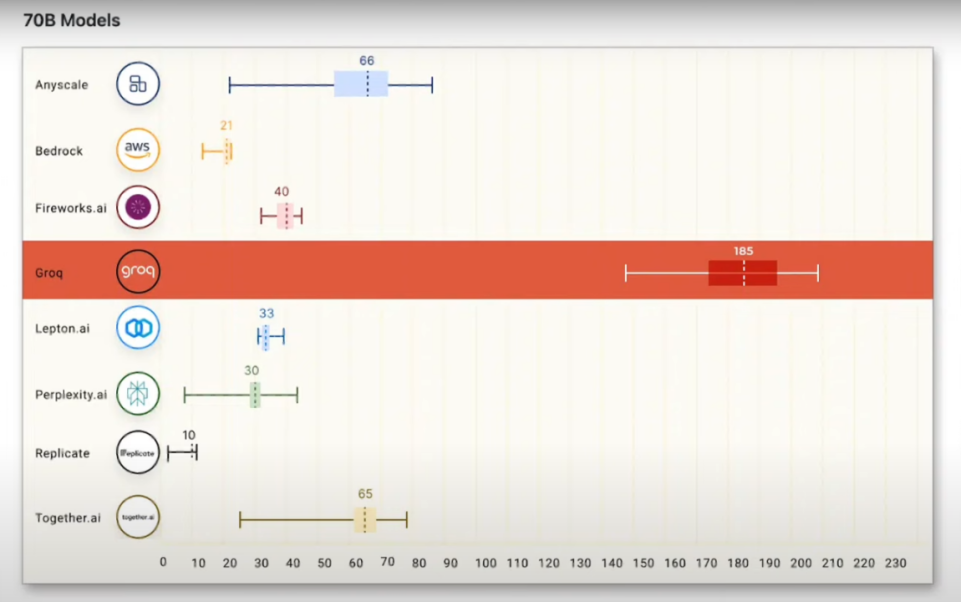
那么,Groq驅動的大模型生成速度究竟有多快呢?令人難以置信的是,當Groq的LPU驅動含有700億參數的Llama 2大模型時,其生成速度被推至新高度,平均每秒生成185個token。該速度遠超其他使用GPU驅動的AI云服務提供商。
而在面對Mix Strore8x7B模型時,Groq的性能更是達到新峰值,其生成速度飆至每秒488.6個token,相比依賴英偉達GPU的系統每秒僅能產生15個token的速度,可以說是取得了壓倒性的勝利。從這些事實中,不難看出Groq的LPU在大型模型生成速度上占據絕對優勢。LPU曾被稱為TSP(Tensor Streaming Processor),即一個裝配有大量Tensor單元的流式處理器。
那么對于Groq公司,大家一定對它的來歷感到好奇吧?
Groq是由前谷歌TPU團隊核心成員喬納斯羅斯2016年創立的公司,其推出產品被稱為LPU(Language Processing Unit),專為處理大模型設計的加速芯片。
一、GPU的局限性
盡管GPU在訓練機器學習模型方面的強大作用無可替代,其強大的計算能力、快速參數更新速度和豐富的生態系統使之成為業內的主流選擇,但它并非模型推理的理想選擇。一方面是因為GPU架構復雜,其中只有部分核心專門針對AI場景。其次,GPU承載存儲和計算兩個部分,導致數據需要頻繁讀寫,從而降低運行速度,提高功耗。
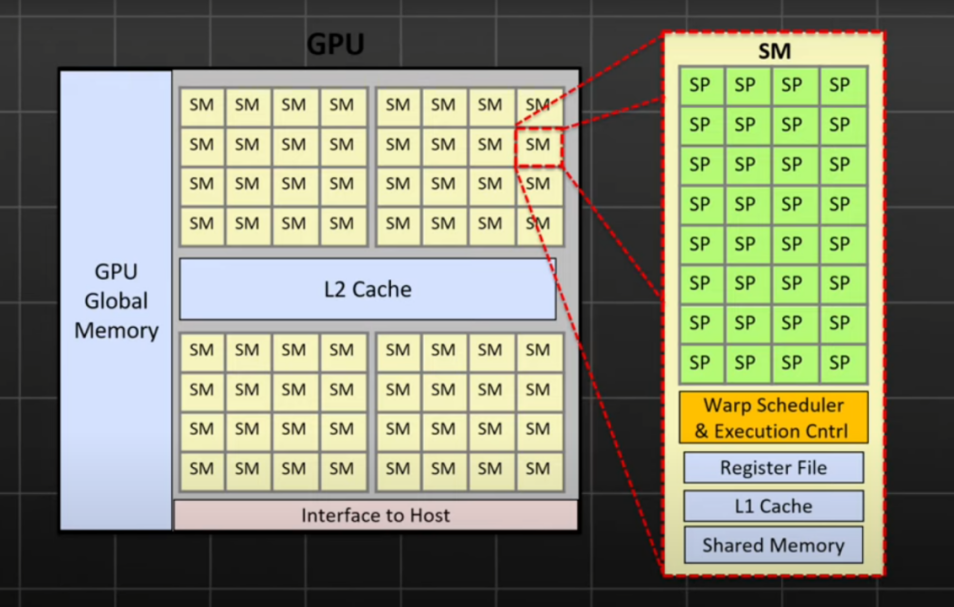
二、GPU、TPU和Groq的LPU的優勢與挑戰
下面我們一起來分析專門為AI應用設計的芯片,以谷歌的TPU和Groq的LPU為例。TPU和LPU都有自身的獨特優勢,但也有著各自的挑戰需要我們去理解和探討。
1、谷歌TPU
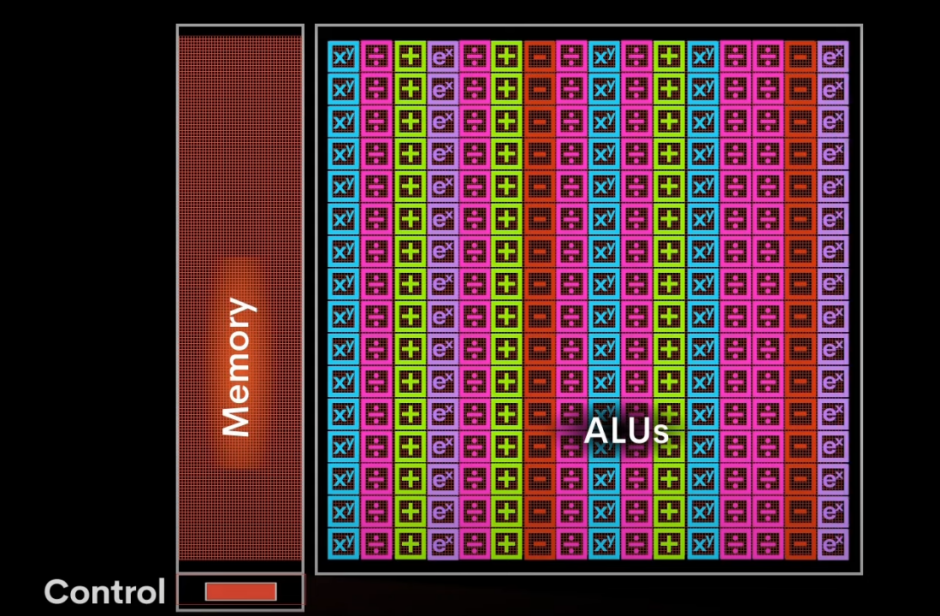
TPU專為AI應用設計的芯片,專門處理矩陣運算(AI應用中超過90%的計算任務)。在執行AI訓練和推理過程中,TPU能夠便捷地處理不同的計算任務,如激活函數、優化算法以及損失函數等。這些都是通過高效的向量計算模塊來完成的。而其特色之處在于,TPU采用一種獨特的陣列設計方法,數據一旦導入,便會在內部形成一個流水線,持續運動直到完成計算。這種持續流動式處理方式極大地降低了數據的讀寫次數,從而提升了在AI應用中的計算效率。
2、Groq的LPU
Groq的LPU采用與TPU相同的處理模式,不同的是它在計算單元旁邊直接集成了大約230MB的SRAM,帶寬可達80TB/s。比起GPU,當運行同等參數的模型時,LPU需要的內存更多,這也是LPU在運行速度上擁有優勢的原因。
不過,盡管LPU的速度令人矚目,但其昂貴的價格也是一個不容忽視的問題。LPU每塊價格近20000美元,如果要運行擁有上千億參數的大模型,可能需要購買數百塊LPU。也就是說,盡管LPU的單獨計算率高,但在數量需求上,部分GPU在成本效益上更具優勢。
3、SRAM的容量問題
有人可能會提出為什么不直接擴大到1TB?實際上,這樣做的技術難度很高,同時也會增加制造成本。因此,230MB的SRAM可能就是在權衡設計難度和制造成本后,現階段可以實現的一個平衡點。

Groq的成本分析
Groq人工智能硬件公司因其在推理API領域的卓越性能以及為技術如思維鏈的實際應用所鋪就道路的貢獻而廣受關注。它在單串性能方面的優勢更是受到稱贊,對于特定的市場和應用環境,Groq的速度優勢已經改變了原有的格局。然而,足夠的運行速度只是解決方案的一部分。Groq的另一優勢是供應鏈的多元化,即所有制造和封裝流程都在美國完成。相比之下,洛基達、谷歌、AMD等依賴韓國內存和臺灣先進芯片封裝技術的AI芯片供應商形成鮮明對比。
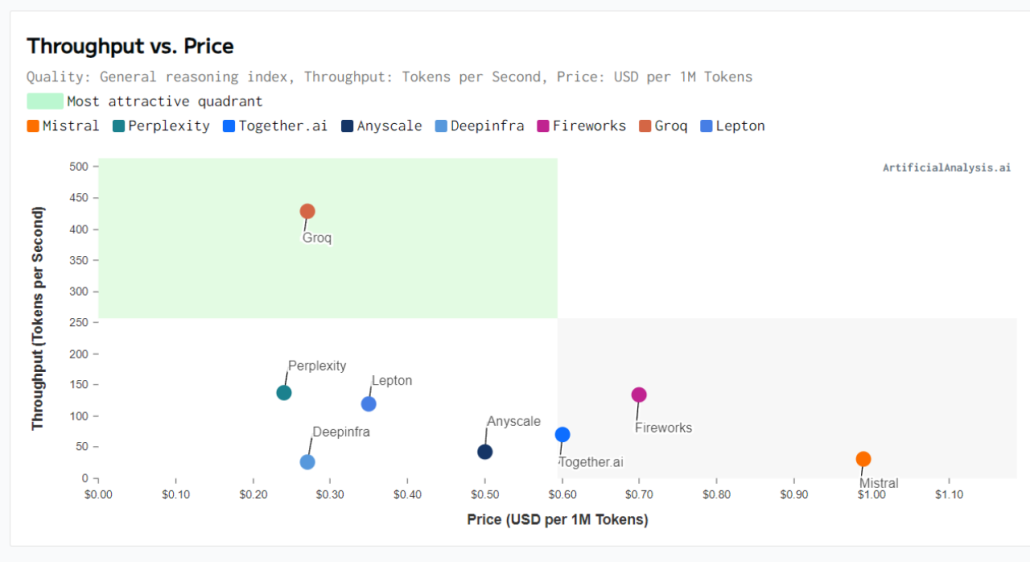
雖然Groq的優勢明顯,但一個硬件是否具有變革性的決定因素是其性能與總成本的比值。不同于傳統軟件,AI軟件的運行需要更強大的硬件基礎設施,這無疑對資本和運營成本產生更大的影響,從而對凈利潤形成影響。因此,優化AI基礎設施以實現AI軟件的高效部署尤為重要,擁有優越基礎設施的公司無疑將在使用AI部署和拓展應用程序的競賽中立于不敗之地。
根據"Inference Race to the Bottom"的研究,大量公司可能會在Mixtral API推理服務中虧本,以致于需要設定極低的訪問率減少損失。然而,Groq卻敢于在定價上與這些公司一較高下,其每個代幣價格低至0.27美元。接下來,我們將更深入地研究Groq的芯片、系統以及成本分析,看看他們是如何實現這樣卓越的性能。
Groq芯片采用固定的VLIW架構,并在Global Foundries的14nm工藝上實現約725mm2的規模。由于芯片并未裝配緩存器,所以所有權重、KVCache和激活數據在處理過程中都儲存于芯片中,不需外置存儲。然而,由于每枚芯片僅擁有230MB的SRAM,所以無法將實際的模型完整地裝入單一芯片中。因此,需要使用多個芯片來共同執行模型的運算,并連接在一起。
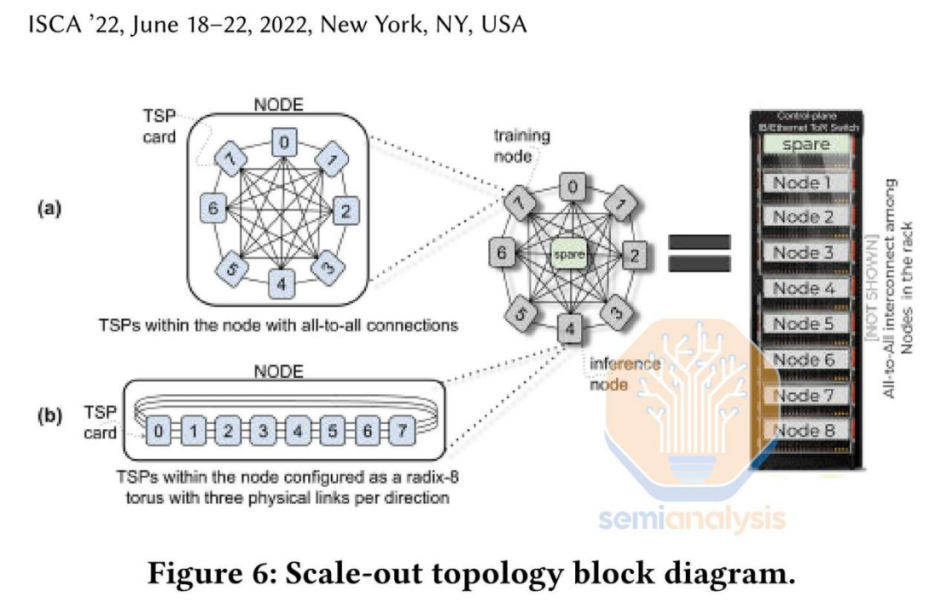
要運行Mixtral模型,Groq需將576個芯片串聯起來,這些芯片被均勻地分布在72個服務器上,而這些服務器則被部署在8個不同機架中。相比之下,Nvidia的H100只需一個芯片就能運行同樣的模型,而兩個芯片則能處理大規模數據。
在芯片成本方面,產出Groq芯片的每片晶圓價格不會超過6000美元。而對照到Nvidia的H100芯片(尺寸為814mm2,采用臺灣半導體制造公司的5nm自定義工藝),同樣一片晶圓的制作成本就近在16000美元。此外,Groq在設計上并未考慮到良率收縮,與Nvidia有著鮮明的對比,后者會關閉大約15%的H100 SKU,以反映出產品的主流族群。
當考慮到內存成本,Nvidia從SK Hynix采購的每片80GB HBM芯片的預計價格為1150美元。另外,還需要額外付費給臺積電的CoWoS服務,導致總成本進一步增加。然而,由于Groq并無額外的外部內存需求,因此其芯片構成要素清單大大縮減。
下表將展示Groq部署策略的特點,特別是在流水線并行性和批處理尺寸均為3時的情況。同時,也會將經過延遲和吞吐量優化后的Nvidia的H100推理部署情況做出對比。
本次分析簡化了部分經濟因素,未充分考慮進一些系統成本及Nvidia巨大的利潤空間。但卻明確突出Groq芯片架構的優勢,尤其是與延遲優化過的Nvidia系統進行比較時。
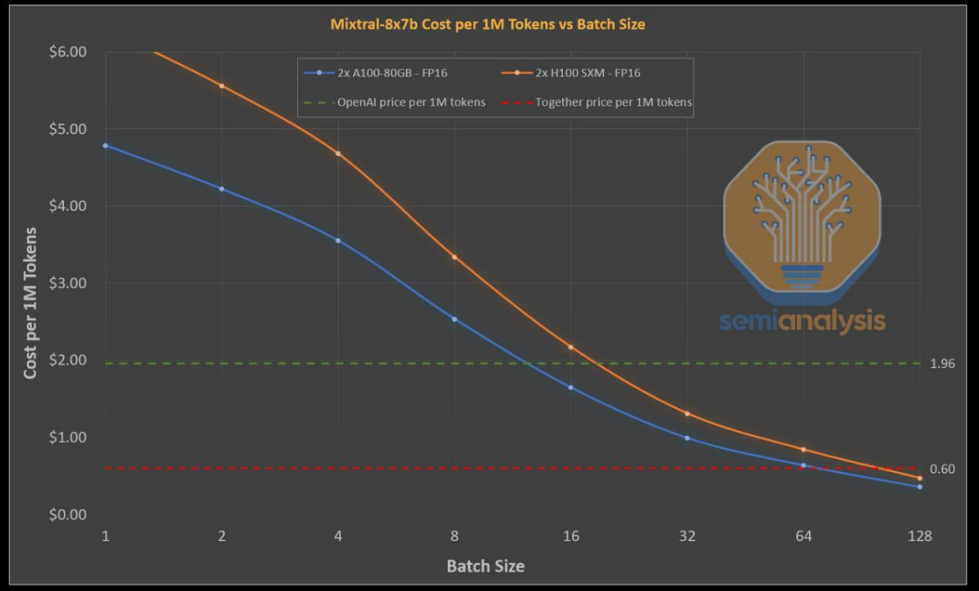
對于Mixtral模型,八顆A100s芯片可以提供約220個代幣的吞吐量/秒,而這還不包括預測解碼。同樣地,八顆H100s芯片可以達到約280個代幣的吞吐量/秒,如果加上預測解碼,吞吐量更可以達到約420。當前,由于經濟收益不高,市場上尚未出現面向延遲優化的API服務。然而,隨著代理及其他低延遲任務的日益普及,以GPU為基礎的API供應商可能會提供相應的優化API。
Groq的優勢表現在不需要預測解碼的高性能,且這一優勢在實現批處理系統后仍然顯著。Groq仍在使用相對較舊的14nm工藝,并向Marvell支付較高的芯片利潤。然而,隨著Groq的投資額增加,以及其下一代4nm芯片產量的提高,情況可能發生改變。
對性能優化過的系統來說,其成本效益將會顯著改變。通過基于BOM計算,在每單位美元的投入中,Nvidia的性能增長率顯著提升,但其用戶吞吐量卻相對較低。
簡化的分析方式無法考慮到系統成本、利潤率和功耗等因素,我們將在未來進一步研究性能與總成本的關系。
一旦將上述因素考慮進去,對Tokenomics的理解將發生改變。Nvidia的商業模式依賴于他們的GPU板的高額利潤,以及所收取的服務器費用。
如今,最大的模型參數范圍已達到1到2萬億,而預期谷歌和OpenAI將研發超過10萬億參數的模型。同時,大模型如Llama3和Mistral也即將發布。此類模型需要搭配幾百個GPU和數十TB的內存的強大推理系統支持。已經有公司如Groq顯示出處理不超過1000億參數模型的能力,并計劃在未來兩年部署上百萬芯片。
谷歌的Gemini 1.5 Pro能夠處理高達1000萬token的上下文,這意味著它可以處理長達10小時的影片、110小時的音質、30萬行的編碼或700萬字的內容。這樣的長上下文處理能力未來有望得到很多公司和服務商的迅速支持以更好地管理大量的編碼庫和文檔庫,取而代之低效的RAG模型。在處理這樣的長上下文信息時,Groq需要構建由數萬片芯片組成的系統,而目前諸如谷歌、英偉達和AMD等公司使用的是幾十到幾百片芯片。盡管預計四年后,由于其優秀的靈活性,GPU將能處理新模型,但對于Groq這樣沒有DRAM的公司來說,隨著模型規模的擴大,系統壽命可能會縮短,從而增加成本。
利用樹狀/分支推測的方式,推測性解碼的速度已經提高約3倍。如果這種技術能在生產級系統上得到有效部署,那么8塊H100的處理速度將會提升到每秒600個Token,從而消解了Groq在速度上的優勢。英偉達也未坐視不理,他們計劃在下個月發布性能以及TCO超過H100兩倍的B100芯片,并計劃在下半年開始發貨,同時旗下B200和X/R100的研發工作也正在積極推進。然而,倘若Groq能有效地擴大到數千個芯片的系統,那么便能大幅增加流水線數量,為更多的鍵值緩存提供空間,從而實現大規模的批處理,可能會大幅降低成本。即使有分析師認為這是可能的方向,但實現的可能性并不大。關鍵問題在于是否值得放棄靈活的GPU,轉而建立專門的基礎設施以滿足小型模型推理市場對于快速響應的需求。
華為芯片應對挑戰
Groq的出現為計算力市場提供新的選擇,這既暗示強勁的市場需求和供應短缺,也說明科技公司正在構建自己的體系,以對抗英偉達、AMD等的壟斷地位。對于國內市場,這無疑為國產芯片提供了更大的發展空間。
華為已經推出昇騰910和昇騰310兩款采用達芬奇架構的AI芯片。該架構具有強大的計算能力,可以在一個周期內完成4096次MAC運算,并集成多種運算單元,支持混合精度計算和數據精度運算。
以昇騰系列AI處理器為基礎,華為構建Atlas人工智能計算方案,包括多種產品形態,以應對各種場景的AI基礎設施需求,覆蓋了深度學習的推理和訓練全流程。
基于昇騰系列處理器構建的全棧AI解決方案,已逐漸完善。該方案包括昇騰系列芯片、Atlas硬件系列、芯片使能、異構計算架構CANN以及AI計算框架等。其中,昇騰910芯片的單卡算力已能媲美英偉達A100。
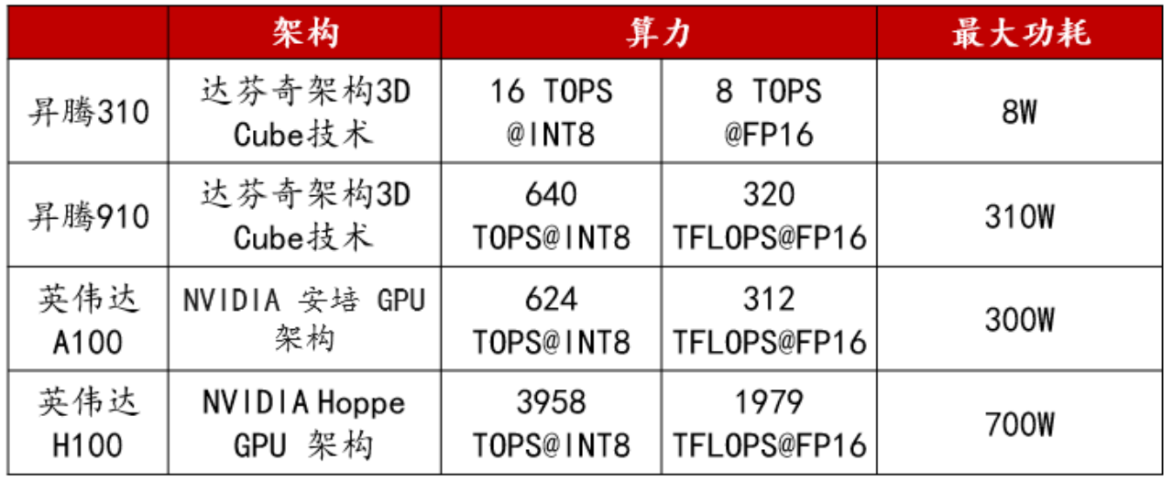
英偉達與華為參數比對
華為的昇騰計算平臺CANN已從無到有取得顯著突破。從2018年的CANN 1.0版本到目前的7.0版本,這個專為AI場景設計的異構計算架構平臺,已成功成為上層深度學習框架和底層AI硬件間的橋梁。
CANN已形成了繁榮的生態體系,適用于50多個主流的大模型,如訊飛星火、GPT-3、Stable Diffusion等,而且兼容主流加速庫和開發工具包,加速創新應用的落地。同時,CANN支持主流的深度學習框架,如Pytorch和Tensorflow,且能在周級時間內適配新版本。PyTorch已升級到2.1版本,支持昇騰NPU,助力開發者在華為昇騰平臺上開發模型。此外,第三方開源社區,如清華大學的Jittor和飛漿的PaddlePaddle FastDeploy也已經支持接入CANN。
隨著華為昇騰910B的算力接近英偉達A100的標準,以科大訊飛為代表的國產AI模型廠商已開始投入使用。科大訊飛宣布,即將以昇騰生態為基礎,發布基于“飛星一號”平臺的訊飛星火大模型,開啟與GPT-4相對標的更大規模訓練。科大訊飛星火大模型3.5版已發布,其語言理解和數學能力已超過GPT-4 Turbo,而代碼能力及多模態理解分別達到其96%和91%。

華為 CANN 時間線
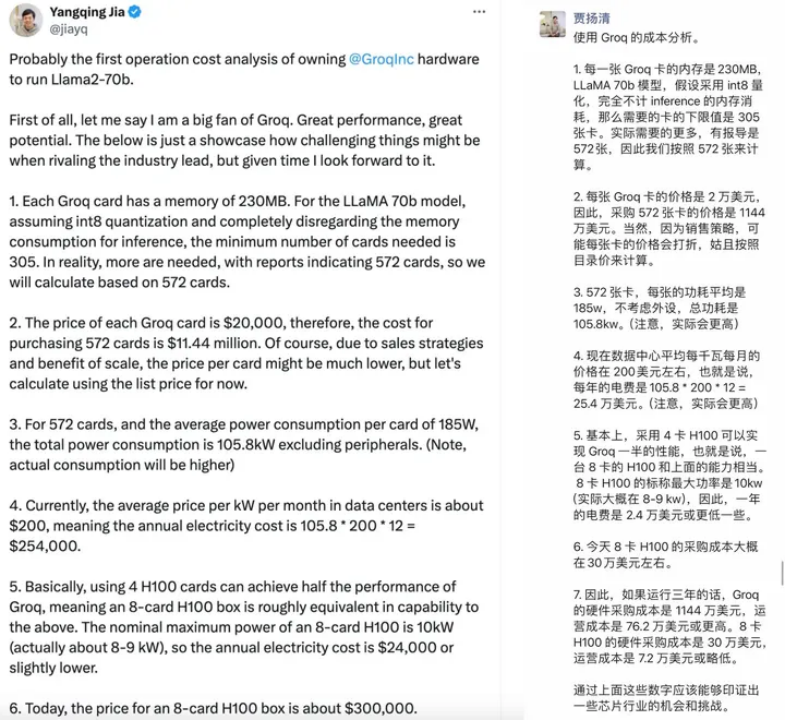
Groq的成本評估方式
原阿里副總裁賈揚清教授對Groq的成本評估非常精準,他強調Groq相較于H100的性價比較低,這其中包含一部分運營成本。這種觀點很有可能不僅僅是針對Groq,而是整個DSA設計領域。然而,如果忽略存儲成本,僅按照每個單元(token)的理論成本重新計算,得出的結果可能與此前相差甚遠。
在現實LLM需求環境中,推理工作負載對內存容量的需求是剛性的,包括模型權重、上下文KV值、各芯片/節點產生的中間結果、優化器狀態(僅訓練)等,都需要進行密集讀取和移動。此種情況下,Groq在處理大批量任務時的性能可能就變得有限,流水線并行中可能會產生低效或負效益。總并行度受限于能存放KV值的內存容量,而并行度不足會對每token的成本產生影響。
相較之下,采用類似結構的Graphcore 7nm IPU面臨的情況也差不多,盡管其配備900MB的片上SRAM,遠超Groq的230MB,但依然遭遇商業化的困境。這進一步驗證了,如果基于SRAM的解決方案真的可行,類似的產品早就應該彌漫市場了。再者,這種特殊構型對應的軟件編程框架和引導編譯器也是極大挑戰;倘若一定要景氣地運行Llama2 70B的推理任務,其復雜的軟件和運維開銷是不容忽視的。
接著,Groq的單卡計算單元規格似乎更適合處理小規模的推理任務,但其頗高的內存帶寬在處理這類任務時的利用率未必能夠達到最優。而倘若要處理中大型任務,則需要面臨內存容量、通信瓶頸和復雜度的問題。雖然官方的測試主要聚焦在最大70B-最小7B的任務規模,但這顯然是Groq比較擅長的工作負載規模,并特別強調INT8的算力(up to 750TOPs),說明Groq產品的主打應該是“INT8量化下的、面向70B-7B規模”的推理場景。
最后,無論從硬件還是軟件層面來看,相較于片外HBM+更大的L4+CXL方案,Groq的方案似乎有較高的迭代局限性,可能并不滿足當前LLM工作負載的剛性需求,邊際效益也可能不如前者。然而,如果堅持設計基于SRAM的DSA加速器,為何不研究一下Tesla Dojo的構型呢?他們通過小顆粒SRAM+PE配對分散排列形成的2D矩陣的近存結構,而非片上集中主存,應該能降低一部分成本,而這種結構可能處理相當復雜的操作,在非LLM計算場景中可能表現優異。
審核編輯 黃宇
-
AI
+關注
關注
87文章
30728瀏覽量
268886 -
英偉達
+關注
關注
22文章
3770瀏覽量
90984 -
A10
+關注
關注
1文章
25瀏覽量
12682 -
H100
+關注
關注
0文章
31瀏覽量
287 -
Groq
+關注
關注
0文章
9瀏覽量
80
發布評論請先 登錄
相關推薦
超萬個英偉達芯片已交付 13000個Blackwell芯片樣品已發送給客戶

英偉達超越蘋果成為市值最高 英偉達取代英特爾加入道指

AI芯片巨頭英偉達漲超4% 英偉達市值暴增7500億

英偉達推出AI模型推理服務NVIDIA NIM
英偉達首席執行官黃仁勛:AI模型推動英偉達AI芯片需求
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
英偉達被控延遲出貨,阻礙競爭
“網紅”芯片Groq讓英偉達蒸發5600億
英偉達為什么要下場定制ASIC芯片?英偉達能稱霸嗎?






 工商網監
工商網監
評論