 如何克服阿姆達爾(Amdahl)定律的影響?
如何克服阿姆達爾(Amdahl)定律的影響?
RA8系列是瑞薩電子推出的全新超高性能產品業界首款基于Arm Cortex-M85處理器的MCU,能夠提供卓越的6.39 CoreMark/MHz,可滿足工業自動化、家電、智能家居、消費電子、樓宇/家庭自動化、醫療等廣泛應用的各類圖形顯示和語音/視覺多模態AI要求。
所有RA8系列MCU均利用Arm Cortex-M85處理器和Arm的Helium技術所帶來的高性能,結合矢量/SIMD指令集擴展,能夠在數字信號處理器(DSP)和機器學習(ML)的實施方面獲得相比Cortex-M7內核高4倍的性能提升。
當人工智能 (AI) 下沉到各式各樣的應用當中,作為市場上最大量的物聯網設備也將被賦予智能性。ArmHelium 技術正是為基于Arm Cortex-M 處理器的設備帶來關鍵機器學習與數字信號處理的性能提升。
Arm Helium 技術誕生的由來
在前幾篇文章中,我們介紹了采用 Arm Helium 技術(也稱為 MVE)的 Armv8.1-M 架構如何處理矢量指令。但問題是,每當代碼被矢量化時,Amdahl 定律的影響很快便會顯現,讓人措手不及。如果您不了解 Amdahl 定律,可以簡單理解為,Amdahl 定律表明算法中無法并行化的部分很快就會成為性能瓶頸。例如,如果有 50% 的工作負載可以并行化,那么即使這部分工作負載可以無限并行,最多也只能將速度提高二倍。不知您作何感受,如果我能將某件事情無限并行化,但速度卻只能提升二倍,這種微不足道的提升一定會讓我感到非常惱火!在設計 Helium 時,我們必須考慮矢量指令及其相關聯的一切內容,這樣才能最大限度地提高性能。
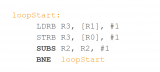
串行代碼在循環處理中很常見,串行代碼造成的開銷可能相當大,特別是對于小循環。下面的內存復制代碼就是一個很好的例子:

循環迭代計數的遞減和返回循環頂端的條件分支占循環指令的 50%。許多小型 Cortex-M 處理器沒有分支預測器(小型 Cortex-M 處理器的面積效率極高,這意味著許多分支預測器比整個 Cortex-M 處理器還要大幾倍)。因此,由于分支損失,運行時開銷實際上高于 50%。通過在多次迭代中攤銷開銷,循環展開可以幫助減少開銷,但會增加代碼大小,并使代碼的矢量化過程更加復雜。鑒于許多 DSP 內核都有小循環,因此在 Helium 研究項目中解決這些問題至關重要。許多專用 DSP 處理器支持零開銷循環。一種實現方法是使用 REPEAT 指令,告訴處理器將下面的指令重復 N 次:

處理器必須記錄多項數據:
循環開始的地址
需要分支回到循環開始前所剩余的指令數
剩余的循環迭代次數
在處理中斷時,跟蹤記錄所有這些數據可能會造成問題,因此一些 DSP 只需要延遲中斷,直到循環完成。如果要執行大量的迭代,這可能需要相當長的時間,而且完全不符合 Cortex-M 處理器應該實現的快速和確定性中斷延遲的需求。這種方法也不適用于處理精確故障,如權限違規導致的內存管理故障異常 (MemManage)。另一種方法是增加額外的寄存器來處理循環狀態。但這些新寄存器必須在異常進入和返回時保存和恢復,而這又會增加中斷延遲。為了解決這個問題,Armv8.1-M 采用了一對循環指令:

該循環首先執行 While Loop Start (WLS) 指令,該指令將循環迭代計數復制到 LR,循環迭代計數為零時,分支到循環結束。還有一條 Do Loop Start (DLS) 指令,可用于設置一個循環,在該循環中至少始終執行一次迭代。Loop End (LE) 指令檢查 LR 以確認是否還需要一次迭代,如果需要,則分支返回起點。有趣的是,處理器可以緩存 LE 指令提供的信息(即循環開始和結束的位置),因此在下一次迭代時,處理器甚至可以在獲取 LE 指令之前分支回到循環的起點。因此,處理器執行的指令序列如下所示:

在循環末尾添加循環指令有一個很好的副作用,如果緩存的循環信息刷新,該指令將重新執行。然后,重新執行 LE 指令將重新填充緩存。如下圖所示,由于無需保存循環開始和結束地址,因此現有的快速中斷處理功能得以保留。

除了第一次迭代和從中斷恢復時的一些設置外,所有時間實際上都花在了內存復制而不是循環處理上。此外,由于處理器事先知道指令的順序,因此總能用正確的指令填充流水線。這樣就消除了流水線清空和由此導致的分支損失。因此,我們可以將這一循環矢量化,不必再擔心 Amdahl 定律的影響,我們(暫時)克服了這些困難。
在對代碼進行矢量化時,一個循環通常以不同類型的指令開始和結束,例如矢量加載 (VLDR) 和矢量乘加 (VMLA)。執行這樣的循環時,會產生一長串不間斷的交替 VLDR/VMLA 操作(如下圖所示)。這種不間斷的鏈條使處理器能夠從指令重疊中獲得最大益處,因為它甚至可以從一個循環迭代結束重疊到下一個迭代開始,從而進一步提高性能。關于指令重疊的更多信息,可參閱:《Arm Helium 技術誕生的由來:為何不直接采用 Neon?》

當需要處理的數據量不是矢量長度的倍數時,矢量化代碼就會出現問題。典型的解決方案是先處理全矢量,然后用一個串行/非矢量化尾部清理循環來處理剩余的元素。不知不覺中,Amdahl 定律又出現了,真是令人不勝其煩!Helium 中的矢量可容納 16 個 8 位數值,因此在我們對 31 字節的 memcpy 函數進行矢量化時,僅有不到一半的拷貝將由尾部循環連續執行,而不是由矢量指令并行執行。
為了解決這個問題,我們增加了循環指令的尾部預測變體(如 WLSTP、LETP)。對于這些尾部預測循環,LR 保存的是要處理的矢量元素的個數,而不是要執行的循環迭代的次數。循環開始指令 (WLSTP) 有一個大小字段(下面 memcpy 函數示例中的“.8”),用于指定要處理的元素的寬度。

如果您曾見過其他優化的 memcpy 例程,可能會對這個例子的簡單程度感到驚訝,但對于 Helium 來說,這已經是最好的完全矢量化解決方案所需要的一切了。具體工作原理如下:處理器使用大小字段和剩余元素的數量來計算剩余迭代次數。如果最后一次迭代要處理的元素個數少于矢量長度,則矢量末尾相應數量的元素將被禁用。
因此,在上文復制 31 個字節的例子中,Helium 會在第一次迭代時并行復制 16 個字節,然后在下一次迭代時并行復制 15 個字節。這不僅可以避免 Amdahl 定律的影響,實現該有的性能,還可以完全消除串行尾碼,減少代碼量,簡化開發過程。
由于面臨高性能目標和嚴格的面積/中斷延遲限制,我們在設計 Helium 時就像在設計一個多維拼圖,且其中一半的形狀是已經固定的。架構中看似毫不相干的部分可以相互作用,產生意想不到的效果或助力解決一些有趣的難題。
整個 Helium 研究團隊和我都無比期待看到 Helium 技術能夠為全新的應用帶來有力的支持。目前 Cortex-M 已有三款產品支持 Helium 技術——Cortex-M52、Cortex-M55 和 Cortex-M85,我迫不及待看到 Helium 技術持續賦能我們生態伙伴的 AI 創新應用。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19259瀏覽量
229652 -
寄存器
+關注
關注
31文章
5336瀏覽量
120230 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238253 -
機器學習
+關注
關注
66文章
8406瀏覽量
132562 -
Cortex-M85
+關注
關注
0文章
13瀏覽量
539
原文標題:Helium技術講堂 | 克服Amdahl定律的影響
文章出處:【微信號:瑞薩MCU小百科,微信公眾號:瑞薩MCU小百科】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【阿爾達科技便攜式節能速熱恒溫電烙鐵試用體驗】開箱收件
【阿爾達科技便攜式節能速熱恒溫電烙鐵免費試用】開箱與鳴謝
【阿爾達科技便攜式節能速熱恒溫電烙鐵免費試用】焊接1.25mm排針
【阿爾達科技便攜式節能速熱恒溫電烙鐵試用體驗】1、開箱測評
【阿爾達科技便攜式節能速熱恒溫電烙鐵試用體驗】阿爾達節能烙鐵試用體驗及總結
【阿爾達H-30T恒溫電烙鐵試用體驗】一支很用心的烙鐵,阿爾達H-30T恒溫電烙鐵
【阿爾達H-30T恒溫電烙鐵試用體驗】阿爾達H-30T恒溫電烙鐵試用體驗
【阿爾達H-30T恒溫電烙鐵試用體驗】主要性能指標實測結果分享

如何克服Amdahl定律的影響呢?





 工商網監
工商網監
評論