

背景簡介
Apache Spark(下文簡稱Spark)是一種開源集群計算引擎,支持批/流計算、SQL分析、機器學(xué)習(xí)、圖計算等計算范式,以其強大的容錯能力、可擴(kuò)展性、函數(shù)式API、多語言支持(SQL、Python、Java、Scala、R)等特性在大數(shù)據(jù)計算領(lǐng)域被廣泛使用。其中,Spark SQL 是 Spark 生態(tài)系統(tǒng)中的一個重要組件,它允許用戶以結(jié)構(gòu)化數(shù)據(jù)的方式進(jìn)行數(shù)據(jù)處理,提供了強大的查詢和分析功能。
隨著SSD和萬兆網(wǎng)卡普及以及IO技術(shù)的提升,CPU計算逐漸成為Spark 作業(yè)的瓶頸,而IO瓶頸則逐漸消失。 有以下幾個原因,首先,因為 JVM 提供的 CPU 指令級的優(yōu)化如 SIMD要遠(yuǎn)遠(yuǎn)少于其他 Native 語言(如C/C++,Rust)導(dǎo)致基于 JVM 進(jìn)行 CPU 指令的優(yōu)化比較困難。其次,NVMe SSD緩存技術(shù)和AQE帶來的自動優(yōu)化shuffle極大的減輕了IO延遲。最后,Spark的謂詞下推優(yōu)化跳過了不需要的數(shù)據(jù),進(jìn)一步減少了IO開銷。
基于此背景,Databricks(Spark背后的商業(yè)公司)在2022年SIGMOD會議上發(fā)表論文《Photon: A Fast Query Engine for Lakehouse Systems》,其核心思想是使用C++、向量化執(zhí)行等技術(shù)來執(zhí)行Spark物理計劃,在客戶工作負(fù)載上獲得了平均3倍、最大10倍的性能提升,這證明Spark向量化及本地化是后續(xù)值得優(yōu)化的方向。 Spark3.0(2020年6月發(fā)布)開始支持了數(shù)據(jù)的列式處理,英偉達(dá)也提出了利用GPU加速Spark的方案,利用GPU的列式計算和并發(fā)能力加速Join、Sort、Aggregate等常見的ETL操作。
DPU(Data Processing Unit) 作為未來計算的三大支柱之一,其設(shè)計旨在提供強大的計算能力,以加速各種數(shù)據(jù)處理任務(wù)。DPU的硬件加速能力,尤其在數(shù)據(jù)計算、數(shù)據(jù)過濾等計算密集型任務(wù)上,為處理海量數(shù)據(jù)提供了新的可能。通過高度定制和優(yōu)化的架構(gòu),DPU能夠在處理大規(guī)模數(shù)據(jù)時顯著提升性能,為數(shù)據(jù)中心提供更高效、快速的計算體驗,從而滿足現(xiàn)代數(shù)據(jù)處理需求的挑戰(zhàn)。但是目前DPU對Spark生態(tài)不能兼容,Spark計算框架無法利用DPU的計算優(yōu)勢。
中科馭數(shù)HADOS 異構(gòu)計算加速軟件平臺(下文簡稱HADOS)是一款敏捷異構(gòu)軟件平臺,能夠為網(wǎng)絡(luò)、存儲、安全、大數(shù)據(jù)計算等場景進(jìn)行提速。對于大數(shù)據(jù)計算場景,HADOS可以認(rèn)為是一個異構(gòu)執(zhí)行庫,提供了數(shù)據(jù)類型、向量數(shù)據(jù)結(jié)構(gòu)、表達(dá)式計算、IO和資源管理等功能。 為了發(fā)揮Spark與DPU各自的優(yōu)勢,基于HADOS平臺,我們開發(fā)了RACE算子卸載引擎,既能夠發(fā)揮Spark優(yōu)秀的分布式調(diào)度能力又可以發(fā)揮DPU的向量化執(zhí)行能力。
我們通過實驗發(fā)現(xiàn),將Spark SQL的計算任務(wù)通過RACE卸載到DPU上, 預(yù)期可以把原生SparkSQL的單表達(dá)式的執(zhí)行效率提升至9.97倍,TPC-DS單Query提升最高4.56倍。本文將介紹如何基于 DPU和RACE來加速 Spark SQL的查詢速度,為大規(guī)模數(shù)據(jù)分析和處理提供更可靠的解決方案。
整體架構(gòu)
整個解決方案可以參考下圖:
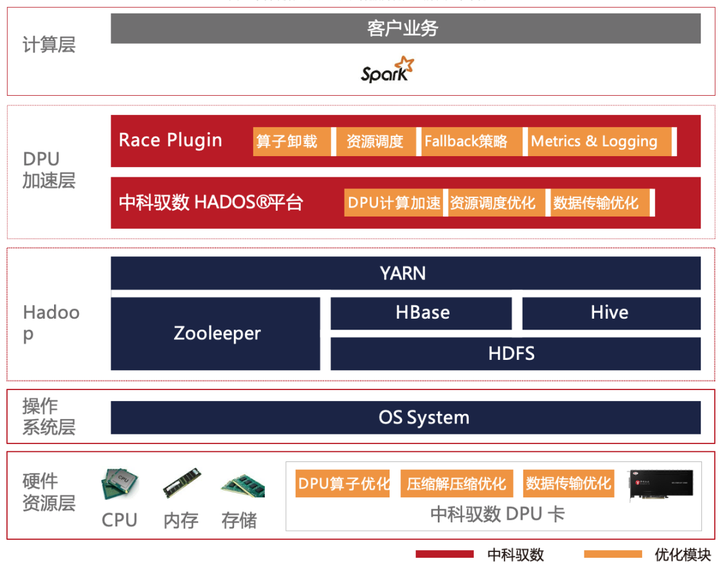
? 最底層硬件資源層是DPU硬件,是面向數(shù)據(jù)中心的專用處理器,其設(shè)計旨在提供強大的計算能力,以加速各種數(shù)據(jù)處理任務(wù),尤其是優(yōu)化Spark等大數(shù)據(jù)框架的執(zhí)行效率。通過高度定制和優(yōu)化的架構(gòu),DPU能夠在處理大規(guī)模數(shù)據(jù)時顯著提升性能,為數(shù)據(jù)中心提供更高效、快速的計算體驗。
? DPU加速層底層是HADOS異構(gòu)計算加速軟件平臺,是中科馭數(shù)推出的專用計算敏捷異構(gòu)軟件開發(fā)平臺。HADOS數(shù)據(jù)查詢加速庫通過提供基于列式數(shù)據(jù)的查詢接口,供數(shù)據(jù)查詢應(yīng)用。支持Java、Scala、C和C++語言的函數(shù)調(diào)用,主要包括列數(shù)據(jù)管理、數(shù)據(jù)查詢運行時函數(shù)、任務(wù)調(diào)度引擎、函數(shù)運算代價評估、內(nèi)存管理、存儲管理、硬件管理、DMA引擎、日志引擎等模塊,目前對外提供數(shù)據(jù)管理、查詢函數(shù)、硬件管理、文件存儲相關(guān)功能API。
? DPU加速層中的RACE層,其最核心的能力就是修改執(zhí)行計劃樹,通過 Spark Plugin 的機制,將Spark 執(zhí)行計劃攔截并下發(fā)給 DPU來執(zhí)行,跳過原生 Spark 不高效的執(zhí)行路徑。整體的執(zhí)行框架仍沿用 Spark 既有實現(xiàn),包括消費接口、資源和執(zhí)行調(diào)度、查詢計劃優(yōu)化、上下游集成等。
? 最上層是面向用戶的原生Spark,用戶可以直接使用已有的業(yè)務(wù)邏輯,無感享受DPU帶來的性能提升
目前支持的算子覆蓋Spark生產(chǎn)環(huán)境常用算子,包括Scan、Filter、Project、Union、Hash Aggregation、Sort、Join、Exchange等。表達(dá)式方面,我們開發(fā)了目前生產(chǎn)環(huán)境常用的布爾函數(shù)、Sum/Count/AVG/Max/Min等聚合函數(shù)。
其中RACE層的架構(gòu)如下:
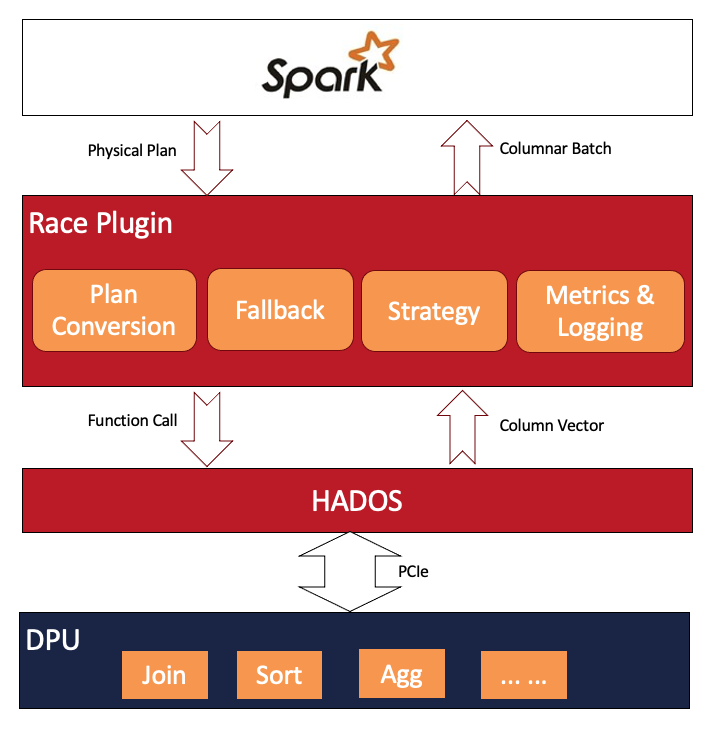
下面我們著重介紹RACE層的核心功能。
核心功能模塊
RACE與Spark的集成
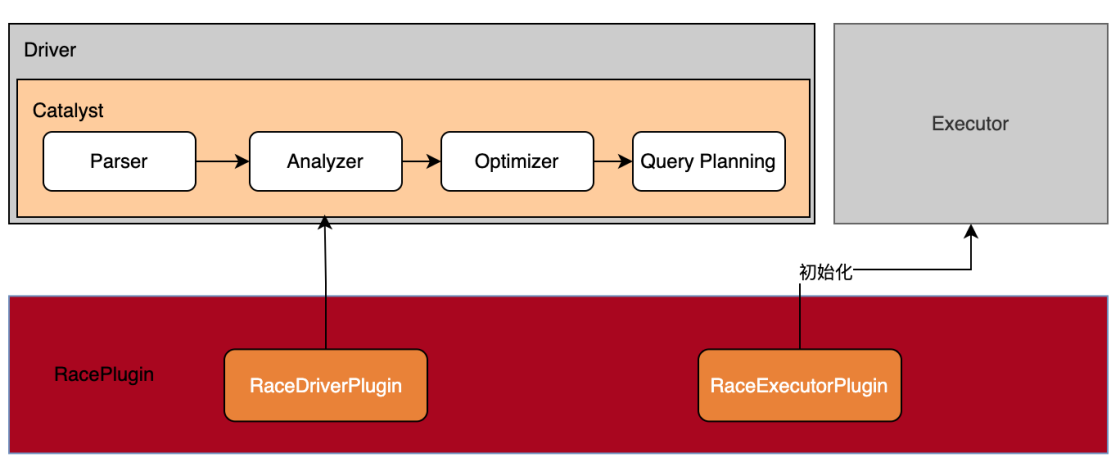
RACE作為Spark的一個插件,實現(xiàn)了SparkPlugin接口,與Spark的集成分為Driver端和Executor端。
? 在Driver端, 通過Spark Catalyst擴(kuò)展點插入自定義的規(guī)則,實現(xiàn)對查詢語句解析過程、優(yōu)化過程以及物理計劃轉(zhuǎn)換過程的控制。
? 在Executor端, 插件在Executor的初始化過程中完成DPU設(shè)備的初始化工作。
Plan Conversion
Spark SQL在優(yōu)化 Physical Plan時,會應(yīng)用一批規(guī)則,RACE通過插入的自定義規(guī)則可以攔截到優(yōu)化后的Physical Plan,如果發(fā)現(xiàn)當(dāng)前算子上的所有表達(dá)式可以下推給DPU,那么替換Spark原生算子為相應(yīng)的可以在DPU上執(zhí)行的自定義算子,由HADOS將其下推給DPU 來執(zhí)行并返回結(jié)果。
Fallback
Spark支持的Operator和Expression非常多,在RACE研發(fā)初期,無法 100% 覆蓋 Spark 查詢執(zhí)行計劃中的算子和表達(dá)式,因此 RACE必須有Fallback機制,支持Spark 查詢執(zhí)行計劃中部分算子不運行在DPU上。
對于DPU無法執(zhí)行的算子,RACE安排 Fallback 回正常的 Spark 執(zhí)行路徑進(jìn)行計算。例如,下圖中展示了插件對原生計劃樹的修改情況,可以下推給DPU的算子都替換成了對應(yīng)的"Dpu"開頭的算子,不能下推的算子仍然保留。除此之外,會自動插入行轉(zhuǎn)列算子或者列轉(zhuǎn)行算子來適配數(shù)據(jù)格式的變化。
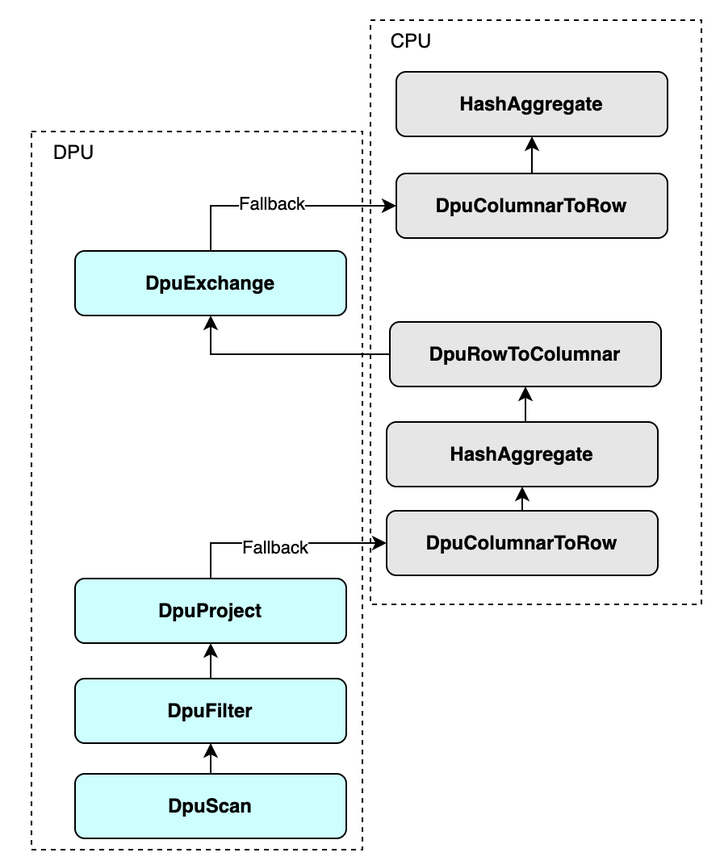
當(dāng)然了,不管是行轉(zhuǎn)列算子還是列轉(zhuǎn)行算子,都是開銷比較大的算子,隨著RACE支持的算子和表達(dá)式越來越多,F(xiàn)allback的情況會逐漸減少。
Strategy
當(dāng)查詢計劃中存在未卸載的算子時,因為這樣引入了行列轉(zhuǎn)換算子,由于其帶來了額外的開銷,導(dǎo)致即使對于卸載到DPU上的算子,其性能得到提升,而對于整個查詢來說,可能會出現(xiàn)比原生Spark更慢的情況。 針對這種情況,最穩(wěn)妥的方式就是整個Query全部回退到CPU,這至少不會比原生Spark慢,這是很重要的。
由于Spark3.0加入了AQE的支持,規(guī)則通常攔截到的是一個個QueryStage,它是Physical Plan的一部分而非完整的 Physical Plan。 RACE的策略是獲取AQE規(guī)則介入之前的整個Query的 Physical Plan,然后分析該Physical Plan中的算子是否全部可卸載。如果全部可以卸載,則對QueryStage進(jìn)行Plan Conversion, 如果不能全部卸載,則跳過Plan Conversion轉(zhuǎn)而直接交給Spark處理。
我們在實際測試過程中發(fā)現(xiàn),一些算子例如Take操作,它需要處理的數(shù)據(jù)量非常小,那么即使發(fā)生Fallback,也不會有很大的行列轉(zhuǎn)換開銷,通過白名單機制忽略這種算子,防止全部回退到CPU,達(dá)到加速目的。
Metrics
RACE會收集DPU執(zhí)行過程中的指標(biāo)統(tǒng)計,然后上報給Spark的Metrics System做展示,以方便Debug和系統(tǒng)調(diào)優(yōu)。
Native Read&Write
SparkSQL的Scan算子支持列式讀取,但是Spark的向量與DPU中定義的向量不兼容,需要在JVM中進(jìn)行一次列轉(zhuǎn)行然后拷貝到DPU中,這會造成巨大的IO開銷。我們主要有以下優(yōu)化:
1. 減少行列轉(zhuǎn)換:對于Parquet格式等列式存儲格式的文件讀取,SparkSQL采用的是按列讀取的方式,即Scan算子是列式算子,但是后續(xù)數(shù)據(jù)過濾等數(shù)據(jù)處理算子均是基于行的算子,SparkSQL必須把列式數(shù)據(jù)轉(zhuǎn)換為行式數(shù)據(jù),這會導(dǎo)致額外的計算開銷。而本方案由于都是列式計算的算子,因此無需這種行列轉(zhuǎn)換。
2. 減少內(nèi)存拷貝: RACE卸載Scan算子到HADOS平臺,HADOS平臺的DPUScan算子以Native庫的方式加載磁盤數(shù)據(jù)直接復(fù)制到DPU,省去了JVM到DPU的拷貝開銷
3. 謂詞下推支持:DPUScan也支持ColumnPruning規(guī)則,這個規(guī)則會確保只有真正使用到的字段才會從這個數(shù)據(jù)源中提取出來。支持兩種Filter:PartitionFilters和PushFilters。PartitionFilters可以過濾掉無用的分區(qū), PushFilters把字段直接下推到Parquet文件中去
4. 同時,文件的寫出也進(jìn)行了類似的優(yōu)化
注意,這些優(yōu)化仍然需要對數(shù)據(jù)進(jìn)行一次復(fù)制,DPU直接讀取磁盤是一個后續(xù)的優(yōu)化方向。
加速效果
TPC-DS 單Query加速
單機單線程local模式場景,在1T數(shù)據(jù)集下,TPC-DS語句中有5條語句E2E時間提升比例超過2倍,最高達(dá)到4.56倍:
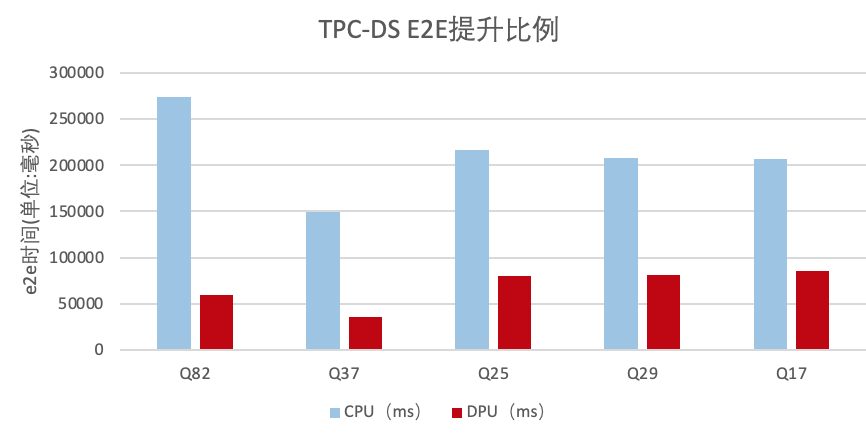
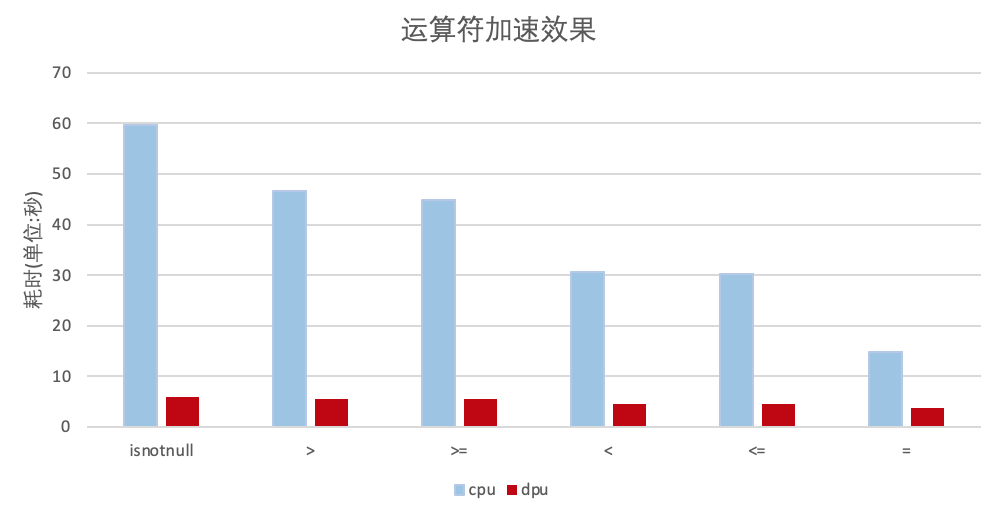
運算符加速效果
運算符的性能提升,DPU運算符相比Spark原生的運算符的加速比最高達(dá)到9.97。
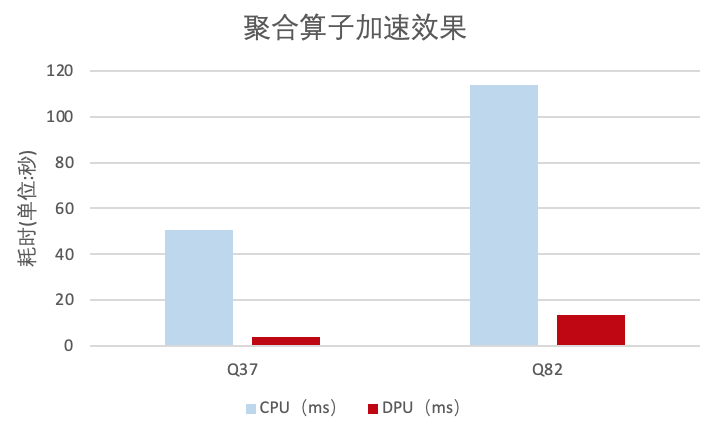
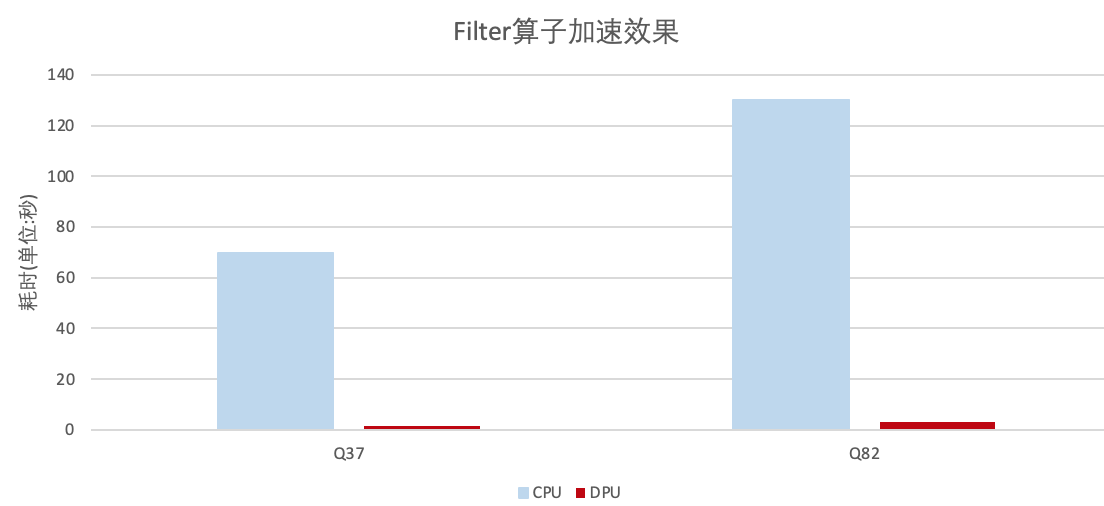
算子加速效果
TPC-DS的測試中,向?qū)τ谠鶶park解決方案,本方案Filter算子性能最高提高到了43倍,哈希聚合算子提升了13倍。這主要是因為我們節(jié)省了列式數(shù)據(jù)轉(zhuǎn)換為行式數(shù)據(jù)的開銷以及DPU運算的加速。
CPU資源使用情況
CPU資源從平均60%下降到5%左右
原生Spark方案CPU使用情況:
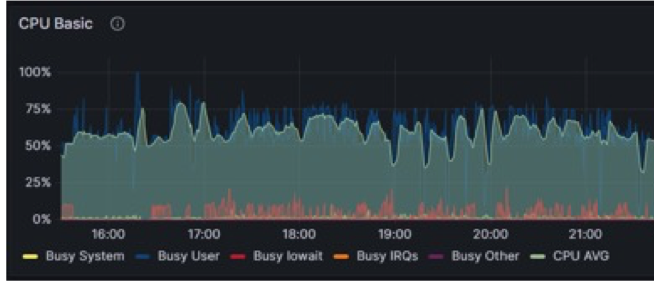
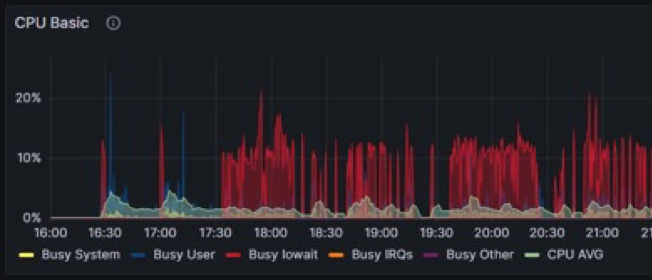
基于RACE和DPU加速后,CPU使用情況:
總結(jié)與展望
通過把Spark的計算卸載到DPU加速器上,在用戶原有代碼無需變更的情況下,端到端的性能可以得到2-5倍的提升,某些算子能達(dá)到43倍性能提升,同時CPU資源使用率從60%左右下降到5%左右,顯著提升了原生SparkSQL的執(zhí)行效率。DPU展現(xiàn)了強大的計算能力,對于端到端的分析,會有一些除去算子之外的因素影響整體運行時間,包括磁盤IO,網(wǎng)絡(luò)Shuffle以及調(diào)度的Overhead。這些影響因素將來可以逐步去做特定的優(yōu)化,例如:
1. 算子的Pipeline執(zhí)行
原生Spark的算子Pipeline執(zhí)行以及CodeGen都是Spark性能提升的關(guān)鍵技術(shù),當(dāng)前,我們卸載到DPU中的計算還沒有支持Pipeline以及CodeGen。未來這兩個技術(shù)的加入,是繼續(xù)提升Spark的執(zhí)行效率的一個方向。
2. 讀數(shù)據(jù)部分,通過DPU卡直讀磁盤數(shù)據(jù)來做優(yōu)化
我們還可以通過DPU卡直接讀取硬盤數(shù)據(jù),省去主機DDR到DPU卡DDR的數(shù)據(jù)傳輸時間,以達(dá)到性能提升的效果,可以參考英偉達(dá)的GPU對磁盤讀寫的優(yōu)化,官方數(shù)據(jù)CSV格式的文件讀取可優(yōu)化20倍左右。
3. RDMA技術(shù)繼續(xù)提升Shuffle性能
對于Shuffle占比很高的作業(yè),可以通過內(nèi)存Shuffle以及RDMA技術(shù),來提升整個Shuffle的過程,目前已經(jīng)實現(xiàn)內(nèi)存Shuffle,未來我們還可以通過RDMA技術(shù)直讀遠(yuǎn)端內(nèi)存數(shù)據(jù),從而完成整個Shuffle鏈路的優(yōu)化。
審核編輯 黃宇
-
DPU
+關(guān)注
關(guān)注
0文章
385瀏覽量
24556 -
SPARK
+關(guān)注
關(guān)注
1文章
105瀏覽量
20291 -
RACE
+關(guān)注
關(guān)注
0文章
2瀏覽量
2382
發(fā)布評論請先 登錄
相關(guān)推薦
用tlv320aic14k音頻采集,有該芯片在Linux 3.x下的驅(qū)動嗎?
無法下載GRID-for-windows驅(qū)動程序(GRID 4.x和3.x)
是否可以使用SPC5Studio 3.x進(jìn)行STM32開發(fā)?
什么是DPU?
利用Apache Spark和RAPIDS Apache加速Spark實踐
中科馭數(shù)發(fā)布軟件開發(fā)平臺HADOS 2.0 釋放DPU極致性能
Spark基于DPU Snappy壓縮算法的異構(gòu)加速方案
Spark基于DPU的Native引擎算子卸載方案

如何將CCS 3.x工程遷移至最新的Code Composer Studio? (CCS)

TMS320C6201(修訂版2.x)至TMS320C6201B(修訂版3.x)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論