 FP8在NVIDIA GPU架構和軟件系統中的應用
FP8在NVIDIA GPU架構和軟件系統中的應用
在深度學習和人工智能的快速發展背景下,尤其是大語言模型(Large Language Model,LLM)的蓬勃發展,模型的大小和計算復雜性不斷增加,對硬件的性能和能效提出了極高要求。為了滿足這些需求,業界一直在尋求新的技術和方法來優化計算過程。其中,FP8(8 位浮點數)技術憑借其獨特的優勢,在 AI 計算領域嶄露頭角。本文作為 FP8 加速推理和訓練系列的開篇,將深入探討 FP8 的技術優勢,以及它在 NVIDIA 產品中的應用,并通過客戶案例來展示 FP8 在實際部署中的強大潛力。
FP8 的原理與技術優勢
FP8 是一種 8 位浮點數表示法,FP8 采取 E4M3 和 E5M2 兩種表示方式,其中 E 代表指數位(Exponent),M 代表尾數位(Mantissa)。在表示范圍內,E4M3 更精準,而 E5M2 有更寬的動態范圍。與傳統的 FP16(16 位浮點數)和 FP32(32 位浮點數)相比,它顯著減少了存儲,提高了計算吞吐。
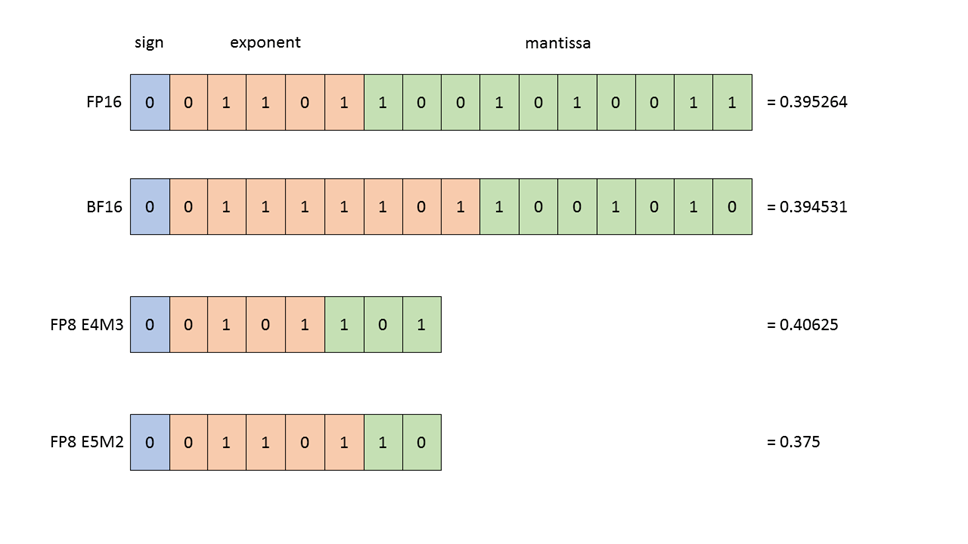
圖 1:浮點數據類型的結構。所有顯示的值
(在 FP16、BF16、FP8 E4M3 和 FP8 E5M2 中)
都是最接近數值 0.3952 的表示形式。
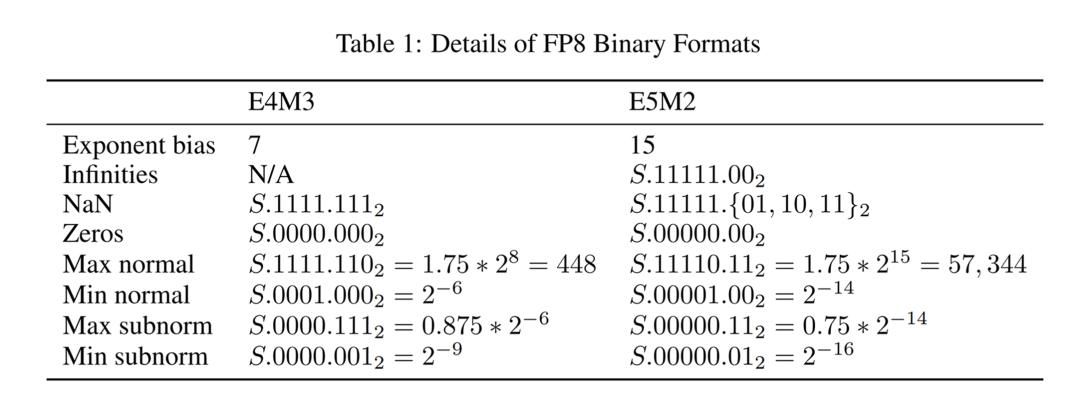
圖 2:FP8 二進制格式
數據表示位數的降低帶來了更大的吞吐和更高的計算性能,雖然精度有所降低,但是在 LLM 場景下,采用技術和工程手段,FP8 能夠提供與更高精度類型相媲美的結果,同時帶來顯著的性能提升和能效改善。
性能提升:由于 FP8 的數據寬度更小,減少了顯存占用,降低了通訊帶寬要求,提高了 GPU 內存讀寫的吞吐效率。并且在相同的硬件條件下,支持 FP8 的 Tensor Core 可以在相同時間內進行更多次的浮點運算,加快訓練和推理的速度。
模型優化:FP8 的使用促使模型在訓練和推理過程中進行量化,這有助于模型的優化和壓縮,進一步降低部署成本。
與 INT8 的數值表示相比較,FP8 在 LLM 的訓練和推理更有優勢。因為 INT8 在數值空間是均勻分布的,而 FP8 有更寬的動態范圍, 更能精準捕獲 LLM 中參數的數值分布,配合 NVIDIA Transformer Engine、NeMo 以及 Megatron Core 的訓練平臺和 TensorRT-LLM 推理優化方案,大幅提升了 LLM 的訓練和推理的性能,降低了首 token 和整個生成響應的時延。
FP8 在 NVIDIA GPU 架構和軟件系統中的應用
作為 AI 計算領域的領導者,NVIDIA 一直在推動新技術的發展和應用。FP8 技術在其產品中得到了廣泛的支持和應用。
GPU 架構與 Transformer Engine
NVIDIA GPU 無論是 Hopper 架構、還是 Ada Lovelace 架構都支持 Transformer Engine 進行 FP8 的訓練和推理。Transformer Engine 是一項專門為加速 Transformer 模型訓練和推理而打造的軟件庫,應用混合的 FP8 和 FP16/BF16 精度格式,大幅加速 Transformer 訓練,同時保持準確性。FP8 也可大幅提升大語言模型推理的速度,性能提升高達 Ampere 架構的 30 倍。
推理方面
TensorRT-LLM
TensorRT-LLM是 NVIDIA 針對 LLM 推出的高性能推理解決方案。它融合了 FasterTransformer 的高性能與 TensorRT 的可擴展性,提供了大量針對 LLM 的新功能,而且能與 NVIDIA Triton 推理服務器緊密配合,使先進的 LLM 發揮出更優異的端到端性能。
TensorRT-LLM 可運行經 FP8 量化的模型,支持 FP8 的權重和激活值。經 FP8 量化的模型能極好地保持原 FP16/BF16 模型的精度,并且在 TensorRT-LLM 上加速明顯,無論在精度上還是性能上,都明顯好于 INT8 SmoothQuant。
TensorRT-LLM 還為 KV 緩存(key-value cache)提供了 FP8 量化。KV 緩存默認是 FP16 數據類型,在輸入文本或輸出文本較長時,占據顯著的數據量;在使用 FP8 量化之后,其數據量縮小一半,明顯地節省顯存,從而可以運行更大的批量。此外,切換到 FP8 KV 緩存可減輕全局顯存讀寫壓力,進一步提高性能。
訓練方面
NVIDIA NeMo
NVIDIA NeMo 是一款端到端云原生框架,用戶可以在公有云、私有云或本地,靈活地構建、定制和部署生成式 AI 模型。它包含訓練和推理框架、護欄工具包、數據管護工具和預訓練模型,為企業快速采用生成式 AI 提供了一種既簡單、又經濟的方法。NeMo 適用于構建企業就緒型 LLM 的全面解決方案。
在 NeMo 中,NVIDIA 集成了對 FP8 的全面支持,使得開發者能夠輕松地在訓練和推理過程中使用 FP8 格式。通過 NeMo 的自動混合精度訓練功能,開發者可以在保持模型準確性的同時,顯著提高訓練速度。此外,NeMo 還將陸續提供了一系列配套的工具、庫和微服務,幫助開發者優化 FP8 推理的性能等。這些功能使得 NeMo 成為了一個強大而靈活的框架,能夠滿足各種 AI 應用場景的需求。
Megatron Core
Megatron Core 是 NVIDIA 推出的一個支持 LLM 訓練框架的底層加速庫。它包含了訓練 LLM 所需的所有關鍵技術,例如:各類模型并行的支持、算子優化、通信優化、顯存優化以及 FP8 低精度訓練等。Megatron Core 不僅吸收了 Megatron-LM 的優秀特性,還在代碼質量、穩定性、功能豐富性和測試覆蓋率上進行了全面提升。更重要的是,Megatron Core 在設計上更加解耦和模塊化,不僅提高了 LLM 訓練的效率和穩定性,也為二次開發和探索新的 LLM 架構提供了更大的靈活性。
Megatron Core 支持 FP8 的訓練,很快也將支持 MoE 的 FP8 訓練。
FP8 在 LLM 訓練和推理的成功應用
以下將詳細介紹幾個成功案例,并深入剖析其中的技術細節,以展現 FP8 在推動 AI 模型高效訓練和快速推理方面的巨大潛力。
FP8 在 LLM 的推理方面的成功應用
Google 的 Gemma 模型與 TensorRT-LLM 完美結合
Google 一直在尋求提高其 LLM 的推理效率。為此,Google 與 NVIDIA 團隊合作,將 TensorRT-LLM 應用于 Gemma 模型,并結合 FP8 技術進行了推理加速。
技術細節方面,雙方團隊首先使用 NVIDIA AMMO 庫對 Gemma 模型進行了精細的量化處理,將模型的權重和激活值從高精度浮點數(FP16/BF16)轉換為低精度浮點數(FP8)。通過仔細調整量化參數,技術團隊確保了 Gemma 模型在使用低精度進行推理的時候不損失準確性。這一步驟至關重要,因為它直接影響到模型推理的性能和準確性。
接下來,技術團隊利用 TensorRT-LLM 對量化后的 Gemma 模型進行了優化。TensorRT-LLM 通過一系列優化技術(如層融合、flash-attention)來提高模型的推理速度。在這個過程中,FP8 技術發揮了重要作用。由于 FP8 的數據寬度較小,它顯著減少了模型推理過程中所需的顯存帶寬和計算資源,從而提高了推理速度。同時,FP8 能夠降低存放激活值、KV 緩存所需要的顯存,增大我們推理時能夠使用的 batch size,進一步的提升我們的吞吐量。
最終,通過 TensorRT-LLM 和 FP8 技術的結合,Google 成功在模型發布的同時實現了 Gemma 模型的高效推理。這不僅為用戶提供了更快的響應時間和更流暢的語言處理體驗,還展示了 FP8 在推動 AI 模型推理加速方面的巨大潛力。
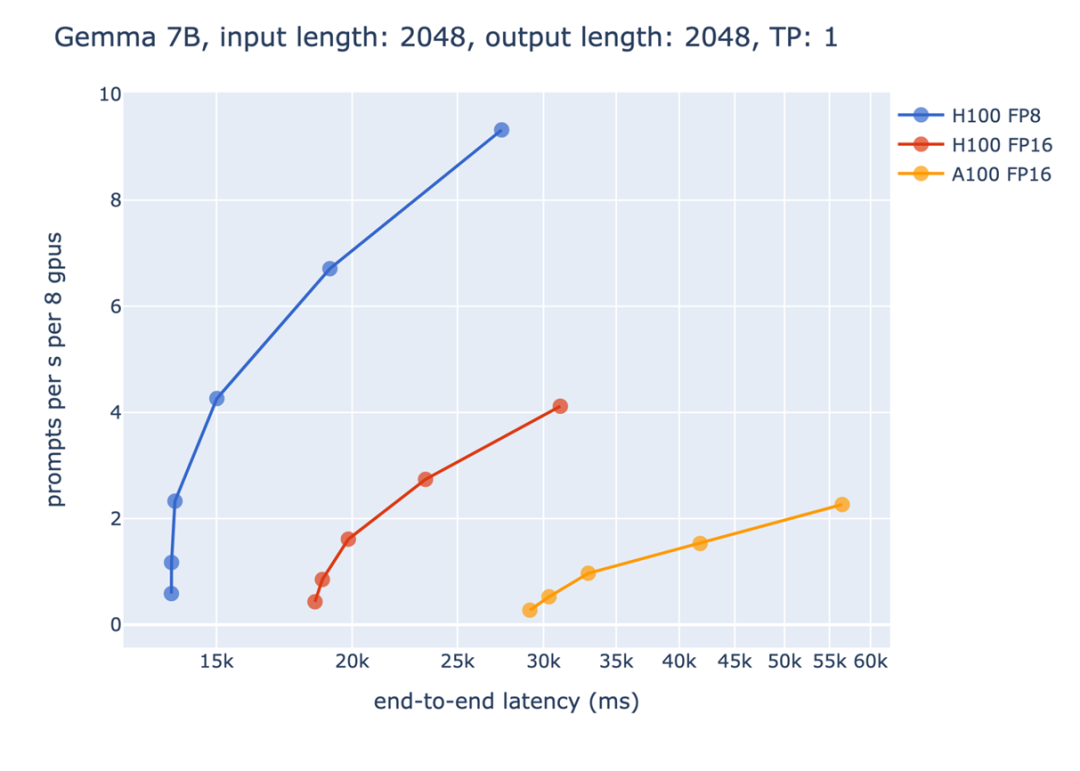
圖 3:靜態批處理,延遲 vs 吞吐量
從上圖我們可以看到 FP8 相較于 FP16 帶來的收益。橫軸代表的是某個端到端的時間限制,縱軸代表的是吞吐量。對于生成式模型的性能評測,不能夠單純的只考慮吞吐量或是延遲。如果只追求吞吐量,導致延遲太長,會讓使用者有不好的體驗;相反的,如果只考慮延遲,則會導致沒辦法充分利用硬件資源,造成浪費。
因此,常見的評測條件是,在一定的延遲限制下,達到最大的吞吐量。以上圖為例,如果將端到端的時間限制設為 15 秒,則只有 FP8 能夠滿足要求,這展示了在一些對延遲限制比較嚴格的場景下,FP8 加速帶來的重要性。而在 20 秒這個時間限制下,都使用 Hopper GPU 進行推理時,FP8 對比 FP16 在吞吐量上能夠帶來 3 倍以上的收益。這是由于上面提到的,FP8 能夠在相同的時間限制下使用更大的 batch size,從而有更好的 GPU 利用率,達到更高的吞吐量。
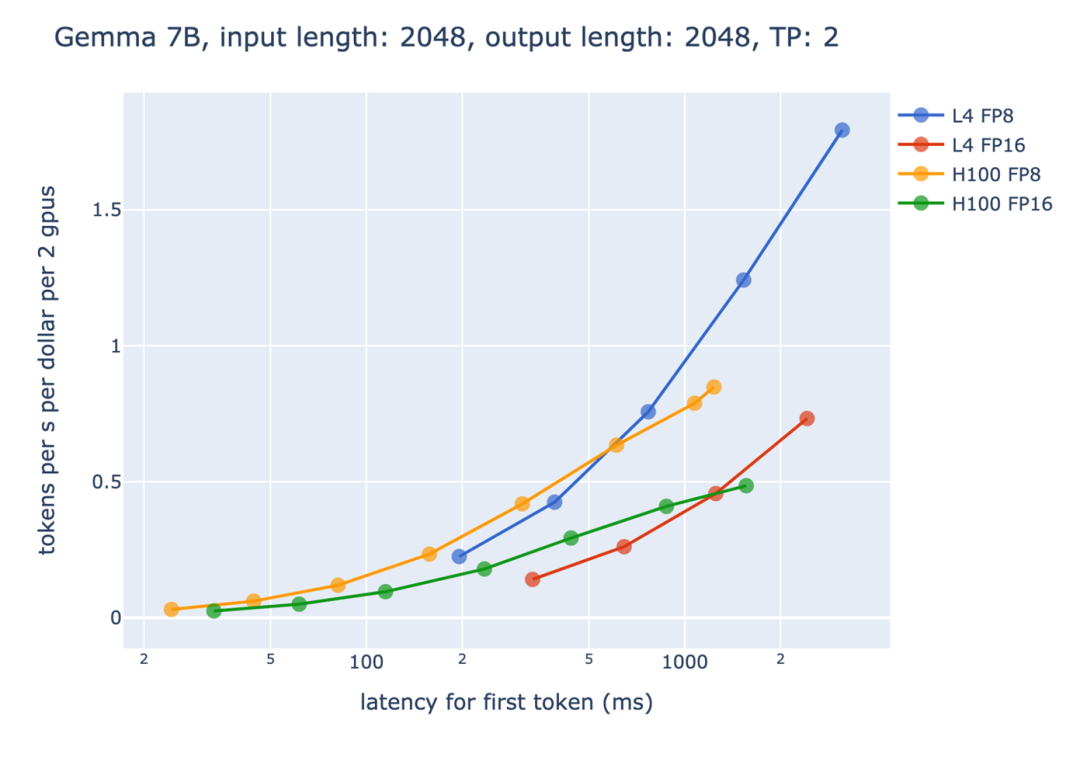
圖 4:首 token 延遲 vs 基于每 dollar 的吞吐量
另外一方面,從性價比的角度來看,FP8 也帶來了很大的收益。上圖中,橫軸是產生第一個 token 的時間限制,而縱軸則是每單位的資源能產生的 token 數量。請注意由于要處理長輸入,產生第一個 token 的時間通常會比較長,而后面的階段可以透過流處理(streaming)的方式,每產生一個 token 就立即返回給使用者,讓使用者不會覺得等待時間過長。我們可以觀察到,隨著時間限制的增加,FP8 帶來的收益也越來越大。尤其是在 L4 Tensor Core GPU 上面,由于 GPU 本身的顯存較小,因此 FP8 節省顯存使用帶來的效益更加的明顯。
FP8 在 LLM 訓練方面的成功應用
Inflection AI 的 FP8 訓練
Inflection AI 是一家專注于 AI 技術創新的公司,他們的使命是創造人人可用的 AI,所以他們深知大模型的訓練對于 AI 生成內容的精準性和可控性至關重要。因此,在他們近期推出的 Inflection2 模型中,采用了 FP8 技術對其模型進行訓練優化。
Inflection-2 采用了 FP8 混合精度在 5000 個 NVIDIA Hopper 架構 GPU 上進行了訓練,累計浮點運算次數高達約 10^25 FLOPs。與同屬訓練計算類別的 Google 旗艦模型 PaLM 2 相比,在包括知名的 MMLU、TriviaQA、HellaSwag 以及 GSM8k 等多項標準人工智能性能基準測試中,Inflection-2 展現出了卓越的性能,成功超越了 PaLM 2,彰顯了其在模型訓練方面的領先性,同時也印證了 FP8 混合精度訓練策略能夠保證模型正常收斂并取得良好的性能。
從 LLM 訓練到推理, FP8 端到端的成功應用
零一萬物的雙語 LLM 模型:FP8 端到端訓練與推理的卓越表現
零一萬物是一家專注于 LLM 的獨角獸公司,他們一直致力于在 LLM 模型及其基礎設施和應用的創新。其最新的支持 200K 文本長度的開源雙語模型,在 HuggingFace 預訓練榜單上,與同等規模的模型中對比表現出色。在零一萬物近期即將發布的千億模型 AI Infra 技術上,他們成功地在 NVIDIA GPU 上進行了端到端 FP8 訓練和推理,并完成了全鏈路的技術驗證,取得了令人矚目的成果。
零一萬物的訓練框架是基于 NVIDIA Megatron-LM 開發的 Y 訓練框架, 其 FP8 訓練基于 NVIDIA Transformer Engine。在此基礎上,零一萬物團隊進一步的設計了訓練容錯方案:由于沒有 BF16 的 baseline 來檢查千億模型 FP8 訓練的 loss 下降是否正常,于是,每間隔一定的步數,同時使用 FP8 和 BF16 進行訓練,并根據 BF16 和 FP8 訓練的 loss diff 和評測指標地差異,決定是否用 BF16 訓練修正 FP8 訓練。
由于 FP8 訓練的過程中需要統計一定歷史窗口的量化信息,用于 BF16 到 FP8 的數據裁切轉換,因此在 BF16 訓練過程中,也需要在 Transformer Engine 框架內支持相同的統計量化信息的邏輯,保證 BF16 訓練可以無縫切換到 FP8 訓練,且不引入訓練的效果波動。在這個過程中,零一萬物基于 NVIDIA 軟硬結合的技術棧,在功能開發、調試和性能層面,與 NVIDIA 團隊合作優化,完成了在大模型的 FP8 訓練和驗證。其大模型的訓練吞吐相對 BF16 得到了 1.3 倍的性能提升。
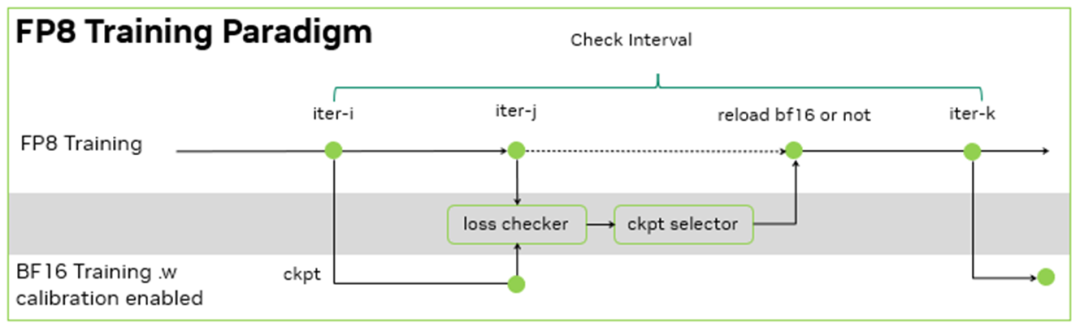
圖 5:FP8 訓練范式
在推理方面,零一萬物基于 NVIDIA TensorRT-LLM 開發了 T 推理框架。這個框架提供了從 Megatron 到 HuggingFace 模型的轉化,并且集成了 Transformer Engine 等功能,能夠支持 FP8 推理,大大減小了模型運行時需要的顯存空間,提高了推理速度,從而方便社區的開發者來體驗和開發。具體過程為:
將 Transformer Engine 層集成到 Hugging Face 模型定義中。
開發一個模型轉換器,將 Megatron 模型權重轉換為 HuggingFace 模型。
加載帶有校準額外數據的 Huggingface 模型,并使用 FP8 精度進行基準測試。取代 BF16 張量以節省顯存占用,并在大批量推理中獲得 2~5 倍的吞吐提升。

圖 6:FP8 模型轉換與評測流程
總結與展望
基于上述 LLM 使用 FP8 訓練和推理的成功實踐,我們可以看到 FP8 在推動 AI 模型的高效訓練和快速推理方面的巨大潛力。隨著 FP8 訓練和推理方法的不斷完善和廣泛應用,我們確信 FP8 將在 LLM 應用中扮演越來越重要的角色,敬請期待更多成功案例和技術解密。
審核編輯:劉清
-
NVIDIA
+關注
關注
14文章
4978瀏覽量
102987 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238255 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5804 -
大模型
+關注
關注
2文章
2423瀏覽量
2641
原文標題:FP8:前沿精度與性能的新篇章
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
解鎖NVIDIA TensorRT-LLM的卓越性能
《CST Studio Suite 2024 GPU加速計算指南》
如何使用FP8新技術加速大模型訓練
FP8數據格式在大型模型訓練中的應用

TensorRT-LLM低精度推理優化


【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
AMD與NVIDIA GPU優缺點
FP8模型訓練中Debug優化思路
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
NVIDIA推出兩款基于NVIDIA Ampere架構的全新臺式機GPU

FPGA在深度學習應用中或將取代GPU
NVIDIA的Maxwell GPU架構功耗不可思議

NVIDIA GPU因出口管制措施推遲發布





 工商網監
工商網監
評論