") Achronix新推出一款用于AI/ML計(jì)算或者大模型的B200芯片
Achronix新推出一款用于AI/ML計(jì)算或者大模型的B200芯片
近日舉辦的GTC大會(huì)把人工智能/機(jī)器學(xué)習(xí)(AI/ML)領(lǐng)域中的算力比拼又帶到了一個(gè)新的高度,這不只是說(shuō)明了通用圖形處理器(GPGPU)時(shí)代的來(lái)臨,而是包括GPU、FPGA和NPU等一眾數(shù)據(jù)處理加速器時(shí)代的來(lái)臨,就像GPU以更高的計(jì)算密度和能效勝出CPU一樣,各種加速器件在不同的AI/ML應(yīng)用或者細(xì)分市場(chǎng)中將各具優(yōu)勢(shì),未來(lái)并不是只要貴的而是更需要對(duì)的。
此次GTC上新推出的用于AI/ML計(jì)算或者大模型的B200芯片有一個(gè)顯著的特點(diǎn),它與傳統(tǒng)的圖形渲染GPU大相徑庭并與上一代用于AI/ML計(jì)算的GPU很不一樣。在其他算力器件品種中也是如此,AI/ML計(jì)算尤其是推理應(yīng)用需要一種專(zhuān)為高帶寬工作負(fù)載優(yōu)化的新型FPGA,下面我們以Achronix的Speedster7t FPGA芯片為例來(lái)看看技術(shù)的演進(jìn)方向,以及在實(shí)際推理應(yīng)用中展現(xiàn)出來(lái)的在性?xún)r(jià)比和能效比等方面優(yōu)于先進(jìn)GPU的特性。
先來(lái)快速看看Speedster7t的產(chǎn)品亮點(diǎn):該器件集成了800K到1500K等效邏輯單元以及326K到692K 6輸入查找表(LUT),高達(dá)120T算力的機(jī)器學(xué)習(xí)處理單元(MLP),同時(shí)還配備了高性能存儲(chǔ)和I/O接口,以及最高可達(dá)190Mb的嵌入式存儲(chǔ)容量。在外部連接接口部署上,Speedster7t包含16個(gè)GDDR6通道,可提供高達(dá)4 Tbps的高速存儲(chǔ)帶寬;32對(duì)SerDes通道,支持1-112Gbps的數(shù)據(jù)速率;4個(gè)400G以太網(wǎng)端口(4× 400G或16× 100G)和2個(gè)PCIe Gen5端口,支持16通道(×16)和8通道(×8)配置。
Achronix的Speedster7t FPGA芯片被用戶(hù)認(rèn)為非常適合AI/ML推理原因是:足夠的算力,靈活可配的計(jì)算精度;高帶寬大容量低成本的GDDR6(4Tbps帶寬, 32GB容量);革命性的全新二維片上網(wǎng)絡(luò)(2D NoC)路由架構(gòu);靈活通用的芯片間互聯(lián);支持用戶(hù)基于該芯片開(kāi)發(fā)自定義的推理系統(tǒng),比如單板多片F(xiàn)PGA甚至多板互聯(lián)以組成更高性能(如1TBbps/64GB,2TBbps/128GB, 4TBbps/256GB…等更高帶寬和更大容量的計(jì)算存儲(chǔ))以支持更大或超大模型推理部署。
簡(jiǎn)而言之,相比傳統(tǒng)的推理算力平臺(tái),Speedster7t FPGA可以提供更高性?xún)r(jià)比和能耗比的大模型推理能力;另外,在傳統(tǒng)的FPGA處理功能中,越來(lái)越多的用戶(hù)在該系統(tǒng)中加入機(jī)器學(xué)習(xí)的能力, Speedster7t FPGA能很好勝任傳統(tǒng)FPGA功能和高性能機(jī)器學(xué)習(xí)融合在一起。
一類(lèi)創(chuàng)新性的高性能FPGA系列產(chǎn)品
Achronix Speedster7t系列FPGA基于革命性的FPGA架構(gòu),該架構(gòu)經(jīng)過(guò)了高度優(yōu)化提供了高速、高帶寬內(nèi)外連接,可以滿(mǎn)足日益增長(zhǎng)的人工智能/機(jī)器學(xué)習(xí)、網(wǎng)絡(luò)密集型和數(shù)據(jù)加速應(yīng)用的需求。Speedster7t系列FPGA芯片具有一個(gè)革命性的全新二維片上網(wǎng)絡(luò),以及一個(gè)針對(duì)人工智能/機(jī)器學(xué)習(xí)進(jìn)行優(yōu)化的高密度的機(jī)器學(xué)習(xí)處理單元陣列。通過(guò)將FPGA的可編程性與類(lèi)似ASIC路由架構(gòu)和計(jì)算引擎相結(jié)合,Speedster7t系列提高了高性能FPGA的標(biāo)準(zhǔn)。
全新的二維片上網(wǎng)絡(luò)(2D NoC)提供ASIC級(jí)別的性能
Speedster7t系列FPGA芯片具有革命性的2D NoC,可在整個(gè)FPGA邏輯陣列中傳輸數(shù)據(jù),并將數(shù)據(jù)傳輸?shù)礁咝阅躀/O和內(nèi)存子系統(tǒng),同時(shí)可提供高達(dá)20 Tbps的總帶寬。憑借2D NoC,在Speedster7t FPGA芯片不需要消耗任何可編程邏輯資源的情況下來(lái)進(jìn)行數(shù)據(jù)傳輸。在該芯片上的2D NoC提供了20 Tbps的二維片上網(wǎng)絡(luò)總帶寬;該2D NoC不僅覆蓋了芯片全域,而且還連接到各類(lèi)高速接口和總帶寬高達(dá)4 Tbps的高速存儲(chǔ)接口。
高速接口
無(wú)論是支持輸入和輸出的數(shù)據(jù)流,還是存儲(chǔ)緩沖這些數(shù)據(jù),對(duì)于高性能計(jì)算、機(jī)器學(xué)習(xí)和硬件加速解決方案而言,都需要在片內(nèi)和片外傳輸數(shù)據(jù)。Speedster7t系列FPGA芯片的架構(gòu)可支持前所未有的帶寬。包括:
400G以太網(wǎng):Speedster7t系列FPGA芯片支持多達(dá)4個(gè)400GbE端口或16個(gè)100GbE端口,通過(guò)2D NoC連接到FPGA邏輯。
PCI Express Gen5:Speedster7t系列FPGA芯片配備了多個(gè)PCle Gen5接口,支持速率達(dá)32GT/s。
存儲(chǔ)接口:GDDR6 + DDR4/5
Speedster7t器件是唯一在片上支持GDDR6存儲(chǔ)器的FPGA,以最低的DRAM成本(每存儲(chǔ)位)提供最快的SDRAM訪問(wèn)速度。Speedster7t系列FPGA芯片具有高達(dá)4 Tbps的GDDR6帶寬,以很低的成本就可提供相當(dāng)于基于HBM的FPGA存儲(chǔ)器帶寬。Speedster7t系列FPGA芯片包括了DDR4/5存儲(chǔ)器接口,以支持更深入的緩沖需求。PHY和控制器支持由JEDEC規(guī)范定義的所有標(biāo)準(zhǔn)功能。
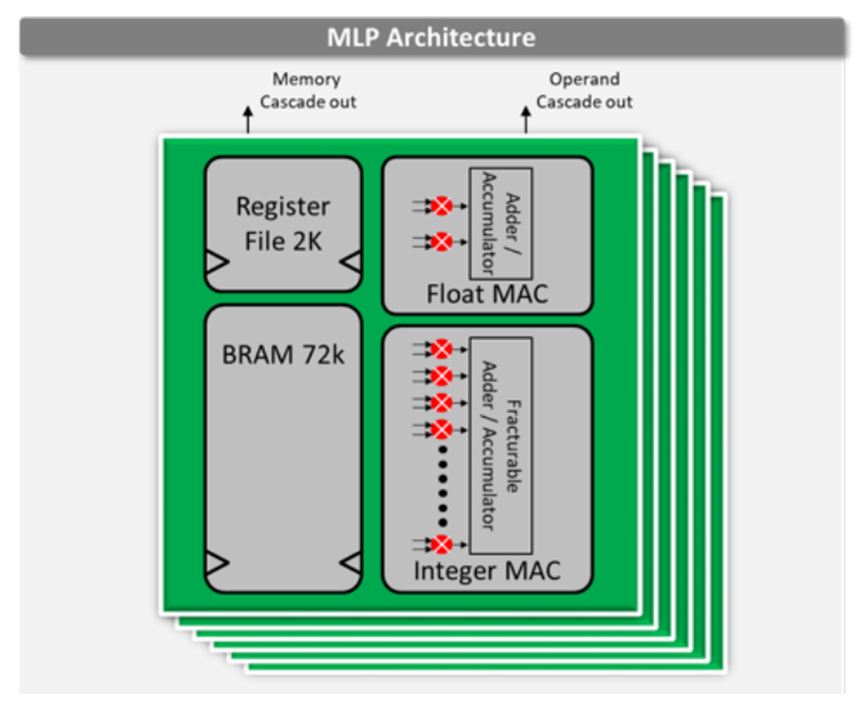
機(jī)器學(xué)習(xí)處理單元
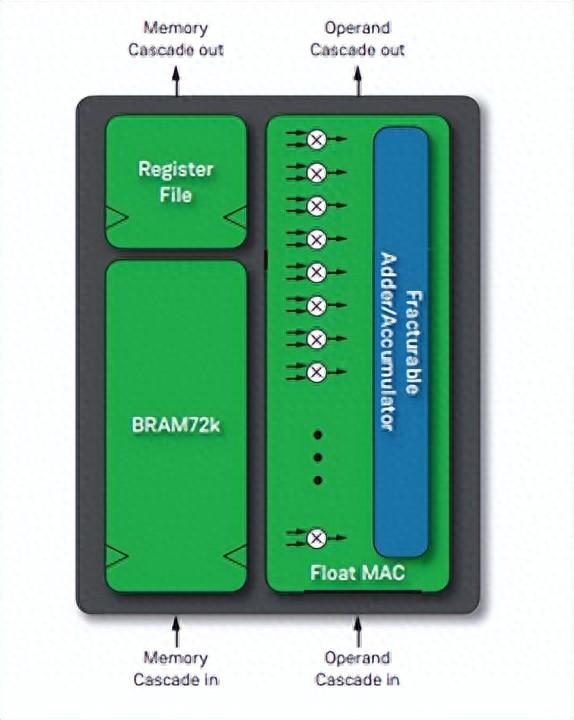
每個(gè)Speedster7t FPGA器件都具有可編程的數(shù)學(xué)計(jì)算單元,這些單元被集成至全新的機(jī)器學(xué)習(xí)處理單元(MLP)模塊中。每個(gè)MLP都是一個(gè)高度可配置的計(jì)算密集型模塊,具有多達(dá)32個(gè)乘法器/累加器(MAC),支持4到24位整數(shù)格式和各種浮點(diǎn)模式,包括Tensorflow的bfloat16格式以及高效的塊浮點(diǎn)格式,大大提高了性能。
MLP模塊包括緊密集成的嵌入式存儲(chǔ)器模塊,以確保機(jī)器學(xué)習(xí)算法將以750 MHz的最高性能運(yùn)行。這種高密度計(jì)算和高性能數(shù)據(jù)傳輸?shù)慕Y(jié)合造就了高性能機(jī)器學(xué)習(xí)處理結(jié)構(gòu),該結(jié)構(gòu)可提供市場(chǎng)上基于FPGA的極高TOPS級(jí)別運(yùn)算能力(TOPS即Tera-Operations Per Second,每秒萬(wàn)億次運(yùn)算)。
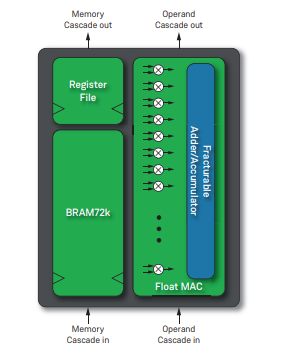
圖中文字說(shuō)明:Register File - 寄存器文件,F(xiàn)racturable Adder/Accumulator - 可拆分的加法器/累加器,F(xiàn)loat MAC - 浮點(diǎn)乘累加單元(MAC),Memory Cascade in - 存儲(chǔ)器級(jí)聯(lián),Operand Cascade in - 操作數(shù)級(jí)聯(lián)。 設(shè)計(jì)工具支持
Achronix Tool Suite工具套件是一個(gè)支持所有Achronix硬件產(chǎn)品的工具鏈。它可與行業(yè)標(biāo)準(zhǔn)的邏輯綜合和仿真工具結(jié)合使用,從而使FPGA設(shè)計(jì)人員能夠輕松地將其設(shè)計(jì)映射到Speedster7t FPGA器件中。Achronix Tool Suite工具套件包括Synopsys的Synplify Pro的優(yōu)化版本和Achronix Snapshot調(diào)試器。Achronix仿真庫(kù)由Siemens EDA的ModelSim、Synopsys的VCS和Aldec的Riviera-PRO提供支持。
展望:在推理等領(lǐng)域幫助開(kāi)發(fā)者打造綜合性能優(yōu)于先進(jìn)GPU的應(yīng)用
隨著AI/ML技術(shù)在各個(gè)領(lǐng)域開(kāi)始廣泛走進(jìn)應(yīng)用,Achronix根據(jù)Speedster7t FPGA器件的高性能和高帶寬特性,選擇了推理這一個(gè)應(yīng)用面非常廣的技術(shù)市場(chǎng)方向,與合作伙伴加大了在Speedster7t FPGA器件上的推理算法和IP的研發(fā),以期幫助更多的創(chuàng)新者實(shí)現(xiàn)突破。
該芯片提供了足夠的算力,并利用其片上搭載的二維片上網(wǎng)絡(luò)(2D NoC)和機(jī)器學(xué)習(xí)處理單元(MLP),各種高速接口和GDDR6高帶寬存儲(chǔ)接口,提供了用于大規(guī)模推理應(yīng)用需要的計(jì)算器件內(nèi)外連接、硬件加速和存儲(chǔ)調(diào)用等新技術(shù),從而可以支持開(kāi)發(fā)者快速去實(shí)現(xiàn)創(chuàng)新。
這個(gè)策略取得了顯著的成果,其中一個(gè)領(lǐng)域是加速自動(dòng)語(yǔ)言識(shí)別(ASR)解決方案,它由搭載Speedster7t FPGA器件的VectorPath加速卡提供支持,運(yùn)行Myrtle.ai提供的基于Achronix FPGA的ASR IP,從而提供業(yè)界領(lǐng)先的、實(shí)時(shí)的、超低延遲的語(yǔ)音轉(zhuǎn)文本功能。運(yùn)行在服務(wù)器中的單張VectorPath加速卡可替代多達(dá)20臺(tái)僅基于CPU的服務(wù)器或10張GPU加速卡。
Speedster7t FPGA的技術(shù)創(chuàng)新為人工智能推理帶來(lái)了更高性?xún)r(jià)比和更高能效比以及可以讓用戶(hù)開(kāi)發(fā)自定義的推理硬件平臺(tái)和系統(tǒng)。 在ASR實(shí)際性能方面,其出色的超低單詞錯(cuò)誤率和僅有最先進(jìn)GPU解決方案八分之一以下的端到端延遲(包括了預(yù)處理和后處理以及與CPU做數(shù)據(jù)交互的時(shí)間)顛覆了ASR領(lǐng)域。該解決方案可以在標(biāo)準(zhǔn)的機(jī)器學(xué)習(xí)框架中使用垂直應(yīng)用特定的或自定義的數(shù)據(jù)集進(jìn)行定制或重新訓(xùn)練。
對(duì)于越來(lái)越多的其他的推理應(yīng)用,Speedster7t FPGA的獨(dú)創(chuàng)高帶寬架構(gòu)也可以為這些應(yīng)用提供有力的支撐。Achronix正在通過(guò)不斷研發(fā),以完善其工具鏈和應(yīng)用生態(tài),將在2024年推出更好的工具來(lái)幫助各種推理應(yīng)用的開(kāi)發(fā),使眾多的用戶(hù)更加便捷地使用Speedster7t FPGA器件或者VectorPath加速卡來(lái)實(shí)現(xiàn)性?xún)r(jià)比和能效提升,而不用去爭(zhēng)搶緊俏的高性能GPU加速卡。
審核編輯:劉清
-
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238259 -
圖形處理器
+關(guān)注
關(guān)注
0文章
198瀏覽量
25539 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132565 -
FPGA器件
+關(guān)注
關(guān)注
1文章
22瀏覽量
11607 -
GDDR6
+關(guān)注
關(guān)注
0文章
52瀏覽量
11312
原文標(biāo)題:新型的FPGA器件將支持多樣化AI/ML創(chuàng)新進(jìn)程
文章出處:【微信號(hào):Achronix,微信公眾號(hào):Achronix】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
亞馬遜轉(zhuǎn)向Trainium芯片,全力投入AI模型訓(xùn)練
NVIDIA DGX B200首次面向零售市場(chǎng):配備8塊B200 GPU
基于Achronix Speedster7t FPGA器件的AI基準(zhǔn)測(cè)試
Mistral AI與NVIDIA推出全新語(yǔ)言模型Mistral NeMo 12B
特斯拉加碼AI布局:xAI將采購(gòu)30萬(wàn)塊英偉達(dá)B200芯片
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
人工智能模型公司Anthropic近日推出了一款Claude移動(dòng)端App
日本Sakura互聯(lián)網(wǎng)投資英偉達(dá)B200芯片 助力AI計(jì)算及數(shù)據(jù)中心發(fā)展
新型的FPGA器件將支持多樣化AI/ML創(chuàng)新進(jìn)程
英偉達(dá)H200性能顯著提升,年內(nèi)將推出B200新一代AI半導(dǎo)體
英偉達(dá)發(fā)布新一代AI芯片B200
英偉達(dá)發(fā)布性能大幅提升的新款B200 AI GPU
戴爾發(fā)布英偉達(dá)B200 AI GPU:高功耗達(dá)1000W,創(chuàng)新性冷卻工程設(shè)計(jì)必要
字節(jié)跳動(dòng)推出一款顛覆性視頻模型—Boximator
Stability AI推出迄今為止更小、更高效的1.6B語(yǔ)言模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論