 深入解析NVIDIA Blackwell架構及其實現細節
深入解析NVIDIA Blackwell架構及其實現細節
智猩猩與智東西將于4月18-19日在北京共同舉辦2024中國生成式AI大會,阿里巴巴通義千問大模型技術負責人周暢,「清華系Sora」生數科技CEO唐家渝,Open-Sora開發團隊潞晨科技創始人尤洋等40+位嘉賓已確認參會,其中鴻博股份副總裁&英博數科CEO周韡韡,中科曙光智能計算產品事業部總經理杜夏威,安謀科技產品總監楊磊三位算力與芯片領域的大咖將帶來主題演講,歡迎報名。
小編按:美國時間3月18日在美國圣何塞SAP中心舉行Nvidia GTC 2024,CEO黃仁勛開幕演說:見證AI變革時刻。其中最火最熱的當屬Blackwell架構和其架構下的B200 GPU。各方解讀都有,本文整理anandtech翻譯,嘗試淺析Blackwell的架構和實現,供各位參考。不當之處請批評指正。
目前,英偉達已經穩固地占據了生成式人工智能加速器市場的主導地位,它長期以來一直明確表示,該公司不會放慢腳步并查看觀點。相反,英偉達打算繼續迭代其GPU和加速器的多代產品路線圖,以利用其早期優勢,并在加速器市場中不斷增長的競爭對手中保持領先地位。因此,盡管 NVIDIA 廣受歡迎的 H100/H200/GH200 系列加速器已經是硅谷最熱門的門票,但現在是時候談論下一代加速器架構來滿足NVIDIA的AI 野心了:Blackwell。
在 5 年來首次面對面GTC的背景下(自Volta成立以來,NVIDIA從未舉辦過此類GTC,NVIDIA首席執行官黃仁勛(Jensen Huang)將登臺宣布公司在過去幾年中一直在努力開發的一系列新企業產品和技術。但這些公告都不像英偉達的服務器芯片公告那樣引人注目,因為正是Hopper架構GH100芯片和運行在它之上的NVIDIA深度軟件堆棧揭開了AI加速器行業的蓋子,并使NVIDIA成為全球第三大最有價值的公司。
Blackwell架構以美國統計學和數學先驅David Harold Blackwell博士的名字命名,他撰寫了第一本貝葉斯統計學教科書,Blackwell 架構再次成為 NVIDIA 在公司許多標志性架構設計上加倍努力的理念,希望找到更智能、更努力地工作的方法,以提高其最重要的數據中心/HPC加速器的性能。NVIDIA與 Hopper(以及之前的Ampere)合作得非常好,在高層次上Blackwell的目標是帶來更多相同的功能,但具有更多功能、更大的靈活性和更多的晶體管。
正如我在 Hopper 發布會上所寫的那樣,“NVIDIA 已經為如何應對服務器 GPU 行業制定了一個非常可靠的劇本。在硬件方面,基本上可以歸結為正確識別當前和未來的趨勢以及客戶對高性能加速器的需求,投資于以極快的速度處理這些工作負載所需的硬件,然后優化所有這些。對于布萊克威爾來說,這種心態并沒有改變。NVIDIA 改進了其芯片設計的各個方面,從性能到內存帶寬,每個元素都旨在提高特定工作負載/場景的性能或消除可擴展性的瓶頸。而且,NVIDIA再次繼續尋找更多方法來減少工作量。
在今天的GTC主題演講之前,NVIDIA向媒體提供了有關Blackwell架構和實現該架構的第一款芯片的有限預簡報。我之所以說“有限”,是因為該公司在主題演講之前沒有透露一些關鍵規格,甚至 GPU 本身的名稱也不清楚;NVDIA稱其為“Blackwell GPU”。但以下是我們目前所知道的關于下一代 NVIDIA 加速器核心的概要。
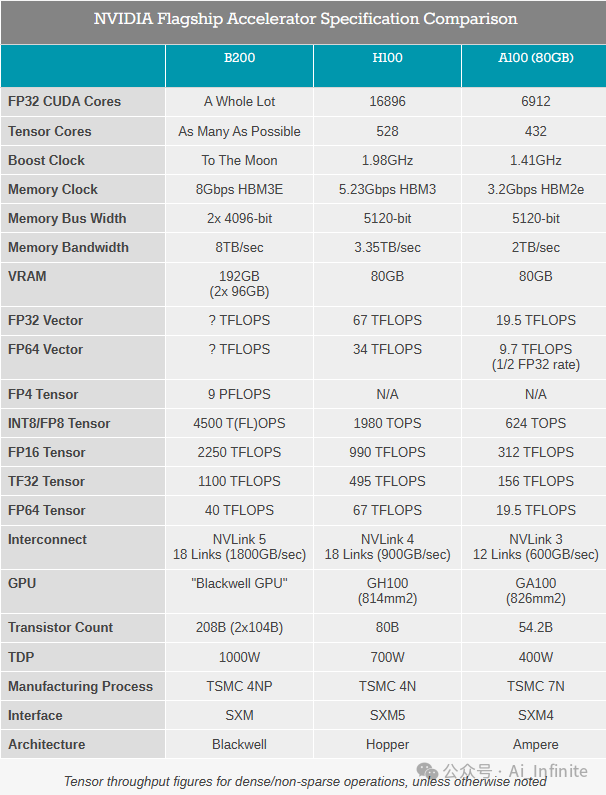
除非另有說明,否則密集/非稀疏操作的張量吞吐量數據
首先要注意的是,Blackwell GPU將會很大。按照字面。它將進入的B200模塊將在單個封裝上具有兩個GPU 芯片。沒錯,NVIDIA終于用他們的旗艦加速器實現了小芯片。雖然他們沒有透露單個模具的尺寸,但我們被告知它們是“十字線大小”的模具,這應該使它們每個超過800mm2。GH100芯片本身已經接近臺積電的4納米光罩限制,因此NVIDIA在這里的增長空間非常小——至少不會停留在單個芯片內。
奇怪的是,盡管存在這些芯片空間限制,但NVIDIA并沒有為Blackwell使用臺積電3nm級節點。從技術上講,他們正在使用一個新節點—臺積電4NP—但這只是用于GH100 GPU的4N節點的更高性能版本。因此,多年來,英偉達第一次沒有利用主要新節點的性能和密度優勢。這意味著 Blackwell 幾乎所有的效率提升都必須來自架構效率,而這種效率和橫向擴展的龐大規模相結合將帶來 Blackwell的整體性能提升。
盡管堅持使用4nm級節點,但NVIDIA已經能夠將更多的晶體管壓縮到單個芯片中。整個加速器的晶體管數量為 208B,即每個芯片 104B 晶體管。GH100是 80B 晶體管,因此每個 B100 芯片的晶體管總體上增加了約 30%,按照歷史標準來看,這是一個適度的收益。這反過來又是為什么我們看到NVIDIA為其完整的GPU使用更多芯片的原因。
對于他們的第一款多芯片芯片,英偉達打算跳過尷尬的“一個芯片上有兩個加速器”階段,直接讓整個加速器表現為單個芯片。根據英偉達的說法,這兩個芯片作為“一個統一的CUDA GPU”運行,提供完整的性能,沒有任何妥協。關鍵是芯片之間的高帶寬I/O 鏈路,NVIDIA將其稱為NV-高帶寬接口(NV-HBI),并提供10TB/秒的帶寬。據推測,這是總量,這意味著芯片可以同時向每個方向發送5TB/秒。
到目前為止,尚未詳細說明的是這種鏈接的構建——NVIDIA 是否始終依賴晶圓基板芯片(CoWoS),使用基礎芯片策略(AMD MI300),或者他們是否依賴單獨的本地中介層來連接兩個芯片(蘋果的 UltraFusion)。無論哪種方式,這都比我們迄今為止看到的任何其他雙芯片橋接解決方案的帶寬都要大得多,這意味著大量的引腳都在發揮作用。
在Blackwell加速器上,每個芯片都與4個HBM3E存儲器堆棧配對,總共8個堆棧,形成8192位的有效存儲器總線寬度。所有 AI 加速器的制約因素之一是內存容量(不要低估對帶寬的需求),因此能夠放置更多堆棧對于提高加速器的本地內存容量非常重要。Blackwell GPU總共提供(高達)192GB的HBM3E,或24GB/堆棧,這與H200的24GB/堆棧容量相同(比原來的16GB/堆棧H100多50%的內存)。
據英偉達稱,該芯片的總HBM內存帶寬為8TB/秒,相當于每個堆棧1TB/秒,或8Gbps/引腳的數據速率。正如我們在之前的HBM3E報道中所指出的,內存最終設計為9.2Gbps/引腳或更高,但我們經常看到NVIDIA在其服務器加速器的時鐘速度上玩得有點保守。無論哪種方式,這幾乎是 H2.4內存帶寬的100倍(或比 H200 多 66%),因此NVIDIA的帶寬顯著增加。
最后,這一代的TDP也再次上升。由于NVIDIA仍處于4nm 級節點上,并且現在將超過兩倍的晶體管封裝到單個Blackwell GPU中,因此TDP除了上升之外無處可去。B200是一個1000W的模塊,高于H100的700W。B200機器顯然仍然可以進行風冷,但毋庸置疑,NVIDIA預計液體冷卻的使用將比以往任何時候都多,無論是出于必要還是出于成本原因。同時,對于現有的硬件安裝,NVIDIA還將發布具有700W TDP的低端B100加速器,使其與H100系統兼容。
總體而言,與集群級別的H100相比,NVIDIA的目標是將訓練性能提高4倍,推理性能提高30 倍,同時將能效提高25倍。我們將介紹這背后的一些技術,毫無疑問,有關NVIDIA打算如何實現這一目標的更多信息將在主題演講中揭曉。
但從這些目標中得到的最有趣的收獲是干擾性能的提高。NVIDIA目前在訓練方面占據主導地位,但推理是一個更廣泛、競爭更激烈的市場。然而一旦這些大型模型被訓練出來,將需要更多的計算資源來執行它們,而NVIDIA不想被排除在外。但這意味著要找到一種方法,在一個更加殘酷的市場中占據(并保持)令人信服的領先優勢,因此NVIDIA有他們的工作要做。
布萊克威爾的三種類型:GB200、B200和B100
NVIDIA 最初將生產三個基于 Blackwell GPU 的加速器。
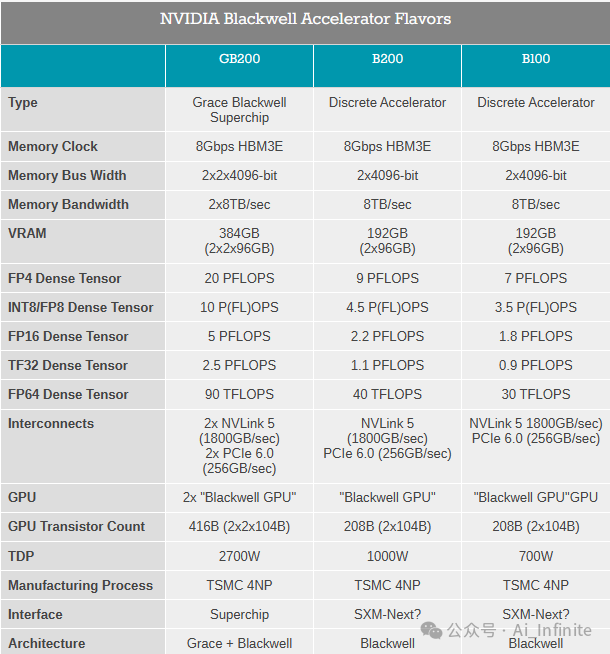
旗艦獨立加速器是B200,其TDP為1000 瓦,獨樹一幟。這部分與現有的 H100系統不兼容,相反,將圍繞它構建新系統。
有趣的是,盡管這是NVIDIA將提供的傳統加速器中最快的,但這并不是峰值性能的Blackwell配置。B200 仍然比最快的Blackwell產品慢 10% 左右。
什么是性能巔峰的產品?Grace·Blackwell超級芯片GB200。由兩個Blackwell GPU和一個72 核Grace CPU組成,是所有Blackwell GPU中速度最快的。例如,這是Blackwell GPU中唯一可以達到每個GPU 20 PFLOPS稀疏 FP4計算性能的配置。當然,在單個超級芯片上使用兩個Blackwell GPU,超級芯片的總吞吐量是其兩倍,即40 PFLOPS FP4。
由于我們沒有關于 Blackwell GPU 的任何詳細規格,因此目前尚不清楚這是否只是時鐘速度差異,或者 GB200 是否正在獲得具有更多啟用張量核心的 GPU 配置。但無論哪種方式,如果您想要最好的布萊克威爾,您都需要以 GB200 超級芯片的形式購買它,以及隨之而來的 Grace。

然而,GB200的電力成本很高。GB200模塊配備2個GPU和板載高性能CPU,可以高達2700瓦的功率運行,是Grace Hopper 200(GH200)峰值可配置 TDP的2.7 倍。假設 Grace CPU 本身的 TDP 為 300W,這使得 Blackwell GPU 在這種配置下的 TDP 達到驚人的 1200W TDP。歸根結底,TDP有些武斷(你通常可以在電壓/頻率曲線上走得更遠一點,以獲得更多的功率),但從廣義上講,Blackwell最顯著的性能提升也是以顯著更高的功耗為代價的。
但對于那些負擔不起更高功率預算的客戶,NVIDIA 的最后一個Blackwell加速器SKU:B100。HGX B100 主板設計為與 HGX H100 主板直接兼容,以相同的每 GPU TDP 700 瓦運行。TDP 最低,這是性能最低的 Blackwell 加速器變體,額定可提供約 78% 的 B200 計算性能。但與它將取代的 H100 GPU 相比,B100 預計將在等精度下提供大約 80% 的計算吞吐量。當然,B100 可以訪問更快、更大數量的 HBM3E 內存。
目前,NVIDIA尚未公布任何Blackwell配置的定價。第一批基于Blackwell的加速器將于今年晚些時候發貨,但該公司沒有提供任何關于它將是哪種Blackwell類型(或者是否會是所有類型)的指導。
第二代變壓器發動機:精度更低
從架構上講,NVIDIA 與 Hopper 的一大勝利是他們決定優化其 Transformer 類型模型的架構,其中包含專用硬件(NVIDIA 稱之為 Transformer Engine)。通過利用變壓器不需要以高精度(FP16)處理所有稱重和參數這一事實,NVIDIA增加了對這些操作與較低精度(FP8)操作混合的支持,以減少內存需求并提高吞吐量。當 GPT-3/ChatGPT 在 2022 年晚些時候起飛時,這個決定得到了非常豐厚的回報,剩下的就是歷史了。
那么,對于他們的第二代變壓器引擎,NVIDIA將更加低迷。Blackwell 將能夠處理低至 FP4 精度的數字格式——是的,一種只有 16 個狀態的浮點數字格式——著眼于使用極低精度的格式進行推理。對于FP4提供的精度太低的工作負載,NVIDIA還增加了對FP6精度的支持。與 FP8 相比,FP6 沒有提供任何計算性能優勢——它基本上仍然作為 FP8 操作通過 NVIDIA 的張量核心——但由于數據大小縮小了 25%,它仍然提供內存壓力和帶寬優勢。一般來說,LLM 推理仍然受到這些加速器的內存容量的限制,因此通過推理降低內存使用量有很大的壓力。
與此同時,在訓練方面,NVIDIA正在考慮在FP8上進行更多的訓練,而不是目前使用的BF16 / FP16。這再次使計算吞吐量保持在較高水平,內存消耗較低。但是,LLM訓練中使用的精度最終超出了NVIDIA的控制范圍,而取決于開發人員,他們需要優化他們的模型以在這些低精度下工作。
在這一點上,轉換器已經顯示出一種有趣的能力,可以處理較低精度的格式,而不會在精度方面損失太多。但至少可以說,FP4 相當低。因此,在沒有進一步信息的情況下,我非常好奇 NVIDIA 及其用戶打算如何以如此低的數據精度滿足他們的準確性需求,因為 FP4 對推理有用似乎是決定 Blackwell 作為推理平臺的成敗。
無論如何,NVIDIA 希望單個基于 Blackwell 的 GPU 能夠提供高達 10 PetaFLOPS 的稀疏性 FP8 性能,或 5 PFLOPS 的密集矩陣。這大約是 H100 速率的 2.5 倍,甚至更荒謬的 FP4 推理性能為 20 PFLOPS。H100 甚至沒有從 FP4 中受益,因此與其最小 FP8 數據大小相比,當可以使用 FP4 時,B200 的原始推理吞吐量應該會增加 5 倍。
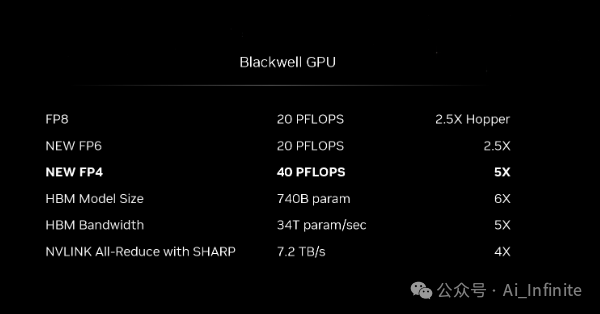
假設 NVIDIA 的計算性能比與 H100 保持不變,FP16 性能是 FP8 的一半,并從那里向下擴展,B200 也將是一款非常強大的芯片,精度也更高。盡管至少對于人工智能用途而言,但顯然目標是嘗試以盡可能低的精度逃脫。
另一方面,在主題演講之前,FP64張量性能也未被披露。NVIDIA 自 Ampere 架構以來一直提供 FP64 張量功能,盡管與較低的精度相比,速度要低得多。這對絕大多數 AI 工作負載幾乎沒有用處,但對 HPC 工作負載是有益的。因此,我很好奇 NVIDIA 在這里計劃了什么——B200 是否會在 HPC 方面發揮重要作用,或者 NVIDIA 是否打算全力以赴開發低精度 AI。
NVLink 5:1.8TB/秒的芯片IO,多機架域可擴展性
除了拋出更多的張量核心和更多的內存帶寬之外,從硬件的角度來看,加速器性能的第三個關鍵因素是互連帶寬。NVIDIA 對他們在過去十年中通過其專有的 NVLink 互連系統所取得的成就感到非常自豪,并且他們正在繼續為 Blackwell 在帶寬和可擴展性方面進行迭代。特別是考慮到需要將大量系統聯網在一起,以便及時訓練最大的 LLM,并建立一個足夠大的內存池來容納它們,NVLink 是 NVIDIA 加速器設計和成功的關鍵因素。
Blackwell推出了第五代NVLink,為了簡單起見可稱為NVLink 5。
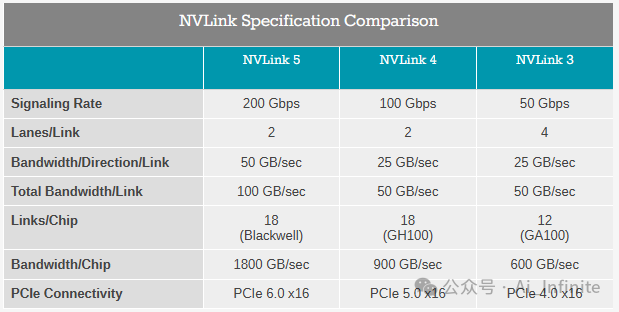
看看迄今為止披露的規格,在高層次上,NVIDIA已將NVLink的帶寬從每個 GPU的900GB/秒翻倍到每個GPU的1800GB/秒。與上一代產品相比,這是過去幾年NVLink帶寬的最大飛躍,因為2022年的Hopper架構僅提供了50%的 NVLink帶寬環比提升。
值得注意的是,NVIDIA將互連帶寬量增加了一倍,同時將 GPU上的芯片數量增加了一倍,因此流入每個芯片的數據量沒有變化。但是,由于兩個芯片需要作為一個處理器協同工作,因此要消耗(和洗牌)的數據總量顯著增加。
也許更有趣的是,在引擎蓋下,每個GPU的NVLink數量沒有變化;GH100 Hopper的NVLink 容量為18 個鏈路,Blackwell GPU 的 NVLink 容量也是 18個鏈路。因此,NVLink 5的所有帶寬增益都來自鏈路中每個高速對的 200Gbps的更高信令速率。這與最近幾代NVLink一致,后者在每次迭代中都使信令速率翻了一番。
否則,由于NVLink 4的鏈路數量保持不變,本地芯片拓撲選項基本保持不變。NVIDIA的HGX H100設計已經合并了4 路和8路設置,而HGX B200/B100設置將相同。這并不意味著NVIDIA沒有增加NVLink域中GPU數量的雄心壯志,但它將是機架級別而不是節點級別。
這讓我們想到了NVIDIA在展會上的大型芯片公告:第五代NVLink Switch。與NVLink的片上功能相對應,NVIDIA的專用NVLink交換機芯片既負責單節點通信,也負責將機架內的多個節點連接在一起。甚至在 NVIDIA收購網絡專業公司Mellanox之前,該公司就已經通過NVLink交換機提供交換式GPU網絡。
審核編輯:黃飛
-
存儲器
+關注
關注
38文章
7484瀏覽量
163762 -
加速器
+關注
關注
2文章
796瀏覽量
37838 -
NVIDIA
+關注
關注
14文章
4978瀏覽量
102987 -
晶體管
+關注
關注
77文章
9682瀏覽量
138079 -
英偉達
+關注
關注
22文章
3770瀏覽量
90984
原文標題:NVIDIA Blackwell架構和實現詳解
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
NVIDIA火熱招聘GPU高性能計算架構師
深入探討軟件定義架構及其意義

大模型部署框架FastLLM實現細節解析

NVIDIA將在今年第二季度發布Blackwell架構的新一代GPU加速器“B100”

NVIDIA 推出 Blackwell 架構 DGX SuperPOD,適用于萬億參數級的生成式 AI 超級計算

NVIDIA推出搭載GB200 Grace Blackwell超級芯片的NVIDIA DGX SuperPOD?
超微電腦借助英偉達Blackwell架構,打造頂尖生成式AI系統
英偉達Blackwell架構,行業首選
英偉達聯合計算機制造商發布Blackwell架構系統
NVIDIA未來1年的Blackwell訂單已全部售罄
深入解析Zephyr RTOS的技術細節






 工商網監
工商網監
評論