") 如何利用DPU加速Spark大數(shù)據(jù)處理? | 總結(jié)篇
如何利用DPU加速Spark大數(shù)據(jù)處理? | 總結(jié)篇
一、總體介紹
1.1 背景介紹
近年來,隨著存儲硬件的革新與網(wǎng)絡(luò)技術(shù)的突飛猛進,如NVMe SSD和超高速網(wǎng)絡(luò)接口的普及應(yīng)用,I/O性能瓶頸已得到顯著改善。然而,在2020年及以后的技術(shù)背景下,盡管SSD速度通過NVMe接口得到了大幅提升,并且網(wǎng)絡(luò)傳輸速率也進入了新的高度,但CPU主頻發(fā)展并未保持同等步調(diào),3GHz左右的核心頻率已成為常態(tài)。
在當前背景下Apache Spark等大數(shù)據(jù)處理工具中,盡管存儲和網(wǎng)絡(luò)性能的提升極大地減少了數(shù)據(jù)讀取和傳輸?shù)臅r間消耗,但Apache Spark框架基于類火山模型的行式處理,在執(zhí)行復雜查詢、迭代計算時對現(xiàn)代CPU并行計算特性和向量化計算優(yōu)勢的利用率仍然有待提高。同時,傳統(tǒng)TCP/IP網(wǎng)絡(luò)通信模式下,CPU承擔了大量的協(xié)議解析、包構(gòu)建和錯誤處理任務(wù),進一步降低了整體數(shù)據(jù)處理效率,這導致Apache Spark 在實際運行中并沒有達到網(wǎng)絡(luò)、磁盤、CPU的IO瓶頸。
1.2 挑戰(zhàn)和困難
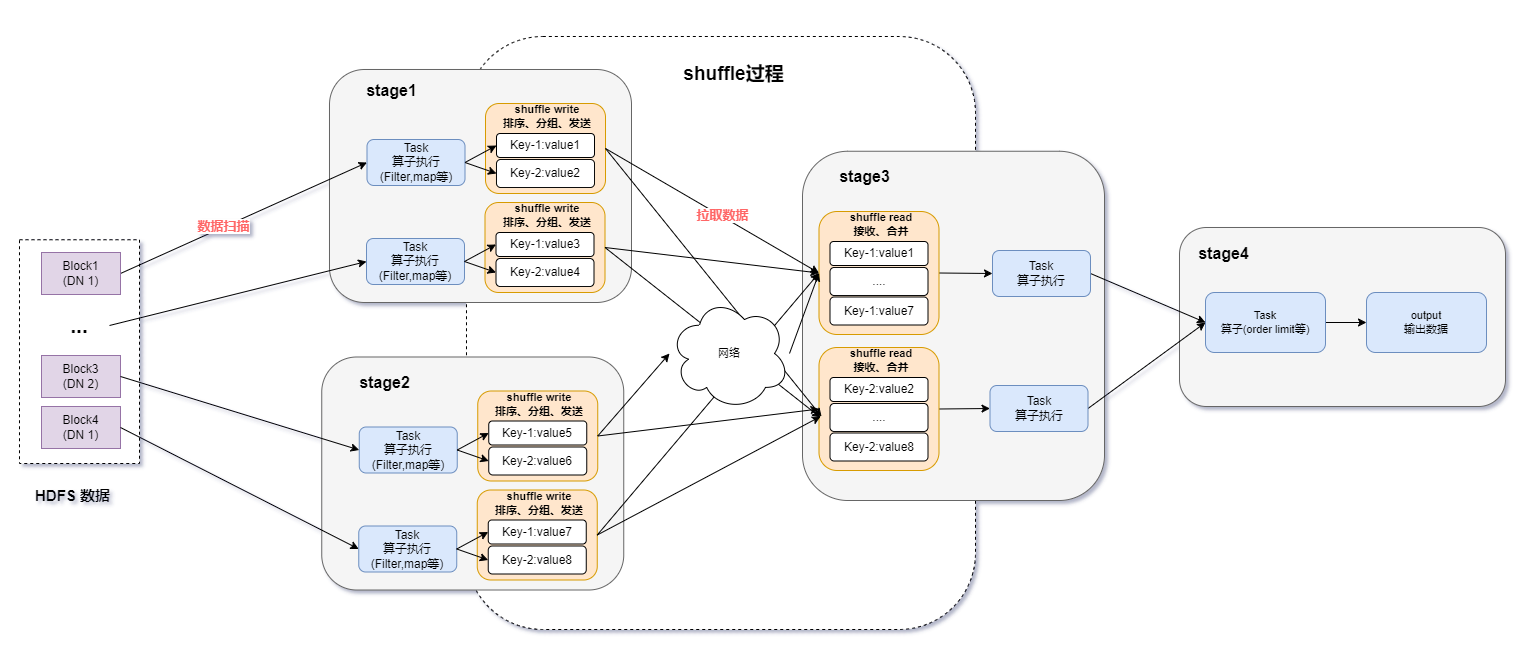
在Apache Spark的數(shù)據(jù)處理流程中,如上圖所示,整個過程從數(shù)據(jù)源開始,首先經(jīng)歷數(shù)據(jù)加載階段。Spark作業(yè)啟動時,任務(wù)被分配到各個運算節(jié)點(executor),它們從諸如HDFS、S3(Amazon Simple Storage Service)或其他支持的存儲系統(tǒng)中高效地獲取數(shù)據(jù)。
一旦數(shù)據(jù)成功加載至內(nèi)存或磁盤上,運算節(jié)點首先開始數(shù)據(jù)的解壓縮工作,然后執(zhí)行相應(yīng)的計算操作,例如map、filter、reduceByKey等轉(zhuǎn)換操作。
接下來,在執(zhí)行涉及不同分區(qū)間數(shù)據(jù)交換的操作(如join、groupByKey)時,Spark會觸發(fā)Shuffle階段。在這個階段,各個executor將計算后的中間結(jié)果按照特定鍵值進行排序,并通過網(wǎng)絡(luò)傳輸至其他executor,以便進行進一步的合并和聚集操作。
完成Shuffle后,數(shù)據(jù)再次經(jīng)過一輪或多輪計算處理,以產(chǎn)出最終結(jié)果。當所有任務(wù)完成后,結(jié)果數(shù)據(jù)會被壓縮后寫回目標存儲系統(tǒng),如HDFS、數(shù)據(jù)庫或其他外部服務(wù),從而完成整個數(shù)據(jù)處理生命周期。
綜上所述,在Apache Spark的數(shù)據(jù)處理過程中,盡管其設(shè)計高度優(yōu)化,但仍面臨多個技術(shù)挑戰(zhàn):
首先,傳統(tǒng)硬件中,數(shù)據(jù)傳輸需要CPU解碼并通過PCIe總線多次搬運至內(nèi)存和硬件,使用反彈緩沖區(qū),雖然是臨時存儲但也增加復雜度與延遲;列式存儲(Parquet、ORC)高效壓縮同類數(shù)據(jù)減少I/O,但讀取時的解壓和編解碼操作加重了CPU負擔,尤其在僅需處理部分列時效率下降;Apache Spark采用行式處理,如DataSourceScanExec按行掃描可能導致冗余加載,并因頻繁調(diào)用“next”及虛函數(shù)引發(fā)CPU中斷,全行掃描對部分列查詢性能損耗顯著。
其次,隨著數(shù)據(jù)量不斷激增以及IO技術(shù)的提升,基于CPU的優(yōu)化帶來的收益越來越不明顯,傳統(tǒng)的CPU算力逐漸成為計算瓶頸。在涉及特定算子操作時,性能問題尤為突出。例如,高散列度數(shù)據(jù)的 join,高散列度數(shù)據(jù)的 aggregate。在執(zhí)行join操作時,尤其當采用基于哈希的join策略時,因為數(shù)據(jù)散列程度越高,哈希計算的負載就越大,對CPU和內(nèi)存的計算能力要求也就越高。哈希計算是一個計算密集型任務(wù),需要CPU執(zhí)行大量的計算操作,并且可能涉及到內(nèi)存的讀取和寫入。當數(shù)據(jù)散列程度較高時,哈希計算的復雜度增加,可能導致CPU和內(nèi)存的使用率增加,從而影響系統(tǒng)的整體性能。其次,數(shù)據(jù)散列程度較高可能會增加哈希沖突的概率,進而影響內(nèi)存的使用效率。當哈希沖突較多時,可能需要額外的操作來解決沖突,例如使用鏈表或者開放地址法來處理沖突。這些額外的操作可能會占用額外的內(nèi)存空間,并且增加內(nèi)存的讀寫次數(shù),從而降低內(nèi)存的使用效率。
此外,Shuffle作為Spark計算框架中決定整體性能的關(guān)鍵環(huán)節(jié)之一,其內(nèi)部包含了多次序列化與反序列化過程、跨節(jié)點網(wǎng)絡(luò)傳輸以及磁盤IO操作等復雜行為。這些操作不僅增加了系統(tǒng)開銷,而且可能導致數(shù)據(jù)局部性的喪失,進一步拖慢整個任務(wù)的執(zhí)行速度。因此,如何優(yōu)化Shuffle過程,減小其對系統(tǒng)資源的影響,是Spark性能調(diào)優(yōu)的重要方向。
因此,面對硬件條件的新格局,開發(fā)者不僅需要深入研究如何優(yōu)化Apache Spark內(nèi)部機制以適應(yīng)大規(guī)模并行計算需求,還應(yīng)探索將特定類型的數(shù)據(jù)運算任務(wù)轉(zhuǎn)移到諸如GPU、FPGA或其他專用加速器等更高效能的硬件上,從而在CPU資源有限的情況下,實現(xiàn)更高層次的大數(shù)據(jù)處理性能提升。
二、整體方案
我們采用軟硬件結(jié)合方式,無侵入式的集成Apache Spark,并在Spark數(shù)據(jù)計算全鏈路的3大方面都進行了全面提升和加速。
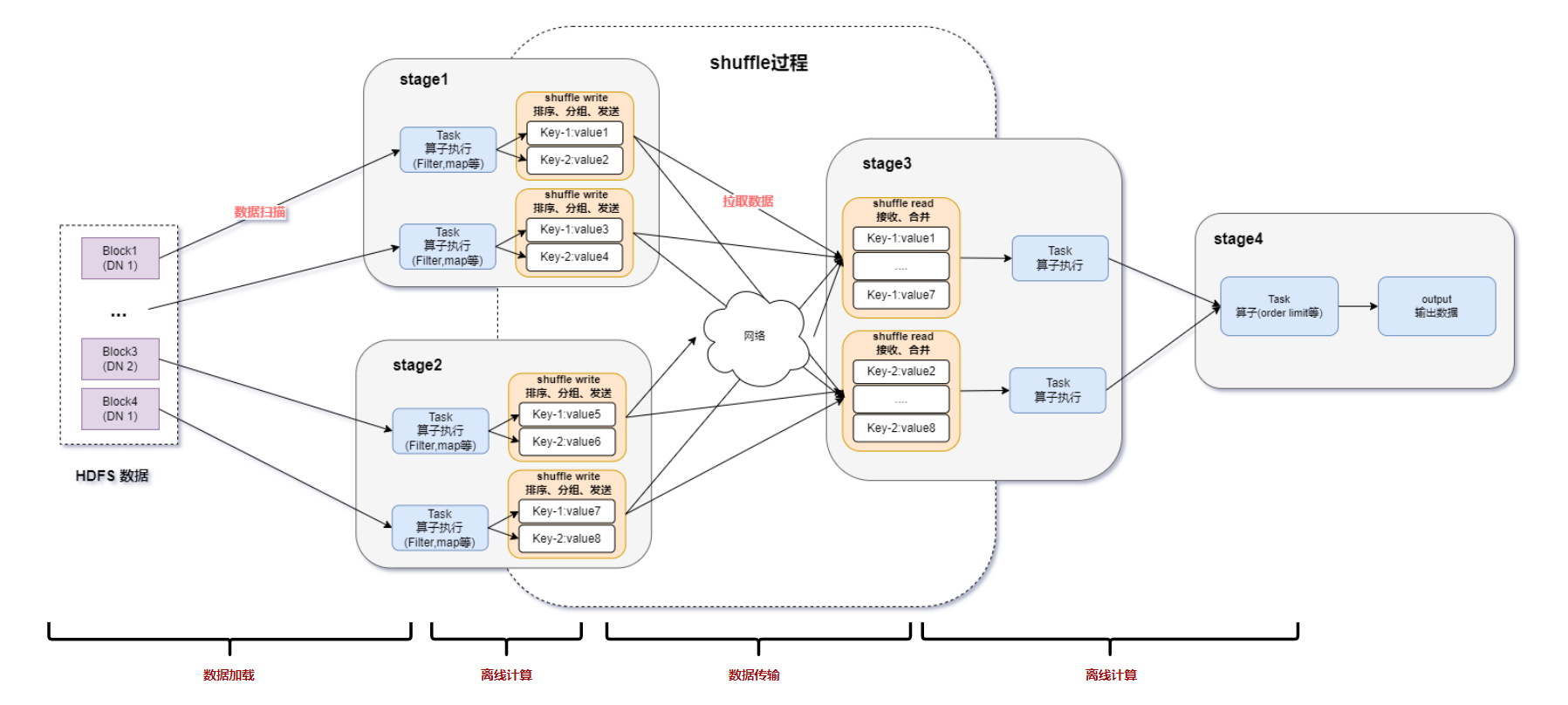
在「數(shù)據(jù)加載」方面,自研的DPU數(shù)據(jù)加載引擎直讀硬件存儲的數(shù)據(jù)到計算卡中,優(yōu)化掉大量的內(nèi)存與加速卡的PCIe數(shù)據(jù)傳輸性能損耗,同時在計算卡中進行數(shù)據(jù)的解壓縮計算。同理在最后的結(jié)果輸出階段,也在計算卡中進行數(shù)據(jù)壓縮。
在「離線計算」方面,自研的DPU計算引擎擁有強大的計算能力、容錯能力、并滿足 Spark 引擎日益復雜的離線處理場景和機器學習場景。
在「數(shù)據(jù)傳輸」方面,采用基于遠程直接內(nèi)存訪問(RDMA)技術(shù),以提高集群間的數(shù)據(jù)傳輸效率。
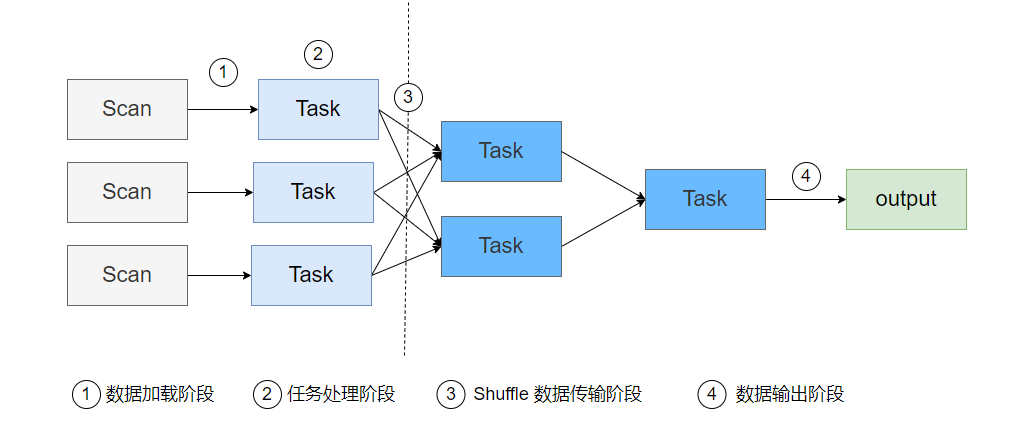
三、核心加速階段
加速階段如下圖所示,核心數(shù)據(jù)加速分為四個部分,分別為 1.數(shù)據(jù)讀取階段;2.任務(wù)處理階段;3.Shuffle數(shù)據(jù)傳輸階段;4.數(shù)據(jù)輸出階段。
3.1數(shù)據(jù)加載階段
3.1.1 面臨挑戰(zhàn)
在Apache Spark的數(shù)據(jù)處理流程中,數(shù)據(jù)加載階段是整個ELT(Extract, Load, Transform)作業(yè)的關(guān)鍵起始步驟。首先,當從傳統(tǒng)硬件架構(gòu)的數(shù)據(jù)源加載本地數(shù)據(jù)時,面臨如下挑戰(zhàn):
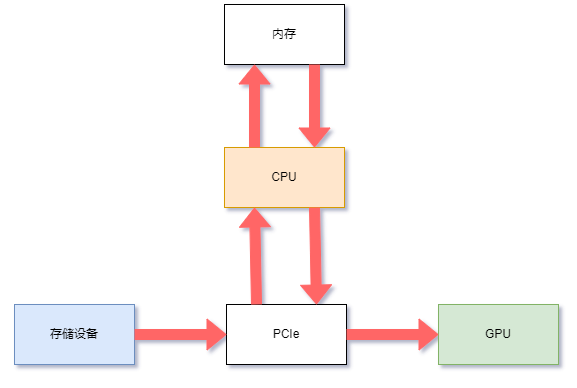
數(shù)據(jù)傳輸瓶頸:在傳統(tǒng)的硬件體系結(jié)構(gòu)中,數(shù)據(jù)加載過程涉及到多次通過CPU和PCIe總線的搬運操作。具體而言,每一份數(shù)據(jù)需要先從數(shù)據(jù)源經(jīng)過CPU解碼并通過PCIe通道傳輸至系統(tǒng)內(nèi)存,然后再次經(jīng)由CPU控制并經(jīng)過PCIe接口發(fā)送到特定硬件如GPU進行進一步處理。在此過程中,“反彈緩沖區(qū)”作為臨時存儲區(qū)域,在系統(tǒng)內(nèi)存中起到了橋接不同設(shè)備間數(shù)據(jù)傳輸?shù)淖饔茫@也會增加數(shù)據(jù)搬移的復雜性和潛在延遲。
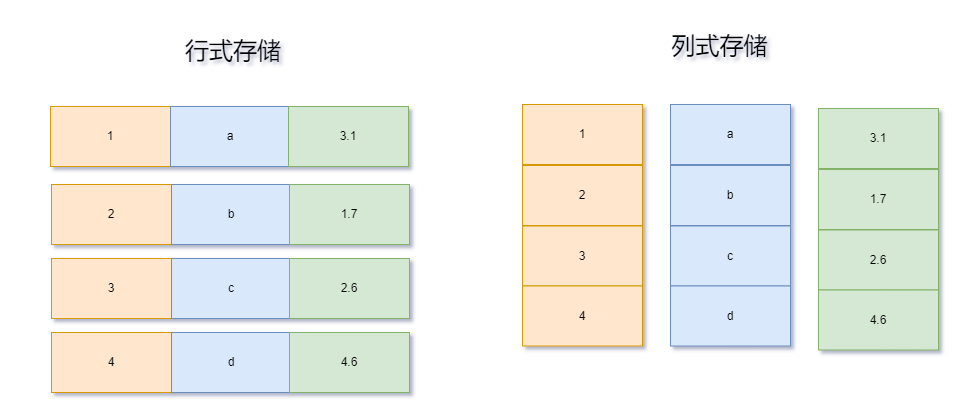
列式存儲的優(yōu)勢與挑戰(zhàn):在大數(shù)據(jù)環(huán)境中,列式存儲格式如Parquet和ORC等被廣泛采用,因其高效性而備受青睞。由于同一列中的數(shù)據(jù)類型相同,可以實現(xiàn)高效的壓縮率,并且內(nèi)存訪問模式相對線性,從而減少I/O開銷。然而,這也帶來了問題,即在讀取數(shù)據(jù)前必須進行解壓縮處理,這無疑增加了CPU額外的計算負擔,尤其是在需要對部分列進行運算的情況下。
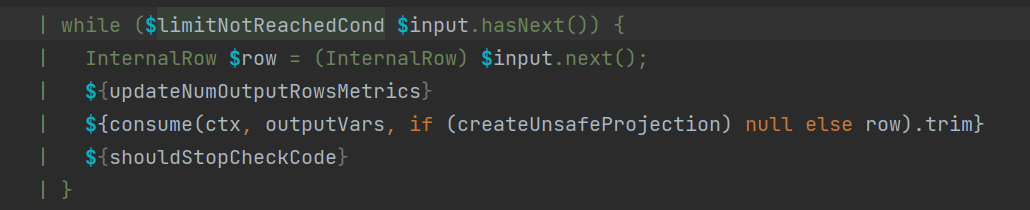
行式處理效率考量:在早期版本或某些特定場景下,Apache Spark在執(zhí)行物理計劃時傾向于行式處理數(shù)據(jù)。例如DataSourceScanExec算子負責底層數(shù)據(jù)源掃描,其默認按行讀取數(shù)據(jù),這種策略可能導致不必要的列數(shù)據(jù)冗余加載及頻繁調(diào)用“next”方法獲取下一行記錄。這一過程中,大量的虛函數(shù)調(diào)用可能引發(fā)CPU中斷,降低了處理效率,特別是在僅關(guān)注部分列時,會因為全行掃描而引入額外的性能損失。
在數(shù)據(jù)壓縮解壓縮過程中,壓縮解壓縮策略選擇階段是整個過程的開始。傳統(tǒng)的硬件體系結(jié)構(gòu)中,數(shù)據(jù)的壓縮和解壓縮過程通常只能依賴CPU完成,沒有其他策略可以選擇,從而無法利用GPU、DPU等其他處理器資源。這種局限性導致數(shù)據(jù)壓縮解壓縮過程會大量占用CPU資源,同時,與DPU相比,CPU的并行處理能力相對較弱,無法充分發(fā)揮硬件資源的潛力。在大規(guī)模數(shù)據(jù)處理的場景下,數(shù)據(jù)壓縮解壓縮過程可能成為CPU的瓶頸,導致系統(tǒng)性能下降。此外,由于數(shù)據(jù)壓縮解壓縮是一個計算密集型任務(wù),當系統(tǒng)中同時存在其他需要CPU資源的任務(wù)時,壓縮解壓縮過程可能會與其他任務(wù)產(chǎn)生競爭,進一步加劇了CPU資源的緊張程度,導致系統(tǒng)整體的響應(yīng)速度變慢。
3.1.2 解決方案與原理
在DPU(Data Processing Unit)架構(gòu)設(shè)計中,采用了一種直接內(nèi)存訪問(DMA)技術(shù),該技術(shù)構(gòu)建了從DPU內(nèi)存到存儲設(shè)備之間直接的數(shù)據(jù)傳輸路徑。相較于傳統(tǒng)的數(shù)據(jù)讀取方式,DMA機制有效地消除了CPU及其回彈緩沖區(qū)作為中間環(huán)節(jié)的必要性,從而顯著提升了系統(tǒng)的數(shù)據(jù)傳輸帶寬,并減少了由數(shù)據(jù)中轉(zhuǎn)造成的CPU延遲以及利用率壓力。
具體而言,在DPU系統(tǒng)內(nèi)部或與之緊密集成的存儲設(shè)備(例如NVMe SSD)上,內(nèi)置了支持DMA功能的引擎,允許數(shù)據(jù)塊以高效、直接的方式在存儲介質(zhì)與DPU內(nèi)存之間進行雙向傳遞。為了確保這一過程的精確執(zhí)行,系統(tǒng)精心設(shè)計了針對DMA操作的專用機制和緩存管理策略,其中包含了由存儲驅(qū)動程序發(fā)起的DMA回調(diào)函數(shù),用于驗證并轉(zhuǎn)換DPU內(nèi)存中的虛擬地址至物理地址,進而保證數(shù)據(jù)能夠準確無誤地從NVMe設(shè)備復制到DPU指定的內(nèi)存區(qū)域。
當應(yīng)用程序通過虛擬文件系統(tǒng)(VFS)向底層硬件提交DPU緩沖區(qū)地址作為DMA目標位置時,用戶空間庫將捕獲這些特定于DPU的緩沖區(qū)地址,并將其替換為原本提交給VFS的代理CPU緩沖區(qū)地址。在實際執(zhí)行DMA操作之前,運行于DPU環(huán)境的軟件會在適當?shù)臅r機調(diào)用相關(guān)接口,識別出原始的CPU緩沖區(qū)地址,并重新提供有效的DPU緩沖區(qū)地址,以便DMA操作能正確且高效地進行。由此,在不增加CPU處理負擔的前提下,實現(xiàn)了NVMe設(shè)備與DPU內(nèi)存間數(shù)據(jù)塊遷移的高度優(yōu)化流程。
3.1.3 優(yōu)勢與效果
吞吐提升:CPU的PCIe吞吐可能低于DPU的吞吐能力。這種差異是由于基于服務(wù)器的PCIe拓撲到CPU的PCIe路徑較少。如圖所示DPU支持直接數(shù)據(jù)路徑(綠色),而非通過CPU中的反彈緩沖區(qū)間接讀取的路徑(紅色)。這可以提高帶寬、降低延遲并減少CPU和DPU吞吐量負載。
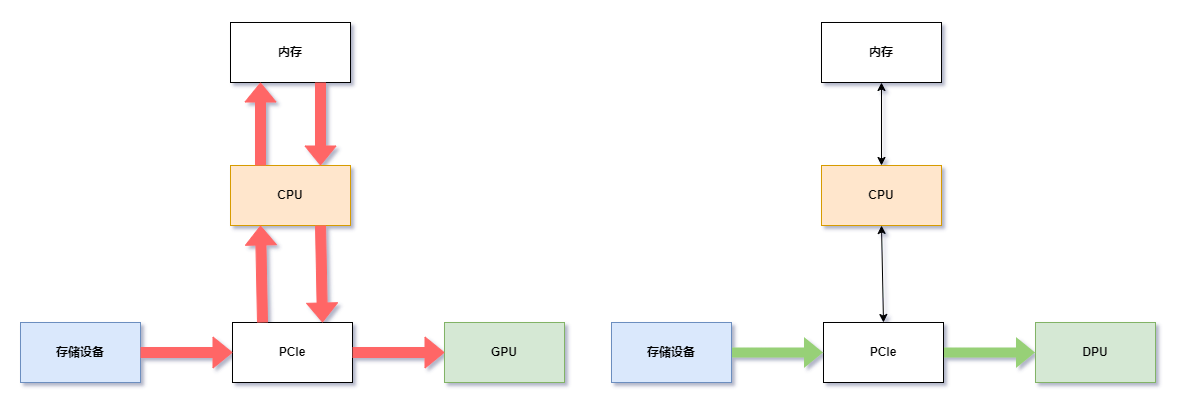
降低延遲:DPU直讀數(shù)據(jù)路徑只有一個副本,直接從源到目標。如果CPU執(zhí)行數(shù)據(jù)移動,則延遲可能會受到CPU可用性沖突的影響,這可能會導致抖動。DPU緩解了這些延遲問題。
提升CPU利用率:如果使用CPU移動數(shù)據(jù),則投入到數(shù)據(jù)搬運的CPU利用率會增加,并干擾CPU上的其余工作。使用DPU可減少CPU在數(shù)據(jù)搬用的工作負載,使應(yīng)用程序代碼能夠在更短的時間內(nèi)運行。
解壓縮:DPU讀取parquet文件的同時會將文件解壓,不用通過CPU進行編譯碼與解壓計算,直接進行謂詞下推減少讀取數(shù)據(jù)量從而提升數(shù)據(jù)讀取效率。
更適合列式處理數(shù)據(jù)結(jié)構(gòu):列式數(shù)據(jù)結(jié)構(gòu)在運算中有更好的性能,有利于Spark的Catalyst優(yōu)化器做出更加智能的決策,如過濾條件下推、列剪枝等,減少了不必要的計算和數(shù)據(jù)移動。在執(zhí)行階段會對列式數(shù)據(jù)進行向量化操作,將多條記錄打包成一個批次進行處理,提升運算效率。
3.2離線計算階段
3.2.1 面臨挑戰(zhàn)
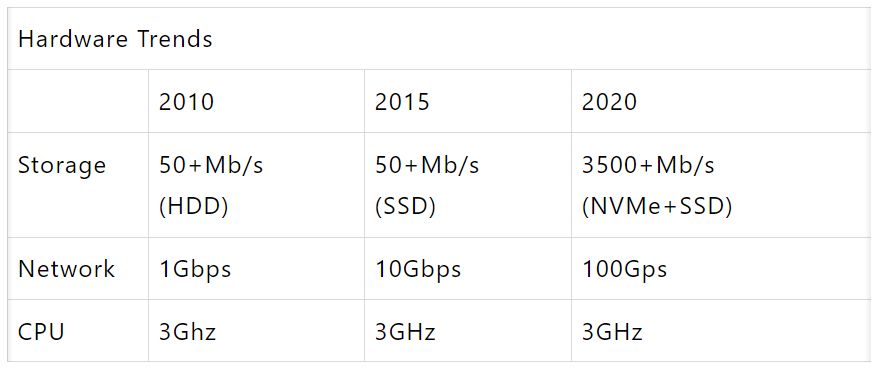
2015年基于Spark Summit調(diào)研顯示,2010年硬件的基本情況是存50+MB/s(HDD),網(wǎng)絡(luò)是1Gpbs,CPU是~3GHz;五年后,存儲和網(wǎng)絡(luò)都有了10倍以上的提升,但是CPU卻并沒有什么變化。

2020年,硬件的變化讓io性能有了進一步提升。SSD有了NVMe接口,同時有了超高速網(wǎng)絡(luò),但CPU仍然是3赫茲。那么當下我們的挑戰(zhàn)是在這樣的硬件條件下,如何最大化CPU性能,如何使用更高效的硬件替代CPU進行專業(yè)數(shù)據(jù)運算。
3.2.2 解決方案與原理
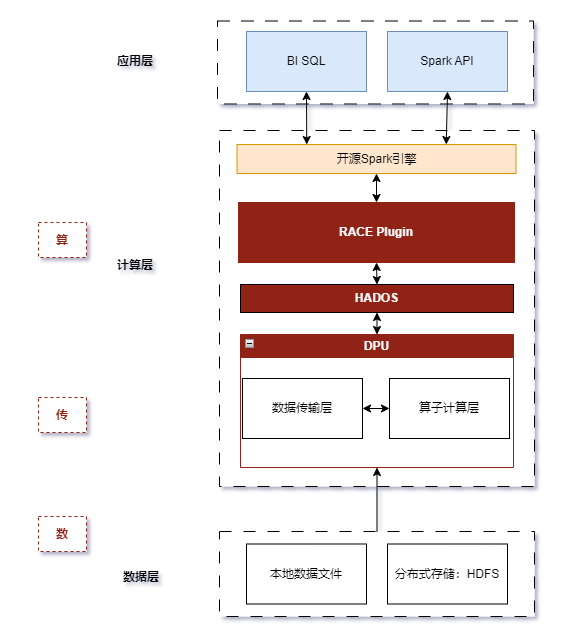
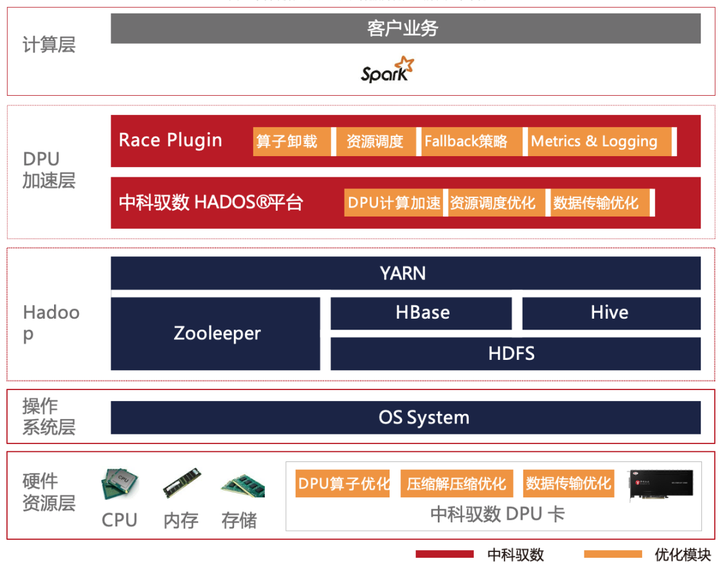
我們考慮如何將具有高性能計算能力的DPU用到 Spark 里來,從而提升 Spark 的計算性能,突破 CPU 瓶頸。接下來將介紹DPU計算引擎:
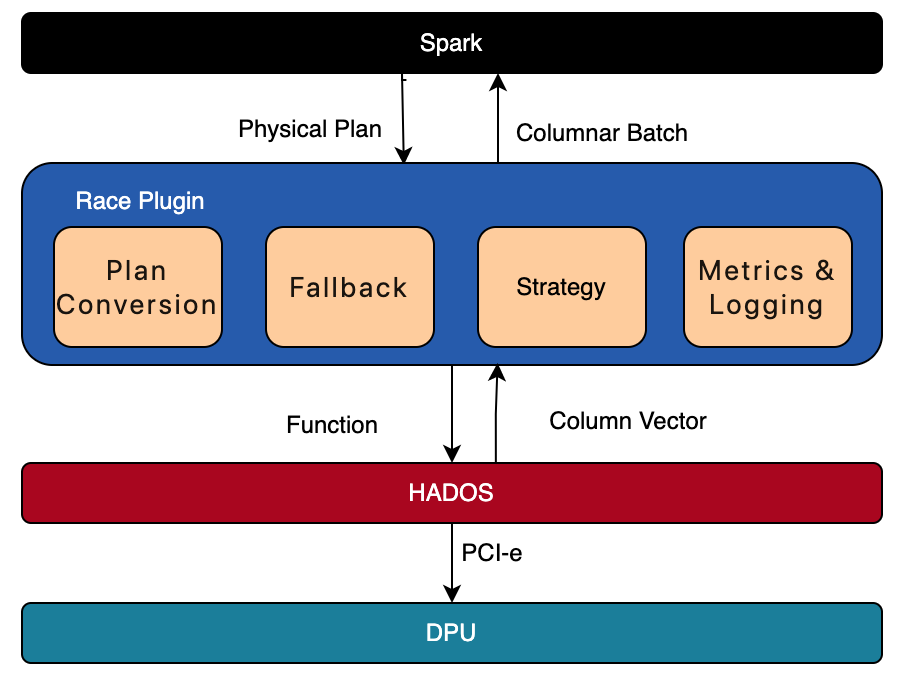
上圖是DPU的整體設(shè)計。目前支持的算子覆蓋Spark生產(chǎn)環(huán)境常用算子,包括Scan、Filter、Project、Union、Hash Aggregation、Sort、Join、Exchange等。表達式方面,我們開發(fā)了目前生產(chǎn)環(huán)境常用的布爾函數(shù)、Sum/Count/AVG/Max/Min等聚合函數(shù)。
在整個流轉(zhuǎn)過程中,RACE Plugin層起到承上啟下的關(guān)系:
1. 最核心的是Plan Conversion組件,在Spark優(yōu)化 Physical Plan時,會應(yīng)用一批規(guī)則,Race通過插入的自定義規(guī)則可以攔截到優(yōu)化后的Physical Plan,如果發(fā)現(xiàn)當前算子上的所有表達式可以下推給DPU,那么替換Spark原生算子為相應(yīng)的可以在DPU上執(zhí)行的自定義算子,由HADOS將其下推給DPU 來執(zhí)行并返回結(jié)果。
2. Fallback組件,Spark支持的Operator和Expression非常多,在Race研發(fā)初期,無法 100% 覆蓋 Spark 查詢執(zhí)行計劃中的算子和表達式,因此 Race必須有先前兼容回退執(zhí)行的能力。
3. Strategy組件, 因為fallback 這個 operator 前后插入行轉(zhuǎn)列、列轉(zhuǎn)行的算子。因為這兩次轉(zhuǎn)換對整個執(zhí)行的過程的性能損耗是很大的。針對這種情況,最穩(wěn)妥的方式就是整個子樹Query全部回退到CPU,而選擇哪些情況下執(zhí)行這個操作至關(guān)重要。
4. Metric組件,Race會收集DPU執(zhí)行過程中的指標統(tǒng)計,然后上報給Spark的Metrics System做展示、Debug、API調(diào)用。
3.2.3 優(yōu)勢與效果
通過Spark Plugin機制成功地將Spark計算任務(wù)卸載至DPU上執(zhí)行,充分利用了DPU強大的計算處理能力,有效解決了CPU在復雜數(shù)據(jù)處理中的性能瓶頸問題。經(jīng)過一系列詳盡的測試與驗證,在TPC-DS基準測試中99條SQL語句的執(zhí)行表現(xiàn)顯著提升:
顯著提高查詢性能:本方案在相同硬件條件下,使得單個查詢的執(zhí)行時間最多可縮短到原來的四分之一左右,即最高性能提升達到4.48倍;而在表達式操作層面,性能優(yōu)化效果更為突出,某些情況下甚至能提升至原始速度的8.47倍。
算子級加速明顯:在對關(guān)鍵算子如Filter和哈希聚合操作進行評估時,相較于原生Spark解決方案,F(xiàn)ilter算子的執(zhí)行效率提升了高達43倍,而哈希聚合算子性能也提升了13倍。這得益于我們減少了列式數(shù)據(jù)轉(zhuǎn)換為行式數(shù)據(jù)的額外開銷,以及DPU硬件層面對運算密集型任務(wù)的強大加速作用。
大幅度降低CPU資源占用:通過DPU加速卸載后,系統(tǒng)資源利用率得到顯著改善。在TPC-DS測試場景下,CPU平均使用率從60%大幅下降至5%,釋放出更多CPU資源用于其他業(yè)務(wù)邏輯處理,增強了系統(tǒng)的整體并發(fā)能力和響應(yīng)速度。
3.3數(shù)據(jù)傳輸階段
3.3.1 面臨挑戰(zhàn)
在Apache Spark的數(shù)據(jù)處理框架中,Shuffle階段扮演著至關(guān)重要的角色,然而,該過程因其涉及大規(guī)模數(shù)據(jù)在網(wǎng)絡(luò)中的傳輸而顯著增加了執(zhí)行時間,容易成為制約Spark作業(yè)性能的關(guān)鍵瓶頸環(huán)節(jié)。傳統(tǒng)的網(wǎng)絡(luò)通信機制在 Shuffle 過程中的表現(xiàn)不盡如人意。具體表現(xiàn)為:
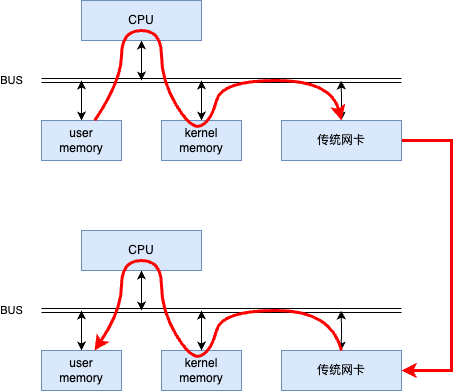
· 數(shù)據(jù)的發(fā)送和接收過程中,操作系統(tǒng)內(nèi)核參與了必要的管理與調(diào)度工作,這一介入導致了額外的延遲開銷。每個數(shù)據(jù)單元在經(jīng)過操作系統(tǒng)的網(wǎng)絡(luò)協(xié)議棧進行傳遞時,需歷經(jīng)多次上下文切換以及數(shù)據(jù)復制操作,這些都無形中加重了系統(tǒng)負擔。
· 另一方面,在基于傳統(tǒng)TCP/IP等網(wǎng)絡(luò)協(xié)議的通信模式下,CPU需要承擔大量的協(xié)議解析、包構(gòu)建及錯誤處理等任務(wù),這不僅大量消耗了寶貴的計算資源,而且對通信延遲產(chǎn)生了不利影響,進一步降低了整體的數(shù)據(jù)處理效率。
3.3.2 解決方案與原理
將RDMA技術(shù)應(yīng)用于Apache Spark,尤其是在Shuffle過程中,可以大幅度減輕網(wǎng)絡(luò)瓶頸帶來的影響。通過利用RDMA的高帶寬和低延遲特性,Spark的數(shù)據(jù)處理性能有望得到顯著的提升。
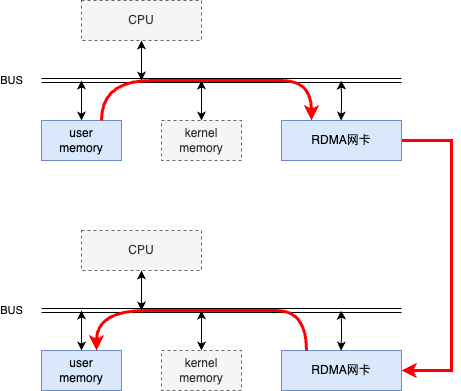
RDMA技術(shù)允許網(wǎng)絡(luò)設(shè)備直接訪問應(yīng)用程序內(nèi)存空間,實現(xiàn)了內(nèi)核旁路(kernel bypass)。這意味著數(shù)據(jù)可以直接從發(fā)送方的內(nèi)存?zhèn)鬏數(shù)浇邮辗降膬?nèi)存,無需CPU介入,減少了傳輸過程中的延遲。如下圖所示。
3.2.3 優(yōu)勢與效果
在該方案中,Netty客戶端被RDMA客戶端所取代,并充分利用了RDMA單邊操作的特性。具體實現(xiàn)時,磁盤數(shù)據(jù)通過內(nèi)存映射(MMAP)技術(shù)加載至用戶空間內(nèi)存,此后,客戶端利用RDMA能力在網(wǎng)絡(luò)層面執(zhí)行直接內(nèi)存訪問操作。這一改進避免了數(shù)據(jù)在操作系統(tǒng)內(nèi)核內(nèi)存和網(wǎng)絡(luò)接口間多次復制,從而提高了數(shù)據(jù)傳輸速度、降低了延遲并減輕了CPU負載。
數(shù)據(jù)傳輸效率提升:得益于RDMA的低延遲與高帶寬優(yōu)勢,Spark中的數(shù)據(jù)處理速率顯著提高。這是因為RDMA能夠?qū)崿F(xiàn)在網(wǎng)絡(luò)設(shè)備與應(yīng)用內(nèi)存之間的直接數(shù)據(jù)傳輸,減少了對CPU的依賴,進而降低了數(shù)據(jù)傳輸過程中的延時。
CPU占用率降低:RDMA的Kernel Bypass特性使得數(shù)據(jù)可以直接從內(nèi)存繞過內(nèi)核進行傳輸,這不僅大大減少了CPU在數(shù)據(jù)傳輸階段的工作負擔,而且提升了CPU資源的有效利用率,釋放出更多計算資源用于Spark的核心計算任務(wù)。
端到端處理時間縮短:對比傳統(tǒng)TCP傳輸方式,在多項性能測試中,采用RDMA的方案明顯縮短了端到端的數(shù)據(jù)處理時間,這意味著整體數(shù)據(jù)處理流程更加高效,能夠在更短的時間內(nèi)完成相同規(guī)模的計算任務(wù)。
Shuffle階段性能優(yōu)化:在Apache Spark框架中,Shuffle階段是一個關(guān)鍵且對性能影響較大的環(huán)節(jié)。借助RDMA減少數(shù)據(jù)傳輸和處理所需時間的優(yōu)勢,有效地優(yōu)化了Shuffle階段的性能表現(xiàn),從而全面提升整個數(shù)據(jù)處理流程的效率。
大規(guī)模數(shù)據(jù)處理能力增強:對于處理大規(guī)模數(shù)據(jù)集的場景,RDMA所提供的高效數(shù)據(jù)傳輸及低延遲特性尤為重要。它確保Spark能在更高效地處理大量數(shù)據(jù)的同時,提高了大規(guī)模數(shù)據(jù)處理任務(wù)的可擴展性和處理效率。
值得注意的是,在多種實際應(yīng)用場景下,使用RDMA通常能夠帶來大約10%左右的性能提升效果。然而,具體的加速效果會受到業(yè)務(wù)邏輯復雜性、數(shù)據(jù)處理工作負載特性的綜合影響,因此可能有所波動。
四、加速效果
4.1端到端整體加速效果
在嚴格的單機單線程本地(local)模式測試環(huán)境下,未使用RDMA技術(shù),針對1TB規(guī)模的數(shù)據(jù)集,通過對比分析TPC-DS基準測試SQL語句執(zhí)行時間,其中有5條語句的E2E(由driver端提交任務(wù)到driver接收輸出結(jié)果的時間)執(zhí)行時間得到了顯著提升,提升比例均超過2倍,最高可達到4.56倍提升。
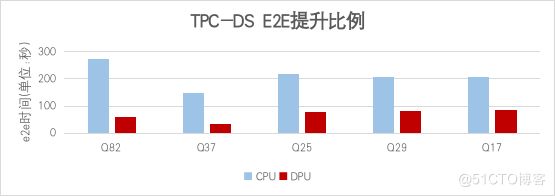
4.2運算符加速效果
進一步聚焦于運算符層面的性能改進,在對DPU加速方案與Spark原生運算符進行比較時,觀察到運算符執(zhí)行效率的最大提升比率達到9.97倍。這一顯著的加速效果主要源于DPU硬件層面的優(yōu)化設(shè)計和高效運算能力。
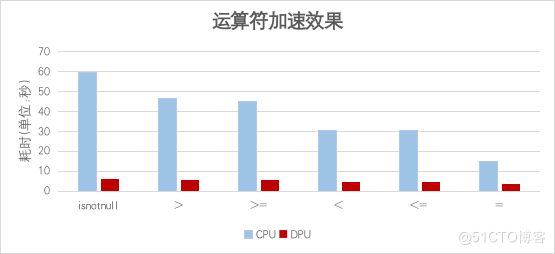
4.3算子加速效果
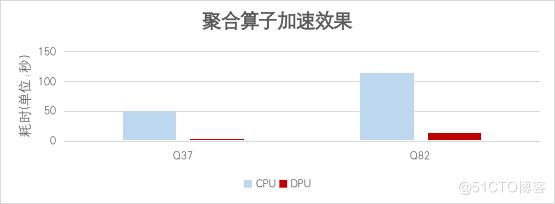
在遵循TPC-DS基準測試標準的前提下,相較于未經(jīng)優(yōu)化的原生Spark解決方案,本方案在關(guān)鍵算子性能方面實現(xiàn)了顯著提升。根據(jù)測試數(shù)據(jù)表明,F(xiàn)ilter算子的執(zhí)行效率提升了43倍,而哈希聚合算子的處理速率也提高了13倍之多。這一顯著性能飛躍的取得,主要歸因于方案深入挖掘并有效利用了DPU所具備的強大計算能力和并行處理特性,從而大幅縮短了相關(guān)算子的執(zhí)行時間,并提升了整個系統(tǒng)的運算效能。通過這種優(yōu)化措施,不僅確保了在復雜查詢和大數(shù)據(jù)處理任務(wù)中更高的響應(yīng)速度,同時也驗證了結(jié)合現(xiàn)代硬件技術(shù)對Spark性能進行深度優(yōu)化的有效性和可行性。

4.4 RDMA加速效果
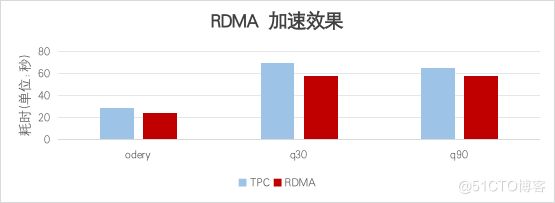
在實際應(yīng)用環(huán)境中,RDMA(Remote Direct Memory Access)技術(shù)展現(xiàn)出顯著的性能提升效果。通過直接訪問遠程內(nèi)存而無需CPU過多介入,RDMA能夠極大地減少數(shù)據(jù)傳輸過程中的延遲和CPU占用率,在多個不同場景中實現(xiàn)至少10%以上的性能增長。這一優(yōu)勢體現(xiàn)在網(wǎng)絡(luò)密集型操作中尤為明顯,如大規(guī)模分布式系統(tǒng)間的通信與數(shù)據(jù)交換。
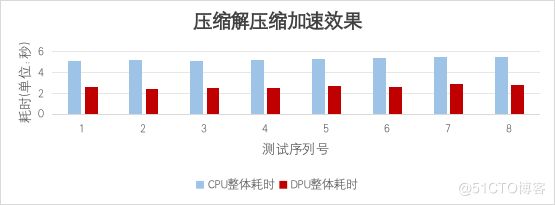
4.5 壓縮解壓縮加速效果
基于目前HADOS-RACE已經(jīng)實現(xiàn)的Snappy壓縮解壓縮方案,制定了對應(yīng)的性能測試計劃。首先生成snappy測試數(shù)據(jù),使用基于CPU和DPU的Spark分別對數(shù)據(jù)進行處理,記錄各自的Snappy壓縮解壓縮階段和Spark整體端到端的耗時和吞吐。執(zhí)行的測試語句為:select * from table where a1 is not null and a2 is not null(盡量減少中間的計算過程,突出Snappy壓縮解壓縮的過程)。
單獨分析Snappy壓縮解壓縮階段,基于CPU的Snappy解壓縮,吞吐量為300MB/s。而將解壓縮任務(wù)卸載到DPU后,DPU核內(nèi)計算的吞吐量可達到1585MB/s。可以看到,基于DPU進行Snappy解壓縮,相比基于CPU進行Snappy解壓縮,性能可提升約5倍。
基于CPU的Spark計算過程總體比基于DPU的Spark計算過程耗時減少了約50%。相當于基于DPU的端到端執(zhí)行性能是基于CPU端到端性能的兩倍。詳細測試結(jié)果如下所示:
五、未來規(guī)劃
5.1 現(xiàn)有優(yōu)勢
性能方面,得益于DPU做算力卸載的高效性,相對于社區(qū)版本Spark具備較為明顯的優(yōu)勢,尤其是單機場景下,該場景下由于更偏重于純算力,優(yōu)勢更加明顯。
資源方面,得益于更優(yōu)秀的數(shù)據(jù)結(jié)構(gòu)設(shè)計,在內(nèi)存、IO和網(wǎng)絡(luò)資源使用上,都具備不同程度的優(yōu)勢,特別是內(nèi)存資源上,較社區(qū)版本Spark優(yōu)勢明顯。
5.2 現(xiàn)有不足
· 集群場景下性能提升較單機場景減弱,網(wǎng)絡(luò)傳輸?shù)男阅軗p耗削弱了整體性能提升能力。
· 功能覆蓋上,目前主要圍繞TPC-DS場景以及一些客戶提出的業(yè)務(wù)場景,未來還需要覆蓋更多的業(yè)務(wù)場景。
5.3 未來規(guī)劃
· 優(yōu)化和完善現(xiàn)有架構(gòu),繼續(xù)完善基礎(chǔ)功能覆蓋。
· 未來計劃在加速純計算場景的同時,也同步引入更多維度的加速方案(如存儲加速、網(wǎng)絡(luò)加速),提升集群模式下的加速性能。
-
cpu
+關(guān)注
關(guān)注
68文章
10854瀏覽量
211578 -
網(wǎng)絡(luò)接口
+關(guān)注
關(guān)注
0文章
85瀏覽量
17207 -
DPU
+關(guān)注
關(guān)注
0文章
357瀏覽量
24169 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8882瀏覽量
137396 -
SPARK
+關(guān)注
關(guān)注
1文章
105瀏覽量
19891
發(fā)布評論請先 登錄
相關(guān)推薦
基于DPU和HADOS-RACE加速Spark 3.x
《數(shù)據(jù)處理器:DPU編程入門》DPU計算入門書籍測評
大數(shù)據(jù)開發(fā)之spark應(yīng)用場景
專?數(shù)據(jù)處理器 (DPU) 技術(shù)??書
【書籍評測活動NO.23】數(shù)據(jù)處理器:DPU編程入門
什么是DPU?
《數(shù)據(jù)處理器:DPU編程入門》+初步熟悉這本書的結(jié)構(gòu)和主要內(nèi)容
工業(yè)大數(shù)據(jù)處理領(lǐng)域的“網(wǎng)紅”——Apache Spark
工業(yè)大數(shù)據(jù)挖掘的利器——Spark MLlib





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論