") 基于雙級優(yōu)化(BLO)的消除過擬合的微調(diào)方法
基于雙級優(yōu)化(BLO)的消除過擬合的微調(diào)方法
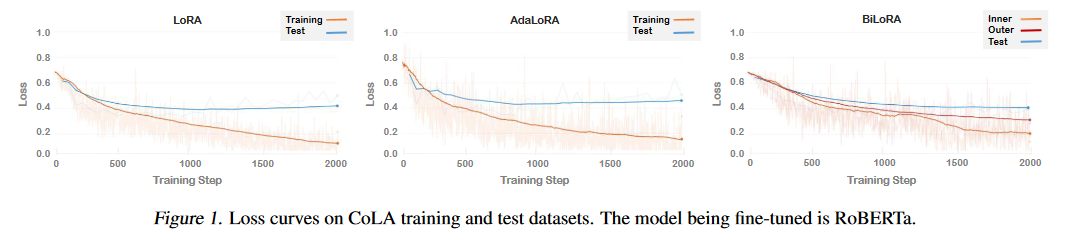
摘要:低秩適應(yīng)(LoRA)是在下游任務(wù)中通過學(xué)習(xí)低秩增量矩陣對大規(guī)模預(yù)訓(xùn)練模型進行微調(diào)的一種流行方法。雖然與完全微調(diào)方法相比,LoRA 及其變體能有效減少可訓(xùn)練參數(shù)的數(shù)量,但它們經(jīng)常會對訓(xùn)練數(shù)據(jù)進行過擬合,導(dǎo)致測試數(shù)據(jù)的泛化效果不理想。為了解決這個問題,我們引入了 BiLoRA,這是一種基于雙級優(yōu)化(BLO)的消除過擬合的微調(diào)方法。BiLoRA 采用偽奇異值分解來參數(shù)化低秩增量矩陣,并將偽奇異向量和偽奇異值的訓(xùn)練分成兩個不同的訓(xùn)練數(shù)據(jù)子集。這種分割嵌入了 BLO 框架的不同層次,降低了對單一數(shù)據(jù)集過度擬合的風(fēng)險。BiLoRA 在涵蓋自然語言理解和生成任務(wù)的十個數(shù)據(jù)集上進行了測試,并應(yīng)用于各種著名的大型預(yù)訓(xùn)練模型,在可訓(xùn)練參數(shù)數(shù)量相似的情況下,BiLoRA 明顯優(yōu)于 LoRA 方法和其他微調(diào)方法。

https://arxiv.org/abs/2403.13037
Q1: 這篇論文試圖解決什么問題?
A:這篇論文試圖解決的問題是大型預(yù)訓(xùn)練模型在下游任務(wù)中進行微調(diào)時出現(xiàn)的過擬合問題。盡管低秩適應(yīng)(LoRA)及其變體通過學(xué)習(xí)低秩增量矩陣有效地減少了與完全微調(diào)方法相比的可訓(xùn)練參數(shù)數(shù)量,但這些方法往往容易過擬合訓(xùn)練數(shù)據(jù),導(dǎo)致在測試數(shù)據(jù)上泛化性能不佳。為了解決這個問題,論文引入了基于雙層優(yōu)化(BLO)的BiLoRA方法,通過在不同的訓(xùn)練數(shù)據(jù)子集上分別訓(xùn)練偽奇異向量和奇異值來減輕過擬合的風(fēng)險。
Q2: 有哪些相關(guān)研究?
A:這篇論文提到了幾項與BiLoRA相關(guān)的研究領(lǐng)域,具體包括:
低秩適應(yīng)(Low-Rank Adaptation, LoRA):
Li et al. (2018) 和 Aghajanyan et al. (2020) 展示了預(yù)訓(xùn)練模型具有很低的內(nèi)在維度,并且可以通過使用低秩參數(shù)化來實現(xiàn)與全參數(shù)微調(diào)相當?shù)男阅堋?/p>
Hu et al. (2021) 提出了LoRA,通過將低秩更新矩陣引入到預(yù)訓(xùn)練的權(quán)重矩陣中來實現(xiàn)。
其他方法如DyLoRA (Valipour et al., 2022),QLoRA (Dettmers et al., 2023),和LoraHub (Huang et al., 2023) 旨在提高LoRA的效率和性能。
雙層優(yōu)化(Bi-level Optimization, BLO):
BLO在元學(xué)習(xí)(Finn et al., 2017; Rajeswaran et al., 2019),超參數(shù)優(yōu)化(Franceschi et al., 2017; Lorraine et al., 2020),神經(jīng)架構(gòu)搜索(Liu et al., 2018; Zhang et al., 2021),強化學(xué)習(xí)(Rajeswaran et al., 2020)等領(lǐng)域得到了廣泛應(yīng)用。
提出了多種算法來解決這種特定形式的優(yōu)化問題,包括零階方法如貝葉斯優(yōu)化(Cui & Bai, 2019),一階算法基于超梯度(Pearlmutter & Siskind, 2008; Lorraine et al., 2020)等。
其他微調(diào)方法:
Full Fine-Tuning (FT) 是一種常用的適應(yīng)方法,涉及對所有模型參數(shù)進行梯度更新。
Bias-only 或 BitFit (Zaken et al., 2021) 只訓(xùn)練偏置向量,而保持預(yù)訓(xùn)練模型中的其他參數(shù)不變。
Prefix-embedding tuning 和 Prefix-layer tuning 是在輸入嵌入或Transformer層之間插入可訓(xùn)練的特定參數(shù)。
Adapter tuning (Houlsby et al., 2019) 通過在神經(jīng)模塊之間插入適配器來適應(yīng)模型。
這些相關(guān)研究為BiLoRA的開發(fā)提供了理論基礎(chǔ)和技術(shù)背景。BiLoRA通過結(jié)合LoRA的低秩更新和BLO的雙層優(yōu)化策略,旨在提高大型預(yù)訓(xùn)練模型在特定下游任務(wù)中的泛化能力和微調(diào)效率。
Q3: 論文如何解決這個問題?
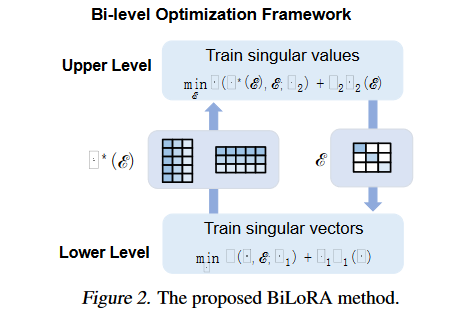
A:為了解決大型預(yù)訓(xùn)練模型在下游任務(wù)微調(diào)時的過擬合問題,論文提出了BiLoRA(Bi-level Optimization Framework for Overfitting-Resilient Low-Rank Adaptation)方法,具體解決方案如下:
雙層優(yōu)化(Bi-level Optimization, BLO):
BiLoRA采用雙層優(yōu)化框架,將參數(shù)學(xué)習(xí)分為兩個層次。在較低層次,優(yōu)化偽奇異向量(P和Q),在較高層次,優(yōu)化偽奇異值(Λ)。
參數(shù)化低秩增量矩陣:
類似于奇異值分解(SVD),每個低秩增量矩陣?W被參數(shù)化為?W = PΛQ,其中P和Q是偽左/右奇異向量矩陣,Λ是偽奇異值對角矩陣。
通過正則化項(R1)鼓勵P和Q的近似正交性。
分離訓(xùn)練過程:
在較低層次,固定Λ,僅在訓(xùn)練數(shù)據(jù)集D1的一個子集上訓(xùn)練P和Q。
在較高層次,使用從較低層次得到的最優(yōu)P和Q(記為V*(Λ)),在剩余的數(shù)據(jù)集D2上訓(xùn)練Λ。
迭代優(yōu)化:
通過迭代方式交替解決兩個層次的優(yōu)化問題,直到收斂。
正則化偽奇異值:
提供了三種偽奇異值的參數(shù)化形式:實值(Real-Value)、Softmax和近似二值(Approximately Binary),以控制不同奇異向量對最終模型的貢獻。
高效的訓(xùn)練框架:
利用基于梯度的優(yōu)化算法,特別是針對高維問題和大量可訓(xùn)練參數(shù)的情況。

通過這種方法,BiLoRA能夠在不同的數(shù)據(jù)子集上分別學(xué)習(xí)模型的架構(gòu)(Λ)和候選操作(P和Q),從而有效地減少了對單一數(shù)據(jù)集的過擬合風(fēng)險,并提高了模型在測試數(shù)據(jù)上的泛化性能。論文通過在多個自然語言理解和生成任務(wù)的數(shù)據(jù)集上進行實驗,證明了BiLoRA與其他微調(diào)方法相比,在保持相似數(shù)量的可訓(xùn)練參數(shù)的同時,能夠取得更好的性能。
Q4: 論文做了哪些實驗?
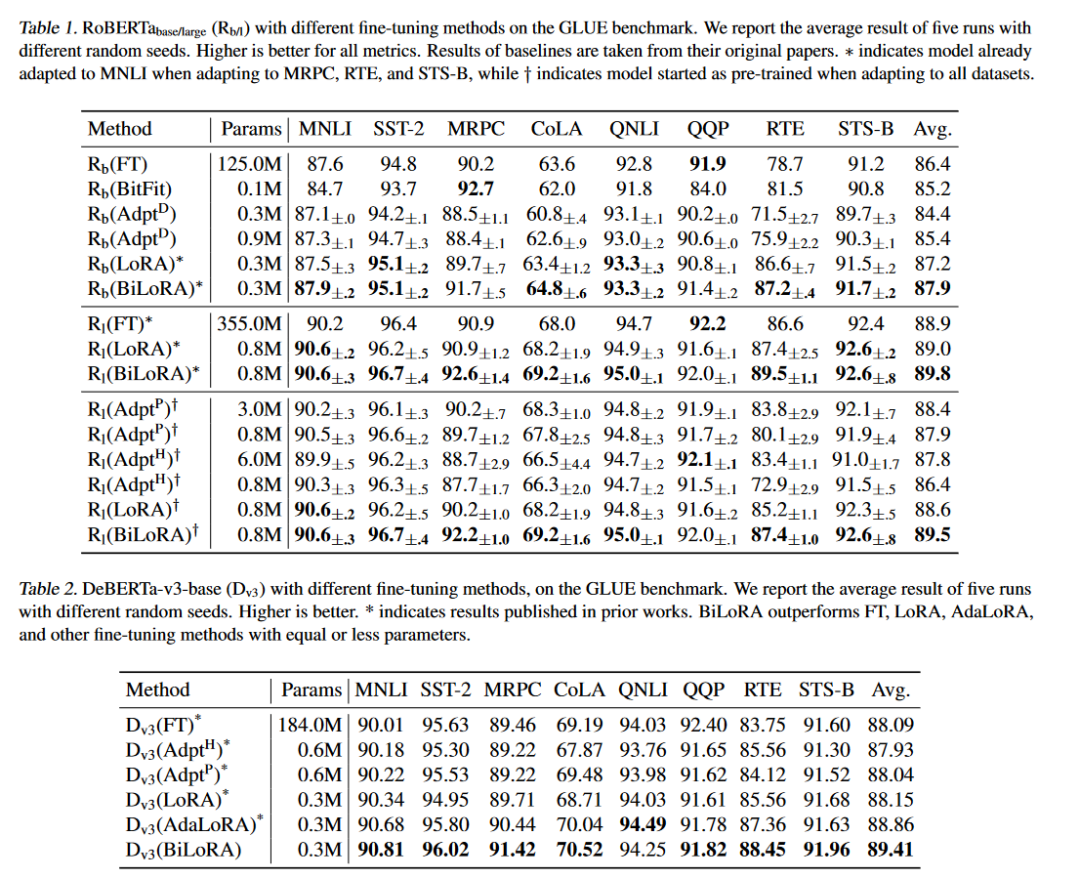
A:論文中進行了一系列的實驗來驗證BiLoRA方法的有效性和性能,具體包括:
自然語言理解(NLU)任務(wù):
在GLUE基準測試上評估了RoBERTa和DeBERTa模型。GLUE包含多種NLU任務(wù),包括情感分析、語義相似性評估、自然語言推理等。
使用開發(fā)集作為測試數(shù)據(jù),因為GLUE的測試集不公開。
將訓(xùn)練集分為兩個子集,分別作為雙層優(yōu)化中的下層(D1)和上層(D2)數(shù)據(jù)集。
自然語言生成(NLG)任務(wù):
在E2E NLG挑戰(zhàn)賽上評估了GPT-2中大型模型。這個數(shù)據(jù)集用于評估端到端、數(shù)據(jù)驅(qū)動的自然語言生成系統(tǒng)。
遵循Prefix-Tuning和LoRA的設(shè)置,并與LoRA和其他微調(diào)方法進行直接比較。
不同參數(shù)化形式的實驗:
對偽奇異值的三種參數(shù)化形式(Real Value、Softmax和Approximately Binary)進行了實驗,以評估它們對模型性能的影響。
超參數(shù)γ1的影響分析:
分析了正交性促進正則化項中超參數(shù)γ1的不同取值對RoBERTa-base性能的影響。
計算成本比較:
比較了LoRA和BiLoRA在訓(xùn)練時間上的差異,以評估BiLoRA在減少總訓(xùn)練時間方面的效率。
與其他過擬合緩解方法的比較:
對比了增加權(quán)重衰減和采用更激進的秩修剪設(shè)置這兩種常見的過擬合緩解方法在AdaLoRA上的效果。
擴展到大型模型的性能評估:
使用DeBERTa-v2xxlarge(1.5億參數(shù))模型評估了BiLoRA在非常大型模型上的擴展性能。
這些實驗覆蓋了從模型微調(diào)、正則化策略分析、不同參數(shù)化形式的比較,到計算效率和大規(guī)模模型適應(yīng)性的全面評估,充分證明了BiLoRA方法在減少過擬合、提高泛化能力和計算效率方面的優(yōu)勢。
Q5: 有什么可以進一步探索的點?
A:論文中提到了幾個可以進一步探索的研究方向和潛在的改進點:
偽奇異值的參數(shù)化形式:
論文中提出了三種偽奇異值的參數(shù)化形式:實值、Softmax和近似二值。未來的研究可以探索更多種類的參數(shù)化方法,特別是支持自動秩選擇的參數(shù)化形式。
理論分析:
BiLoRA的雙層優(yōu)化框架提高了微調(diào)模型的泛化能力。未來的工作可以對這種優(yōu)化策略的理論和實際效果進行更深入的分析,以更好地理解其工作原理。
超參數(shù)調(diào)整:
盡管BiLoRA的超參數(shù)調(diào)整相對簡單,但進一步的研究可以探索自動化超參數(shù)優(yōu)化技術(shù),例如貝葉斯優(yōu)化或進化算法,以提高BiLoRA的性能和效率。
不同模型架構(gòu)的適應(yīng)性:
論文中的實驗主要針對RoBERTa、DeBERTa和GPT-2模型。BiLoRA方法在其他類型的模型架構(gòu)上的效果和適用性值得進一步研究。
更廣泛的任務(wù)和數(shù)據(jù)集:
盡管BiLoRA在多個NLU和NLG任務(wù)上表現(xiàn)出色,但在更多種類的任務(wù)和更大規(guī)模的數(shù)據(jù)集上的性能尚未得到驗證。未來的研究可以在這些方面進行擴展。
計算效率:
盡管BiLoRA已經(jīng)顯示出比LoRA更少的訓(xùn)練時間,但仍有進一步提高計算效率的空間,例如通過優(yōu)化迭代優(yōu)化步驟或并行化技術(shù)。
模型解釋性:
BiLoRA通過分開訓(xùn)練偽奇異向量和值來減少過擬合。研究這種訓(xùn)練策略如何影響模型的可解釋性和決策過程可能是一個有趣的方向。
長期影響和適應(yīng)性:
研究BiLoRA在長期部署和適應(yīng)新任務(wù)或數(shù)據(jù)時的表現(xiàn),以及如何整合新知識以最小化性能下降。
這些潛在的研究方向可以進一步推動BiLoRA方法的發(fā)展,并擴展其在自然語言處理和其他機器學(xué)習(xí)領(lǐng)域的應(yīng)用。
Q6: 總結(jié)一下論文的主要內(nèi)容?
A:這篇論文的主要內(nèi)容可以總結(jié)如下:
標題: BiLoRA: A Bi-level Optimization Framework for Overfitting-Resilient Low-Rank Adaptation of Large Pre-trained Models
問題陳述: 大型預(yù)訓(xùn)練模型在下游任務(wù)中的微調(diào)經(jīng)常面臨過擬合問題,導(dǎo)致模型在訓(xùn)練數(shù)據(jù)上表現(xiàn)良好,但在測試數(shù)據(jù)上泛化能力不足。
方法: 為了解決這個問題,論文提出了BiLoRA,一個基于雙層優(yōu)化(BLO)的微調(diào)方法。BiLoRA通過偽奇異值分解(pseudo SVD)的形式參數(shù)化低秩增量矩陣,并在兩個不同的訓(xùn)練數(shù)據(jù)子集上分別訓(xùn)練偽奇異向量和偽奇異值。
關(guān)鍵創(chuàng)新:
引入雙層優(yōu)化框架,將參數(shù)學(xué)習(xí)分為兩個層次,分別優(yōu)化偽奇異向量和偽奇異值。
在不同的數(shù)據(jù)子集上訓(xùn)練參數(shù),減少了對單一數(shù)據(jù)集的過擬合風(fēng)險。
提出了三種偽奇異值的參數(shù)化形式:實值、Softmax和近似二值。
實驗:
在GLUE基準測試上對RoBERTa和DeBERTa模型進行了評估。
在E2E NLG挑戰(zhàn)賽上對GPT-2模型進行了評估。
對比了BiLoRA與LoRA、AdaLoRA和其他微調(diào)方法的性能。
分析了不同參數(shù)化形式和超參數(shù)設(shè)置對模型性能的影響。
結(jié)果: BiLoRA在多個自然語言理解和生成任務(wù)上顯著優(yōu)于LoRA方法和其他微調(diào)方法,同時保持了相似數(shù)量的可訓(xùn)練參數(shù)。
結(jié)論: BiLoRA是一個有效的微調(diào)方法,可以減少大型預(yù)訓(xùn)練模型的過擬合問題,并提高模型在測試數(shù)據(jù)上的泛化性能。論文還提出了未來研究的潛在方向,包括改進參數(shù)化形式、理論分析和計算效率等。
這篇論文為大型預(yù)訓(xùn)練模型的微調(diào)提供了一個新的視角,并通過實驗驗證了其有效性。BiLoRA方法的提出,為NLP社區(qū)提供了一個有價值的工具,以提高模型在各種下游任務(wù)中的性能。
審核編輯:黃飛
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24689 -
LoRa
+關(guān)注
關(guān)注
349文章
1689瀏覽量
231910 -
自然語言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13346 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2641
原文標題:每日論文速遞 | BiLoRA: 基于雙極優(yōu)化消除LoRA過擬合
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
深層神經(jīng)網(wǎng)絡(luò)模型的訓(xùn)練:過擬合優(yōu)化
基于SLM的樣條擬合優(yōu)化工具箱
封裝級微調(diào)與其它失調(diào)校正法的比較
曲線擬合的判定方法
基于G 的ANFIS在函數(shù)擬合中的應(yīng)用
GPS高程擬合方法研究

萊特準則的橢圓擬合優(yōu)化算法
PCB設(shè)計:消除過孔至過孔耦合噪聲的技巧
基于DFP優(yōu)化的大規(guī)模數(shù)據(jù)點擬合方法

基于LSPIA的NURBS曲線擬合優(yōu)化算法

四種微調(diào)大模型的方法介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論