 先進節點上glitch功耗問題
先進節點上glitch功耗問題
這個問題在 AI 加速器中尤為嚴重,修復這個問題需要一些tradeoff。
據估計,一些最先進和最復雜的芯片設計中總功耗的 20% 到 40% 被浪費了。
glitch功耗并不是一個新現象。在先進節點上,glitch功耗問題正變得越來越突出,沒有一種解決方案適用于所有芯片或設計類型。
在組合電路中,時鐘控制不同狀態寄存器的傳播。但是,在柵極或導線中經常存在延遲,因此輸入不會同時到達柵極。
假設你有一個 AND 或 OR 門,你所有的信號不會同時到達,所以需要有一個允許范圍內的穩定時間窗口。輸入越多,發生這種情況的概率就越大,浪費的glitch功耗就越多。
這種現象也被稱為hazards。hazards是電路中可能產生這種glitch的原因。根據邏輯的類型,如果存在非常寬的扇入邏輯,或者非常長深度的組合邏輯,那么這些glitch發生的可能性就更高。glitch是非常高頻率的東西,它們toggle,然后幾乎立即關閉,這種情況可能在任何地方發生多次。
AI 加速器中的glitch
對于 AI 加速器來說,這個問題尤其麻煩,因為 AI 加速器旨在以最小的功耗實現最大的性能。
在神經網絡處理硬件中,有很多乘法累加計算。事實上,許多神經網絡處理器的評級標準是每秒執行數以百萬計的MAC,這是性能的衡量標準。但是,如果你看一下硬件乘法器和加法器的傳統設計,并且這些類型的電路串聯在一起,并采用流水線連接。發生的情況是,即使在單個時鐘周期內,也發生了很多這些信號轉換。由于不同電路的不同延遲,最終穩定下來,得出最終結果。
由于電路的設計方式,這些神經網絡處理器中的乘法器非常容易出現glitch功耗,并且需要多次轉換才能穩定到最終結果。
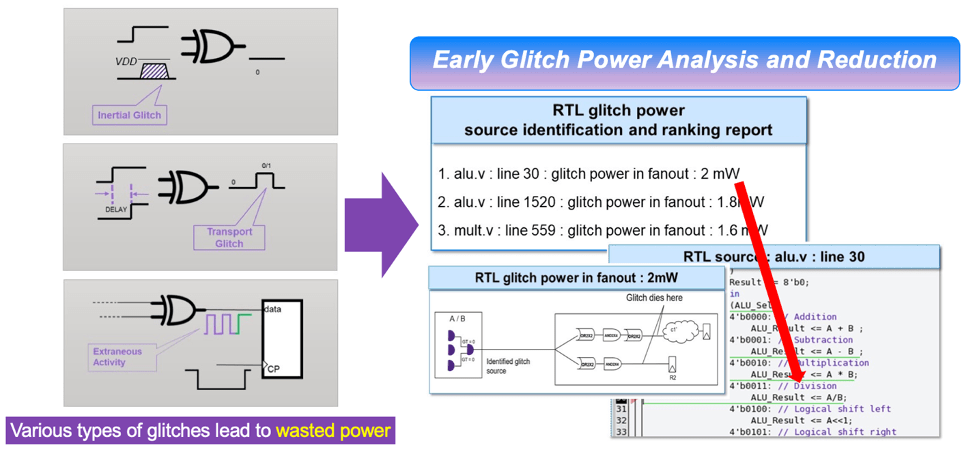
glitch源識別和排序
整體效率
Glitch 也會影響設計的整體效率。當你切換某些東西時,它使用來自電壓源的能量,一直到引腳,但也使用存儲在網絡電容中的能量。因此,如果你像這樣打開和關閉,你就會不必要地充電和放電這些電容器。
由于 RC 延遲增加,先進工藝使情況變得更糟。在先進節點中,晶體管越來越小,延遲開始由RC部分主導。當進入越來越先進的節點時,這些小晶體管必須驅動這些大負載,信號延遲和變化的機會就越多。
如果在線路中存在hazards,就會增加發生glitch的可能性。由于兩個輸入信號的到達時間不同,因此出現了輸出glitch。
很多時候這個glitch的傳播實際上影響更大,對于芯片設計師來說,更令人擔憂的是它的下游影響,因為這種glitch不僅僅停留在那個信號上。這就是事情變得非常復雜的地方。很多時候它可以向下游傳播,因為組合邏輯是多級的。如今,數據路徑更深,時鐘頻率更快。數據路徑可以深達 15 或 20 級,該信號的glitch可以一直傳播,并導致它通過的每個柵極的功耗浪費。
過去,對glitch功耗的擔憂并不多,因為它在總動態功耗中占比不大。但是,我們開始在7nm左右看到的情況,組合邏輯路徑開始變得如此之深,以至于glitch功耗成為一個大問題。突然之間,在某些設計中,它占總動態功耗的 25% 到 40%。
審核編輯:黃飛
-
處理器
+關注
關注
68文章
19259瀏覽量
229652 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100714 -
AI加速器
+關注
關注
1文章
68瀏覽量
8634
原文標題:glitch功耗的問題在先進節點上更加突出
文章出處:【微信號:數字芯片實驗室,微信公眾號:數字芯片實驗室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文讀懂藍牙網狀網絡什么是“友鄰節點”與低功耗
如何在低功耗Bluetooth? PEPS系統中添加CAN節點
用于油管檢漏的WSNs節點低功耗設計
在40-nm工藝節點實現世界上最先進的定制邏輯器件
詳細介紹一種顯著降低LoRa節點功耗的方法
先進工藝節點下的芯片設計需考慮更多變量
5nm及更先進節點上FinFET的未來






 工商網監
工商網監
評論