


MCX N系列是高性能、低功耗微控制器,配備智能外設和加速器,可提供多任務功能和高能效。部分MCX N系列產品包含恩智浦面向機器學習應用的eIQNeutron神經處理單元(NPU)。低功耗高速緩存增強了系統性能,雙塊Flash存儲器和帶ECC檢測的RAM支持系統功能安全,提供了額外的保護和保證。這些安全MCU包含恩智浦EdgeLock安全區域Core Profile,根據設計安全方法構建,提供具有不可變信任根和硬件加速加密的安全啟動。
MCX N系列微型處理器:MCXN94xMCXN54x基于兩個高性能的Arm Cortex-M33核心構建,核心運行速度可達150 MHz。它配備了2MB的板載閃存(Flash),并可選擇配置完整的ECC(錯誤校正碼)RAM,同時集成了一款專屬的神經處理單元(eIQ Neutron NPU)。該NPU在機器學習(ML)任務處理速度上,比M33核心快出40倍,顯著減少了設備的喚醒時間,并有效降低了總體功耗。
eIQ Neutron NPUs能夠支援包括CNN(卷積神經網絡)、RNN(循環神經網絡)、TCN(時間卷積網絡)以及Transformer等多種類型的神經網絡。利用eIQ Neutron NPU進行機器學習應用的開發,將得到eIQ機器學習軟件開發環境的全方位支持。eIQ Neutron NPU系統框圖如下所示:
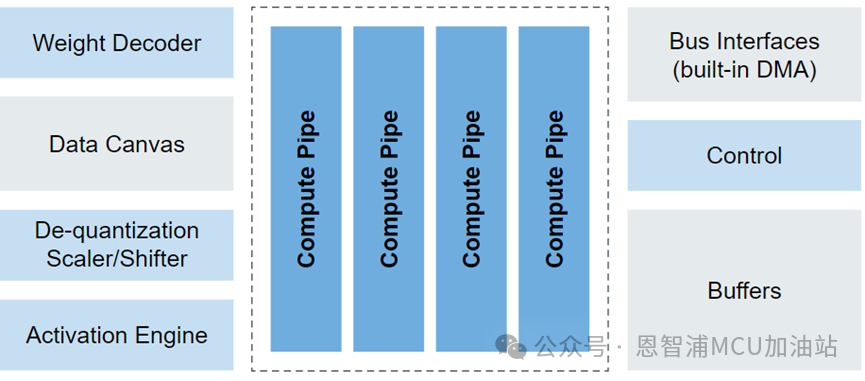
NPU由計算單元,權重解碼器,量化器,優化函數加速器,RAM以及DMA快速訪問接口組成,其ML算力可達4.8G。強大的算力給ML推理帶來極大的加速,在TinyML Perf benchmark測試模型上的性能對比如下圖所示:
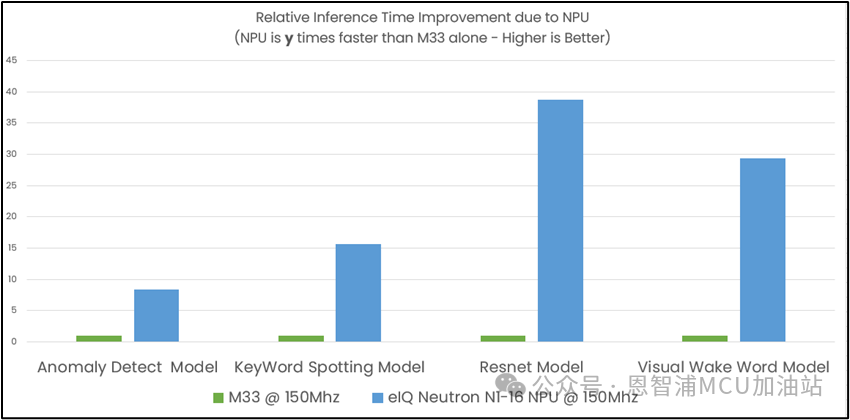
圖中表示NPU的性能提升倍數,綠色柱體代表M33,藍色柱體代表NPU基于M33的提升倍數。從圖中可以看到Anomaly Detect異常檢測模型NPU提供8倍的性能提升,Keyword spotting關鍵詞檢測模型NPU提供15倍的提升,Resnet圖像分類模型NPU提供38倍的性能提升,VisualWake Word模型NPU提供28倍的性能提升。
對于不同類型的模型,NPU的加速效果略有不同。Resnet主要是由卷積網絡構成,NPU的主要計算單元是乘累加計算器,并且通道間權重是共享的,所以NPU對卷積網絡性能提升是最大的,異常檢測模型主要由全連接網絡組成,全連接網絡的權重無法共享故而無法最大限度的利用NPU,所以全連接網絡的加速是最小的。
推理速度的提升必然會減少核心的運行時間從而降低了整體的功耗,打開NPU會額外增加1.4mA(3.3V)的電流,相比運算速度的提升,這個增量可以忽略不記。
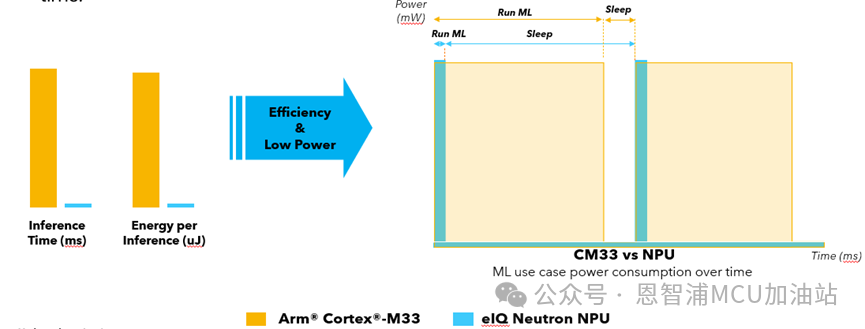
從運行時序圖上看,NPU使能后Core的大部分時間是在休眠狀態,如果不在NPU上推理模型,Core基本一直處于運行狀態,NPU節能效果顯而易見。
審核編輯:劉清
-
微控制器
+關注
關注
48文章
7937瀏覽量
154417 -
加速器
+關注
關注
2文章
826瀏覽量
39052 -
神經網絡
+關注
關注
42文章
4812瀏覽量
103350 -
機器學習
+關注
關注
66文章
8500瀏覽量
134437 -
NPU
+關注
關注
2文章
326瀏覽量
19669
原文標題:MCX N系列微處理器之NPU使用方法簡介
文章出處:【微信號:NXP_SMART_HARDWARE,微信公眾號:恩智浦MCU加油站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
恩智浦MCX A系列微處理器之供電系統
恩智浦 MCX N系列之電源管理(MCX N94/54與MCX N23)
恩智浦MCU解析 MCX A系列微處理器之系統架構


什么是ARM處理器 ARM處理器有哪些系列
微控制器與微處理器簡析
處理器系列之X86微處理器體系結構

恩智浦全新MCX N微控制器推出!助力實現高性能、低功耗的邊緣安全智能
npu是什么處理器?NPU卡是什么?
恩智浦推出首次搭載專屬神經處理單元(NPU)的MCX N系列!

MCX N系列微處理器之NPU的入門使用方法介紹





 工商網監
工商網監

評論