


4月19日,在以“重構(gòu)世界 奔赴未來”為主題的2024中國生成式AI大會上,中科馭數(shù)作為DPU新型算力基礎設施代表,受邀出席了中國智算中心創(chuàng)新論壇,發(fā)表了題為《以網(wǎng)絡為中心的AI算力底座構(gòu)建之路》主題演講,勾勒出在通往AGI之路上,DPU技術賦能下一代AI算力基礎設施中的關鍵作用。
算力是當前人工智能領域發(fā)展的關鍵,是AI時代的“面包”。要訓練百萬億參數(shù)超大預訓練模型,算力基礎設施架構(gòu)優(yōu)化是提升算力的首要步驟。當前,DPU算力基礎已經(jīng)發(fā)展迭代了4到5年,算力領域?qū)PU的期望和需求已經(jīng)涵蓋計算、網(wǎng)絡、存儲、安全等多個領域。
中科馭數(shù)旨在通過DPU將計算加速、存儲加速、網(wǎng)絡加速、安全加速及云原生加速等基礎設施層深度整合,構(gòu)建高性能、高集成的AI服務基礎架構(gòu)。公司已基于此打造出涵蓋云原生DPU軟硬一體加速、RDMA/RoCE AI計算網(wǎng)絡、NVMe-oF高性能存儲、靈活存算分離架構(gòu)、DPU硬件級安全隔離以及數(shù)據(jù)中心資源池化與統(tǒng)一調(diào)度的豐富產(chǎn)品矩陣與解決方案,不僅僅能夠助力AI算力底座的整體性能提升,也為用戶提供了更高效更完整的基礎設施解決方案,有力支撐各類AI應用的快速發(fā)展。
以中科馭數(shù)自研FLEXFLOW-2100R RDMA加速DPU卡為例,該加速卡產(chǎn)品能夠?qū)⒏咝阅堋⒎€(wěn)定性、便捷性和通用性融為一體,提供2x100GbE網(wǎng)口的連接能力,支持RoCEv2的硬件卸載能力以及無損網(wǎng)絡能力,為國產(chǎn)化業(yè)務場景提供微秒級時延和百G帶寬的RDMA網(wǎng)絡環(huán)境,為用戶提供靈活和高性能的網(wǎng)絡解決方案。同時,適配市面上所有主流支持無損網(wǎng)絡的交換機,以及國內(nèi)外主流服務器和操作系統(tǒng),可以快速接入現(xiàn)有RDMA網(wǎng)絡環(huán)境。經(jīng)實測,KPU FLEXFLOW-2100R在4K以下小文件send、read、write測試場景中,時延數(shù)據(jù)均在5us以下,最低可達3us,優(yōu)于國內(nèi)外主流RDMA智能網(wǎng)卡性能水準。
需要看到的是,隨著AI向更多領域滲透,對基礎設施的需求將更加多元化、智能化。同樣,DPU的成功落地和使用需要經(jīng)過精心設計和打磨,以滿足整個基礎設施領域的多樣需求。中科馭數(shù)將繼續(xù)秉持著技術創(chuàng)新和開放合作的理念,歡迎服務器廠商、CPU/GPU廠商、操作系統(tǒng)廠商等上下游合作伙伴加入馭數(shù)DPU生態(tài),共同推動AI算力底座的發(fā)展。
審核編輯:劉清
-
交換機
+關注
關注
22文章
2735瀏覽量
101814 -
DPU
+關注
關注
0文章
393瀏覽量
24882 -
人工智能
+關注
關注
1806文章
48973瀏覽量
248792 -
RDMA
+關注
關注
0文章
83瀏覽量
9271 -
生成式AI
+關注
關注
0文章
531瀏覽量
785
原文標題:通往AGI路上,DPU將如何構(gòu)建生成式AI時代的堅實算力基石?
文章出處:【微信號:yusurtech,微信公眾號:馭數(shù)科技】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
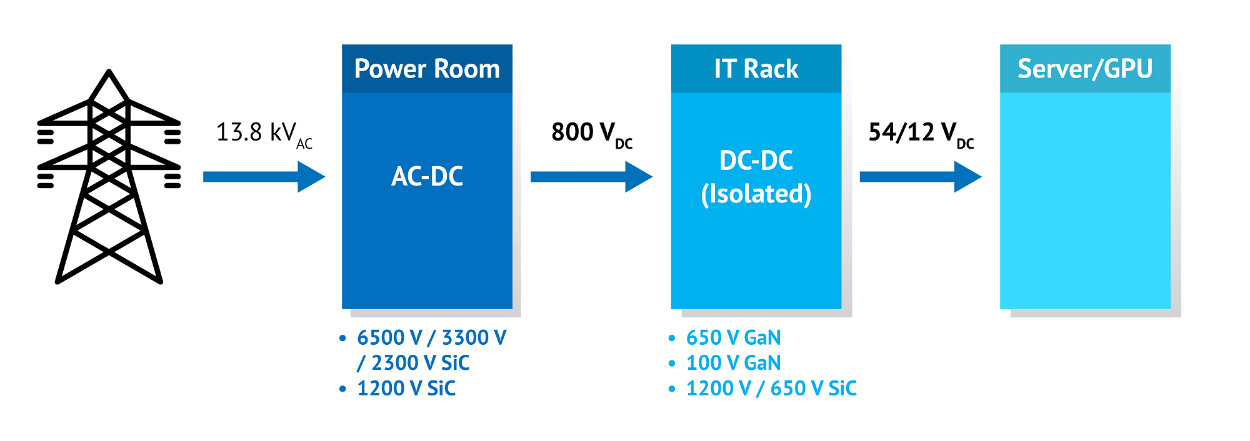
NVIDIA 采用納微半導體開發(fā)新一代數(shù)據(jù)中心電源架構(gòu) 800V HVDC 方案,賦能下一代AI兆瓦級算力需求
華為云黃瑾:昇騰云CloudMatrix 384超節(jié)點六大科技創(chuàng)新,定義下一代AI基礎設施
智能算力基建:RAKsmart如何賦能下一代AI開發(fā)工具
RAKsmart服務器如何賦能AI開發(fā)與部署

DeepSeek推動AI算力需求:800G光模塊的關鍵作用
百度李彥宏談訓練下一代大模型
企業(yè)AI算力租賃模式的好處
算力再躍升!億萬克發(fā)布新一代AI服務器——G882N7+!
穩(wěn)定、高效、低成本,儲能與算力正在相互賦能
科通技術:引領AI算力供應鏈,賦能下一代數(shù)據(jù)中心

AI驅(qū)動下的數(shù)字經(jīng)濟:智能社會基礎設施與算力革新
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
國科微AI首席科學家邢國良:打造全系邊端AI芯片,賦能下一代自動駕駛






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論