") AI時(shí)代的存儲(chǔ)墻,哪種存算方案才能打破?
AI時(shí)代的存儲(chǔ)墻,哪種存算方案才能打破?
電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))回顧計(jì)算行業(yè)幾十年的歷史,芯片算力提升在幾年前,還在遵循摩爾定律。可隨著如今摩爾定律顯著放緩,算力發(fā)展已經(jīng)陷入瓶頸。而且禍不單行,陷入同樣困境的還有存儲(chǔ)。從新標(biāo)準(zhǔn)推進(jìn)的角度來看,存儲(chǔ)市場(chǎng)依然在朝著更高性能的方向發(fā)展。但以這些通用標(biāo)準(zhǔn)推出的產(chǎn)品,終究還是會(huì)被用到馮諾依曼架構(gòu)的計(jì)算體系中去。或許單個(gè)產(chǎn)品的性能有所增加,可面對(duì)AI計(jì)算的海量數(shù)據(jù),這點(diǎn)提升還是有些不夠看。
以LLM這個(gè)熱門AI應(yīng)用而言,其數(shù)據(jù)量已經(jīng)在以2年750倍的速度爆發(fā)式增長(zhǎng),相較之下硬件算力正在以2年3倍的速度增長(zhǎng)。但與存儲(chǔ)不同,硬件算力是可以靠堆規(guī)模來實(shí)現(xiàn)持續(xù)提升的,可存儲(chǔ)帶寬和互聯(lián)帶寬卻沒法擁有同樣的拓展性,只有存儲(chǔ)容量能夠勉強(qiáng)跟上。所以市場(chǎng)上多數(shù)都在追求某種形式的存算一體方案,但實(shí)現(xiàn)的形式和技術(shù)路線不盡相同。
近存方案,更大的SRAM和HBM
對(duì)于我們說的存儲(chǔ)墻而言,其實(shí)在SRAM上并不那么明顯,這種最接近處理單元的存儲(chǔ),常被用作高速緩存,不僅讀寫速度極快,能效比更是遠(yuǎn)超DRAM。但SRAM相對(duì)其他存儲(chǔ)而言,存儲(chǔ)密度最低,成本卻不低。所以盡管現(xiàn)如今雖然更大的SRAM設(shè)計(jì)越來越普遍,但容量離DRAM還差得很遠(yuǎn)。
但這并不代表這樣的設(shè)計(jì)沒有人嘗試,對(duì)于愿意花大成本的廠商而言,還是很高效的一條技術(shù)路線。以特斯拉為例,其Tesla Dojo超算系統(tǒng)的自研芯片D1就采用了超大SRAM的技術(shù)路線。Dojo在其網(wǎng)格設(shè)計(jì)中采用了超快且平均分布的SRAM。
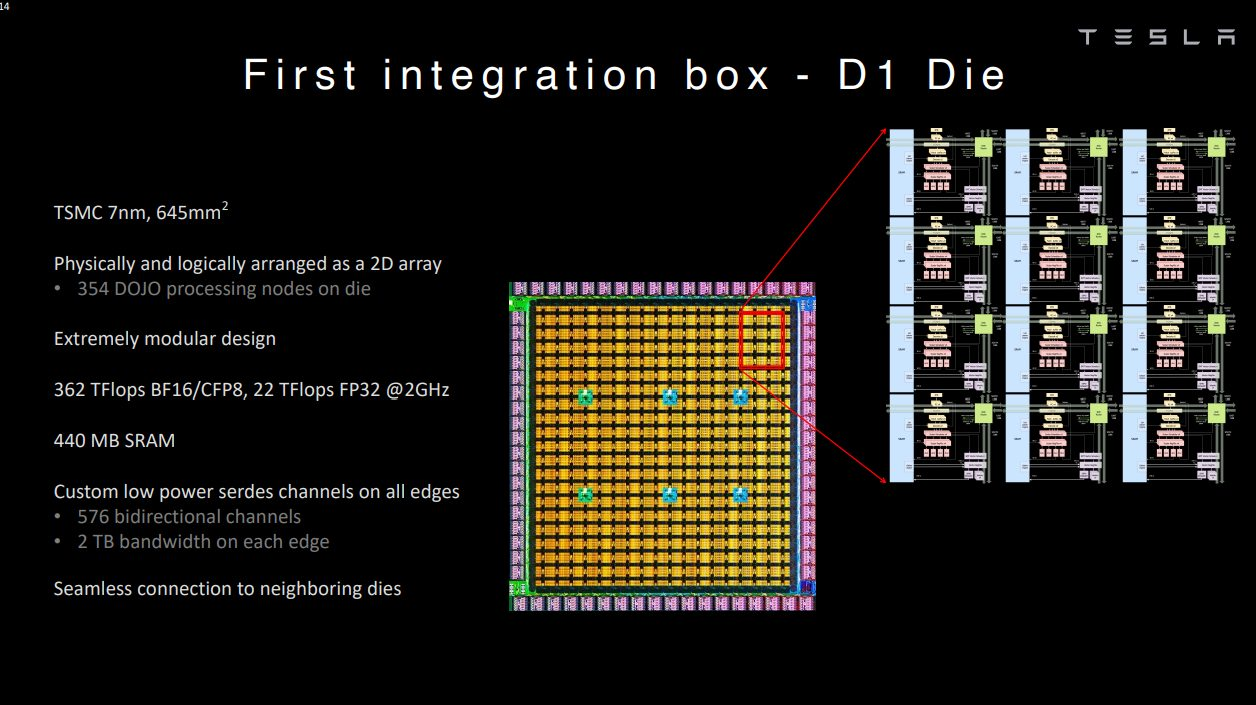
單個(gè)D1核心擁有1.25MB的SRAM,加載速度達(dá)到400GB/s,存儲(chǔ)速度達(dá)到270GB/s。單個(gè)D1芯片的SRAM緩存達(dá)到440MB。簡(jiǎn)單來說,Dojo可以用遠(yuǎn)超L2緩存級(jí)別的SRAM容量,實(shí)現(xiàn)L1緩存級(jí)別的帶寬和延遲。
當(dāng)然了,這樣的設(shè)計(jì)注定代表了投入大量的成本。在特斯拉2023財(cái)年Q4的財(cái)報(bào)會(huì)議上,馬斯克強(qiáng)調(diào)他們做了英偉達(dá)和Dojo的兩手準(zhǔn)備。Dojo作為長(zhǎng)遠(yuǎn)計(jì)劃,因?yàn)樽罱K的回報(bào)可能會(huì)值回現(xiàn)在的投入,但他也強(qiáng)調(diào)這確實(shí)不是什么高收益的項(xiàng)目。
所以對(duì)于已有的計(jì)算架構(gòu)來說,走近存路線,提高DRAM的性能是最為適合的,比如HBM。HBM作為主流的近存高帶寬方案,已經(jīng)被廣泛應(yīng)用在新一代的AI芯片、GPU上。以HBM3e為例,1.2TB/s的超大帶寬足以滿足現(xiàn)如今絕大多數(shù)AI芯片的數(shù)據(jù)傳輸。未來的HBM4更是承諾1.5TB/s到2TB/s的帶寬,
HBM的方案象征了目前DRAM堆疊的集大成技術(shù),但目前還是存在不少問題,比如更高的成本以及對(duì)產(chǎn)能的要求。在現(xiàn)如今的AI需求驅(qū)動(dòng)下,新發(fā)布的芯片很難再采用HBM設(shè)計(jì)的同時(shí),保證大批量量產(chǎn),無論是HBM產(chǎn)能還是CoWoS產(chǎn)能都處于滿載的階段,而且與制造廠商強(qiáng)綁定。可恰恰存儲(chǔ)帶寬決定了AI應(yīng)用的速度,所以在HBM方案量產(chǎn)困難成本高昂的前提下,即便是英特爾和AMD這樣的廠商也經(jīng)不起這樣揮霍,不少其他廠商更是選擇了看下存內(nèi)計(jì)算。
存內(nèi)計(jì)算與處理,需要解決算力與存儲(chǔ)雙瓶頸
為了解決AI計(jì)算中數(shù)據(jù)存取的效率問題,把數(shù)據(jù)處理和篩選的工作放在存儲(chǔ)端,就能極大地降低數(shù)據(jù)移動(dòng)的能耗。以三星的PIM技術(shù)為例,其將關(guān)鍵的算法內(nèi)核放在內(nèi)存中的PCU模塊中執(zhí)行,相比已有的HBM方案,PIM-HBM可以將能耗降低70%以上。而且不僅是HBM,PIM也可以集成到LPDDR、GDDR等存儲(chǔ)方案中。
不過存內(nèi)處理的方案只解決了功耗和效率的問題,并沒有對(duì)計(jì)算性能和存儲(chǔ)性能帶來任何大幅提升。至于將主要計(jì)算工作交給存內(nèi)的計(jì)算單元,就是存內(nèi)計(jì)算的目標(biāo)了,比如不少?gòu)S商嘗試的模擬存內(nèi)計(jì)算(AIMC)。但這類方案實(shí)現(xiàn)大規(guī)模并行化運(yùn)算的同時(shí),還是需要昂貴的數(shù)模轉(zhuǎn)換器,以及逃不開的錯(cuò)誤檢測(cè)。至于數(shù)字存內(nèi)計(jì)算方案,一定程度上規(guī)避了模擬存內(nèi)計(jì)算的缺陷,但還是犧牲了一些面積效率。對(duì)于一些大模型AI應(yīng)用而言,單芯片的存儲(chǔ)容量擴(kuò)展性堪憂。
所以數(shù)模混合成了新的研究方向,比如中科院微電子研究所就在今年的ISSCC大會(huì)上發(fā)表了數(shù)模混合存算一體芯片的論文,其采用模擬方案來進(jìn)行陣列內(nèi)位乘法計(jì)算,利用數(shù)字方案來進(jìn)行陣列外多位移位累加計(jì)算,從而達(dá)到整體的高能量效率和面積效率,INT8精度下的計(jì)算峰值能效可達(dá)111.17TFLOPS/W.

除此之外,還有存間計(jì)算的廠商,將計(jì)算單元放在不同的SRAM之間。以存間計(jì)算初創(chuàng)公司Untether AI為例,他們以打造存內(nèi)推理加速器AI為主,通過將計(jì)算單元放在兩個(gè)存儲(chǔ)單元之間,其IC可以提供更高能效比的推理性能。比如他們?cè)诖蛟斓牡诙鶬C,speedAI240,集成了1400個(gè)定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可達(dá)30 TFLOPS/W。
除了各種存算一體架構(gòu)的算力瓶頸外,存儲(chǔ)本身也需要做出突破。以三星的PIM為例,其雖然在DRAM上引入了PIM計(jì)算單元,但并未對(duì)DRAM本身的帶寬的性能帶來提升,這就造成了在存算一體的架構(gòu)中,依然存在計(jì)算單元與存儲(chǔ)器性能不平衡的問題,各種其他類型的存儲(chǔ)器,包括MRAM、PCM、RRAM,除了量產(chǎn)問題外,寫入速度和功耗的問題也還未實(shí)現(xiàn)突破。
西安紫光國(guó)芯為此提出了一種3D異質(zhì)集成DRAM架構(gòu),邏輯晶圓通過3D混合鍵合工藝堆疊至SeDRAM晶圓上,進(jìn)一步提升了訪存帶寬,降低了單位比特能耗,還能實(shí)現(xiàn)超大容量。從去年紫光國(guó)芯在VLSI 2023發(fā)布的論文來看,其SeDRAM已經(jīng)發(fā)展至新一代多層陣列架構(gòu)。結(jié)合低溫混合鍵合技術(shù)和mini-TSV堆疊技術(shù),可以實(shí)現(xiàn)135Gbps/Gbit的帶寬和0.66pJ/bit的能效。
寫在最后
其實(shí)無論是哪一種突破存儲(chǔ)墻瓶頸的方式,最終都很難逃脫復(fù)雜工藝帶來的挑戰(zhàn)。行業(yè)遲遲不愿普及相關(guān)的存算技術(shù),還是在制造工藝上沒有達(dá)到適合普及的標(biāo)準(zhǔn),無論是良率、成本還是所需的設(shè)計(jì)、制造流水線變化。已經(jīng)占據(jù)主導(dǎo)地位的計(jì)算芯片廠商,也不會(huì)選擇非得和存儲(chǔ)綁在一條船上,但行業(yè)必然會(huì)朝這個(gè)方向發(fā)展。
此外,不少存內(nèi)計(jì)算的堆疊方案中,還沒有選擇將主計(jì)算資源的CPU或GPU與存儲(chǔ)垂直堆疊,而是把部分計(jì)算負(fù)載交給與存儲(chǔ)結(jié)合的計(jì)算單元。這樣一來既提高了AI計(jì)算的效率,又不會(huì)因?yàn)榻Y(jié)構(gòu)變化而出現(xiàn)不兼容的情況。從行業(yè)發(fā)展的角度來看,近存計(jì)算和存內(nèi)處理最有可能先普及開來。
以LLM這個(gè)熱門AI應(yīng)用而言,其數(shù)據(jù)量已經(jīng)在以2年750倍的速度爆發(fā)式增長(zhǎng),相較之下硬件算力正在以2年3倍的速度增長(zhǎng)。但與存儲(chǔ)不同,硬件算力是可以靠堆規(guī)模來實(shí)現(xiàn)持續(xù)提升的,可存儲(chǔ)帶寬和互聯(lián)帶寬卻沒法擁有同樣的拓展性,只有存儲(chǔ)容量能夠勉強(qiáng)跟上。所以市場(chǎng)上多數(shù)都在追求某種形式的存算一體方案,但實(shí)現(xiàn)的形式和技術(shù)路線不盡相同。
近存方案,更大的SRAM和HBM
對(duì)于我們說的存儲(chǔ)墻而言,其實(shí)在SRAM上并不那么明顯,這種最接近處理單元的存儲(chǔ),常被用作高速緩存,不僅讀寫速度極快,能效比更是遠(yuǎn)超DRAM。但SRAM相對(duì)其他存儲(chǔ)而言,存儲(chǔ)密度最低,成本卻不低。所以盡管現(xiàn)如今雖然更大的SRAM設(shè)計(jì)越來越普遍,但容量離DRAM還差得很遠(yuǎn)。
但這并不代表這樣的設(shè)計(jì)沒有人嘗試,對(duì)于愿意花大成本的廠商而言,還是很高效的一條技術(shù)路線。以特斯拉為例,其Tesla Dojo超算系統(tǒng)的自研芯片D1就采用了超大SRAM的技術(shù)路線。Dojo在其網(wǎng)格設(shè)計(jì)中采用了超快且平均分布的SRAM。
D1芯片 / 特斯拉
單個(gè)D1核心擁有1.25MB的SRAM,加載速度達(dá)到400GB/s,存儲(chǔ)速度達(dá)到270GB/s。單個(gè)D1芯片的SRAM緩存達(dá)到440MB。簡(jiǎn)單來說,Dojo可以用遠(yuǎn)超L2緩存級(jí)別的SRAM容量,實(shí)現(xiàn)L1緩存級(jí)別的帶寬和延遲。
當(dāng)然了,這樣的設(shè)計(jì)注定代表了投入大量的成本。在特斯拉2023財(cái)年Q4的財(cái)報(bào)會(huì)議上,馬斯克強(qiáng)調(diào)他們做了英偉達(dá)和Dojo的兩手準(zhǔn)備。Dojo作為長(zhǎng)遠(yuǎn)計(jì)劃,因?yàn)樽罱K的回報(bào)可能會(huì)值回現(xiàn)在的投入,但他也強(qiáng)調(diào)這確實(shí)不是什么高收益的項(xiàng)目。
所以對(duì)于已有的計(jì)算架構(gòu)來說,走近存路線,提高DRAM的性能是最為適合的,比如HBM。HBM作為主流的近存高帶寬方案,已經(jīng)被廣泛應(yīng)用在新一代的AI芯片、GPU上。以HBM3e為例,1.2TB/s的超大帶寬足以滿足現(xiàn)如今絕大多數(shù)AI芯片的數(shù)據(jù)傳輸。未來的HBM4更是承諾1.5TB/s到2TB/s的帶寬,
HBM的方案象征了目前DRAM堆疊的集大成技術(shù),但目前還是存在不少問題,比如更高的成本以及對(duì)產(chǎn)能的要求。在現(xiàn)如今的AI需求驅(qū)動(dòng)下,新發(fā)布的芯片很難再采用HBM設(shè)計(jì)的同時(shí),保證大批量量產(chǎn),無論是HBM產(chǎn)能還是CoWoS產(chǎn)能都處于滿載的階段,而且與制造廠商強(qiáng)綁定。可恰恰存儲(chǔ)帶寬決定了AI應(yīng)用的速度,所以在HBM方案量產(chǎn)困難成本高昂的前提下,即便是英特爾和AMD這樣的廠商也經(jīng)不起這樣揮霍,不少其他廠商更是選擇了看下存內(nèi)計(jì)算。
存內(nèi)計(jì)算與處理,需要解決算力與存儲(chǔ)雙瓶頸
為了解決AI計(jì)算中數(shù)據(jù)存取的效率問題,把數(shù)據(jù)處理和篩選的工作放在存儲(chǔ)端,就能極大地降低數(shù)據(jù)移動(dòng)的能耗。以三星的PIM技術(shù)為例,其將關(guān)鍵的算法內(nèi)核放在內(nèi)存中的PCU模塊中執(zhí)行,相比已有的HBM方案,PIM-HBM可以將能耗降低70%以上。而且不僅是HBM,PIM也可以集成到LPDDR、GDDR等存儲(chǔ)方案中。
不過存內(nèi)處理的方案只解決了功耗和效率的問題,并沒有對(duì)計(jì)算性能和存儲(chǔ)性能帶來任何大幅提升。至于將主要計(jì)算工作交給存內(nèi)的計(jì)算單元,就是存內(nèi)計(jì)算的目標(biāo)了,比如不少?gòu)S商嘗試的模擬存內(nèi)計(jì)算(AIMC)。但這類方案實(shí)現(xiàn)大規(guī)模并行化運(yùn)算的同時(shí),還是需要昂貴的數(shù)模轉(zhuǎn)換器,以及逃不開的錯(cuò)誤檢測(cè)。至于數(shù)字存內(nèi)計(jì)算方案,一定程度上規(guī)避了模擬存內(nèi)計(jì)算的缺陷,但還是犧牲了一些面積效率。對(duì)于一些大模型AI應(yīng)用而言,單芯片的存儲(chǔ)容量擴(kuò)展性堪憂。
所以數(shù)模混合成了新的研究方向,比如中科院微電子研究所就在今年的ISSCC大會(huì)上發(fā)表了數(shù)模混合存算一體芯片的論文,其采用模擬方案來進(jìn)行陣列內(nèi)位乘法計(jì)算,利用數(shù)字方案來進(jìn)行陣列外多位移位累加計(jì)算,從而達(dá)到整體的高能量效率和面積效率,INT8精度下的計(jì)算峰值能效可達(dá)111.17TFLOPS/W.
speedAI240 / Untether AI
除此之外,還有存間計(jì)算的廠商,將計(jì)算單元放在不同的SRAM之間。以存間計(jì)算初創(chuàng)公司Untether AI為例,他們以打造存內(nèi)推理加速器AI為主,通過將計(jì)算單元放在兩個(gè)存儲(chǔ)單元之間,其IC可以提供更高能效比的推理性能。比如他們?cè)诖蛟斓牡诙鶬C,speedAI240,集成了1400個(gè)定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可達(dá)30 TFLOPS/W。
除了各種存算一體架構(gòu)的算力瓶頸外,存儲(chǔ)本身也需要做出突破。以三星的PIM為例,其雖然在DRAM上引入了PIM計(jì)算單元,但并未對(duì)DRAM本身的帶寬的性能帶來提升,這就造成了在存算一體的架構(gòu)中,依然存在計(jì)算單元與存儲(chǔ)器性能不平衡的問題,各種其他類型的存儲(chǔ)器,包括MRAM、PCM、RRAM,除了量產(chǎn)問題外,寫入速度和功耗的問題也還未實(shí)現(xiàn)突破。
西安紫光國(guó)芯為此提出了一種3D異質(zhì)集成DRAM架構(gòu),邏輯晶圓通過3D混合鍵合工藝堆疊至SeDRAM晶圓上,進(jìn)一步提升了訪存帶寬,降低了單位比特能耗,還能實(shí)現(xiàn)超大容量。從去年紫光國(guó)芯在VLSI 2023發(fā)布的論文來看,其SeDRAM已經(jīng)發(fā)展至新一代多層陣列架構(gòu)。結(jié)合低溫混合鍵合技術(shù)和mini-TSV堆疊技術(shù),可以實(shí)現(xiàn)135Gbps/Gbit的帶寬和0.66pJ/bit的能效。
寫在最后
其實(shí)無論是哪一種突破存儲(chǔ)墻瓶頸的方式,最終都很難逃脫復(fù)雜工藝帶來的挑戰(zhàn)。行業(yè)遲遲不愿普及相關(guān)的存算技術(shù),還是在制造工藝上沒有達(dá)到適合普及的標(biāo)準(zhǔn),無論是良率、成本還是所需的設(shè)計(jì)、制造流水線變化。已經(jīng)占據(jù)主導(dǎo)地位的計(jì)算芯片廠商,也不會(huì)選擇非得和存儲(chǔ)綁在一條船上,但行業(yè)必然會(huì)朝這個(gè)方向發(fā)展。
此外,不少存內(nèi)計(jì)算的堆疊方案中,還沒有選擇將主計(jì)算資源的CPU或GPU與存儲(chǔ)垂直堆疊,而是把部分計(jì)算負(fù)載交給與存儲(chǔ)結(jié)合的計(jì)算單元。這樣一來既提高了AI計(jì)算的效率,又不會(huì)因?yàn)榻Y(jié)構(gòu)變化而出現(xiàn)不兼容的情況。從行業(yè)發(fā)展的角度來看,近存計(jì)算和存內(nèi)處理最有可能先普及開來。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
存儲(chǔ)
+關(guān)注
關(guān)注
13文章
4296瀏覽量
85800 -
sram
+關(guān)注
關(guān)注
6文章
767瀏覽量
114675 -
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268891 -
HBM
+關(guān)注
關(guān)注
0文章
379瀏覽量
14745 -
存算一體
+關(guān)注
關(guān)注
0文章
102瀏覽量
4297 -
存內(nèi)計(jì)算
+關(guān)注
關(guān)注
0文章
30瀏覽量
1378
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AI驅(qū)動(dòng)新型存儲(chǔ)器技術(shù),國(guó)內(nèi)新興存儲(chǔ)企業(yè)進(jìn)階
生成式AI對(duì)于算力、運(yùn)力和存力的需求與日俱增,如何打破“存儲(chǔ)墻”成為
發(fā)表于 10-16 08:10
?940次閱讀

開源芯片系列講座第24期:基于SRAM存算的高效計(jì)算架構(gòu)
先進(jìn)的計(jì)算架構(gòu)技術(shù),以克服傳統(tǒng)馮諾依曼架構(gòu)中計(jì)算單元與存儲(chǔ)單元分離導(dǎo)致的“內(nèi)存墻”問題。基于SRAM的存算一體技術(shù)在智能計(jì)算中具有高能效、高密度等優(yōu)勢(shì),近年來在A

知存科技啟動(dòng)首屆存內(nèi)計(jì)算創(chuàng)新大賽
存內(nèi)計(jì)算作為一項(xiàng)打破“內(nèi)存墻”“功耗墻”的顛覆性技術(shù),消除了存與算的界限,相比CPU或GPU能夠
知存科技榮獲2024中國(guó)AI算力層創(chuàng)新企業(yè)
中國(guó)科技產(chǎn)業(yè)智庫(kù)「甲子光年」主辦、中關(guān)村東升科學(xué)城協(xié)辦的「AI創(chuàng)生時(shí)代2024甲子引力X科技產(chǎn)業(yè)新風(fēng)向」大會(huì)在北京正式舉行。作為壓軸,「甲子光年」重磅發(fā)布了【星辰100】2024創(chuàng)新企業(yè)榜。知存
存算一體架構(gòu)創(chuàng)新助力國(guó)產(chǎn)大算力AI芯片騰飛
在灣芯展SEMiBAY2024《AI芯片與高性能計(jì)算(HPC)應(yīng)用論壇》上,億鑄科技高級(jí)副總裁徐芳發(fā)表了題為《存算一體架構(gòu)創(chuàng)新助力國(guó)產(chǎn)大算力AI
存力與算力并重:數(shù)據(jù)時(shí)代的雙刃劍
在2024年的今天,人工智能(AI)技術(shù)已經(jīng)全面滲透至我們生活的方方面面,從醫(yī)療診斷到智能交通,從金融分析到智能家居,AI正以前所未有的速度重塑我們的世界。這一變革背后,算力和存力成為
大模型時(shí)代的算力需求
現(xiàn)在AI已進(jìn)入大模型時(shí)代,各企業(yè)都爭(zhēng)相部署大模型,但如何保證大模型的算力,以及相關(guān)的穩(wěn)定性和性能,是一個(gè)極為重要的問題,帶著這個(gè)極為重要的問題,我需要在此書中找到答案。
發(fā)表于 08-20 09:04
后摩智能推出邊端大模型AI芯片M30,展現(xiàn)出存算一體架構(gòu)優(yōu)勢(shì)
了基于M30芯片的智算模組(SoM)和力謀??AI加速卡。 ? 后摩智能存算一體架構(gòu)芯片產(chǎn)品 ? 后摩智能是一家專注于存
2024多樣性算力產(chǎn)業(yè)峰會(huì):江波龍解碼AI存儲(chǔ)方案的未來之路
6月18日,多樣性算力產(chǎn)業(yè)峰會(huì)2024在北京圓滿舉行,江波龍企業(yè)級(jí)存儲(chǔ)事業(yè)部市場(chǎng)總監(jiān)曹潯峰受邀出席本次峰會(huì)并發(fā)表了《大模型時(shí)代AI存儲(chǔ)

知存科技助力AI應(yīng)用落地:WTMDK2101-ZT1評(píng)估板實(shí)地評(píng)測(cè)與性能揭秘
一體領(lǐng)域的研發(fā)領(lǐng)導(dǎo)者
存算一體技術(shù)作為解決馮諾依曼架構(gòu)下存儲(chǔ)墻問題的重要方案,吸引了國(guó)內(nèi)外眾多企業(yè)的研發(fā)投入,其中知
發(fā)表于 05-16 16:38
存內(nèi)計(jì)算WTM2101編譯工具鏈 資料
出來再進(jìn)行計(jì)算,讀取時(shí)間與參數(shù)規(guī)模成正比,計(jì)算芯片的功耗和性能受限,GPU算力利用率甚至不到8%。
存內(nèi)計(jì)算芯片實(shí)現(xiàn)了存儲(chǔ)單元與計(jì)算單元的物理融合,沒有獨(dú)立的計(jì)算單元,直接通過在存儲(chǔ)器
發(fā)表于 05-16 16:33
一圖看懂星河AI數(shù)據(jù)中心網(wǎng)絡(luò),全面釋放AI時(shí)代算力
華為中國(guó)合作伙伴大會(huì) | 一圖看懂星河AI數(shù)據(jù)中心網(wǎng)絡(luò),以網(wǎng)強(qiáng)算,全面釋放AI時(shí)代算力


大算力時(shí)代, 如何打破內(nèi)存墻
設(shè)計(jì)的不斷革新,進(jìn)入了大算力時(shí)代。 目前,主流AI芯片的架構(gòu)仍然沿用了傳統(tǒng)的馮·諾依曼模型,這一設(shè)計(jì)將計(jì)算單元與數(shù)據(jù)存儲(chǔ)分離。在這種架構(gòu)下,處理器需要從內(nèi)存中讀取數(shù)據(jù),執(zhí)行計(jì)算任務(wù),然
SRAM存算一體芯片的研究現(xiàn)狀和發(fā)展趨勢(shì)
人工智能時(shí)代對(duì)計(jì)算芯片的算力和能效都提出了極高要求。存算一體芯片技術(shù)被認(rèn)為是有望解決處理器芯片“存儲(chǔ)墻





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論