

幾十年前,CPU 作為通用處理器幾乎處理所有計算任務,那個時代的顯卡有助于加快應用程序中圖形的繪制速度。但在今天ChatGPT引爆的人工智能iPhone時刻,GPU成為了整個行業最具主導地位的芯片之一。大家都在搶購GPU,龍頭企業英偉達也因此賺的盆滿缽滿。
在此前的文章中我們介紹了AI算力的主要載體數據中心IDC的商業模式和組成部分,并進一步走進服務器這個數據中心中主要負責計算的硬件。服務器中有處理器、內存、硬盤等零部件,其中最核心的負責計算的當屬處理器,也就是芯片。因此,今天我們繼續梳理AI算力芯片,看看為什么在當今AI時代GPU占據了主導地位以及我國目前的發展情況與相關企業。
產業鏈
從產業鏈說起,首先來看芯片在產業鏈中扮演的角色。這里從兩方面說,站在算力產業鏈角度,芯片屬于上游產品,正如我們在《AI服務器革命:硬件進化驅動人工智能新紀元》一文中提到,芯片與其它硬件組成服務器,也就是產業鏈中游,服務器又與其它設備共同組成下游的數據中心。
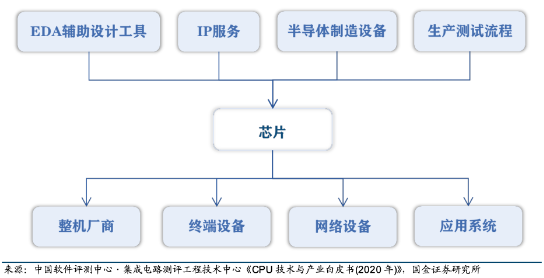
如果站在半導體產業鏈的角度看,那么芯片屬于中游。它的上游包括支撐集成電路設計和制造的 EDA 輔助設計工具和 IP 服務,半導體制造設備、芯片生產測試流程。產業鏈下游包括各類整機廠商、終端設備、網絡設備和應用系統等,其中最重要的是服務器、桌面和嵌入式系統等硬件設備廠商。
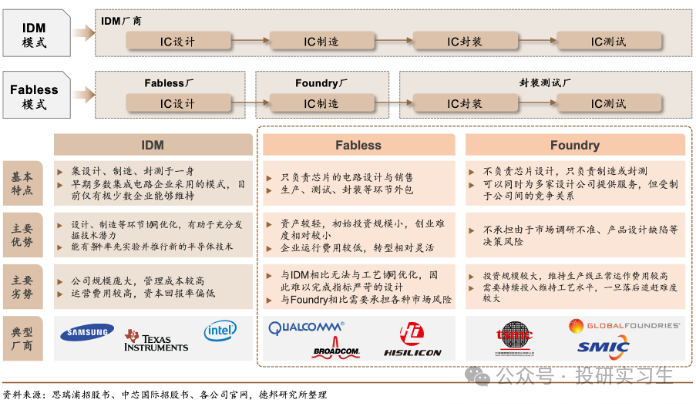
由于全球化的不斷深入,半導體產業發生了多次區域轉移,分工不斷細化。可以將半導體的生產分為四個主要步驟:設計、制造、封裝、測試。在傳統的垂直整合制造商模式(IDM,即自己完成設計、制造、封裝測試等所有環節)基礎上誕生了著名的Fabless+Foundry模式,Fabless廠商是以美國為主的負責設計,而Foundry則是以中國臺灣為主的負責制造的廠商。兩種模式各有利弊,不過這屬于半導體產業鏈范疇的討論,我們在此不做贅述。
半導體產品可以分為集成電路(芯片)、分立器件、光電器件和傳感器,其中芯片進一步分為數字芯片和模擬芯片,數字芯片下還有邏輯芯片、微處理器和存儲芯片三類。我們所說到的算力芯片或AI芯片實際上指的都是邏輯芯片,廣義上可以是所有采用邏輯門的大規模集成電路,包括以 CPU、GPU 為代表的通用計算芯片、專用芯片(ASIC)和 FPGA,狹義上,AI芯片指針對大量數據進行訓練和推理設計的芯片。

CPU
CPU是中央處理器(Central Processing Unit),是計算機的運算核心和控制核心。CPU包括運算器(算術邏輯單元ALU、累加寄存器、 數據緩沖寄存器、狀態條件寄存器)、控制器(指令寄存器IR、程序計數器PC、地址寄存器、 指令譯碼器ID、時序、總線、中斷邏輯控制)、高速緩沖存儲器(Cache)、內部數據總線 、控制總線、狀態總線及輸入/輸出接口等模塊。
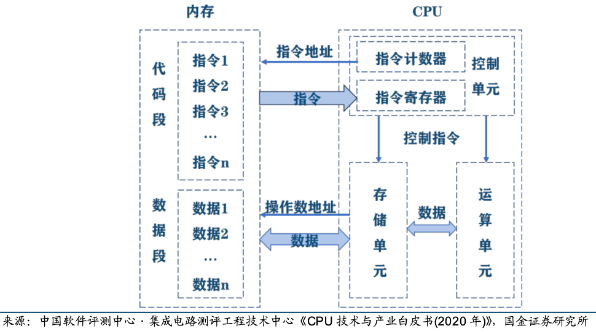
CPU 的主要功能是解釋計算機指令以及處理計算機軟件中的數據,其運行程序時主要包括一下5個步驟:1)指令寄存器(IR)從存儲器或高速緩沖存儲器中獲取指令;2)指令譯碼器(ID)對指令進行譯碼,并將指令分解成一系列簡單的微操作;3)譯碼后的微操作通過控制單元發送給CPU內的運算器執行數學運算和邏輯決策,;4)執行某些指令時需要讀取或寫入數據到主存儲器,地址寄存器用于確定存儲器中數據的位置,而數據經過內部總線傳輸;5)指令執行完成后,結果會被寫回到CPU的寄存器或存儲器中,供后續指令使用。
我們可以將這個流程類比自己做數學題時的場景,從最開始的讀題(獲取指令)、審題(指令譯碼)到一步一步計算答案(執行運算),再將答案寫在草稿紙上(存儲結果)用于下一小問。對于CPU來說這整個過程是一個連續循環,稱為指令周期,包括獲取指令、譯碼、執行、訪問存儲器和寫回結果的步驟。人們用主頻來衡量以上一個指令周期被執行的速度(CPU性能),主頻是指CPU內部時鐘的頻率,通常以赫茲(Hz)為單位,1赫茲等于每秒鐘一個周期。此外,FLOPS(每秒執行多少浮點運算)也被用于衡量CPU性能。
在CPU的發展歷史中,為了進一步提升它的運算能力人們提出了多線程(Multithreading)和多核(Multi-core)的設計方法。多線程指的是程序可以同時執行多個任務,也就是電腦可以同時做不同的事。例如,一個線程可以處理用戶輸入,同時另一個線程可以執行后臺計算,還有一個線程可以處理網絡通信。即使一個線程被阻塞,其他線程仍然可以繼續工作,從而提高了整體的效率和程序的響應性。多核則是增加CPU內的處理單元,使CPU可以并行處理多個指令流。
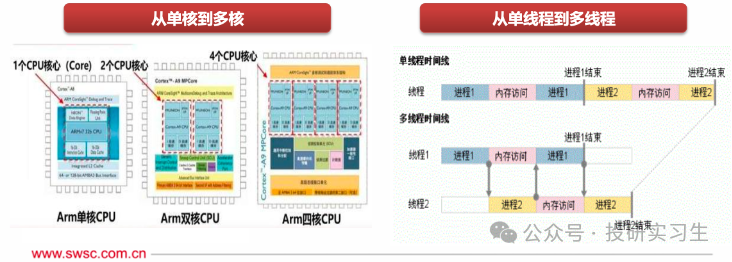
可以按指令集和應用領域對CPU進行分門別類,指令集是 CPU 所執行指令的二進制編碼方法,是軟件和硬件的接口規范。按照指令集可分為 CISC復雜指令集和 RISC精簡指令集兩大類,在上一篇文章中做過詳細介紹,這里不再贅述。CPU 按照下游應用領域還可分為通用微處理器(MPU, Micro Processor Unit)和微控制器(MCU, Micro Controller Unit),MPU便是我們熟悉的應用于服務器、桌面(臺式機/筆記本)、超級計算機等中的CPU。MCU是用于控制類應用的低性能、低功耗CPU。MCU的主頻一般低于 100MHz,一般是用在智能制造、工業控制、智能家居、遙控器、汽車電子、機器手臂的控制等。

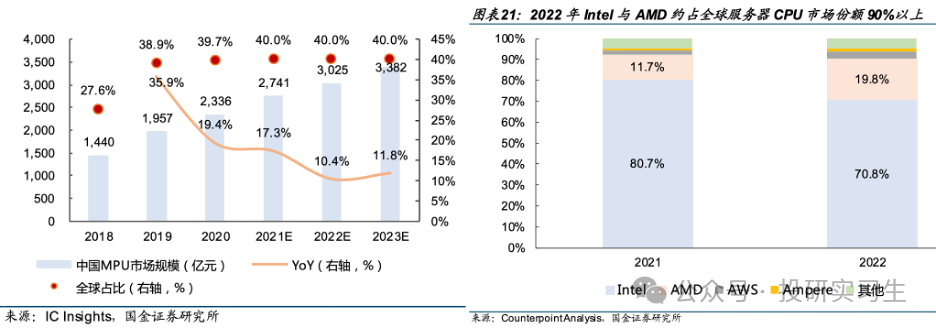
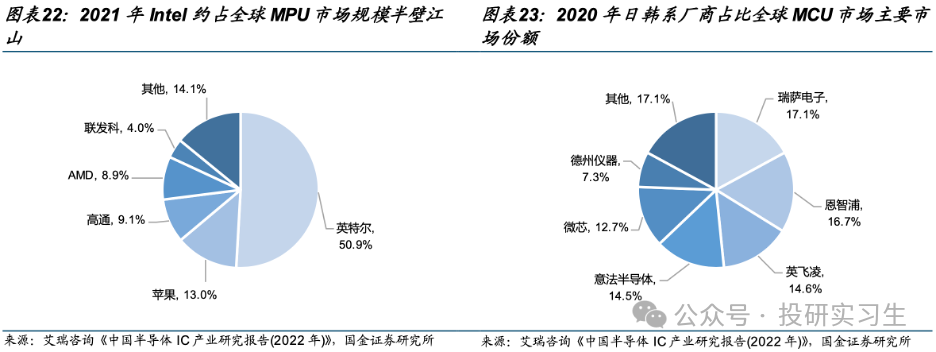
從競爭格局上看,英特爾和AMD占據了大部分市場份額,其中英特爾作為CPU的締造者擁有絕對主導地位。從服務器CPU角度看,2022年英特爾與AMD合計占到全球90%的市場份額,不過近兩年AMD不斷搶占英特爾份額。從MPU整體上看,英特爾占據半壁江山,移動設備端蘋果和高通分別擁有13%和9%的份額。從MCU上看則是日韓系廠商份額較多。
GPU
作為通用處理器,以前幾乎所有的計算任務都由CPU處理,不過到了八十年代末九十年代初,越來越多的圖形渲染處理需求催生了GPU的誕生,黃仁勛正是在這一時期創立的英偉達,專注于GPU的研發與制造。
GPU是圖形處理器(Graphic Processing Unit),又稱為顯示芯片(顯卡),最初是作為專用處理器來輔助CPU進行圖像和圖形相關運算工作的。從結構上來說,CPU的設計是低延遲的串行計算模式,擁有少數強大的ALU算數邏輯單元高效的挨個完成每個任務。而GPU側重于并行計算(Parallel Processing),擁有大量的ALU可以同時處理大規模的簡單計算。簡單來說,CPU的工作模式好比一位博士單獨去解一道復雜的高數題,而GPU則如同一百名高中生一起計算加減、乘除法。
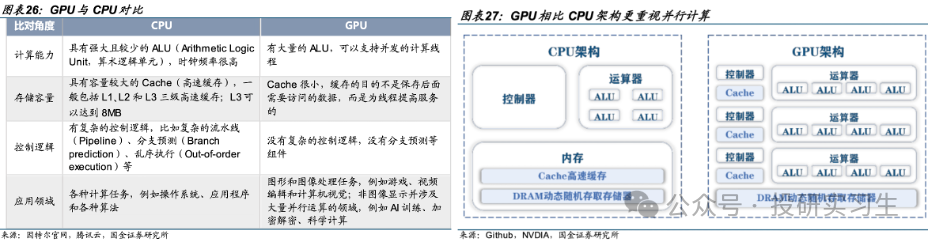
CPU已經如此強大了,為什么還需要GPU呢,或者說為什么在圖形處理和如今的人工智能浪潮下為什么GPU這個以前CPU的小弟成為了王者呢?首先在圖像處理領域,圖片是由一個個像素點組成的,比如一張1080p的圖片實際上是由1920x1080= 207萬像素點組成,但是每個像素點的計算并不復雜。由CPU加載圖片時是一個一個的單獨運算每個像素點,而使用GPU的話則是并行計算,由多個ALU同時處理每個像素點,從而實現快速處理全部像素點。

在人工智能大模型中同理,大模型可以有各種不同結構,但其背后的本質都是基于神經網絡的深度學習,它的核心運算需求并不高,主要就是累加和累乘的運算,但是由于模型參數巨大、網絡層數復雜,因此需要運用大規模并行計算,這也就是為什么GPU如今獨領風騷。

由黃仁勛于1993年創立的英偉達可謂是GPU的奠定者和締造者,1999年英偉達推出了被譽為世界上第一款真正的GPU的GeForce 256,并憑借此產品獲得巨大成功。然而,作為專用處理器,傳統 GPU 應用局限于圖形渲染計算,在面對非圖像并涉及大量并行運算的領域,比如 AI、加密解密、科學計算等則更需要通用計算能力。為了提高GPU的通用性,英偉達于2006年推出的CUDA開發環境構造了其強大的生態護城河,自此GPGPU(General Purpose GPU)時代開啟。

CUDA(Compute Unified Device Architecture,統一計算設備架構) 可以讓開發者能夠用類似 C 語言的方式編寫程序,讓 GPU 來處理計算密集型任務。簡單來說,CUDA平臺是英偉達提供給開發者的編程工具,包含了一系列工具函數,有各種功能,同時CUDA可以讓開發者調用成千上萬的 GPU 核心同時工作,進一步提高計算速度。隨著時間推移,CUDA被應用在包括物理化學、生物醫藥、人工智能等眾多行業領域,其開發者生態也不斷豐富,同時由于CUDA只適用于英偉達的GPU,它成為了英偉達主導GPU的殺手锏。類似于CUDA的還有針對AMD的GPU使用的ATIStream,以及兩款開源平臺ROCm和OpenCL,這兩者可實現不同生態GPU的相互遷移。
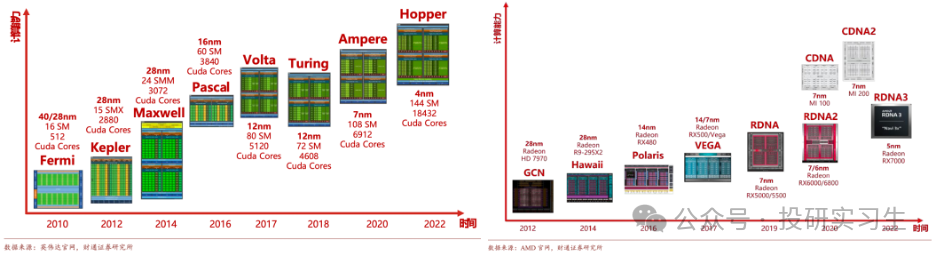
在GPU發展歷史上,除了CUDA平臺外,微架構迭代與芯片制程升級是單卡GPU性能提升的關鍵途徑。GPU 的微架構是用以實現指令執行的硬件電路結構設計,不同的微架構設計會對 GPU 的性能產生決定性的影響。以英偉達為例,從最初 Fermi 架構到現在的Hopper架構和最新的Blackwell架構,英偉達平均買兩年更新一次架構,每一階段都在性能和能效比方面得到提升,同時引入了新技術,如 CUDA、GPU Boost、RT 核心和 Tensor 核心等,作為行業第二的AMD也緊跟英偉達更新其微架構。
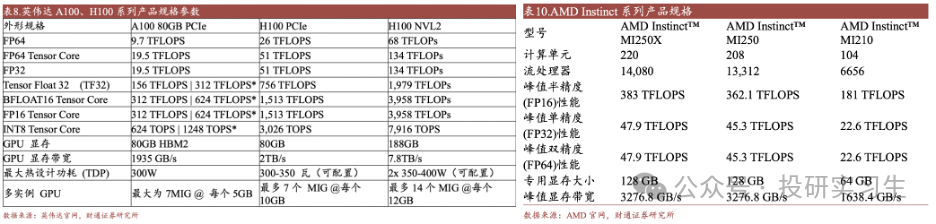
對比當前主流的頂級GPU英偉達H100和AMD的MI250X可以看出,二者在硬件層面上的差距并不大,真正能夠使英偉達維持80%市占率達的其實是軟件層面的CUDA平臺,由于多年以來眾多主要開發者都使用基于CUDA的英偉達GPU,其形成的廣泛生態和粘性極大的增加了進行更換廠商的總成本,同時這也給遠在大洋彼岸的國內廠商追趕英偉達造成更大的挑戰。因此英偉達不僅僅是我們印象中的賣芯片的硬件公司,它也是一家強大的軟件公司。
ASIC
在GPGPU時代GPU已經具備了類似CPU的通用性,專用處理器中還剩下ASIC和FPGA兩款。ASIC (Application Specific Integrated Circuit,專用集成電路)是為了某種特定需求而專門定制的芯片。ASIC 的計算能力和計算效率都可以根據算法需要進行定制,因此與通用芯片相比具有體積小、功耗低、計算性能高等優勢。但是缺點也很明顯,ASIC只能針對特定的幾個應用場景,算法和流程變更可能導致 ASIC 無法滿足業務需求。
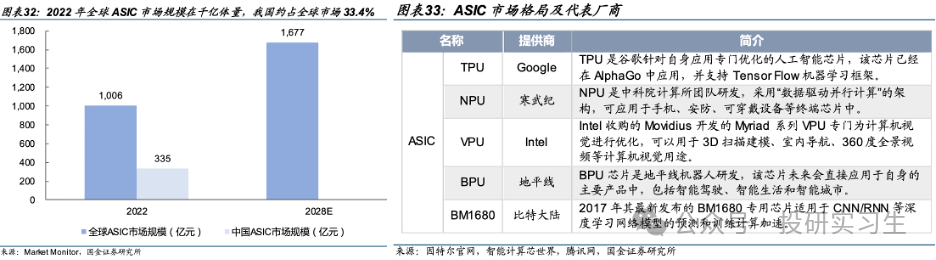
由于目前對于芯片的需求爆發主要還是來自AI領域,針對AI計算場景設計的ASIC從性能、能效、成本均極大的超越了通用芯片,是GPU的潛在競爭對手。目前全球 ASIC 市場并未形成明顯的頭部廠商,由于 ASIC 需要定制且開發周期長,大多為云計算/互聯網等大廠有資金與實力進行研發,且僅當其定制化應用場景市場空間足夠大時量產ASIC才能實現豐厚利潤。目前市場上主流 ASIC 有 TPU 芯片、NPU 芯片、VPU 芯片以及 BPU 芯片,它們分別是由谷歌、寒武紀、英特爾以及地平線公司設計生產,預計未來將有更多諸如微軟、亞馬遜、百度、阿里等云計算巨頭加入定制自家的ASIC。
FPGA
除了ASIC外,FPGA (Field-Programmable Gate Array,現場可編程門陣列)也是一種專用芯片,其最大特點是現場可編程性。CPU、GPU以及各類 ASIC 芯片在制造完成后,其芯片的功能就已被固定,而 FPGA 芯片在制造完成后,用戶可以根據自己的實際需要,將自己設計的電路通過 FPGA 芯片公司提供的專用 EDA 軟件對 FPGA 芯片進行功能配置,從而將空白的 FPGA 芯片轉化為具有特定功能的集成電路芯片。FPGA 芯片由可編程的邏輯單元(Logic Cell,LC)、輸入輸出單元(Input Output Block,IO)和開關連線陣列(Switch Box,SB)三個部分構成。
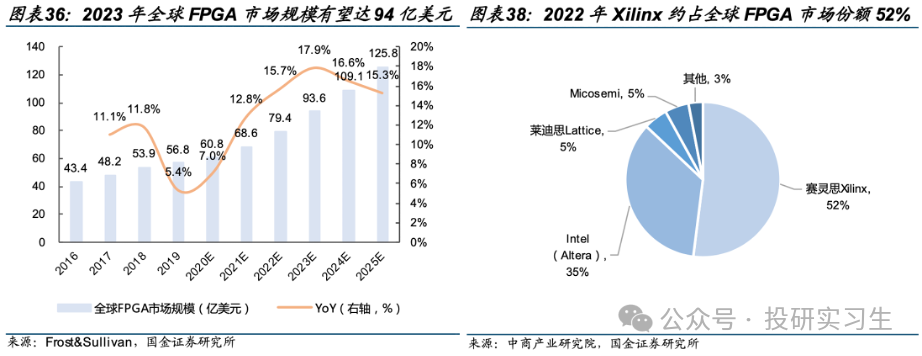
2023 年全球 FPGA 市場規模有望達 94 億美元,且保持15%左右的增速。從競爭格局上看,被AMD收購的賽靈思Xilinx 約占全球 FPGA 市場份額 52%,Intel 旗下 Altera 約占 35%。
中美情況對比
前面詳細介紹了主要四種處理器芯片的功能、市場空間和競爭格局,接下來進一步說說中國和美國在AI芯片上的差距。首先,無論是站在國家安全、自主可控的角度還是受美國卡脖子技術禁令影響的角度,國產自研替代雖然艱難但一定是未來最可靠甚至是唯一的出路。
從算力、算法和應用層出發,中國廠商和美國同行相比都有一定差距。在算力端存在芯片性能及生態差距,在芯片的生產端核心環節如芯片的設計、流片等也均由海外主導;在算法端,海外在基礎研究方面較為領先,如谷歌發布底層架構 Transformer ;應用端,海外頭部應用多已成為行業標準,擁有較為良好的用戶基礎,有助于 LLM+產品的快速落地,如辦公領域的微軟 Office 產品。
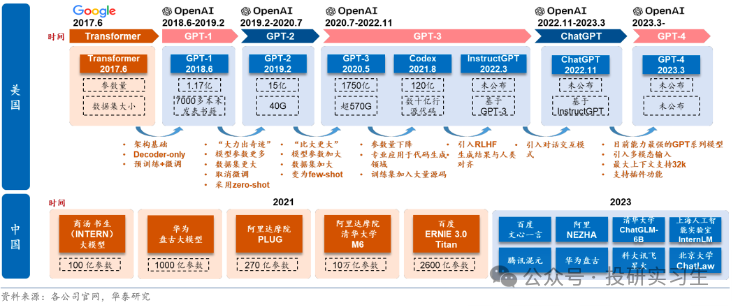
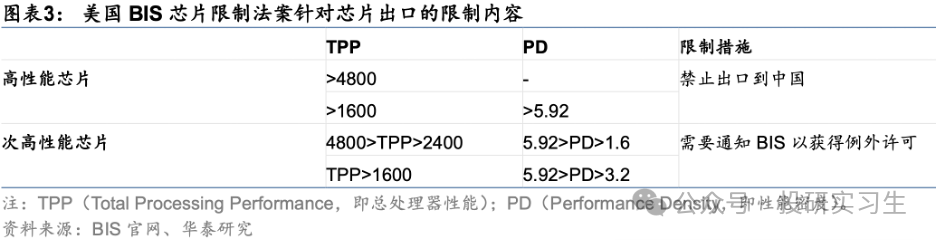
不過算法和應用端的差距不大,而算力層面的差距是最關鍵的。一方面算力端的核心環節均受海外主導,很難繞開,而且海外頭部算力廠商圍繞自身產品形成了包含應用、算法的生態壁壘,更加難以突破。另一方面,算力處于基礎支撐地位,直接影響模型的落地和應用的推廣進度。美國政府為了限制中國AI的發展更是出臺政策禁止了美國企業將高端芯片賣給國內企業,自2022年以來美國已多次出臺出口限制法案,限制力度逐步提升。去年10月的最新法案中以總處理性能 TPP(Total Processing Performance,即計算速度*字節長度)和性能密度 PD(Performance Density,即每平方毫米的 TPP)為要求,TPP>4800 的芯片、TPP>1600 且 PD>5.92 的芯片屬于高性能芯片,不再被允許出口。
在這個背景下,我們來對比下中美主要AI芯片發展進度。國內的算力產業整體上可分為三大體系:以鯤鵬+昇騰為核心芯片的Arm服務器華為系,以海光為核心芯片、中科曙光為整機廠的x86服務器中科院系,以飛騰為核心芯片、中國長城為整機廠的Arm服務器中電子系。
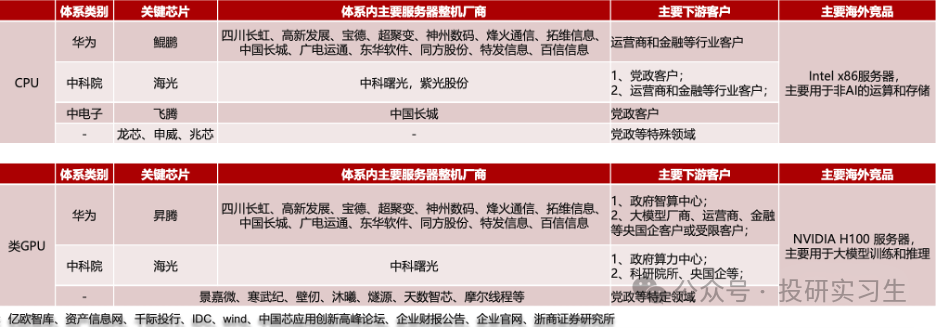
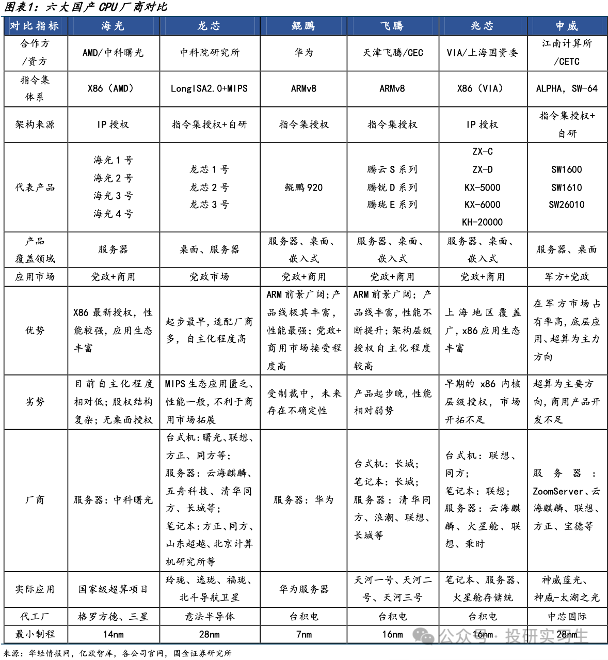
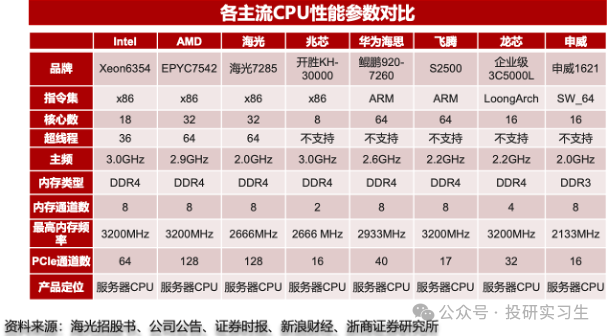
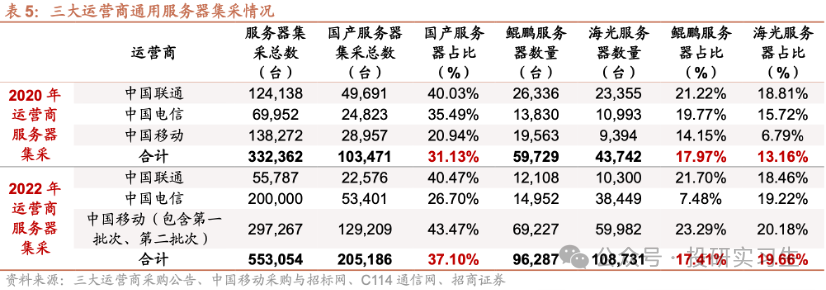
在CPU領域,國內企業經過多年發展與積累形成了海光信息、龍芯中科、華為、飛騰、兆芯和申威六大廠商齊頭并進的局面,其中華為和海光性能最好,可對標英特爾與AMD的頂級CPU產品,飛騰和申威的芯片則主要應用于國家超算中心如天河、神威。從三大運營商的采購情況也可以看出,2022年采購中國產CPU服務器占比達到37%,其中海光占比19.66%,華為鯤鵬占比17.41%。
GPU方面,由于GPU領域英偉達占據絕對領導地位,國內廠商目前在硬件和生態上都有較大差距。國內GPU最強的是華為,昇騰310為推理芯片,昇騰910為訓練芯片。昇騰 910 芯片采用7nm制程,FP16 算力達到 320TFLOPS、INT8 算力達到 640TOPS,與 NVIDIA A100 80GB 版本旗鼓相當,組網集群上限達到18000張(英偉達A100為16000,H100為50000)。不過與英偉達H100和今年剛剛發布的B100相比存在1-2代差距。
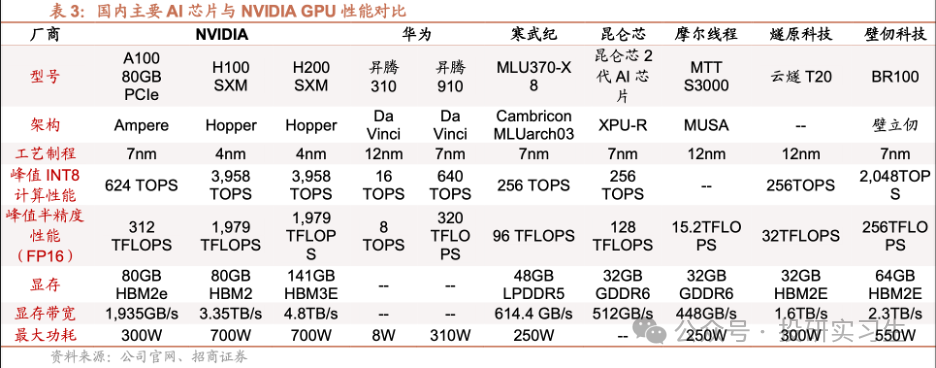
此外,海光信息基于GPGPU架構推出DCU深算產品,軟件生態完善兼容通用的“類 CUDA”環境,旗下產品DCUZ100 的關鍵性能指標實現FP6410.8TFlops,顯存32GB HBM2,也可對標英偉達A100和AMD的MI100單卡性能。

發展趨勢
最后來說說AI芯片的發展趨勢有哪些,由于未來應用于大模型推理的需求將遠超過訓練需求,AI芯片也朝著更高性能、更低功耗和更靠近邊緣和端側發展。在性能提升方面,單個處理器層面的提升主要來自過去幾十年都遵循的摩爾定律,也就是芯片制程的提升,以及設計層面的微架構迭代。然而當晶體管大小接近 1nm 左右時,與 0.1nm 的原子直徑尺寸量級接近,量子隧穿引起的晶體管漏電效應將愈發明顯,以至于影響芯片正常工作。微架構方面,英偉達于今年三月GTC大會上最新推出的Blackwell架構也展現出架構更新放緩的趨勢。
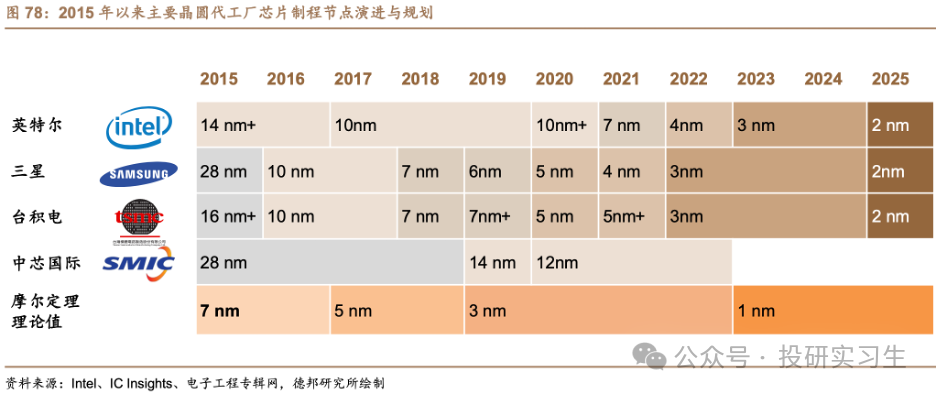
在這個背景下,單張GPU的性能已接近瓶頸,因此未來的發展必然聚焦于多張卡的聯合上。在芯片封裝層面,通過Chiplet和CoWos等先進封裝技術將多顆芯片與內存等模塊封裝在一起。在系統層面,通過卡間互聯、服務器間互聯以及數據中心集群間互聯等方式集合更多的GPU。
此外,隨著越來越多的推理需求出現,AI芯片也將越來越多的從云端轉移到邊緣和端側,也會出現更多低功耗的端側芯片,比如現在的自動駕駛、AI PC和AI手機等概念,都需要將算力直接部署到汽車、電腦或手機上。
-
處理器
+關注
關注
68文章
19829瀏覽量
233862 -
半導體
+關注
關注
335文章
28687瀏覽量
233881 -
光電器件
+關注
關注
1文章
180瀏覽量
18986 -
人工智能
+關注
關注
1804文章
48820瀏覽量
247246 -
GPU芯片
+關注
關注
1文章
305瀏覽量
6140
原文標題:為什么是GPU?一文深度梳理AI算力芯片
文章出處:【微信號:Rocker-IC,微信公眾號:路科驗證】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
“四算合一”算力平臺,芯片國產化率超九成,兼容8種國產AI芯片
摩爾線程與AI算力平臺AutoDL達成深度合作
大算力芯片的生態突圍與算力革命
DeepSeek推動AI算力需求:800G光模塊的關鍵作用
【一文看懂】什么是端側算力?


算智算中心的算力如何衡量?
AI算力芯片供電電源測試利器:費思低壓大電流系列電子負載






 工商網監
工商網監

評論