 SiMa.ai推出針對Edge AI調整的SoC
SiMa.ai推出針對Edge AI調整的SoC
面臨的主要技術挑戰之一是邊緣計算:如何在資源受限的嵌入式設備上執行計算密集型人工智能任務。在這種追求中,硬件和軟件從根本上相互矛盾,因為設計人員試圖同時平衡低功耗、低成本和高性能。
機器學習硬件初創公司SiMa.ai現在正試圖通過設計“軟件優先”的硬件來應對這一挑戰,以實現前所未有的邊緣AI性能。本周,SiMa.ai發布了他們的新MLSoC平臺,這是一個以ML為中心的SoC,旨在使邊緣AI比以往任何時候都更加直觀和靈活。
在本文中,我們將討論邊緣AI的現狀,以及SiMa.ai的新平臺希望如何解決其一些缺點。
Edge AI的現狀
當談到將AI帶到邊緣時,也被稱為TinyML,這個過程通常非常以硬件為中心。
通常,邊緣AI的挑戰在于設備資源非常有限,RAM、處理能力和電池壽命有限。因此,TinyML的設計過程通常圍繞著將機器學習模型定制為設備的大多數預定硬件功能。
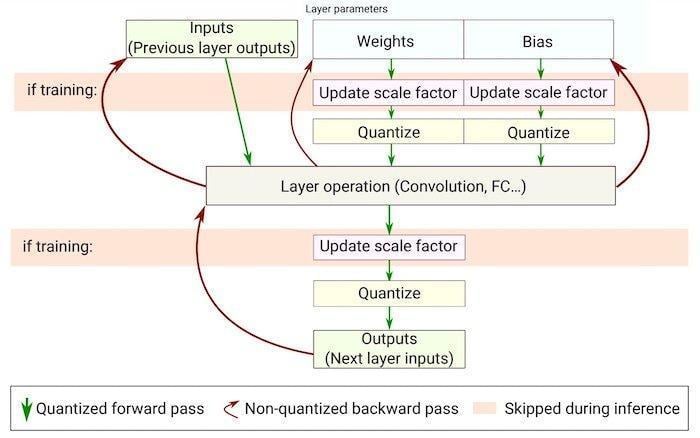
量化感知培訓流程圖。圖片來源:Courtesy of
Novac等人
為此,軟件流程包括獲取給定的機器學習模型,在所需的數據集上對其進行訓練,然后將其縮小以適應邊緣設備的約束。這種模型縮放通常通過量化過程來完成,量化過程是降低模型權重和參數的精度以使它們消耗更少內存的過程。
通過這種方式,TinyML工程師可以采用大型機器學習模型,該模型旨在部署在更強大的設備上,并將其縮小以適應邊緣設備。nbsp;
正如SiMa.ai所看到的,這種工作流程的問題在于,這些模型實際上并不是為邊緣而設計的,而是為邊緣而設計的。這在性能和靈活性方面受到限制,因為模型從未真正針對硬件進行優化,反之亦然。
SiMa的新SoC解決方案
為了解決這個問題,SiMa.ai最近發布了他們的MLSoC平臺,這是一個“軟件優先”的邊緣AI SoC。
MLSoC平臺基于16 nm工藝構建,是一種異構計算片上系統(SoC),集成了許多專用硬件模塊用于AI加速。在這些硬件中,模塊包括SiMa.ai專有的機器學習加速器(MLA)。該公司表示,它以10 TOPS/W的速度為神經網絡計算提供50 TOPS。
SoC的應用處理單元(APU)由四個1.15 GHz Arm Cortex-A65雙線程處理器組成。還有一個視頻編碼器和解碼器模塊以及一個計算機視覺單元(CVU),它由一個四核Synopsys ARC EV 74嵌入式視覺處理器組成。這些模塊由4 MB片內存儲器以及32位LPDDR 4 DRAM接口支持。更多信息可在MLSoC產品簡介中找到。
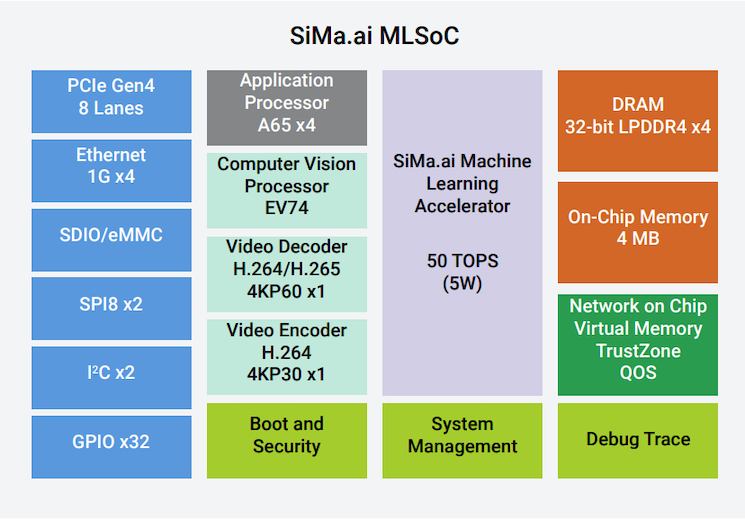
MLSoC的框圖。圖片來源:Courtesy of
SiMa.ai
然而,除了硬件之外,SiMa.ai聲稱其MLSoC平臺是獨一無二的,因為它是與其ML軟件工具鏈共同設計的。具體來說,該公司聲稱其方法包括精心定義的中間表示以及新穎的編譯器優化技術,以支持廣泛的框架和網絡。
這些框架包括TensorFlow,PyTorch和ONNX等熱門框架,同時還聲稱支持超過120個網絡。其想法是,通過使用MLSoC軟件工具鏈,工程師可以開發專門針對MLSoC SoC的ML模型,從而提高設計靈活性、效率和性能。
重新構想TinyML的方法?
總的來說,該公司聲稱,他們的MLSoC平臺現在正在向客戶交付,與同類競爭對手相比,可以在計算機視覺方面提供10倍的性能/功耗解決方案。為了支持這一點,他們聲稱在ResNet-50 v1上具有500 FPS/W的一流DNN推理效率,批量大小為1。nbsp;
憑借其獨特的軟件/硬件兼容性方法,www.example.com希望重新想象業界對TinyML的方法,并借此釋放前所未有的性能和效率。
審核編輯 黃宇
-
soc
+關注
關注
38文章
4161瀏覽量
218162 -
AI
+關注
關注
87文章
30728瀏覽量
268886 -
EDGE
+關注
關注
0文章
181瀏覽量
42648 -
ML
+關注
關注
0文章
149瀏覽量
34642
發布評論請先 登錄
相關推薦
通過無代碼方法開發Edge AI和ML
千芯科技推出了針對芯來RISC-V平臺的AI部署工具包(tinyAI SDK)
音頻處理SoC在500 μW以下運行AI
嵌入式邊緣AI應用開發指南
AI智能呼叫中心
耐能3D AI解決方案亮相CES 2019,并宣布將推出智能家居AI SoC
研華推VEGA-340 Edge AI加速卡,非常適合基于AI的視覺應用
新思科技汽車級解決方案加速MLSoC平臺開發
新思科技宣布與SiMa.ai開展合作
Edge AI在深度學習應用中超越云計算

凌華智能推出全新AI 邊緣服務器MEC-AI7400 (AI Edge Server)系列
AM62A Edge AI零售掃描儀演示:SoC選型和功耗分析






 工商網監
工商網監
評論