") NVIDIA Spectrum-X助力IBM為AI Cloud提供高性能底座
NVIDIA Spectrum-X助力IBM為AI Cloud提供高性能底座
在混合云與 AI 的時(shí)代,企業(yè)和組織需要?jiǎng)?chuàng)建、分析和保存海量的數(shù)據(jù),在分布式的應(yīng)用環(huán)境中會(huì)形成各種各樣的數(shù)據(jù)孤島,導(dǎo)致復(fù)雜系統(tǒng)難以管理,成本不斷增加。為了能夠更快速地從數(shù)據(jù)中獲得所需的洞察力,其底層的信息架構(gòu)必須支持混合云、大數(shù)據(jù)和人工智能(AI)工作負(fù)載以及傳統(tǒng)應(yīng)用,同時(shí)確保安全性、可靠性、數(shù)據(jù)效率和高性能,還需要能夠無(wú)縫擴(kuò)展來(lái)應(yīng)對(duì)非結(jié)構(gòu)化數(shù)據(jù)的飛速增長(zhǎng)。
IBM Storage Scale 作為一種高性能的并行數(shù)據(jù)存儲(chǔ)解決方案,可以幫助用戶(hù)更快速地獲得所需的計(jì)算或分析結(jié)果,管理快速擴(kuò)展的數(shù)據(jù)和基礎(chǔ)架構(gòu),同時(shí)確保數(shù)據(jù)安全性并降低總體存儲(chǔ)成本。
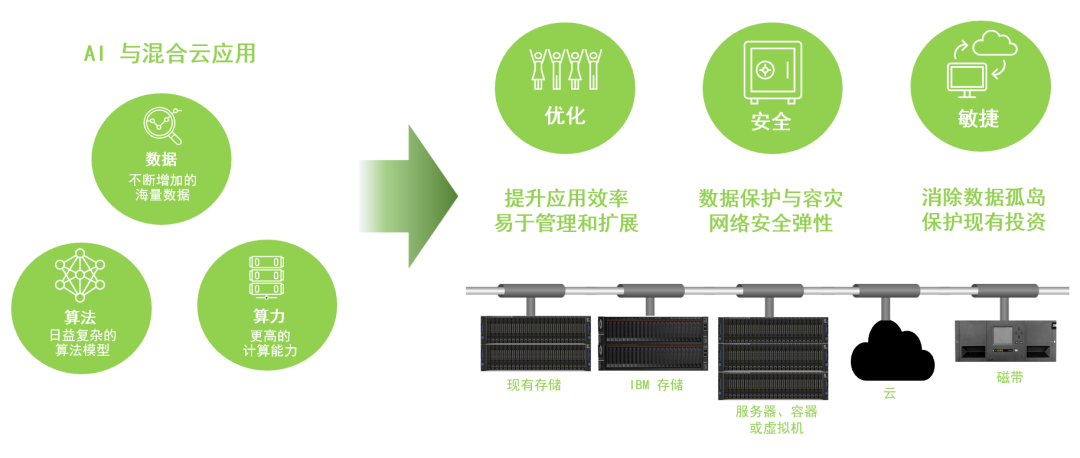
圖1:AI 與混合云對(duì)數(shù)據(jù)存儲(chǔ)的需求
面對(duì)生成式 AI 的爆炸式發(fā)展,GPU 集群的運(yùn)算性能至關(guān)重要,不僅需要更高的 GPU 的計(jì)算能力和更快的存儲(chǔ),同時(shí)需要專(zhuān)用的網(wǎng)絡(luò)基礎(chǔ)設(shè)施來(lái)確保多個(gè)節(jié)點(diǎn)并行的最佳性能。NVIDIA 開(kāi)發(fā)了業(yè)界首款面向 AI 的以太網(wǎng)網(wǎng)絡(luò)平臺(tái) - Spectrum-X ,旨在增強(qiáng) AI 云的性能和效率。Spectrum-X 平臺(tái)的核心是 NVIDIA Spectrum-4 以太網(wǎng)交換機(jī)、NVIDIA BlueField-3 SuperNIC/DPU、NVIDIA DOCA 軟件棧及交換機(jī)軟件棧和 NVIDIA LinkX 高品質(zhì)互連設(shè)備,這種組合構(gòu)成了 AI 加速計(jì)算網(wǎng)絡(luò)架構(gòu)的基礎(chǔ)。NVIDIA 將 BlueField-3 SuperNIC 和 DPU 集成到其面向 AI 訓(xùn)練、推薦及推理等各種系統(tǒng)中,不僅滿(mǎn)足以太網(wǎng)在多租戶(hù)云上的各種需求,同時(shí)保證了 AI 集群最好的運(yùn)算及存儲(chǔ)性能。
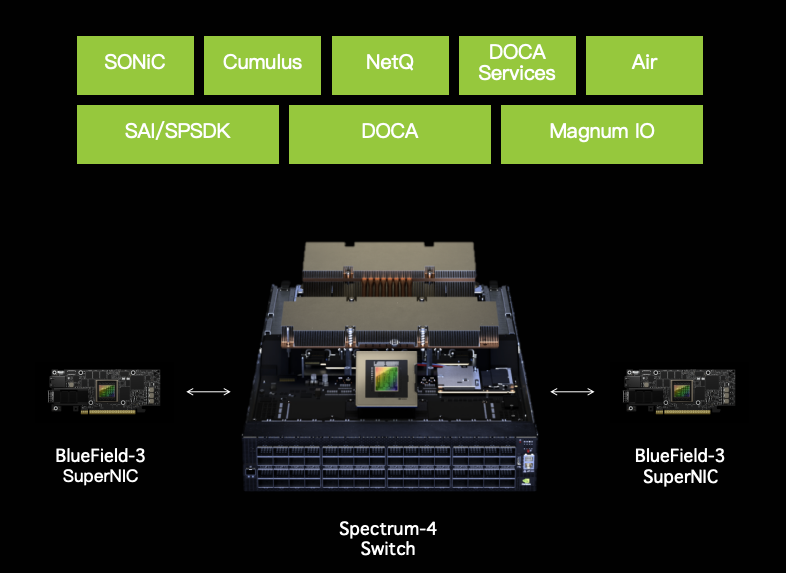
圖2:NVIDIA Spectrum-X 平臺(tái)介紹
在 AI 云存儲(chǔ)平臺(tái)的選擇上,IBM Storage Scale 可提供經(jīng)過(guò)驗(yàn)證的企業(yè)級(jí)數(shù)據(jù)平臺(tái)。IBM Storage Scale 源自 GPFS,有超過(guò) 30 年的研發(fā)歷史,在全球有大量成功部署的經(jīng)驗(yàn),廣泛應(yīng)用在業(yè)界超大規(guī)模和需求嚴(yán)苛的應(yīng)用環(huán)境,包括過(guò)去幾十年間全球性能最強(qiáng)的人工智能和高性能計(jì)算環(huán)境。
為了滿(mǎn)足不同類(lèi)型應(yīng)用的數(shù)據(jù)訪問(wèn)需求,IBM Storage Scale 能夠?qū)⑽募⒋髷?shù)據(jù)分析、對(duì)象和容器應(yīng)用的接口集成到一個(gè)統(tǒng)一的向外擴(kuò)展的存儲(chǔ)解決方案之中。它可為所有這些數(shù)據(jù)提供一個(gè)統(tǒng)一的命名空間,實(shí)現(xiàn)協(xié)議互通,并通過(guò)直觀的圖形用戶(hù)界面(GUI)提供單點(diǎn)管理。通過(guò)對(duì)最終用戶(hù)透明的存儲(chǔ)策略,可對(duì)數(shù)據(jù)進(jìn)行分層、壓縮或遷移到磁帶或云端,以降低成本;數(shù)據(jù)還可以分層到高性能數(shù)據(jù)存儲(chǔ)介質(zhì),包括服務(wù)器緩存,進(jìn)而降低延遲、提升性能。遠(yuǎn)程站點(diǎn)的智能數(shù)據(jù)緩存可確保借助活動(dòng)文件管理(AFM)功能以本地讀/寫(xiě)性能在地域分散的各個(gè)站點(diǎn)之間提供數(shù)據(jù),不需要復(fù)制全部數(shù)據(jù),減少數(shù)據(jù)傳遞的網(wǎng)絡(luò)開(kāi)銷(xiāo)。
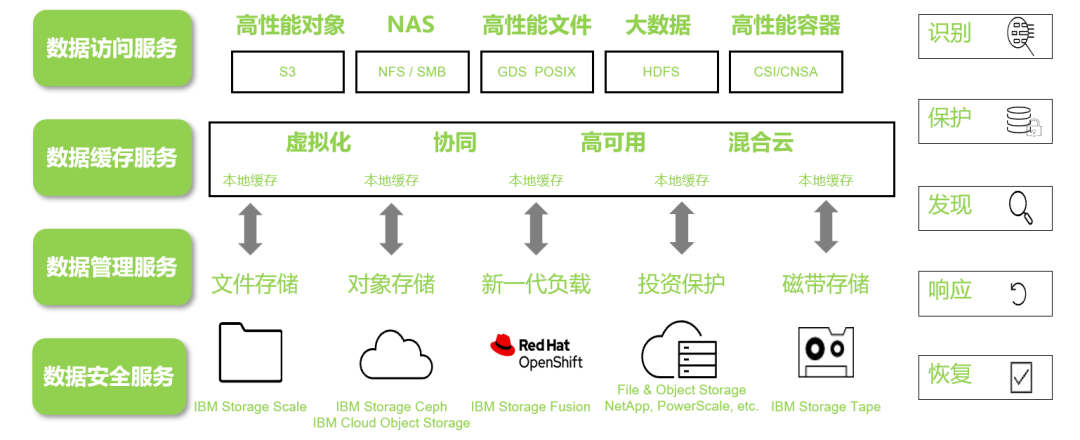
圖3:IBM Storage Scale 概覽
對(duì)于 AI 集群應(yīng)用來(lái)說(shuō),為了滿(mǎn)足不斷提高的算力和各種基礎(chǔ)模型對(duì)更大參數(shù)規(guī)模的需要,也需要更高速的數(shù)據(jù)訪問(wèn)能力,避免因?yàn)榇媪Σ蛔銓?dǎo)致的低效 I/O使得 GPU 無(wú)用武之地。由多臺(tái)服務(wù)組成的 GPU 服務(wù)器集群需要數(shù)百 GBps 到數(shù) TBps 的高速數(shù)據(jù)存儲(chǔ)才能滿(mǎn)足其對(duì)存力的需求;此外,為了提升 GPU 的應(yīng)用效率,NVIDIA 開(kāi)發(fā)了 GPUDirect Storage 技術(shù),可以通過(guò) RDMA 高速網(wǎng)絡(luò)直接將數(shù)據(jù)從外部存儲(chǔ)傳輸至 GPU 顯存上,能有效減輕 CPU I/O 的瓶頸,提升 GPU 訪問(wèn)數(shù)據(jù)的帶寬并大幅縮短通信延遲;此外,對(duì)于 AI 應(yīng)用來(lái)說(shuō),從數(shù)據(jù)攝入到生產(chǎn)推理,每個(gè)環(huán)節(jié)都需要利用不同工具實(shí)現(xiàn)海量數(shù)據(jù)處理,并且這是一個(gè)不斷重復(fù)的流程。用戶(hù)需要構(gòu)建的端到端的高速數(shù)據(jù)管道,簡(jiǎn)化流程并實(shí)現(xiàn)數(shù)據(jù)安全、高效的流動(dòng)。
經(jīng)過(guò)充分優(yōu)化的 IBM Storage Scale System 可以充分發(fā)揮并行架構(gòu)和高速網(wǎng)絡(luò)的優(yōu)勢(shì),加速各種 AI 工作負(fù)載應(yīng)用,具備以下優(yōu)勢(shì):
極致性能:提供業(yè)界領(lǐng)先的文件讀寫(xiě)性能,目前單個(gè) SSS 模塊可提供超過(guò) 310 GB/s 的文件訪問(wèn)帶寬和 13M IOPS,可擴(kuò)展到上千個(gè)模塊滿(mǎn)足更高性能和容量的需求,同時(shí)內(nèi)置的 Decluster RAID 技術(shù)可以最小化各種硬件故障對(duì)性能的影響;
認(rèn)證支持:IBM Storage Scale 是 NVIDIA 官方認(rèn)證支持 GPUDirect Storage 的存儲(chǔ)技術(shù),能夠避免 GPU 的 I/O 瓶頸,幫助用戶(hù)加速各種 AI 業(yè)務(wù) 和數(shù)據(jù)密集型應(yīng)用,同時(shí)大幅度提升寶貴 GPU 資源的利用率;
全局訪問(wèn):IBM Storage Scale 提供的全局?jǐn)?shù)據(jù)平臺(tái)訪問(wèn)能力,支持多種應(yīng)用訪問(wèn)協(xié)議互通(如對(duì)象、容器、HDFS 等等)和不同存儲(chǔ)環(huán)境,實(shí)現(xiàn)數(shù)據(jù)的整合和調(diào)度,結(jié)合其它存儲(chǔ)設(shè)備(包括磁帶)實(shí)現(xiàn)分層存儲(chǔ),降低數(shù)據(jù)總體擁有成本,提升端到端的數(shù)據(jù)處理效率;
安全彈性:提供端到端的全面數(shù)據(jù)安全彈性解決方案,包括完善的數(shù)據(jù)高可用和容災(zāi)解決方案,以及用于實(shí)現(xiàn)網(wǎng)絡(luò)安全彈性的 Safeguarded Copy 和安全日志審計(jì)能力。
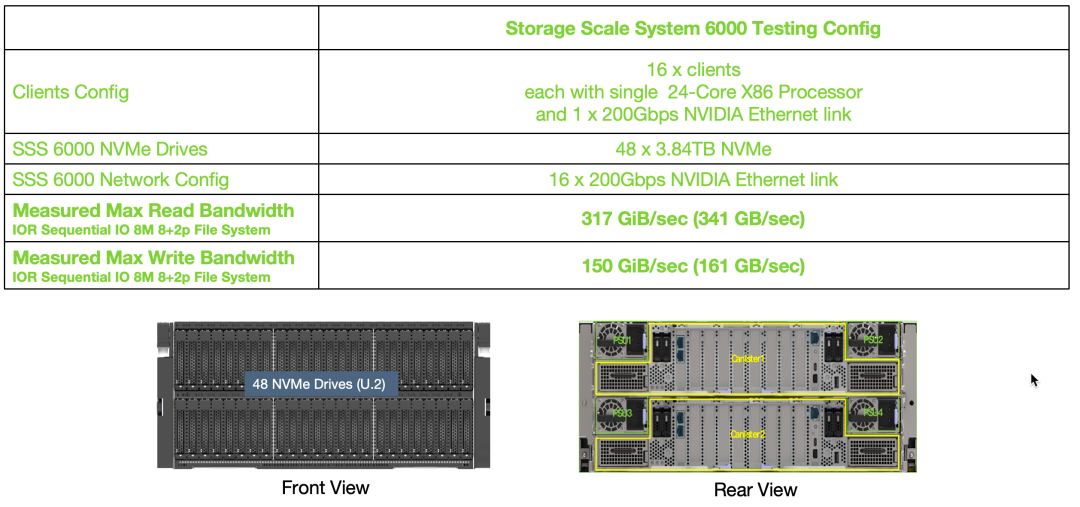
圖4:?jiǎn)蝹€(gè) IBM SSS 6000 模塊性能實(shí)測(cè)結(jié)果
為了充分發(fā)揮 IBM Storage Scale 高帶寬、低時(shí)延的優(yōu)勢(shì),通常用戶(hù)會(huì)采用支持 RDMA 的網(wǎng)絡(luò)來(lái)進(jìn)行數(shù)據(jù)訪問(wèn),包括 InfiniBand 網(wǎng)絡(luò)和 RoCE(RDMA over Converged Ethernet)網(wǎng)絡(luò)。NVIDIA Spectrum-X 平臺(tái)具備 NVIDIA 獨(dú)有的 Adapt Routing 等專(zhuān)門(mén)面向 AI 的以太網(wǎng)網(wǎng)絡(luò)優(yōu)化技術(shù),可以在大規(guī)模集群中充分發(fā)揮出存儲(chǔ)系統(tǒng)的高帶寬的性能,為客戶(hù)打造高性能且穩(wěn)定運(yùn)行的 AI 集群提供穩(wěn)定的網(wǎng)絡(luò)基礎(chǔ)。
以 AI 集群的數(shù)據(jù)業(yè)務(wù)流為例,數(shù)據(jù)從 GPU 顯存到網(wǎng)絡(luò)存儲(chǔ)服務(wù)器的網(wǎng)絡(luò)路徑會(huì)經(jīng)過(guò) GPU 集群上存儲(chǔ)平面的 Leaf 交換機(jī)到 Spine 交換機(jī),再到 Leaf 交換機(jī),最后連接到存儲(chǔ)服務(wù)器;AI 存儲(chǔ)業(yè)務(wù)是典型的大象流,傳統(tǒng)的以太網(wǎng)交換機(jī)是基于流為粒度的負(fù)載分擔(dān),不難看出 GPU 集群內(nèi)的 Leaf 層交換機(jī)和 Spine 交換機(jī)之間會(huì)有多條等價(jià)路徑,包括 Leaf 到不同 Spine 的等價(jià)路徑,也包括同一 Leaf 到 Spine 內(nèi)多條鏈路的等價(jià)路徑,但是由于寫(xiě)數(shù)據(jù)流 Hash key 值高度一致,導(dǎo)致,在 Leaf 層交換機(jī)不能將流充分的分配到不同的等價(jià)路徑上,這樣的技術(shù)對(duì)于目前大規(guī)模 AI 集群內(nèi)的存儲(chǔ)業(yè)務(wù)來(lái)說(shuō)會(huì)影響存儲(chǔ)數(shù)據(jù)流的傳輸帶寬,即便存儲(chǔ)系統(tǒng)本身性能強(qiáng)大,也會(huì)因?yàn)榫W(wǎng)絡(luò)成為瓶頸而不能發(fā)揮出應(yīng)有的性能;而當(dāng)采用 Adapt Routing 技術(shù)之后,由于是基于數(shù)據(jù)包為粒度的轉(zhuǎn)發(fā)機(jī)制,無(wú)論存儲(chǔ)數(shù)據(jù)流的數(shù)量大小,都可以均勻的將流量轉(zhuǎn)發(fā)到所有等價(jià)路徑上,從而消除網(wǎng)絡(luò)上的瓶頸,最大化的利用存儲(chǔ)系統(tǒng)的性能,提升存儲(chǔ)帶寬、降低存儲(chǔ)平面時(shí)延。這對(duì)基于以太網(wǎng)絡(luò)構(gòu)建 AI 集群極為重要。
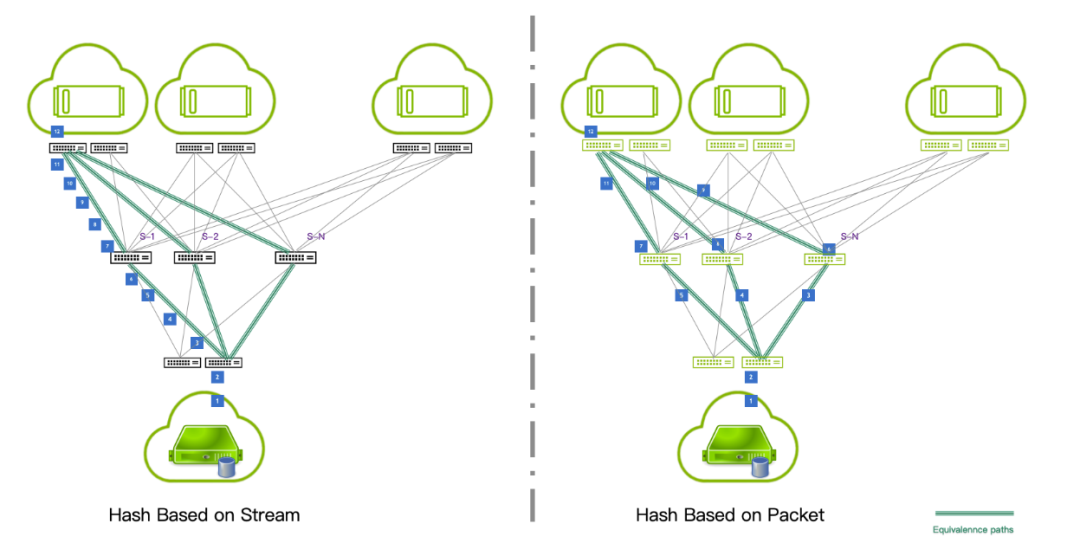
圖5:開(kāi)啟 AR 和關(guān)閉 AR 的轉(zhuǎn)發(fā)路徑對(duì)比
為了展示 Spectrum-X 平臺(tái)在存儲(chǔ)領(lǐng)域內(nèi)的實(shí)際效果,如下圖所示,搭建一個(gè) Demo 環(huán)境用于模擬 AI 存儲(chǔ)應(yīng)用的典型場(chǎng)景,采用 4 臺(tái)搭載 NVIDIA BlueField-3 的服務(wù)器,兩臺(tái)計(jì)算節(jié)點(diǎn)配備 BlueField-3 DPU,兩臺(tái)存儲(chǔ)節(jié)點(diǎn)配備 BlueField-3 SuperNIC,采用 6 臺(tái)搭載 Spectrum-4 交換芯片的 SN5600 交換機(jī)組成典型的兩層 Spine-Leaf 胖樹(shù)網(wǎng)絡(luò);并且,BlueField DPU 和 SuperNIC 均為為雙端口卡,每個(gè)端口連接到不同的 Leaf 交換機(jī)上,保證存儲(chǔ)平面的高可靠,同時(shí)開(kāi)啟端口 Bonding,使得可以最大化利用端口性能。測(cè)試覆蓋 2 打 1 和 2 打 2 兩種場(chǎng)景,構(gòu)造 RDMA 流量進(jìn)行測(cè)試。
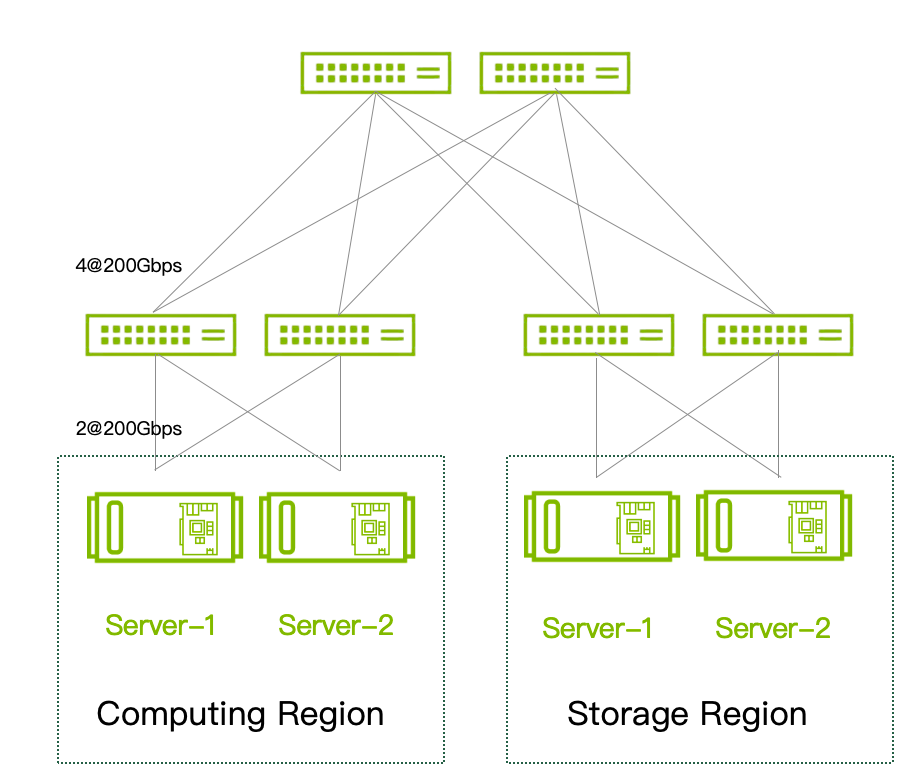
圖6:Spectrum-X 存儲(chǔ) AR 測(cè)試 Topo
在 2 打 1 和 2 打 2 的場(chǎng)景下,兩個(gè)計(jì)算節(jié)點(diǎn)同時(shí)發(fā)送流量給一個(gè)或 2 個(gè)存儲(chǔ)節(jié)點(diǎn),模擬典型的存儲(chǔ)寫(xiě)場(chǎng)景,對(duì)交換網(wǎng)絡(luò)的影響。在測(cè)試過(guò)程中,分別開(kāi)啟 Adapt Routing 和關(guān)閉 Adapt Routing,收集接受端網(wǎng)絡(luò)帶寬,用于對(duì)比性能差異,測(cè)試如數(shù)據(jù)下圖所示,可以清楚看到,開(kāi)啟 Adapt Routing 之后無(wú)論是 2 打 1,還是 2 打 2 場(chǎng)景,接受端網(wǎng)絡(luò)帶寬都已經(jīng)接近物理帶寬 95% 以上。在沒(méi)有開(kāi)啟 Adapt Routing 測(cè)試用例,流量在交換機(jī)之間網(wǎng)絡(luò)帶寬利用率大幅下降,最終測(cè)試的帶寬不足開(kāi)啟 Adapt Routing 的一半。從而可以看出,采用了 Adapt Routing 技術(shù)的 Spectrum-X 平臺(tái)可以有效的解決存儲(chǔ)網(wǎng)絡(luò)內(nèi)帶寬瓶頸,充分發(fā)揮存儲(chǔ)系統(tǒng)的性能,從而提升 AI 集群整體的效能。
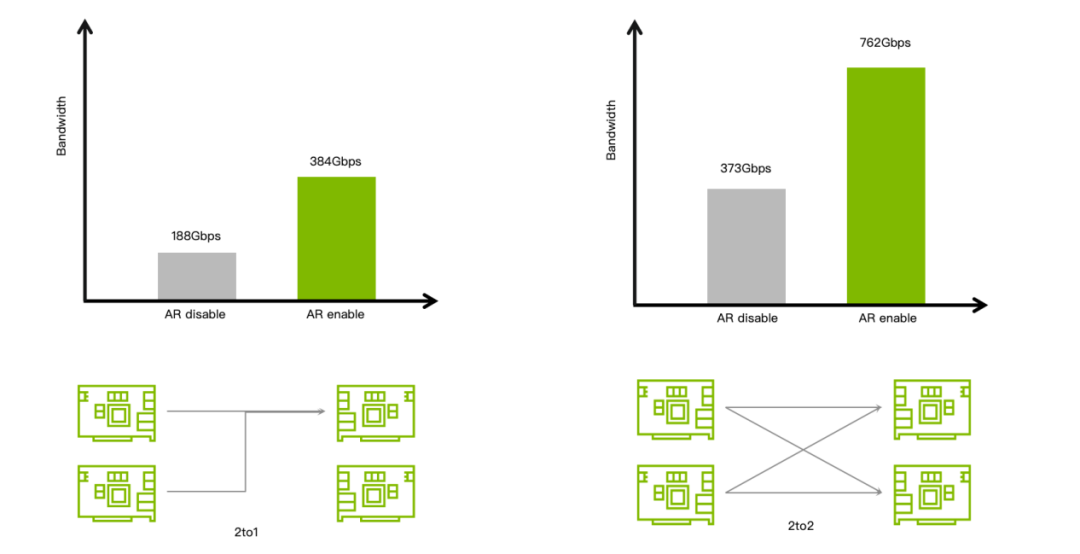
圖7:2 打 1 和 2 打 2 場(chǎng)景下開(kāi)啟 Adapt Routing
和 關(guān)閉 Adapt Routing 的帶寬對(duì)比
通過(guò)和 NVIDIA 網(wǎng)絡(luò)團(tuán)隊(duì)的合作,采用 IBM Storage Scale 和 NVIDIA Spectrum-X 平臺(tái)實(shí)現(xiàn)軟件定義的數(shù)據(jù)基礎(chǔ)架構(gòu),使得搭建在 Spectrum-X 平臺(tái)上 IBM 的 Storage Scale 不僅可以面向云上應(yīng)用提供基于以太網(wǎng)存儲(chǔ)生態(tài)的多種服務(wù),同時(shí)也可以大幅提升存儲(chǔ)的性能,發(fā)揮出 IBM 的 Storage Scale 高吞吐大帶寬的性能優(yōu)勢(shì),滿(mǎn)足 AI 時(shí)代云上高性能存儲(chǔ)數(shù)據(jù)的要求。解決新一代以數(shù)據(jù)為中心的基礎(chǔ)設(shè)施所面臨的挑戰(zhàn)和技術(shù)瓶頸,為 AI 云應(yīng)用提供高性能的底座,幫助客戶(hù)在混合云和 AI 時(shí)代實(shí)現(xiàn)競(jìng)爭(zhēng)優(yōu)勢(shì)。
審核編輯:劉清
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4978瀏覽量
102988 -
以太網(wǎng)交換機(jī)
+關(guān)注
關(guān)注
0文章
124瀏覽量
14240 -
數(shù)據(jù)存儲(chǔ)
+關(guān)注
關(guān)注
5文章
970瀏覽量
50894 -
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238258 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8882瀏覽量
137401
原文標(biāo)題:NVIDIA Spectrum-X 助力 IBM 為 AI Cloud 提供高性能底座
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
IBM與AMD攜手部署MI300X加速器,強(qiáng)化AI與HPC能力
NVIDIA AI助力初創(chuàng)企業(yè)為心理治療師提供AI工具
NVIDIA助力xAI打造全球最大AI超級(jí)計(jì)算機(jī)
NVIDIA Colossus超級(jí)計(jì)算機(jī)集群突破10萬(wàn)顆Hopper GPU
NVIDIA 以太網(wǎng)加速 xAI 構(gòu)建的全球最大 AI 超級(jí)計(jì)算機(jī)

NVIDIA新增生成式AI就緒系統(tǒng)認(rèn)證類(lèi)別
應(yīng)用NVIDIA Spectrum-X網(wǎng)絡(luò)構(gòu)建新型主權(quán)AI云
NVIDIA發(fā)布Omniverse微服務(wù),為物理AI提供超強(qiáng)助力

NVIDIA 通過(guò) Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持
NVIDIA Spectrum-X 以太網(wǎng)網(wǎng)絡(luò)平臺(tái)已被業(yè)界廣泛使用
NVIDIA AI Enterprise榮獲金獎(jiǎng)

借助NVIDIA DOCA 2.7增強(qiáng)AI 云數(shù)據(jù)中心和NVIDIA Spectrum-X
NVIDIA發(fā)布專(zhuān)為大規(guī)模AI量身訂制的全新網(wǎng)絡(luò)交換機(jī)-X800系列
NVIDIA 發(fā)布全新交換機(jī),全面優(yōu)化萬(wàn)億參數(shù)級(jí) GPU 計(jì)算和 AI 基礎(chǔ)設(shè)施

NVIDIA發(fā)布Omniverse Cloud API,為眾多工業(yè)數(shù)字孿生軟件工具提供助力





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論