 K折交叉驗證算法與訓練集
K折交叉驗證算法與訓練集
K折交叉驗證算法通常使用數據集中的大部分數據作為**訓練集**。
K折交叉驗證是一種評估模型性能的統計方法,它涉及將數據集分成K個子集,每個子集大致等大。在K折交叉驗證過程中,其中一個子集被留作測試集,而其余的K-1個子集合并起來形成訓練集。這個過程會重復K次,每次選擇不同的子集作為測試集,以確保每個樣本都有機會作為測試集和訓練集的一部分。這種方法可以有效地評估模型對新數據的泛化能力,因為它考慮了數據集的多個子集。具體步驟如下:
1. 數據劃分:原始數據集被平均分成K個子集。這些子集通常具有相似的數據分布,以確保訓練過程的穩定性。
2. 模型訓練:在每次迭代中,K-1個子集被合并用作訓練集,剩下的一個子集用作驗證集。模型在訓練集上進行訓練。
3. 模型驗證:訓練好的模型在保留的驗證集上進行測試,以評估模型的性能。
4. 性能匯總:重復上述過程K次,每次都使用不同的子集作為驗證集。最后,將所有迭代的結果平均,得到模型的整體性能估計。
5. 模型選擇:如果有多個模型需要比較,可以根據K折交叉驗證的結果選擇表現最佳的模型。
6. 最終測試:一旦選擇了最佳模型,可以在未參與交叉驗證的獨立測試集上進行最終測試,以驗證模型的泛化能力。
總的來說,K折交叉驗證的優勢在于它能夠更全面地利用數據集,每個數據點都有機會參與訓練和測試,從而提高了評估的準確性。此外,它還可以減少由于數據劃分方式不同而導致的評估結果波動。然而,這種方法的缺點是計算成本較高,因為需要多次訓練模型。此外,如果數據集太小,K折交叉驗證可能不夠穩定,因為每次迭代的測試集只有總數據集的一小部分。
審核編輯 黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
算法
+關注
關注
23文章
4607瀏覽量
92840 -
數據集
+關注
關注
4文章
1208瀏覽量
24689
發布評論請先 登錄
相關推薦
第三章:訓練圖像估計光照度算法模型
,我使用圖片的 rgb 數值經過算法**r\*0.2126+g\*0.7152+b\*0.0722**計算亮度。這樣就有了一定數量的數據集。也就有基礎進行后續的訓練和測試了。
【飛凌嵌入式OK3576-C開發板體驗】RKNN神經網絡算法開發環境搭建
download_model.sh 腳本,該腳本
將下載一個可用的 YOLOv5 ONNX 模型,并存放在當前 model 目錄下,參考命令如下:
安裝COCO數據集,在深度神經網絡算法中,模型的訓練離不開大量的數據
發表于 10-10 09:28
pycharm怎么訓練數據集
在本文中,我們將介紹如何在PyCharm中訓練數據集。PyCharm是一款流行的Python集成開發環境,提供了許多用于數據科學和機器學習的工具。 1. 安裝PyCharm和相關庫 首先,確保你已經
機器學習中的交叉驗證方法
在機器學習中,交叉驗證(Cross-Validation)是一種重要的評估方法,它通過將數據集分割成多個部分來評估模型的性能,從而避免過擬合或欠擬合問題,并幫助選擇最優的超參數。本文將詳細探討幾種
如何理解機器學習中的訓練集、驗證集和測試集
理解機器學習中的訓練集、驗證集和測試集,是掌握機器學習核心概念和流程的重要一步。這三者不僅構成了模型學習與評估的基礎框架,還直接關系到模型性
神經網絡如何用無監督算法訓練
標記數據的處理尤為有效,能夠充分利用互聯網上的海量數據資源。以下將詳細探討神經網絡如何用無監督算法進行訓練,包括常見的無監督學習算法、訓練過程、應用及挑戰。
人臉識別模型訓練失敗原因有哪些
人臉識別模型訓練失敗的原因有很多,以下是一些常見的原因及其解決方案: 數據集質量問題 數據集是訓練人臉識別模型的基礎。如果數據集存在質量問題
人臉識別模型訓練是什么意思
人臉識別模型訓練是指通過大量的人臉數據,使用機器學習或深度學習算法,訓練出一個能夠識別和分類人臉的模型。這個模型可以應用于各種場景,如安防監控、身份認證、社交媒體等。下面將介紹人臉識別模型訓練
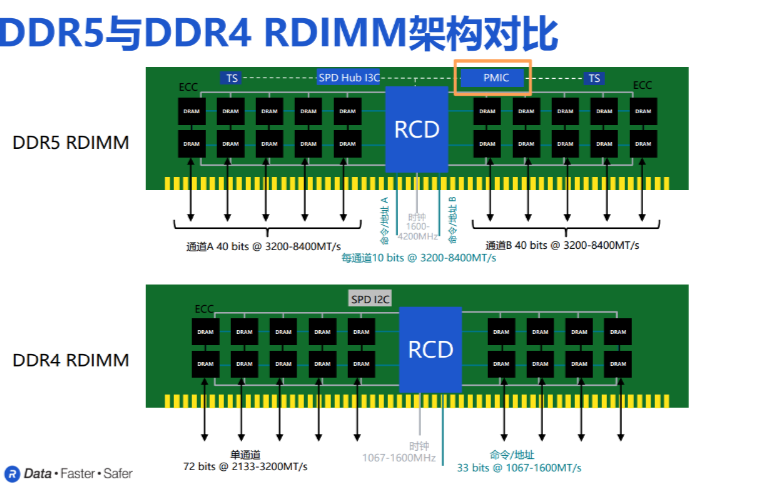
AI訓練狂飆,DDR5集成PMIC護航,內存技術持續助力
電子發燒友網報道(文/黃晶晶)AI訓練數據集正高速增長,與之相適應的不僅是HBM的迭代升級,還有用于處理這些海量數據的服務器內存技術的不斷發展。 ? 以經過簡化的AI訓練管道流程來看,在數據采集進來
PyTorch如何訓練自己的數據集
PyTorch是一個廣泛使用的深度學習框架,它以其靈活性、易用性和強大的動態圖特性而聞名。在訓練深度學習模型時,數據集是不可或缺的組成部分。然而,很多時候,我們可能需要使用自己的數據集而不是現成
【基于存內計算芯片開發板驗證語音識別】訓練手冊
本教程展現語音識別算法在WTM2101開發板上從訓練到部署的全流程,包括實驗環境搭建,語音數據集以及算法模型轉換燒錄。

Kaggle知識點:訓練神經網絡的7個技巧
科學神經網絡模型使用隨機梯度下降進行訓練,模型權重使用反向傳播算法進行更新。通過訓練神經網絡模型解決的優化問題非常具有挑戰性,盡管這些算法在實踐中表現出色,但不能保證它們會及時收斂到一






 工商網監
工商網監
評論