 深度學習編譯工具鏈中的核心——圖優化
深度學習編譯工具鏈中的核心——圖優化
圖優化
圖優化的概念:
深度神經網絡模型可以看做由多個算子連接而成的有向無環圖,圖中每個算子代表一類操作(如乘法、卷積),連接各個算子的邊表示數據流動。在部署深度神經網絡的過程中,為了適應硬件平臺的優化、硬件本身支持的算子等,需要調整優化網絡中使用的算子或算子組合,這就是深度學習編譯工具鏈中的核心——圖優化。
圖優化是指對深度學習模型的計算圖進行分析和優化的過程,通過替換子圖(算子)為在推理平臺上性能更佳的另一個等價子圖、或優化數據流動,來提高模型推理的性能。圖優化的出現很大程度上是因為算法開發人員不熟悉硬件,在算法層面上可以靈活表達的一種計算方式,在硬件底層和推理方式上可能存在顯著的性能差異[1]。
為了更好的理解圖優化,我們需要先了解幾個圖相關的基本概念。
(1)節點(Vertex):圖的重要概念,也是圖的基本單位,可以代表網絡中的一個實體;
(2)邊(Edge):圖的重要概念,是連接兩個節點的線,可以是有向的(箭頭指向一個方向)或無向的。邊可以表示頂點之間的關系,如距離、相似性等;
(3)權重(Weights):邊的屬性,表示從一個節點到另一個節點的“成本”(如距離、時間或其他資源消耗);
(4)路徑(Path):節點的序列,其中任意相鄰的節點都通過圖中的邊相連。
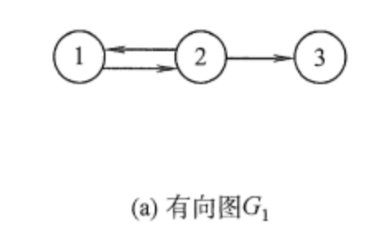
圖 1 圖的基本概念
基于這些基本的概念,我們可以將優化問題引入到圖中來,比如最短路徑問題、最小生成樹問題、網絡流問題、匹配問題等等;為了解決這些優化問題,我們也提出了一系列優化算法,比如Dijkstra算法、Kruskal算法、Ford-Fulkerson算法等等。
圖優化的分類:
圖優化問題通常根據解空間的連續性可分為“組合優化問題”和“連續優化問題”,其中前者的解空間是離散的,后者的解空間是連續的。
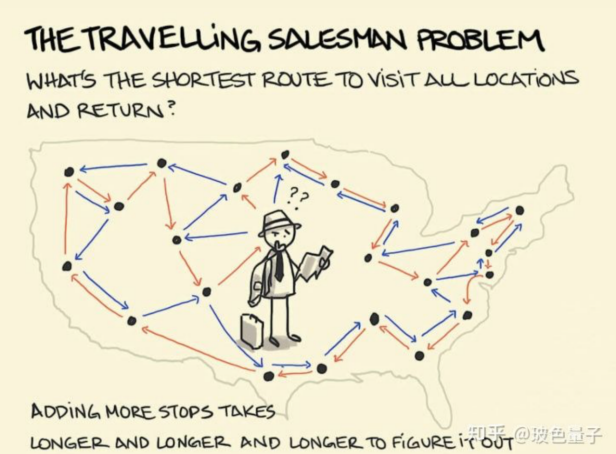
圖 2 組合優化問題之“旅行商問題”[2]
(1)組合優化問題
組合優化問題涉及到在一個有限的、離散的可能解集合中尋找最優解的問題。這類問題的特點是解空間通常由一組離散的選擇構成,解決問題的關鍵在于如何從這些離散的選擇中找到滿足約束條件的最優組合。
i.旅行商問題(TSP):旅行商問題要求找到一條經過圖中每個頂點恰好一次并返回起點的最短可能路徑。這是組合優化中的一個典型問題。
ii.圖著色問題:給定一個圖,目標是使用最少的顏色給圖中的每個頂點著色,使得任何兩個相鄰的頂點顏色不同。這是一個經典的NP難(NP-hard)問題。
(2)連續優化問題
與組合優化不同,連續優化問題的解空間是連續的。這意味著問題的變量可以在某個連續的范圍內取值。連續優化問題在工程、經濟學、物理學等多個領域都有廣泛應用。
i.最小二乘問題:在統計學和數據分析中,最小二乘問題是一種常見的連續優化問題,目標是找到一組參數,使得模型預測值和實際觀測值之間的誤差平方和最小。
ii.線性規劃問題:雖然線性規劃問題的解可能是離散的,但大多數情況下它被視為連續優化問題,因為問題的變量可以在連續范圍內取值。線性規劃問題的目標是在滿足一組線性約束的條件下,最大化或最小化一個線性目標函數。
綜上所述,在圖優化的背景下,組合優化問題通常涉及到圖的結構和圖上的離散決策,例如路徑選擇、網絡設計、資源分配等。而連續優化問題可能涉及到圖的邊權重的連續調整,或者在圖表示的某種物理系統中尋找最優的連續狀態。
圖優化的策略:
傳統意義上,圖優化包含的具體策略有:
算子融合,將多個操作融合為一個復合操作,減少內存訪問次數和中間數據的存儲需求;
常量折疊,在編譯時期預先確定結果的表達式,減少運行時的計算量;
內存復用,識別和優化計算圖中的內存使用,減少內存分配和釋放操作;
數據布局轉換,根據硬件特性調整數據的存儲格式,提高內存訪問效率;
算子集并行化,識別可以并行執行的操作,利用硬件處理單元的并行計算能力;
子圖替換/合并,如圖3所示,將計算圖中的某些算子替換為在轉為硬件優化的版本或效率更高的實現方式。
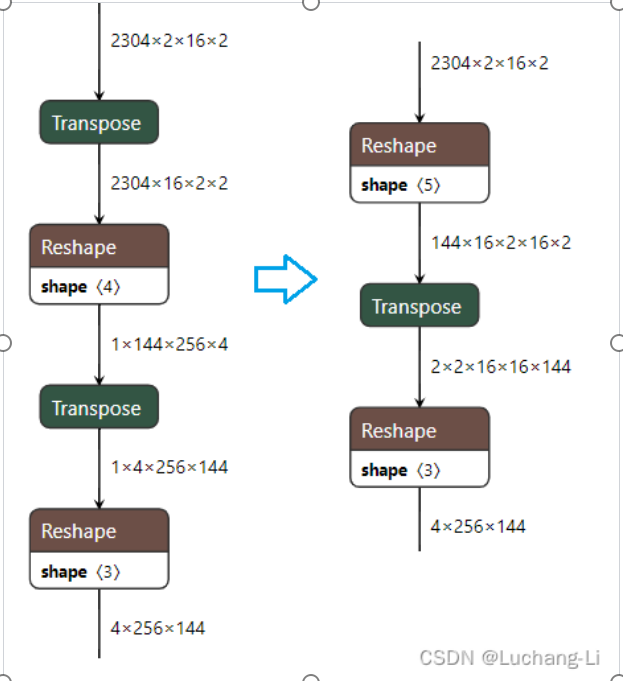
圖3 深度神經網絡模型中的子圖合并示意圖
對于采用存算一體架構設計的硬件而言,圖優化需要特別考慮減少數據移動。具體到圖優化策略中,考慮到存算一體加速乘累加的特點及硬件資源,主要考慮的圖優化策略有:
(1)子圖替換/合并,由于存算一體架構芯片支持的加速算子類型有限,如果深度學習模型中使用了不受支持的算子,則必須被替換;
(2)數據局部性優化,確保負責計算卷積的存算一體核心所存儲的權重在一次計算中不需要重新寫入,依靠數據流動到存儲不同權重的核心進行計算,同時確立統一的數據存儲格式,避免計算過程中為對其存儲數據付出額外的時間。
圖優化的應用場景:
圖優化的應用場景主要體現在優化神經網絡以匹配硬件或適應需求。圖優化針對特定硬件優化神經網絡,減少模型的硬件需求、使用針對硬件優化的算子,以在終端設備部署神經網絡模型;針對CPU、GPU、FPGA等不同平臺進行特定優化,保證模型的可移植性。圖優化針對特定需求,優化模型吞吐量,提升云端模型服務單位時間可處理的訪問次數;降低模型處理的延時,以更快速地處理高分辨率視頻、滿足音頻處理的實時性需求。
工具鏈的圖優化
圖優化和其他網絡優化方法共同支持深度學習模型的開發、訓練、優化、部署和執行過程,是深度學習工具鏈的重要組成部分。下面我們將從文獻研究和企業產品兩個方面介紹工具鏈圖優化的發展現狀。
1.文獻研究相關:
圖優化有許多經典算法,以下列舉了幾個經典算法及其參考文獻,這些圖優化經典算法為工具鏈的圖優化提供了具體的思路與方案。
(1)Dijkstra算法(最短路徑問題):用于尋找圖中某一節點到其他所有節點的最短路徑,特別適用于帶權重的有向圖和無向圖[3]。
(2)Kruskal算法(最小生成樹問題):該算法用于在一個加權連通無向圖中尋找最小生成樹,即找到一個邊的子集,使得這些邊構成的樹包括圖中的所有節點,并且樹的總權值盡可能小[4]。
(3)Ford-Fulkerson算法(最大流問題):該算法用于計算網絡流中的最大流,通過不斷尋找增廣路徑來增加從源點到匯點的流量,直到無法再增加為止[5]。
(4)Hungarian算法(二分圖最大匹配問題):該算法用于解決二分圖的最大匹配問題,特別是在工作分配等應用中,尋找最優匹配方式,使總成本最低[6]。
2.企業產品相關:
(1)英偉達(NVIDIA)[7]
i.產品與技術:
英偉達是全球領先的 GPU 龍頭廠商,所生產的GPU被廣泛應用于圖計算,尤其是在需要大量并行處理的場景中。CUDA(Compute Unified Device Architecture)是NVIDIA推出的一個并行計算平臺和編程模型,它允許軟件開發者和軟件工程師使用C語言等高級編程語言來編寫程序。
ii.圖優化工具鏈:
NVIDIA提供了CUDA圖分析庫(cuGraph),這是一個基于GPU加速的圖分析算法庫,旨在處理大規模圖形數據。cuGraph提供了一系列優化的圖算法,包括最短路徑、PageRank、個性化PageRank、最大流和最小割等,為工具鏈的圖優化提供新的思路。通過利用GPU的并行處理能力,cuGraph能夠顯著加速圖計算任務。
(2)谷歌(Google)
i.產品與技術:
谷歌開發了TPU(Tensor Processing Unit),專門為深度學習應用設計,其高效的矩陣運算能力也可以被應用于圖計算場景,尤其是在圖神經網絡(GNN)等領域。
ii.圖優化工具鏈:
TensorFlow是Google開發的一個開源機器學習框架,它支持廣泛的機器學習任務,包括圖計算。TensorFlow可以利用TPU進行加速,從而提高圖計算的效率。此外,Google也在研究如何優化圖算法的執行,如圖4所示,為GraphX的架構圖,通過GraphX在圖頂點信息和邊信息存儲上進行優化,使得圖計算框架性能得到較大提升,接近或到達 GraphLab 等專業圖計算平臺的性能,可以在其大數據處理工具Apache Spark上進行圖處理[8]。
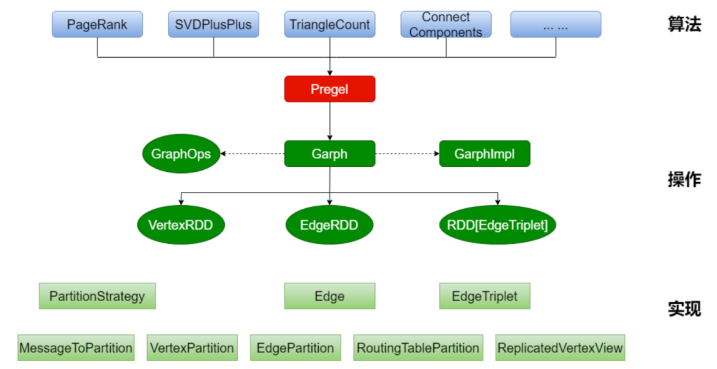
圖 4 GraphX架構圖[8]
(3)Graphcore[9]
i.產品與技術:
Graphcore公司專注于為機器學習和AI應用開發創新的處理器,稱為智能處理單元(IPU)。IPU設計目標是提高圖計算的效率,其架構優化了復雜的數據結構處理,特別是圖形數據結構,這使得其非常適合執行圖神經網絡和其他圖計算任務。
ii.圖優化工具鏈:
Graphcore提供了Poplar軟件開發工具鏈,這是一個專為IPU設計的軟件堆棧。Poplar包含了一系列圖計算庫和工具,支持開發者高效地在IPU上實現和運行圖計算任務,從而充分發揮IPU在圖處理上的優勢,專門針對AI和圖計算任務提供了優化的解決方案,為工具鏈的圖優化提供了新的思路。
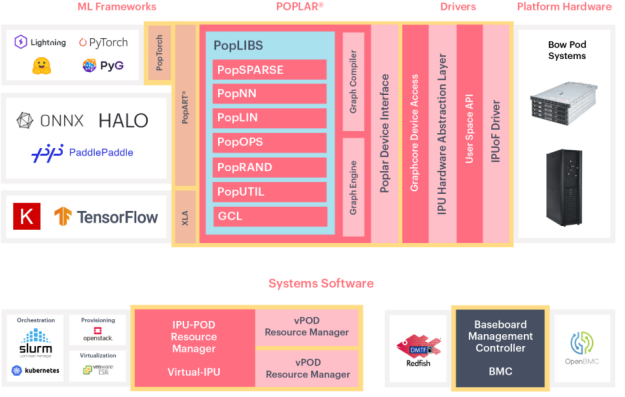
圖 5 Poplar整體架構示意圖[9]
知存科技[10]
i.產品與技術:
知存科技是全球領先的存內計算芯片企業。公司針對AI應用場景,在全球率先商業化量產基于存內計算技術的神經網絡芯片,已有WTM1001、WTM2101、WTM-8等存算一體芯片。
ii.圖優化工具鏈:
如圖6所示,WITIN_MAPPER是知存科技自研的用于神經網絡映射的編譯軟件棧,可以將量化后的神經網絡模型映射到WTM2101 MPU加速器上,是一種包括RISC-V和MPU的完整解決方案。WITIN_MAPPER工具鏈可以完成算子和圖級別的轉換和優化,將預訓練權重編排到存算陣列中,并針對網絡結構和算子給出存算優化方案,同時將不適合MPU運算的算子調度到CPU上運算,實現整網的調度,讓神經網絡開發?員高效快捷的將訓練好的算法運行在WTM2101芯片上,極大縮短模型移植的開發周期并提高算法開發的效率。
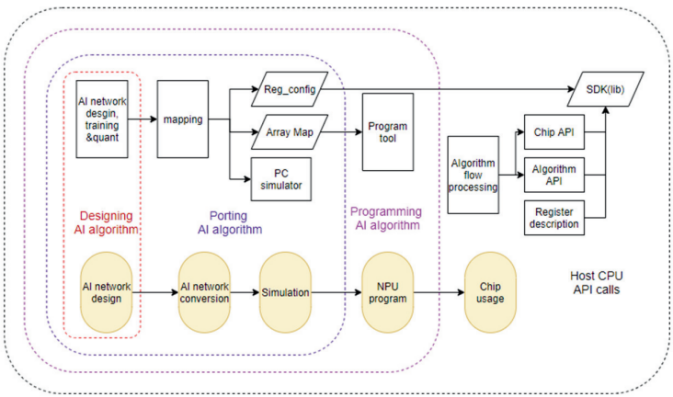
圖 6 WITIN_MAPPER工具鏈軟件架構圖[10]
三.未來展望
當前工具鏈的圖優化研究相對較多,然而存算一體編譯工具鏈的圖優化仍處于起步階段,面臨著許多科學與技術問題。此外,由于存算一體架構規模有限,目前存算一體編譯工具鏈的圖優化主要是針對硬件的適配,通過層間的調度優化,提高硬件的利用率等。為了解決以上問題,科研工作者仍需進行不斷的探索。
同時,隨著人工智能技術的持續發展,神經網絡的參數數量已經從Alexnet的6000萬個增長到OpenAI GPT-3的1750億個,參數量以指數級別增長,人工智能已進入大模型時代,存算一體編譯工具鏈技術的研究也逐漸增多。在大模型時代,存算一體工具鏈的圖優化將會更多地涉及整網的優化調度,從而極大地加快模型的部署與開發,相信更加成熟全面的存算一體工具鏈圖優化技術指日可待!
參考文獻:
[1] Luchang-Li:深度學習性能優化之圖優化(blog.csdn.net).
[2] 知乎@玻色量子.
[3] E. W. (1959). A note on two problems in connexion with graphs. Numerische Mathematik, 1(1), 269-271.
[4]J. B. (1956). On the shortest spanning subtree of a graph and the traveling salesman problem. Proceedings of the American Mathematical Society, 7(1), 48-50.
[5]L. R., & Fulkerson, D. R. (1956). Maximal flow through a network. Canadian Journal of Mathematics, 8, 399-404.
[6]H. W. (1955). The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2(1-2), 83-97.
[7]機器學習和分析 | NVIDIA 開發者.
[8]Spark GraphX_存儲-CSDN博客.
[9]Poplar? 軟件 (graphcore.ai).
[10]WITMEM 2023.ALL RIGHTS,知存科技.
審核編輯 黃宇
-
神經網絡模型
+關注
關注
0文章
24瀏覽量
5605 -
編譯
+關注
關注
0文章
657瀏覽量
32852 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論