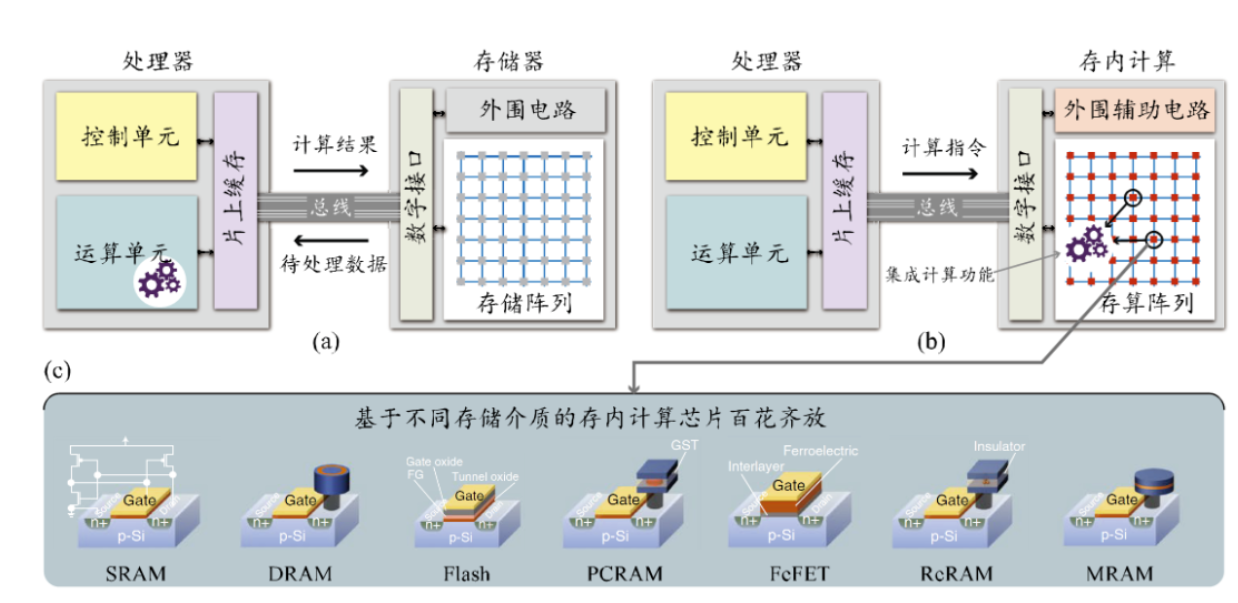
") 存內(nèi)計(jì)算原理分類——數(shù)字存內(nèi)計(jì)算與模擬存內(nèi)計(jì)算
存內(nèi)計(jì)算原理分類——數(shù)字存內(nèi)計(jì)算與模擬存內(nèi)計(jì)算
存算一體作為一種新型架構(gòu),將數(shù)據(jù)存儲(chǔ)和計(jì)算融合一體化,有望突破算力與功耗瓶頸。存內(nèi)計(jì)算可分為模擬和數(shù)字兩大類別。接下來(lái)我們將重點(diǎn)介紹數(shù)字存內(nèi)計(jì)算與模擬存內(nèi)計(jì)算及其優(yōu)劣。
一.數(shù)字存內(nèi)計(jì)算
數(shù)字存內(nèi)計(jì)算利用全數(shù)字電路執(zhí)行計(jì)算,指將數(shù)字邏輯集成到存內(nèi)計(jì)算中,能夠?qū)⒅鹞粩?shù)字乘積累加運(yùn)算直接集成到存儲(chǔ)器陣列。由于數(shù)字存內(nèi)計(jì)算結(jié)構(gòu)上對(duì)乘積累加計(jì)算有良好的支持,在神經(jīng)網(wǎng)絡(luò)需求的運(yùn)算場(chǎng)景中應(yīng)用潛力巨大,如智能手表、藍(lán)牙耳機(jī)中的語(yǔ)音處理,智能手機(jī)中的神經(jīng)網(wǎng)絡(luò)運(yùn)算加速,模型訓(xùn)練加速卡等。
數(shù)字存內(nèi)計(jì)算的主要優(yōu)勢(shì)就是存儲(chǔ)器中權(quán)重可更換、高帶寬以及高魯棒性,但面積和功耗開(kāi)銷都比較大,適用于高精度、對(duì)功耗等要求不高的應(yīng)用場(chǎng)景。
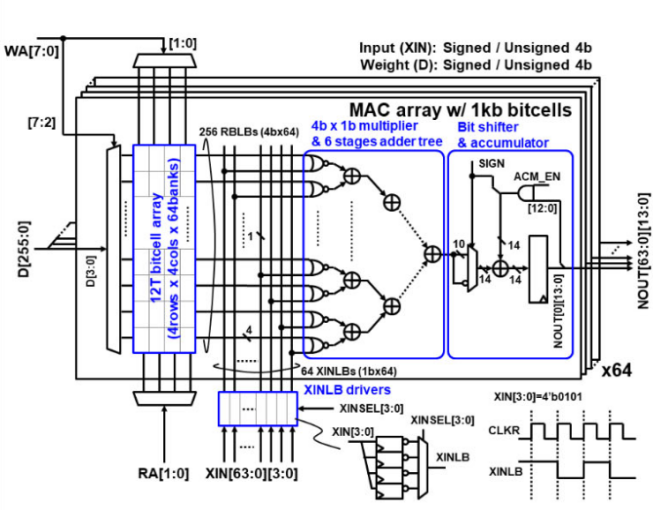
圖 1 數(shù)字存內(nèi)計(jì)算核結(jié)構(gòu)[1]
以ISSCC 2022中的文獻(xiàn)[1]中展示的數(shù)字存內(nèi)計(jì)算總體結(jié)構(gòu)為例,解釋數(shù)字存內(nèi)計(jì)算的運(yùn)算方式,其結(jié)構(gòu)如圖1所示。
該運(yùn)算核結(jié)構(gòu)由64個(gè)如圖中頂層所示的MAC array構(gòu)成。在每一個(gè)MAC array中,存儲(chǔ)器存儲(chǔ)權(quán)重?cái)?shù)據(jù)(圖1中左側(cè)12T bitcell array部分),乘法器計(jì)算輸入數(shù)據(jù)與權(quán)重?cái)?shù)據(jù)的元素乘積結(jié)果,加法器樹計(jì)算元素乘積結(jié)果的和(圖中4b×1b multiplier & 6 stages adder tree部分),移位累加器將加法器樹計(jì)算得到的結(jié)果移位累加(圖中Bit shifter & accumulator部分)。
運(yùn)算核計(jì)算64×1的4bit輸入向量XIN[63:0][3:0]與64×64的4bit權(quán)重矩陣的內(nèi)積結(jié)果,其結(jié)果為一列64×1的14bit向量NOUT[63:0][13:0]。計(jì)算過(guò)程為:權(quán)重矩陣的權(quán)重信息被拆分為64個(gè)64×1的4bit權(quán)重向量存儲(chǔ)在每一層MAC array的存儲(chǔ)器中,寫入過(guò)程受到WA[7:0]信號(hào)控制,每次寫入向量中一個(gè)元素的4bit信息D[4:0],一共64個(gè)MAC array,一次需要寫入D[255:0]。輸入向量受XINSEL[3:0]控制按比特由高到低依次輸入,每個(gè)時(shí)鐘周期計(jì)算一個(gè)輸入比特64 XINLBs與權(quán)重向量256 RBLBs的元素乘積,并求和,將四個(gè)周期的結(jié)果移位累加便得到該MAC array的權(quán)重向量與輸入向量的內(nèi)積,將每層MAC array的結(jié)果組成為一個(gè)向量,即為NOUT[63:0][13:0]。
據(jù)悉已有基于數(shù)字存內(nèi)計(jì)算的產(chǎn)品產(chǎn)出。后摩于2023年5月推出鴻途?H30,該芯片基于SRAM存儲(chǔ)介質(zhì),據(jù)其官網(wǎng)信息,該產(chǎn)品擁有極低的訪存功耗和超高的計(jì)算密度,在Int8數(shù)據(jù)精度條件下,其AI核心IPU能效比高達(dá)15Tops/W,是傳統(tǒng)架構(gòu)芯片的7倍以上,暫未落地到市場(chǎng)化應(yīng)用實(shí)測(cè)性能。
二.模擬存內(nèi)計(jì)算[2]
不同于前述的數(shù)字存內(nèi)計(jì)算,模擬存內(nèi)計(jì)算主要基于物理定律(歐姆定律和基爾霍夫定律),在存算陣列上實(shí)現(xiàn)乘積累加運(yùn)算。對(duì)于模擬存內(nèi)計(jì)算,其存內(nèi)計(jì)算電路的計(jì)算模式通過(guò)定制模擬計(jì)算電路模塊來(lái)實(shí)現(xiàn),通過(guò)這些模擬計(jì)算電路與存儲(chǔ)單元的結(jié)合來(lái)實(shí)現(xiàn)高能效存內(nèi)計(jì)算,一般使用RRAM(阻變隨機(jī)存儲(chǔ)器,又名憶阻器)和Flash(閃存)。
模擬存內(nèi)計(jì)算面積、功耗等開(kāi)銷小,能量效率高,但是缺乏準(zhǔn)確性,適用于需要低功耗、對(duì)精度要求不高的應(yīng)用場(chǎng)景。
下面以RRAM為例,來(lái)描述模擬存內(nèi)計(jì)算的原理。
憶阻器電路可以做成陣列結(jié)構(gòu),如下圖2所示,與矩陣類似,利用其矩陣運(yùn)算能力,可以廣泛應(yīng)用于人工智能推理場(chǎng)景中。在推理過(guò)程中,通過(guò)輸入矢量與模型的參數(shù)(也即權(quán)重)矩陣完成乘加運(yùn)算,便可以得到推理結(jié)果。
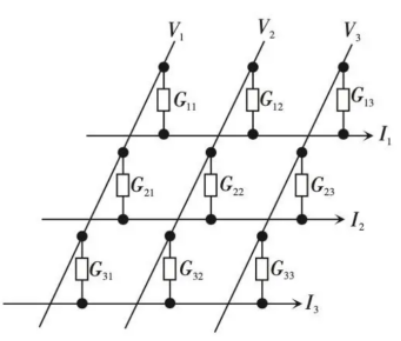
圖 2 3×3交叉陣列的模擬型憶阻器[3]
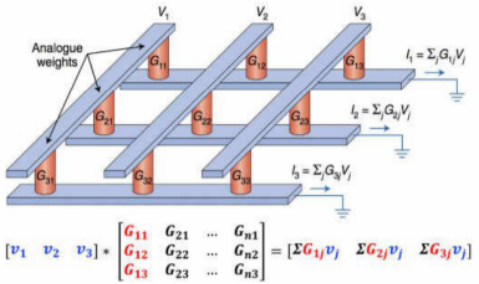
圖 3 交叉陣列進(jìn)行矩陣乘加運(yùn)算示意圖[4]
關(guān)于矩陣乘加運(yùn)算,如上圖3所示,將模型的輸入數(shù)據(jù)設(shè)為矩陣[V],模型的參數(shù)設(shè)為矩陣[G],運(yùn)算后的輸出數(shù)據(jù)設(shè)為矩陣[I]。運(yùn)算前,先將模型參數(shù)矩陣按行列位置存入憶阻器(即[G]),在輸入端給定電壓值來(lái)表示輸入矢量(即[V]),根據(jù)歐姆定律,便可在輸出端得到對(duì)應(yīng)的電流矢量,再根據(jù)基爾霍夫定律將電流相加,即得到輸出結(jié)果(即[I])。此外,多個(gè)存算陣列并行,便可完成多個(gè)矩陣乘加計(jì)算。
目前模擬存內(nèi)計(jì)算研究已經(jīng)有了很多成果。例如,2023年10月,清華錢鶴、吳華強(qiáng)帶領(lǐng)團(tuán)隊(duì)創(chuàng)新設(shè)計(jì)出適用于RRAM存算一體的高效片上學(xué)習(xí)的新型通用算法和架構(gòu)(STELLAR),研制出全球首顆全系統(tǒng)集成的、支持高效片上學(xué)習(xí)的RRAM存算一體芯片,該成果已發(fā)表在《Science》上。此外,基于Flash的模擬存內(nèi)計(jì)算也是研究重點(diǎn)。2022年,國(guó)內(nèi)的知存科技率先量產(chǎn)商用WTM2101芯片,結(jié)合了RISC-V指令集與NOR Flash存內(nèi)計(jì)算陣列,使用特殊的電路設(shè)計(jì)抑制閾值電壓漂移對(duì)計(jì)算精度的影響,可實(shí)現(xiàn)低功耗計(jì)算與低功耗控制,其陣列結(jié)構(gòu)與芯片架構(gòu)如圖4所示,包括1.8 MB NOR Flash存內(nèi)計(jì)算陣列,一個(gè)RISC-V核,一個(gè)數(shù)字計(jì)算加速器組,320 kB RAM以及多種外設(shè)接口[5]。WTM2101芯片適配低功耗AIoT應(yīng)用,可使用微瓦到毫瓦級(jí)功耗完成大規(guī)模深度學(xué)習(xí)運(yùn)算,可應(yīng)用于智能語(yǔ)音、智能健康等市場(chǎng)領(lǐng)域,目前已完成批量生產(chǎn)和市場(chǎng)應(yīng)用。此外,知存科技也推出了WTM-8系列產(chǎn)品芯片,這是針對(duì)視頻增強(qiáng)處理的一款高性能低功耗的存算一體AI處理芯片,采用第二代3D存內(nèi)計(jì)算架構(gòu),為全球首粒端側(cè)大算力存算一體芯片,即將量產(chǎn),具備高算力、低功耗、高能效、低成本的核心優(yōu)勢(shì),應(yīng)用于1080P-4K視頻的實(shí)時(shí)處理和空間計(jì)算[6]。WTM2101和WTM-8的主要產(chǎn)品性能如下表1所示, 未公開(kāi)的數(shù)據(jù)用“-”表示,請(qǐng)酌情采信。
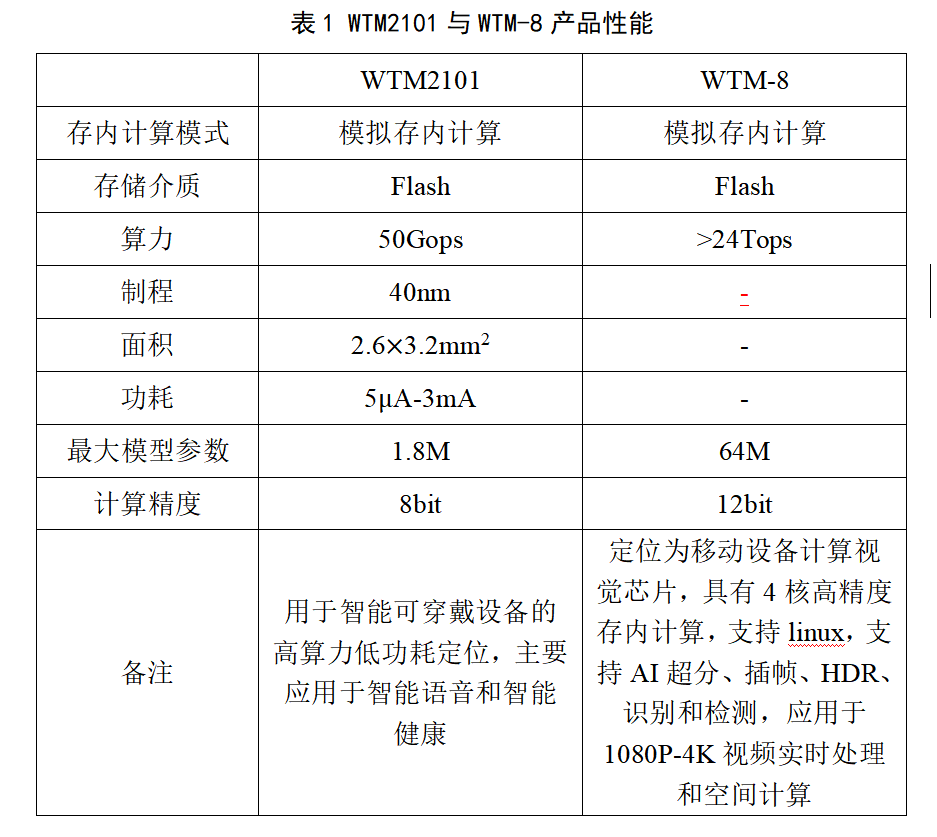
備注:用于智能可穿戴設(shè)備的高算力低功耗定位,主要應(yīng)用于智能語(yǔ)音和智能健康
定位為移動(dòng)設(shè)備計(jì)算視覺(jué)芯片,具有4核高精度存內(nèi)計(jì)算,支持linux,支持AI超分、插幀、HDR、識(shí)別和檢測(cè),應(yīng)用于1080P-4K視頻實(shí)時(shí)處理和空間計(jì)算
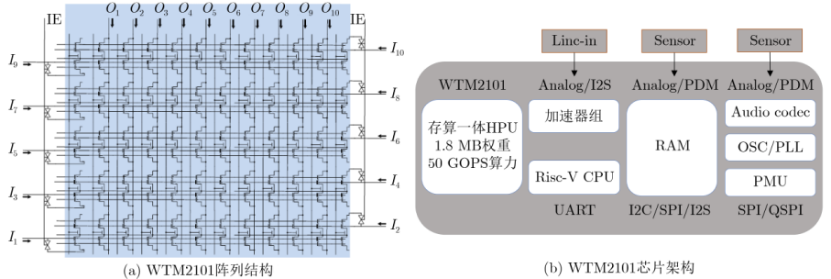
圖 4 WTM2101芯片陣列及架構(gòu)[7]
三.二者優(yōu)劣對(duì)比分析
數(shù)字存內(nèi)計(jì)算與模擬存內(nèi)計(jì)算都是存算一體發(fā)展進(jìn)程中的重點(diǎn)發(fā)展路徑,二者有著不同的優(yōu)缺點(diǎn)與應(yīng)用場(chǎng)景。
數(shù)字存內(nèi)計(jì)算主要以SRAM作為存儲(chǔ)器件,采用先進(jìn)邏輯工藝,具有高性能高精度的優(yōu)勢(shì),且具備很好的抗噪聲能力和可靠性,可以避免由于工藝變化、數(shù)據(jù)轉(zhuǎn)換開(kāi)銷和模擬電路的可縮放性差而導(dǎo)致的不準(zhǔn)確,因此更適合大規(guī)模高計(jì)算精度芯片的實(shí)現(xiàn)。然而,數(shù)字存內(nèi)計(jì)算單位面積功耗高,在功率和面積等方面都遇到了新的問(wèn)題,比如一個(gè)一般的CMOS全加器單元就需要28個(gè)晶體管,面積和功耗開(kāi)銷都比較大。綜上,數(shù)字存內(nèi)計(jì)算更適用于高精度、對(duì)功耗不敏感的大算力計(jì)算場(chǎng)景,比如云邊AI場(chǎng)景。
模擬存內(nèi)計(jì)算通常以RRAM、Flash等非易失性介質(zhì)作為存儲(chǔ)器件,存儲(chǔ)密度大,并行度高,面積、功耗等開(kāi)銷小,成本較低,能量效率高。但是模擬存內(nèi)計(jì)算對(duì)環(huán)境噪聲和溫度非常敏感,由于晶體管變化和ADC(模數(shù)轉(zhuǎn)換器)等的影響,SNR(信噪比)不足,模擬存內(nèi)計(jì)算往往缺乏準(zhǔn)確性,更適用于低功耗、功能靈活性要求不高、對(duì)精度要求不高的高能效小算力應(yīng)用場(chǎng)景,如端側(cè)可穿戴設(shè)備等[8]。兩種存內(nèi)計(jì)算模式的優(yōu)劣對(duì)比如下表2所示。
總而言之,數(shù)字存內(nèi)計(jì)算與模擬存內(nèi)計(jì)算各有優(yōu)劣,都是存算一體發(fā)展進(jìn)程中的重點(diǎn)發(fā)展路徑,數(shù)字存內(nèi)計(jì)算由于其高速、高精度、抗噪性強(qiáng)、工藝技術(shù)成熟、能效比高等特點(diǎn),更適用于大算力、云計(jì)算、邊緣計(jì)算等應(yīng)用場(chǎng)景;模擬存內(nèi)計(jì)算由于其非易失性、高密度、低成本、功耗低等特點(diǎn),更適用于小算力、端側(cè)、需長(zhǎng)時(shí)待機(jī)等的應(yīng)用場(chǎng)景。在如今可穿戴設(shè)備、智能家具、玩具機(jī)器人等應(yīng)用走進(jìn)千家萬(wàn)戶的背景下,模擬存內(nèi)計(jì)算的高能效、小面積、低成本等市場(chǎng)優(yōu)勢(shì)逐漸凸顯,比如前面所提到的知存科技WTM2101已率先進(jìn)入市場(chǎng)規(guī)模化應(yīng)用,在商業(yè)化進(jìn)程中處于領(lǐng)先地位,且更高算力WTM-8系列即將量產(chǎn),在端側(cè)AI市場(chǎng)具有極大的應(yīng)用潛力。
不論是數(shù)字存內(nèi)計(jì)算還是模擬存內(nèi)計(jì)算,目前都面臨各自的一些挑戰(zhàn),比如編程模型的復(fù)雜性、硬件設(shè)計(jì)的復(fù)雜性、硬件系統(tǒng)的可靠性等等,但隨著研究人員的不斷努力,這些難題將逐步得到解決,存內(nèi)計(jì)算芯片的未來(lái)將大有可期。
參考文獻(xiàn)
[1] Yan B, Hsu J L, Yu P C, et al. A 1.041-Mb/MM 2 27.38-TOPS/W signed-INT8 dynamic-logic-based ADC-less SRAM compute-in-memory macro in 28nm with reconfigurable bitwise operation for AI and embedded applications[C]//2022 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2022, 65: 188-190.
[2][4] 存算一體白皮書(2022年),中國(guó)移動(dòng)通信有限公司研究院.
[3] 針對(duì)憶阻器的工作原理和發(fā)展的研究-知乎.
[5][7] 郭昕婕,王光燿,王紹迪.存內(nèi)計(jì)算芯片研究進(jìn)展及應(yīng)用[J].電子與信息學(xué)報(bào),2023,45(05):1888-1898.
[6] 知存科技官網(wǎng) (witintech.com).
[8] Chih Y D, Lee P H, Fujiwara H, et al. 16.4 An 89TOPS/W and 16.3 TOPS/mm 2 all-digital SRAM-based full-precision compute-in memory macro in 22nm for machine-learning edge applications[C]//2021 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2021, 64: 252-254.
審核編輯 黃宇
-
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7484瀏覽量
163762 -
模擬
+關(guān)注
關(guān)注
7文章
1422瀏覽量
83921 -
矩陣運(yùn)算
+關(guān)注
關(guān)注
1文章
5瀏覽量
7467 -
RRAM
+關(guān)注
關(guān)注
0文章
28瀏覽量
21346 -
存內(nèi)計(jì)算
+關(guān)注
關(guān)注
0文章
30瀏覽量
1378
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
存內(nèi)計(jì)算并不滿足于現(xiàn)有的算力
存內(nèi)生態(tài)構(gòu)建重要一環(huán)- 存內(nèi)計(jì)算工具鏈
存內(nèi)計(jì)算技術(shù)工具鏈——量化篇
存內(nèi)計(jì)算芯片研究進(jìn)展及應(yīng)用
探索存內(nèi)計(jì)算—基于 SRAM 的存內(nèi)計(jì)算與基于 MRAM 的存算一體的探究

論基于電壓域的SRAM存內(nèi)計(jì)算技術(shù)的嶄新前景
從MRAM的演進(jìn)看存內(nèi)計(jì)算的發(fā)展
存內(nèi)計(jì)算——助力實(shí)現(xiàn)28nm等效7nm功效

存內(nèi)計(jì)算WTM2101編譯工具鏈 資料
淺談存內(nèi)計(jì)算生態(tài)環(huán)境搭建以及軟件開(kāi)發(fā)
三星基于HMB的存內(nèi)計(jì)算芯片有何亮點(diǎn)?
?什么是存內(nèi)計(jì)算
存內(nèi)計(jì)算的前景如何
淺談存內(nèi)計(jì)算生態(tài)環(huán)境搭建以及軟件開(kāi)發(fā)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論