 大模型,站在“向下競底”和“向上定價”的分岔路口
大模型,站在“向下競底”和“向上定價”的分岔路口
2024年以來,大模型的價格出現了顯著的下降趨勢,并且是全球性的。
海外AI巨頭,OpenAI和谷歌都在五月的新品發布會上,下調了模型調用價格。
OpenAI的GPT-4o支持免費試用,調用API的價格也比GPT-4-turbo降低了一半,為5 美元/百萬tokens。谷歌的當家王牌Gemini大模型系列,Gemini 1.5 Flash 的價格為0.35美元/百萬tokens,比GPT-4o 便宜得多。

同樣的“價格戰”,也在國內開打。
5月13日智譜AI上線了新的價格體系,入門級產品GLM-3 Turbo模型,調用價格從5 元/百萬tokens,降至1元/百萬tokens。緊隨其后的字節跳動,正式發布豆包大模型家族,其中的豆包通用模型Pro 32k模型,定價為0.0008元/千tokens。
當一串代表價格的數字,成為各家發布會上最顯眼的一頁、最廣為傳播的信息,其他廠商為了不失去曝光度,不流失現有用戶,當然也要有所表示,被動跟進,加入“價格戰”。
就在今天,5月21日,阿里云也拋出重磅炸彈,宣布通義千問主力模型Qwen-Long,API輸入價格降至0.0005元/千tokens。
大模型價格正在競底,但究其本質,向下競底是不具備“向上定價”的條件。將“降價”而非“賣貴”作為核心競爭力的大模型,是走不長遠的。
降價的本質,是無法“向上定價”
大模型百萬tokens價格一再跳水,OpenAI說是為了“造福世界”,谷歌說是為了擴大AI用戶,國產大模型廠商也紛紛表示要讓利個人和企業開發者。
那為什么ChatGPT、Gemini剛問世的時候,就敢于強勢向開發者收錢呢?那時怎么不踐行“造福世界”的初心呢?
我們越過那些官方的宣傳辭藻,來看幾組行業數據,就會發現:降價是一種必然。
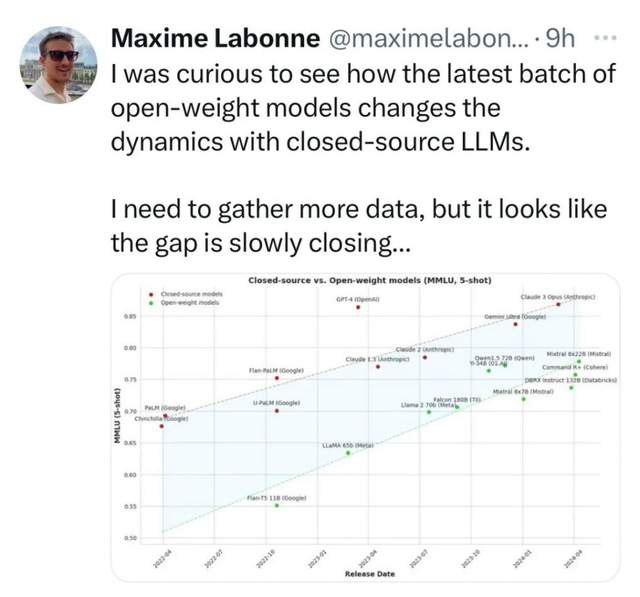
第一,模型能力正在趨同,OpenAI/谷歌也沒有護城河。
數據顯示,自GPT-4發布以來,多個模型在GPT-4水平性能上的巨大收斂,然而并沒有明顯領先的模型。
就是大家都在向GPT-4看齊,但誰都沒有突出優勢。能力趨同的前提下,不得不放棄收費,靠降價/免費來爭奪用戶,保住地盤。
第二,大模型的邊際收益正在持續走低。
Gary Marcus 博士在“Evidence that LLMs are reaching a point of diminishing returns — and what that might mean”《LLMs正達到收益遞減的證據——及其可能意味著什么》一文中提到,從GPT-2到GPT-4甚至GPT-4 Turbo的性能變化,已經出現了性能遞減的跡象。
在收益遞減的背景下,意味著處理相同的任務,開發者的實際成本是在上升的。在AI創新商業化前景還不明朗的市場環境下,為了保住現有用戶,大模型廠商必須給出有吸引力的對策。包括提供更小的模型,比如谷歌推出的Gemini 1.5 Flash,通過“蒸餾”實現了與Gemini 1.5 Pro性能接近、成本更低。另一個手段就是直接降價。
綜上,大模型降價的本質,是因同質化競爭+投入產出比降低,而無法賣貴、不敢賣貴的必然選擇。
向下競底的前途,是沒有前途
論跡不論心,只要大模型廠商的降價行動,能夠切實惠及企業和開發者,當然是受市場歡迎的。
問題就在這里,企業和開發者能從中獲得多大收益呢?
有人說,降低成本能推動大模型的“價值創造”,是錯誤的因果歸因。大模型的“價值創造”,是以大模型本身為錨點,而非價格。
最直接的例子,ChatGPT問世即付費,當時很多從業者都很開心,認為市場終于重返工程師主導的文化,技術為王,代碼競爭,“沒有那些精心設計的流量游戲或者運營技巧,沒人會動砍一刀送1000個token的心思”。說明明碼標價、為好東西付費的模式,才是開發者心中的良性商業模式。
差的商業模式是什么?是模型能力不行,企業和個人開發者投入了大量時間、精力,結果無法建立競爭力,無法從應用創新中獲得商業回報。
有一個SaaS開發者直言:“我們折騰了一年(做基于LLM的產品),也有不少用戶提出了付費需求,但我們感覺做不到SLA,全部婉拒了。”所謂SLA,是指一定開銷下,服務商與用戶之間的一種協定,來保障服務的性能和可靠性。
開發者和ISV服務商,如果被低價吸引,但底座模型的能力卻不行,不能解決用戶的問題,賺不到錢,還投入了大量研發資金和工程團隊,那最后實際的沉沒成本,可比調用省下的仨瓜倆棗大多了。
正如微軟所強調的那樣,大模型“仍將是解決眾多復雜任務的黃金標準”。所以,良性的商業模式,是大模型能力持續提升,商業化版本上同時兼顧普惠。
以下圖來說,逐步進入到低價高質的綠色區域,也是“最具吸引力象限”。
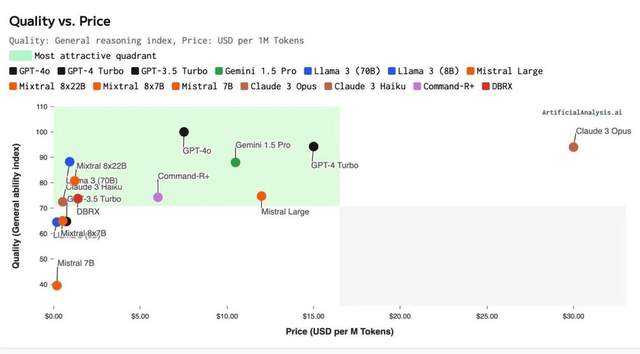
從圖中不難看到,GPT-4o是目前質量最高、價格相對降低的位置。
而放眼國內的廠商,模型能力如果達不到OpenAI的水平,一味拼價格并不是一個好策略。
可以推演一下,打價格戰,會發生三種情況:
最樂觀、最好的結果,是大模型廠商靠低價吸引用戶,用戶數量和使用量的規模化增加,能夠低效甚至超過降價的虧損,實現盈利。而即使是最好的情況,大模型企業也會在短期內,利潤受到擠壓,財務表現可能會受到來自資本市場或投資人的壓力。
至少目前來看,可能性很小。降價或許能夠吸引不少用戶嘗鮮、試用,但最終模型能力才是沉淀下來的主因,留存率并不一定理想。
用戶增長不確定,大模型投資成本卻在節節攀升,意味著大模型廠商的風險敞口不斷擴大,由此帶來打價格戰的一種最壞情況:國內大模型廠商被迫跟進價格戰,不斷壓縮本就不大的盈利空間。
Anthropic的CEO曾向媒體透露,目前正在訓練的模型成本已接近10億美元,到2025年和2026年,將飆升至50億或100億美元。
這意味著,一旦大模型企業為了“價格戰”,現金流會持續承壓,缺乏充足的資金投入到招募AI人才、升級基礎設施、部署數據中心、升級網絡等投資中去,模型進化與迭代也會受到影響,從而讓國產基座模型進入發展瓶頸期,與世界一流水平的差距越拉越大。
需要注意的是,社會各界用戶早已在各個模型廠商的宣傳布道中,拔高了對大模型的期望值。一味推廣低質低價的使用體驗,讓人們對AI失去信心,覺得大模型不夠萬能、啥都干不好,對這一輪大模型主導的AI熱潮,將是極大的負面影響。
當然,也不必過于焦慮。最壞情況和最好情況一樣,發生的概率不大。現實中最有可能的,是大模型行業在最佳和最壞情況之間震蕩。
一部分模型性能領先、商業模式向好、客情關系良好、現金流相對充裕的廠商,能夠在跟進降價的同時,保持對底層創新的持續投資,但長期可以攤薄研發成本,靠規模增長來實現收入上漲。而注定也有一部分企業會在價格戰與現金流壓力下,被震蕩出局。
一個AI公司創始人就表示:其實挺期待AGI到來的,雖然能秒滅我們這種小團隊,但至少大家都解脫了。
說到底,一味打價格戰,AI巨頭有沒有前途,不一定,但創新型小公司,一定危險。
降價的前提,是有“向上定價”的實力
有必要疊個甲,我們不反對大模型降價,鼓勵大模型廠商為個人和企業開發者減輕負擔。
只不過,當輿論各方都關注“低價”的時候,當一場大模型發布會的亮點是百萬token價格小數點后有幾位,當大模型的商業模式從技術為王,變成“羊毛出在豬身上”、把用戶當成流量商品……有必要再重申一下:新技術,是大模型產業的“震中”。
高科技領域,新技術層出不窮。企業要在一波又一波技術浪潮中,同時扮演“顛覆者”和“防御者”。拿大模型來說,廠商必須有至少兩個梯隊來參與競爭。
一個梯隊負責進攻,孵化全新的模型和產品,追逐技術上的顛覆式創新;另一個梯隊負責防御,通過低價、生態等守住現有業務和用戶,抵御對手的襲擊。
而當前,大模型廠商的更優先事務,不是“向下降價”,而是塑造“向上定價”的可能性。
將自家大模型矩陣中的某一些特定模型,做一個極致低價,是很容易操作和吸引眼球的。能把大模型賣出去,向上定價,向價格段的上游遷移,才是AI實力的體現,才能讓企業保有更長的生命力。
舉個例子,GPT-4o雖然免費,但免費版本只提供有限的次數,而天花板級別的語音交互能力又帶來了極強的付費潛力。此外,GPT-5也早就被曝已經做出來了,只是OpenAI沒決定好何時推向市場。谷歌也采用類似的策略,更低價格、更低成本的模型,與高性能的付費模型,以及龐大的軟硬件生態來讓AI落地,共同構成商業版圖。
當前國產大模型亟待完成的,是能力突破的技術進擊。
從我們了解的大模型使用情況來看,企業和個人開發者最在意的商業化問題,仍然要靠模型本身的進化來解決,比如說:
目前階段,很多任務場景,大模型連兜底的效果都還沒有搞定,距離SLA級別的收費標準差距很大,無法達到商用;
精調雖然可以滿足一部分場景,但難以泛化。有些場景的大模型精調效果,還不如用傳統的小模型。這不是大模型“夠不夠便宜”的問題,是“為什么要用”的問題;
最終用戶愿意付費的AI應用,必須真正做到降本增效,學習成本高一點都不會用。這就需要服務商和開發者詳細地拆解任務流程,不忽視任何微小的業務細節,量身定制,降低整個開發過程的周期和難度,或許比降價更有吸引力。
其實,大模型質價比的“最具吸引力象限”,已經說明了,質量做高的前提下,實現價格更優,才是大模型商業化的可持續之路。
向下競底只是權宜之計,能夠“向上定價”的大模型才有未來。
-
Gemini
+關注
關注
0文章
53瀏覽量
7591 -
AI
+關注
關注
87文章
30728瀏覽量
268886 -
OpenAI
+關注
關注
9文章
1079瀏覽量
6481 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595 -
大模型
+關注
關注
2文章
2423瀏覽量
2640
發布評論請先 登錄
相關推薦
達爾優A75HE電競磁軸鍵盤震撼發布:引領電競新潮流
住宅區電動汽車充電電費定價的雙層規劃模型研究
TLV2553檢測電壓整體向上偏移的原因?
本源產品丨量子期權定價真機應用

AIC3106的底噪如何消除?
tlv320aic3106底噪過大要如何解決?
PGA280噪底很大是為什么?
示波器如何測量底噪?示波器測量底噪的步驟
具有向下/向上模式控制的同步向上/向下計數器CD54HC190 CD74HC190 CD54HC191 CD74HC191 CD54HCT191 CD74HCT191數據表






 工商網監
工商網監
評論