


摩爾線程聯(lián)合無問芯穹宣布,雙方已在本周正式完成基于國產(chǎn)全功能GPU千卡集群的3B規(guī)模大模型實(shí)訓(xùn)。該模型名為“MT-infini-3B”,在摩爾線程夸娥(KUAE)千卡智算集群與無問芯穹AIStudio PaaS平臺上完成了高效穩(wěn)定的訓(xùn)練。
本次實(shí)訓(xùn)充分驗(yàn)證了夸娥千卡智算集群在大模型訓(xùn)練場景下的可靠性,同時也在行業(yè)內(nèi)率先開啟了國產(chǎn)大語言模型與國產(chǎn)GPU千卡智算集群深度合作的新范式。
MT-infini-3B模型訓(xùn)練總用時13.2天,經(jīng)過精度調(diào)試,實(shí)現(xiàn)全程穩(wěn)定訓(xùn)練不中斷,集群訓(xùn)練穩(wěn)定性達(dá)到100%,千卡訓(xùn)練和單機(jī)相比擴(kuò)展效率超過90%。目前,實(shí)訓(xùn)出來的MT-infini-3B性能在同規(guī)模模型中躋身前列,相比在國際主流硬件上訓(xùn)練而成的其他模型,在C-Eval,MMLU,CMMLU等3個測試集上均實(shí)現(xiàn)性能領(lǐng)先。
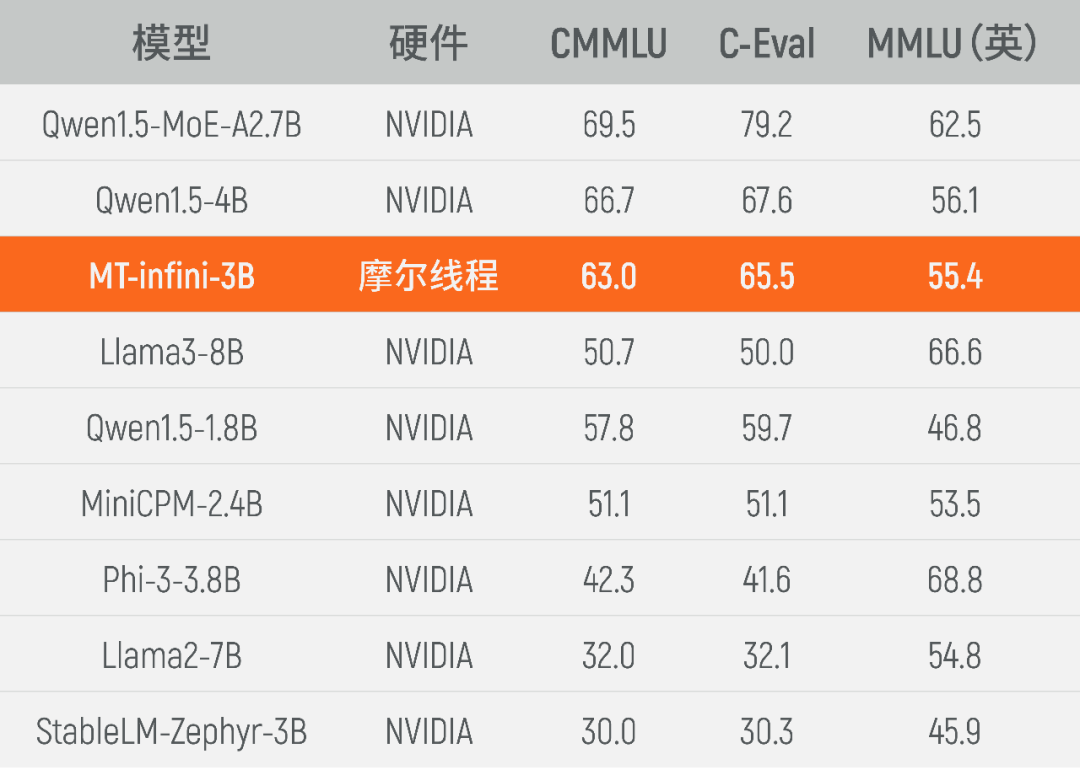
MT-infini-3B性能表現(xiàn)
無問芯穹聯(lián)合創(chuàng)始人兼CEO夏立雪表示:“國內(nèi)大模型與國產(chǎn)芯片的軟硬件協(xié)同發(fā)展,最終目標(biāo)是構(gòu)建一個成熟的生態(tài)系統(tǒng)。無問芯穹正在打造‘M種模型’和‘N種芯片’間的‘M×N’中間層產(chǎn)品,實(shí)現(xiàn)多種大模型算法在多元芯片上的高效、統(tǒng)一部署。摩爾線程是第一家接入無問芯穹并進(jìn)行千卡級別大模型訓(xùn)練的國產(chǎn)GPU公司,而‘MT-infini-3B’的訓(xùn)練是行業(yè)內(nèi)首次實(shí)現(xiàn)基于國產(chǎn)GPU芯片從0到1的端到端大模型實(shí)訓(xùn)案例。”
摩爾線程創(chuàng)始人兼CEO張建中表示:“無問芯穹在夸娥千卡智算集群上實(shí)現(xiàn)的從零開始的大模型訓(xùn)練,不僅是對摩爾線程技術(shù)實(shí)力的有力認(rèn)證,更是實(shí)現(xiàn)了國內(nèi)大模型訓(xùn)練的國產(chǎn)化閉環(huán)。摩爾線程夸娥千卡智算集群以全功能GPU為底座,提供軟硬一體化的全棧解決方案,具備高兼容性、高穩(wěn)定性、高擴(kuò)展性等綜合優(yōu)勢,我們致力于成為AGI時代大模型訓(xùn)練堅(jiān)實(shí)可靠的先進(jìn)基礎(chǔ)設(shè)施。”
此前,摩爾線程與無問芯穹已達(dá)成深度戰(zhàn)略合作。無問芯穹大模型開發(fā)與服務(wù)平臺“無穹Infini-AI”和摩爾線程大模型智算千卡集群夸娥已完成系統(tǒng)級融合適配,該平臺可以靈活調(diào)用夸娥的集群能力以完成大模型的訓(xùn)練、微調(diào)與推理任務(wù)。未來,雙方還將開展更多適配與測試,推動國產(chǎn)大模型技術(shù)的快速發(fā)展與應(yīng)用普及,為中國人工智能產(chǎn)業(yè)的蓬勃發(fā)展貢獻(xiàn)力量。
審核編輯:劉清
-
GPU芯片
+關(guān)注
關(guān)注
1文章
305瀏覽量
6174 -
摩爾線程
+關(guān)注
關(guān)注
2文章
233瀏覽量
5302 -
大模型
+關(guān)注
關(guān)注
2文章
3111瀏覽量
4009
原文標(biāo)題:摩爾線程攜手無問芯穹:基于夸娥千卡智算集群的“MT-infini-3B”大模型實(shí)訓(xùn)已完成
文章出處:【微信號:moorethreads,微信公眾號:摩爾線程】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
摩爾線程GPU成功適配Deepseek-V3-0324大模型

摩爾線程支持阿里云通義千問QwQ-32B開源模型

無問芯穹實(shí)現(xiàn)七家國產(chǎn)芯片DeepSeek適配
阿里通義千問代碼模型全系列開源
性能提升近一倍!壁仞科技攜手無問芯穹,在千卡訓(xùn)練集群等領(lǐng)域取得技術(shù)新突破

摩爾線程GPU與超圖軟件大模型適配:共筑國產(chǎn)地理空間AI新生態(tài)
摩爾線程與超圖軟件完成產(chǎn)品兼容認(rèn)證
摩爾線程與羽人科技完成大語言模型訓(xùn)練測試
摩爾線程夸娥智算中心解決方案重磅升級
摩爾線程和樂創(chuàng)能源簽署戰(zhàn)略合作協(xié)議
無問芯穹發(fā)布千卡規(guī)模異構(gòu)芯片混訓(xùn)平臺
從千卡集群卡到萬卡集群,燧原科技打造更好的AI算力底座






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論