 基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器解決方案
基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器解決方案
概 述
近年來人工智能 (AI) 技術突飛猛進的一個重要標志是大語言模型 (LLM) 的重要突破。大語言模型是基于自然語言處理 (NLP) 技術的transformer機制,目標在于理解、生成自然語言文本,以及處理人機對話等邏輯性創造性語義理解要求更高的自然語言任務。與傳統NLP模型不同,大語言模型具備參數規模巨大、訓練數據量大等特點,在模型訓練、模型微調、模型推理等階段均需要龐大的算力資源。在大模型應用 “百花齊放” 的今天,AI算力的供需缺口已經成為一個不爭的事實,如何快速構建高性能、低成本的算力平臺成為企業普遍關心的問題。
面向希望經濟、高效進行大語言模型落地場景的中小企業用戶,新華三 (H3C) 提供了基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器解決方案。該服務器能夠借助英特爾至強可擴展處理器內置的強大AI加速能力,滿足常見大語言模型微調和推理算力需求。同時,該服務器還具備交付與部署便捷、性價比高等優勢,能夠幫助更多中小企業挖掘大語言模型的應用潛力,賦能企業的智能化轉型。
背景:大語言模型突飛猛進中小企業迎來轉型契機
大語言模型是當前大模型最具應用潛力的領域之一,由大語言模型賦能的AI應用已經在搜索增強、代碼生成、問答系統、智能語音助手、知識圖譜構建、專業文檔生成、智能翻譯等任務中展現出巨大的價值。賽迪研究院的數據顯示,截止2023年 12月,中國已有多家語言大模型研發廠商,2023年市場規模約為132.3億元,增長率達到110%;預測到2027年,中國語言大模型市場規模有望達到600億元1。對于中小企業而言,積極迎接大語言模型帶來的產業發展浪潮,將有助于跟上AI發展趨勢,提升企業的競爭力,助力降本增效。
大語言模型落地鏈路主要分為模型預訓練、模型微調 (Fine Tuning)、模型推理等階段,對于中小企業而言,由于投入規模限制和特定應用場景的需求,其落地的工程化路徑更傾向于使用已經初步完成大規模預訓練的開源/通用大模型(30B及以下),并采用特定領域的數據集對模型進行微調,通過檢索增強生成 (RAG) 等相關技術,同樣達到與通用大模型接近的理想效果,以使其更好地適應特定的任務或應用場景。
綜上所述,在大語言模型的實際部署階段,中小企業需要解決大語言模型微調與推理問題,這會在性能、算力成本、效率等方面遇到相應的挑戰。
在滿足微調和推理兩大場景需求的同時降低成本
在大語言模型微調方面,性能與成本通常是呈現正比關系,采用專用的AI服務器能夠提供強大的算力,但是會消耗高額的成本,這對于中小企業而言是一項巨大的支出。
快速迎上大語言模型的發展浪潮
大語言模型發展的日新月異意味著,中小企業必須快速行動起來,投身到大語言模型的發展浪潮中。但同時,專用的AI服務器面臨著供貨緊張、部署繁瑣、上線時間周期長等客觀現狀,難以快速提供AI算力支持,反觀不少企業都擁有大量的通用服務器資源,若能高效利用這些資源,將有助于大幅縮短大模型應用上線周期。
解決方案:基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器
針對中小企業在中小規模的模型微調與推理上的挑戰,H3C推出了H3C UniServer R6900 G6服務器單一節點解決方案,成功地展示了基于中等規模大語言模型的微調和推理能力。
作為該解決方案的核心,H3C UniServer R6900 G6服務器是H3C基于第四代英特爾至強可擴展處理器自主研發的新一代4U四路機架式服務器。整機設計在上一代產品的基礎上進行了全面優化,無論在計算效率、擴展能力還是低碳節能等方面都達到了全新的高度,是繼G5產品之后的又一標桿四路服務器產品,是大規模虛擬化、數據庫、內存計算、數據分析、數據倉庫、商業智能、ERP等數據密集型應用關鍵業務的理想選擇。

圖 1. H3C UniServer R6900 G6服務器
H3C UniServer R6900 G6服務器搭載的第四代英特爾至強可擴展處理器通過創新架構增加了每個處理器核心每個時鐘周期的可執行指令數量,每個插槽多達60個核心,支持8通道DDR5內存,有效提升了內存帶寬與速度,并通過PCIe 5.0(80個通道)實現了更高的PCIe帶寬提升。第四代英特爾至強可擴展處理器提供了出色性能和安全性,可根據用戶的業務需求進行擴展。借助內置的加速器,用戶可以在AI、分析、云和微服務、網絡、數據庫、存儲等類型的工作負載中獲得優化的性能。
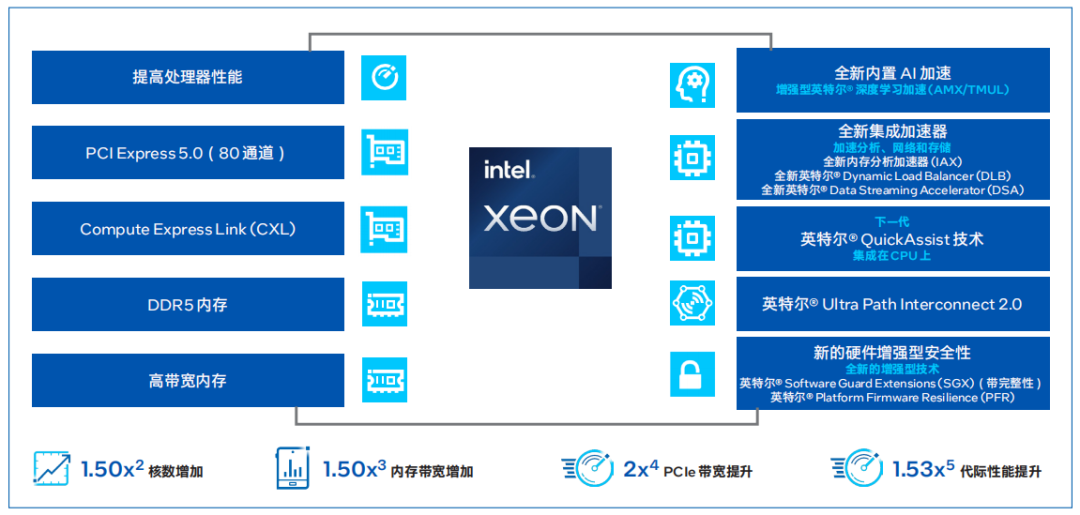
圖 2. 第四代英特爾至強可擴展處理器為數據中心提供多種優勢
H3C UniServer R6900 G6服務器單一節點解決方案在大語言模型微調及推理上的能力,源于以下三大技術突破:
單CPU算力突破
在大模型微調和推理任務中,涉及大規模矩陣運算。隨著模型尺寸的擴大,矩陣的大小也相應增加,這對處理器的算力有著極高的要求。
第四代英特爾至強可擴展處理器提供了增強的AI算力支持。與此前的英特爾至強可擴展處理器中提供的英特爾AVX-512不同,英特爾 AMX采用了全新的指令集與電路設計,通過提供矩陣類型的運算,顯著增加了人工智能應用程序的每時鐘指令數 (IPC),可為AI工作負載中的訓練和推理帶來大幅的性能提升。
單機算力突破
在大語言模型的訓練和微調過程中,為提供充足的算力,通常采用多機多卡的分布式訓練方式,但這種方式會帶來額外的系統互聯開銷,同時也可能導致訓練性能的損耗。
H3C結合英特爾平臺的特有的UPI (Ultra Path Interconnect) 多CPU組合技術,推出了H3C UniServer R6900 G6四路服務器。這種服務器突破了傳統雙路服務器的算力限制,能夠提供單機更高的算力密度。方案采用了高帶寬低延遲的UPI互聯方案,能夠實現CPU算力的高速橫向倍增。這意味著,用戶可以在一臺節點上完成所有的計算任務,從而避免了分布式訓練可能帶來的各種問題。
內存限制突破
大語言模型的訓練和推理對于內存容量有著較高需求,這種需求源于AI 模型訓練過程中的兩個關鍵步驟:一是加載模型的權重,二是存儲用于反向傳播的梯度信息以及執行參數更新的優化器參數。此外,選擇適當的訓練批量大小也至關重要,因為較大的批量有助于模型更快地收斂,從而提升微調后模型的性能。然而,較大的批量會使得中間激活值的存儲也占據了大量的內存空間。以Llama 30B模型為例,在進行16位浮點數訓練時,如果訓練批量大小被設定為16并且使用Adam優化器,估算需要600GB左右的內存才能成功完成30B模型的LoRA微調。雖然目前 涌現了非常多的技術手段來解決內存限制的問題,但是會引入復雜的技術棧和額外復雜度。
針對上述問題,H3C UniServer R6900 G6服務器可支持64根4800MT/s DDR5 ECC內存,能夠提供高達16TB的內存容量,從而打破了內存限制。相比于使用GPU的方案,這種方案能夠減少內存壓縮和多卡間數據通信的開銷,從而更有效地完成微調訓練任務。
除了上面三方面的技術突破,在實現算力突破的同時,英特爾還針對大型語言模型的推理和訓練過程,提供了一系列基于PyTorch框架的軟件優化措施。這些優化被集成在IntelExtension for PyTorch開源軟件庫中,旨在進一步提升模型的性能和效率。
IntelExtension for PyTorch是英特爾發起的一個開源擴展項目,它基于 PyTorch的擴展機制實現,旨在通過提供額外的軟件優化充分發揮硬件特性,幫助用戶在原生PyTorch的基礎上顯著提升英特爾硬件(如CPU和GPU)上的深度學習推理計算和訓練性能。通過擴展,PyTorch用戶將能更加及時地受益于英特爾硬件的最新功能,并在第一時間體驗軟件優化帶來的卓越性能和部署便捷性。
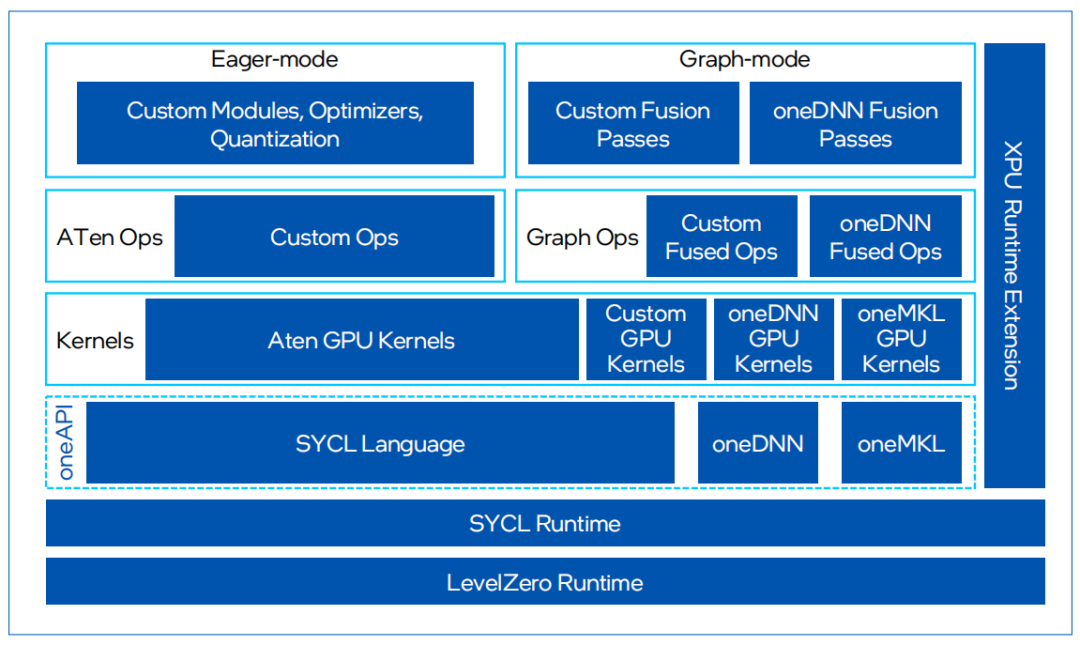
圖 3.IntelExtension for PyTorch框架
目前,IntelExtension for PyTorch配合PyTorch,可支持PyTorch框架下大部分主流模型,其中深度優化模型有50+以上。用戶只需要從Hugging Face拉取模型,加載到PyTorch框架中,通過簡單幾步完成BF16混合精度轉換,模型就可以在CPU上高效部署。同時,Intel Extension for PyTorch面向transformer運算對相關計算進行了深入優化,實現了融合的ROPE (Fused Rotary Positional Embeddings) 操作,可以減少計算的復雜性并提高模型的運行效率。
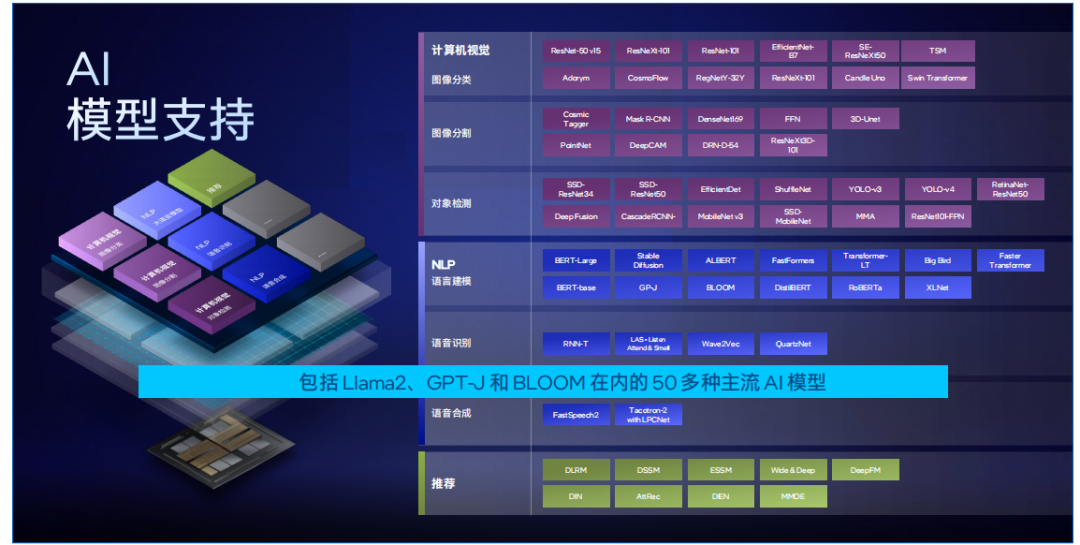
圖 4.IntelExtension for PyTorch 支持50多種主流AI模型
性能驗證:充分滿足中等規模大模型微調
與推理的算力要求
為驗證基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器在大語言模型推理和微調兩大場景的服務能力,H3C選擇了英特爾至強金牌 6448H處理器+2TB內存的配置,并進行了測試。
微調場景
H3C對Llama2-7B和Llama2-13B模型,以及Llama1-30B模型進行了微調測試。這些測試在業界通用的Alpaca數據集(6.5M token,數據集大小 20MBytes)上進行,旨在評估在禁用梯度累積(Gradient Accumulation) 的情況下,四路服務器能支持的batch size,訓練過程中的峰值內存占用,以及訓練完成所需的時間。
測試數據如表1所示,對于7B、13B和30B大小的Llama模型,四路H3C UniServer R6900 G6服務器可以滿足實用訓練時長的要求。
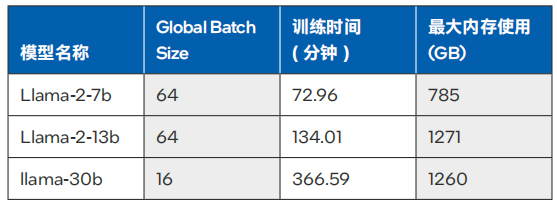
表 1. 不同模型在微調中的訓練時間與最大內存使用6
推理場景
H3C對Llama2的7B和13B模型,以及Code Llama的34B模型進行了深入測試,以充分挖掘基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器的性能極限。本測試專注于評估這些硬件配置在不同的 input/output token latency、 batch size,以及多實例運行情況下的表現。
首token延遲、總吞吐與并發數的測試結果分別如圖5、圖6所示,對于 7B、13B大小的Llama模型,四路H3C UniServer R6900 G6服務器可以滿足多實例運行的要求。
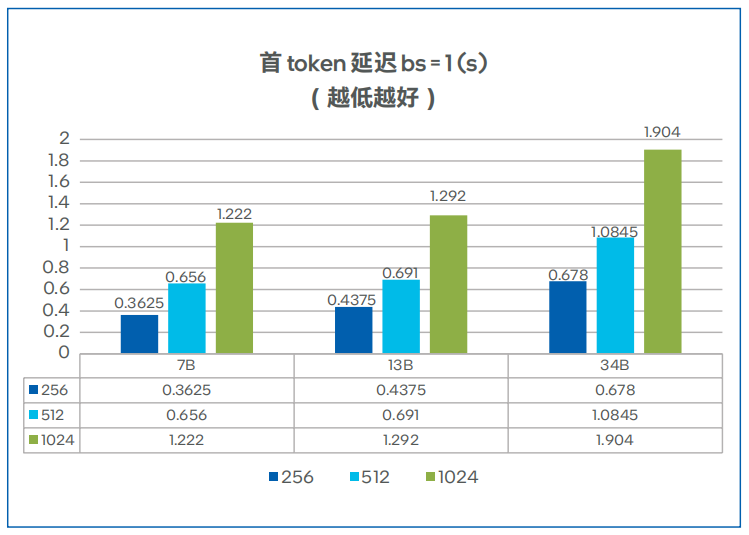
圖 5. 不同模型的首token延遲7
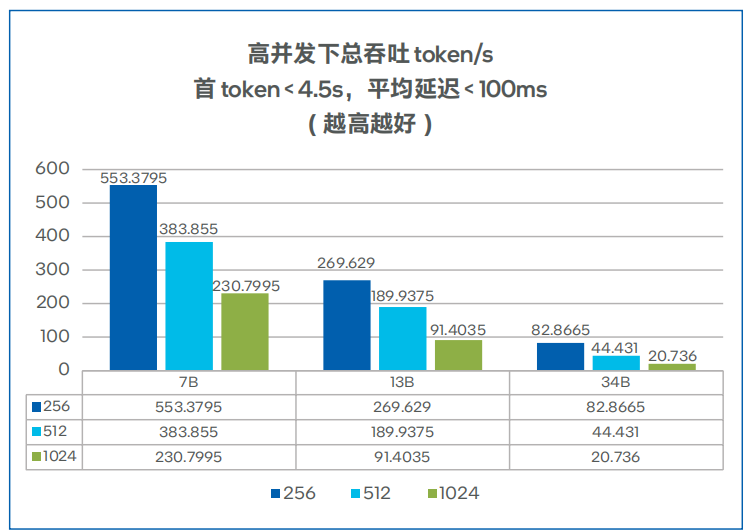
圖 6. 不同模型的總吞吐性能測試8
收 益
基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器提供了大語言模型微調推理一體方案,為中小企業提供了一種更高效、更經濟的解決方案,實現了以下價值:
可以更加快速的推動以大語言模型為代表的AGI的部署:該方案能夠在單一服務器上覆蓋微調和推理,不僅簡化了操作流程,也提高了算力平臺的交付效率。同時,方案基于Pytorch,TensorFlow,OpenVINO等流行的開源框架,使得中小企業能夠在CPU平臺上方便快捷地搭建最新的模型服務,更快地將AGI應用到業務流程中。
有助于企業搭建更具性價比的大語言模型算力平臺:該方案不依賴于昂貴的GPU服務器,而是可以采用更具經濟性的通用CPU服務器,同時達到理想的性能表現,可以助力用戶降低大語言模型算力平臺的總體擁有成本 (TCO)。
實現出色的靈活性與擴展性:解決方案具有極高的適應性和靈活性,可以廣泛應用于通用計算和AI專用場景。用戶可以靈活地調整和優化系統資源的使用,從而實現最優的性能和效果。
展 望
大語言模型已經徹底改變了智能化應用的生態,大語言模型帶來的涌現能力賦予了其巨大的應用前景,成為足以改變商業競爭態勢的重要能力。基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器在當前算力稀缺、資源不足的情況下,為中小企業提供了經濟、高效、靈活的AI算力平臺選項,可以助力用戶投入到AI競賽中,為業務帶來切實的收益。
除了用于大語言模型的微調和推理之外,基于英特爾至強可擴展處理器的H3C UniServer R6900 G6服務器具備的強大通用性意味著,其能夠在更多領域發揮價值,而對于有更高性能需求的場景,該方案也能夠通過服務器節點擴展來提供更高的算力。面向未來,英特爾與H3C還將進一步合作,包括采用新一代硬件平臺,通過軟件工具套件進行性能優化,攜手拓展AI生態等,助力用戶在AI時代獲得成功。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19265瀏覽量
229687 -
英特爾
+關注
關注
61文章
9953瀏覽量
171706 -
PCIe
+關注
關注
15文章
1235瀏覽量
82597 -
人工智能
+關注
關注
1791文章
47208瀏覽量
238303
原文標題:基于英特爾? 至強? 可擴展處理器的H3C UniServer R6900 G6服務器加速大語言模型微調及推理
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英特爾發布至強6性能核處理器
英特爾?至強?可擴展處理器助力智慧醫療的數字化轉型

128核性能猛獸,劍指云數據中心算力升級!英特爾發布至強6性能核處理器

開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能

采用144核,能效提升66%!英特爾至強6處理器震撼上市,加速數據中心升級

英特爾發布至強6能效核處理器

重磅!英特爾發布intel3制程至強6能效核處理器,賦能數據中心能效升級


全新 μATX 服務器載板為英特爾 Ice Lake D 處理器系列產品提供更多可擴展性

第五代英特爾至強處理器,AI特化的通用服務器CPU

英特爾至強處理器優化升級,助力打造未來高能效數據中心
H3C UIS超融合方案采用第五代英特爾至強可擴展處理器





 工商網監
工商網監
評論