 澳鵬入選億歐大模型基礎層圖譜,以優質數據賦能AGI智能涌現
澳鵬入選億歐大模型基礎層圖譜,以優質數據賦能AGI智能涌現
上海2024年5月27日/美通社/ -- 自ChatGPT的發布引發全球范圍內對大模型的廣泛關注以來,目前,國內公布的大模型數量已超過300個,行業呈現出"百模大戰"的競爭格局。在此背景下,億歐近日發布《2024中國"百模大戰"競爭格局分析報告》,全方位呈現大模型產業現狀。作為產業鏈上的重要一環,澳鵬Appen憑借高質量的大模型數據能力入選大模型基礎層圖譜。與此同時,作為大模型數據領域的代表案例,本次報告還分析了澳鵬如何成功助力全球15,000+個AI項目的研發及商業化,賦能AGI智能涌現。

澳鵬Appen憑借高質量的大模型數據能力入選大模型基礎層圖譜
隨著"數據二十條"等一系列政策措施相繼出臺,數據要素市場的探索與發展已步入高速增長階段。據億歐預計,2025年數據要素市場規模可達1990億元,年復合增長率可達25%。尤其是在人工智能快速迭代、大模型與數據相得益彰的發展態勢中,數據要素的戰略地位進一步凸顯。
澳鵬(中國)自主研發的大模型智能開發平臺集大模型數據準備、訓練、推理、部署應用于一體,支持從數據集管理、數據標注、模型評估、模型調優、訓練平臺部署及標注工具部署等大模型定制開發的全流程需求,助力企業輕松擁抱大模型。
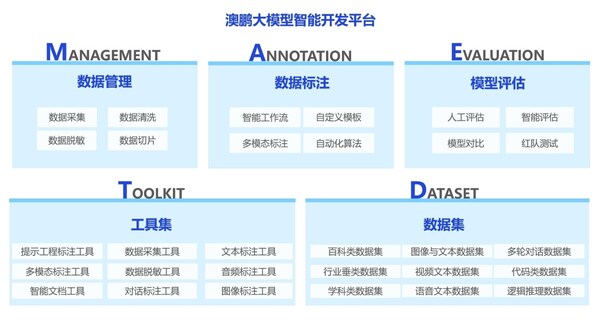
澳鵬(中國)自主研發的大模型智能開發平臺
澳鵬大模型智能開發平臺涵蓋三大核心技術:自研的預標注模型、交互式分割模型及算法賦能的文檔智能。首先,澳鵬通過海量圖像、點云等數據,結合豐富的實際項目經驗,預訓練了車輛行駛、交通燈、停車位、人像識別等多場景預標注模型,可實現2D 3D聯合拉框、視頻連續幀mask追蹤等全方位的預識別結果輸出,大幅提高后續標注效率。
澳鵬自研預標注模型
為適應2D圖像標注中多樣化的物體類別分割與檢測,澳鵬結合豐富的圖像數據訓練了交互式分割模型并內嵌于標注工具中。僅需通過點擊的方式標記正確區域并糾正輸出結果,即可完成物體識別;再結合連續幀信息引入,大幅提升2D圖像標注效率。模型支持微調訓練,可適應定制化的場景需求。

澳鵬交互式分割模型
為解決各類場景下的文檔信息轉化提取難題,澳鵬基于海量文檔數據預訓練了智能文檔處理模型。支持輸入圖片或PDF格式文檔,對帶陰影圖片、傾斜圖片、手寫表格、各類學科公式等多類信息進行識別,并轉化成word文檔輸出,便于人工編輯校對。
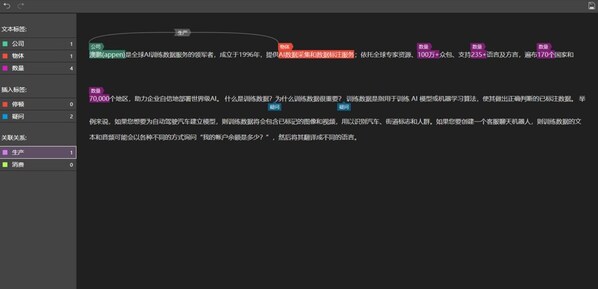
澳鵬Appen算法賦能的文檔智能
隨著大模型技術的演進,其賦能千行百業的能力不斷提升。在數據集方面,澳鵬LLM數據庫覆蓋教育、法律、醫療、金融、百科等眾多熱門垂直領域,提供超過290種語言和方言的文本、語音數據庫,并創建了一系列大模型專用數據集,如:百科類人工泛化文本問答數據集,知識類百科文本語料對數據庫,58億圖文對數據庫等等。澳鵬提供JSON格式的多學科題目,并擁有20萬余條各種不同類型的高質量指令集文本及法律醫療百科類文本,通過多重質檢環節嚴格把關數據質量,助力通用大模型和各種細分垂類大模型的訓練和落地。
澳鵬Appen全球高級副總裁、大中華區及北亞區總經理田小鵬博士表示:"數據是決定機器學習模型性能的三大要素之一。隨著各類大模型的智能涌現,數據,尤其是高質量的行業數據,正在成為決定大模型高速發展的關鍵因素。澳鵬自研的算法模型和核心技術,以及一系列大模型數據集,充分給予AI應用優質的數據養料,為大規模的大模型場景落地提供支持。"
審核編輯 黃宇
-
Agi
+關注
關注
0文章
80瀏覽量
10204 -
GPT
+關注
關注
0文章
352瀏覽量
15342 -
大模型
+關注
關注
2文章
2423瀏覽量
2640
發布評論請先 登錄
相關推薦
億緯鋰能榮獲小鵬汽車“與鵬同行獎”

燧原科技入選先進計算賦能新質生產力典型應用案例
軟通動力入選《人工智能數據標注產業圖譜》
圖為大模型一體機新探索,賦能智能家居行業
西井科技成功入選《2024大模型典型示范應用案例集》

AI模型在面對數據壁壘時的困境
機械革命入選《2024全國企業新質生產力賦能典型案例》

知識圖譜與大模型之間的關系
維智科技入選《2024中國數據智能產業圖譜1.0》

大模型應用之路:從提示詞到通用人工智能(AGI)
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
科大訊飛與華中師范大學合作 大模型賦能教育
億緯動力憑借卓越的技術實力與賦能表現榮獲“開發賦能獎”
普迪飛:人工智能時代,高質量大數據賦能芯片生產制造

數字化轉型守護者丨芯盾時代入選“2023央國企數字化產業賦能圖譜”多個領域






 工商網監
工商網監
評論