 美光HBM3E解決方案,高帶寬內存助力AI未來發展
美光HBM3E解決方案,高帶寬內存助力AI未來發展
美光近期發布的內存和存儲產品組合創新備受矚目,這些成就加速了 AI 的發展。美光8 層堆疊和 12 層堆疊 HBM3E 解決方案提供業界前沿性能,功耗比競品1低 30%。美光 8 層堆疊 24GB HBM3E 產品將搭載于 NVIDIA H200 Tensor Core GPU 中。在 Six Five Media 最近的一期節目中,主持人 Daniel Newman(Futurum Group 首席執行官)和 Patrick Moorhead(Moor Insights & Strategy 首席執行官)與美光產品管理高級總監 Girish Cherussery 進行了視頻訪談。
他們探討了高帶寬內存 (HBM)的廣闊市場,并研究了其在當今技術領域的各種應用。這篇文章回顧了他們的談話,其中話題包括 HBM 的復雜性、美光如何滿足市場需求以及目前內存生態系統的發展情況。Girish 還為渴望了解 AI 內存和存儲技術市場趨勢的聽眾提供了寶貴的見解。
什么是高帶寬內存?有哪些應用領域?
HBM 作為行業標準的封裝內存,是一款變革性產品。其以較小的尺寸,在給定容量下實現更高的帶寬和能效。正如 Girish 在 Six Five 播客節目中所言,AI 應用部署越來越多的復雜大語言模型 (LLM),由于 GPU 內存容量和帶寬有限,訓練這些模型面臨著挑戰。大語言模型的規模呈指數級增長,遠遠超過了內存容量的增長速度。這一趨勢凸顯了對內存容量日益增長的需求。
以 GPT-3 為例,該模型有大約 1750 億個參數。這意味著需要約 800GB 的內存及更高的帶寬,以防止出現性能瓶頸。最新的 GPT-4 模型的參數更多(估計達到萬億個)。采用傳統方法增加內存器件會導致系統成本過高。
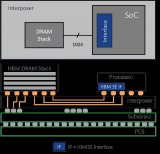
HBM 提供了一種高效的解決方案。美光基于其業界前沿 1β (1-beta) 技術,推出 11mm x 11mm 封裝規格堆疊 8 或 12 層 24Gb 裸片的 HBM3E 內存,提供 24GB 或 36GB 容量。美光先進的設計和工藝創新,助力 HBM3E 實現超過 1.2 TB/s 的內存帶寬,超過 9.2 Gb/s 的引腳速率。正如 Girish 所言,HBM3E 擁有 16 個獨立的高頻數據通道,類似于“高速公路車道”,可以更快地來回傳輸數據,提供所需性能。
美光 HBM3E 更高的容量和帶寬縮短了大語言模型的訓練時間,為客戶節省了大量運營支出。HBM3E 容量更大,支持規模更大的大語言模型,有助于避免 CPU 卸載和 GPU 之間的通信延遲。
HBM3E 功耗很低,因為主機和內存之間的數據路徑較短。DRAM 通過硅通孔 (TSV) 與主機通信,Girish 將其形象地比喻為牙簽穿過漢堡。其從底層顆粒獲取電源和數據,然后將其傳輸到頂部內存層。憑借基于 1β 制程節點的先進 CMOS 技術創新,以及多達 2 倍硅通孔和封裝互連縮小 25% 的先進封裝創新,美光 HBM3E 的功耗比競品低 30%。在每個內存實例 8Gbps 的速率下,功耗降低了 30%,以擁有 500,000 個 GPU 安裝基數的客戶為例,僅在五年內就可以節約超過 1.23 億美元運營成本。
因此,正如 Daniel Newman 所言,美光 HBM3E 內存在容量、速度和功耗方面表現優異,對數據中心的可持續發展需求產生了積極影響。
美光 HBM3E 如何滿足生成式 AI和高性能計算的需求?
美光相信通過解決各種技術問題,可以幫助人們應對所面臨的根本性難題,豐富所有人的生活。
如今,超級計算機模擬技術帶來了巨大的內存和帶寬需求。正如 Girish 所言,在新冠疫情期間,制藥公司迫切需要找到用于治療新冠病毒的新藥物和化合物。HBM 作為高性能計算系統器件,可滿足大規模計算的需求,解決當今時代的關鍵難題。因此,HBM 作為支持大規模計算系統發展的重要器件,以其緊湊的外形尺寸提供所需的性能和容量,同時大幅降低功耗,從根本上改變了人們對內存技術的看法。
隨著 AI 時代計算規模的不斷擴大,當下的數據中心面臨著耗電量高、缺乏建設空間的難題。AI 和高性能計算 (HPC) 工作負載推動提高內存利用率和容量。冷卻數據中心所需的能源消耗巨大,也是個挑戰。對于采用 HBM 的系統而言,系統冷卻位于 DRAM 堆棧頂部,而底部顆粒和 DRAM 層功耗所產生的熱量則位于堆棧底部。這要求我們在設計的早期階段就考慮功耗和散熱問題。美光先進的封裝創新技術提供了改善熱阻抗的結構解決方案,有助于改善立方體的散熱表現。結合大幅降低的功耗,整體散熱表現將大大優于競品。美光 HBM3E 的功耗更低、散熱效率更高,有助于應對數據中心面臨的重大挑戰。
AI 內存解決方案的新興趨勢是什么?
生成式 AI 在從云到邊緣的各種應用中迅速普及,推動了異構計算環境中系統架構的重大創新。AI 正在加速推動邊緣應用的發展趨勢,如工業 4.0、自動駕駛汽車、AI 個人電腦和 AI 智能手機等。正如 Girish 所分享的,這些長期趨勢推動了內存子系統的重大技術創新,以提供更高的容量、帶寬、可靠性和更低的功耗。
美光基于 1β 技術的 LPDDR5X 產品組合為這些系統提供了出色的性能/功耗,可用于邊緣 AI 推理。美光率先在市場上推出基于 LPDDR5X 的創新型 LPCAMM2,旨在提升個人電腦用戶的體驗,推動 AI 個人電腦革命。
數據中心架構也在不斷演變。美光單顆粒大容量 RDIMM 推動了全球數據中心服務器在 AI、內存數據庫和通用計算工作負載方面的進步。我們率先上市的 128GB 大容量 RDIMM 性能卓越、容量大、延遲低,可高效處理需要更大容量內存的應用程序,包括從 GPU 卸載到 CPU 處理的 AI 工作負載。
我們還看到,由于 LPDDR 內存(低功耗 DRAM)在性能/功耗方面的優勢,越來越多的數據中心將其用于 AI 加速和推理應用。美光顯存 GDDR6X 的引腳速率達到驚人的 24 Gb/s,也被用于數據中心的推理應用中。
美光率先推出的另一種新興內存解決方案 CXL 內存,可為數據中心應用提供內存和帶寬擴展。美光 CXL 內存模塊 CZ120可為 AI、內存數據庫、高性能計算和通用計算工作負載提供內存擴展。
AI 正在為人類開創一個新時代,觸及我們生活的方方面面。隨著社會不斷利用 AI 的潛力,AI 將繼續推動數字經濟中各行業的快速創新。數據是數字經濟的核心,也是內存和存儲解決方案的核心。美光已做好準備,憑借其技術實力、創新內存和存儲解決方案的強大產品組合及強有力的路線圖,以及致力于通過改變世界使用信息的方式豐富全人類生活的承諾,助推 AI 革命。
審核編輯:劉清
-
DRAM
+關注
關注
40文章
2319瀏覽量
183605 -
GPT
+關注
關注
0文章
354瀏覽量
15431 -
大模型
+關注
關注
2文章
2482瀏覽量
2849 -
生成式AI
+關注
關注
0文章
508瀏覽量
501 -
HBM3E
+關注
關注
0文章
78瀏覽量
280
原文標題:美光 HBM3E:高帶寬內存助力 AI 未來發展
文章出處:【微信號:gh_195c6bf0b140,微信公眾號:Micron美光科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
美光12層堆疊HBM3E 36GB內存啟動交付
三星電子HBM3E內存獲英偉達認證,加速AI GPU市場布局
SK海力士9月底將量產12層HBM3E高性能內存
三星否認HBM3E通過英偉達測試傳聞
NVIDIA預定購三星獨家供應的大量12層HBM3E內存
什么是HBM3E內存?Rambus HBM3E/3內存控制器內核
美光開始量產HBM3E解決方案
美光科技開始量產HBM3E高帶寬內存解決方案
美光量產行業領先的HBM3E解決方案,加速人工智能發展

美光開始量產行業領先的 HBM3E 解決方案,加速人工智能發展






 工商網監
工商網監
評論