
 LLM之外的性價比之選,小語言模型
LLM之外的性價比之選,小語言模型
電子發燒友網報道(文/周凱揚)大語言模型的風靡給AI應用創造了不少機會,無論是效率還是創意上,大語言模型都帶來了前所未有的表現,這些大語言模型很快成為大型互聯網公司或者AI應用公司的殺手級產品。然而在一些對實時性要求較高的應用中,比如AI客服、實時數據分析等,大語言模型并沒有太大的優勢。
在動輒萬億參數的LLM下,硬件需求已經遭受了不小的挑戰。所以面對一些相對簡單的任務,規模較小的小語言模型(SLM)反而更加適合。尤其是在端側的本地AI模型,在低功耗算力有限的邊緣AI芯片支持下,小語言模型反而更適合發揮最高性能,而不是促使硬件一味地去追求更大規模模型的支持。
微軟Phi
2023年,微軟推出了一個基于Transformer架構的小語言模型Phi-1,該模型只有13億參數,且主要專注于基礎的Python編程,實現文本轉代碼。整個模型僅僅用到8塊A100 GPU,耗時四天訓練完成的。
這也充分說明了小語言模型的靈活性,在LLM普遍需要成百上千塊GPU,花費數十乃至上百天的時間完成模型的訓練時,SLM卻只需要千分之一的資源,就可以針對特定的任務打造適合的模型。
近日,微軟對Phi模型進行了全面更新,推出了Phi-3-mini、Phi-3-small和Phi-3-medium三個版本。其中Phi3-mini是一個38億參數的小語言模型,同步推出的Phi-3-small和Phi-3-medium分別為70億參數和140億參數的模型。
Phi-3-mini有支持4K和128K兩個上下文長度的版本,也是這個規模的模型中,第一個支持到最高128K上下文長度的版本,微軟聲稱其性能甚至超過不少70億參數的大模型。通過在搭載A16芯片的iPhone 14上測試,在純粹的設備端離線運行下,Phi-3-mini可以做到12 token每秒的速度。
谷歌Gemma
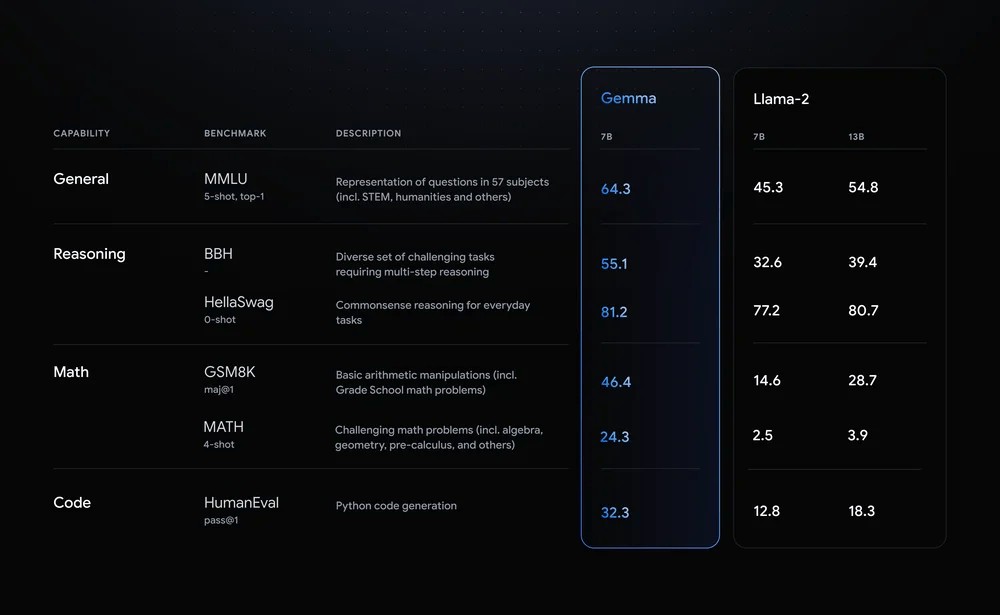
在Gemini模型獲得成功后,基于大語言模型框架Gemini,谷歌也開發了對應的輕量小語言模型Gemma。Gemma分為20億參數和70億參數的版本,其中20億參數的Gemma可以在移動設備和筆記本電腦上運行,而70億參數的版本則可以擴展至小型服務器上。雖然資源占用不高,但Gemma在各項基準測試中,依然可以與更大規模的模型相媲美,比如130億參數的Llama-2等。
此外,谷歌不僅提供了預訓練版本的Gemma,也支持通過額外的訓練來實現模型調優,用于修改Gemma模型的行為,提高其在特定任務上的表現,比如通過人類語言互動進行訓練,提高聊天機器人中響應式對話輸入的表現等。
 ?
?
Gemma與Llama-2的性能對比/谷歌
在對運行設備的要求上,Gemma自然比不上大哥Gemini,但谷歌與英偉達合作,針對從數據中心到云端再到RTX AI PC的GPU都進行了優化,這樣一來不僅具有廣泛的跨設備兼容性,也能確保擴展性和高性能的雙重優勢。
寫在最后
小語言模型的出現為行業帶來了新的選擇,尤其是在大多數大模型應用還是在不斷燒錢的當下,小語言模型加速落地的同時,也提供了訓練成本更低的解決方案。但與此同時,小語言模型的缺陷依然不可忽視,比如其規模注定了無法存儲足夠的“事實性知識”,其次這類小語言模型很難做到多語言支持。但我們必須認清小語言模型的存在并不是為了替代大語言模型,而是提供一個更加靈活的模型方案。
-
模型
+關注
關注
1文章
3490瀏覽量
50023 -
大模型
+關注
關注
2文章
3033瀏覽量
3839 -
LLM
+關注
關注
1文章
320瀏覽量
688
發布評論請先 登錄
小白學大模型:從零實現 LLM語言模型

無法在OVMS上運行來自Meta的大型語言模型 (LLM),為什么?
新品| LLM630 Compute Kit,AI 大語言模型推理開發平臺

小白學大模型:構建LLM的關鍵步驟
什么是LLM?LLM在自然語言處理中的應用
如何訓練自己的LLM模型
使用LLM進行自然語言處理的優缺點
新品|LLM Module,離線大語言模型模塊





 工商網監
工商網監

評論