 大語言模型(LLM)快速理解
大語言模型(LLM)快速理解
自2022年,ChatGPT發布之后,大語言模型(Large Language Model),簡稱LLM掀起了一波狂潮。作為學習理解LLM的開始,先來整體理解一下大語言模型。
一、發展歷史
大語言模型的發展歷史可以追溯到早期的語言模型和機器翻譯系統,但其真正的起點可以說是隨著深度學習技術的興起而開始。
1.1 統計語言模型
在深度學習技術出現之前,語言模型主要基于傳統的統計方法,也稱為統計語言模型(SLM)。
SLMs是基于統計語言方法開始,基本思想是基于馬爾可夫假設建立詞預測模型,如根據最近的上下文預測下一個詞。具有固定上下文長度n的SLM也稱為n—gram語言模型。
然而這些模型雖然簡單,但在處理長文本序列時存在著詞匯稀疏性和上下文理解能力有限等問題。
1.2 神經語言模型
隨著神經網絡技術的發展,Bengio等人于2003年提出了神經語言模型,將語言模型建模問題轉化為了一個神經網絡的學習問題。
循環神經網絡(RNN)和長短期記憶網絡(LSTM)的提出進一步增強了神經語言模型對文本序列的建模能力。這些模型能夠捕捉到文本序列中的長程依賴關系,從而提高了語言模型的性能。
2013年,Google提出了Word2Vec模型,通過詞嵌入(Word Embedding)的方式將單詞映射到連續的向量空間中,提高了語言模型對單詞語義的理解能力。
2017年,谷歌提出了Transformer模型,該模型通過自注意力機制(Self-Attention)實現了并行計算,大大提高了模型的訓練速度。
1.3 預訓練語言模型
2018年,OpenAI發布了第一個版本的GPT模型,利用Transformer結構進行預訓練,這是首個成功利用大規模無監督學習方法來預訓練通用語言表示的模型。
2018年,Google提出了BERT模型,與GPT的區別是GPT采用了單向的自回歸方式進行預訓練,而BERT通過MLM和NSP實現雙向上下文建模。使得預訓練語言模型的性能得到了進一步的提升。
隨后就激發了后續一系列的預訓練模型的發展,如XLNet、RoBERTTa、T5、 GPT-2、GPT-3、GPT 3.5、GPT-4 等等。而大語言模型也是在此過程中被定義下來的。
二、什么是大語言模型
2.1 定義
從大語言模型字面意思來理解,“語言”和“模型”很好理解,就是代表著在自然語言處理上的AI模型。而這個大指的是神經網絡很大,包括模型的參數數量、訓練數據量、計算資源等。
參數數量
大語言模型通常含有數十億到數千億個參數,使得模型能夠有更強的語言理解、推理和生成能力。
如果只通過 GPT(生成式預訓練 Transformer)模型的演進規模來看:
2018年發布的GPT-1包含 1.17 億個參數,9.85 億個單詞。2019年發布的GPT-2包含15億個參數。2020年發布的GPT-3包含1750億個參數。ChatGPT 就是基于這個模型。2023年發布的GPT-4據爆料它可能包含1.8萬億個參數
訓練數據訓練大語言模型通常需要大規模的文本語料庫。這些語料庫可以包括來自互聯網、書籍、新聞等各種來源的文本數據,從而確保模型能夠學習到豐富和多樣化的語言知識。如GPT-3,它是在混合數據集上進行訓練的;PaLM使用了一個有社交媒體對話、過濾后的網頁、書籍、Github、多語言維基百科和新聞組成的預訓練數據集。計算資源訓練大型語言模型需要大量的計算資源,包括高性能的計算機集群、大容量的存儲設備以及高速的網絡連接。英偉達價格高昂但依然一卡難求的高性能GPU H100,長期霸占著LLM領域的熱門話題,可以說,英偉達壟斷了目前的AI算力市場。馬斯克甚至戲言:GPU現在比drug還緊俏。
2.2 大語言模型訓練方式
現有的神經網絡在進行訓練時,一般基于反向傳播算法(BP算法),先對網絡中的參數進行隨機初始化,再利用隨機梯度下降(SGD)等優化算法不斷優化模型參數。
大語言模型的訓練通常采用兩階段方法:預訓練(pre-training)和微調(fine-tuning)預訓練(Pre-training):
- 在預訓練階段,模型使用大規模無監督的文本數據進行訓練,學習文本數據中的語言表示。
- 通常采用自監督學習方法,即使用文本數據自身作為標簽來訓練模型。
訓練過程中,模型通過最小化損失函數來優化參數,以使得模型能夠更好地表示文本中的語義和語法信息。
微調(Fine-tuning):
- 在預訓練完成后,可以將預訓練好的模型參數應用于特定的下游任務,如文本生成、文本分類、情感分析等。
- 在微調階段,通常使用帶標簽的數據集對模型進行進一步訓練,以適應特定任務的需求。微調可以在預訓練模型的頂部添加一個或多個額外的層,并使用標簽數據對這些層進行訓練。
微調的目標是調整模型參數,使得模型能夠更好地適應特定任務的特征和標簽,從而提高任務性能。
在微調階段,模型在與目標任務或領域相關的更具體、更小的數據集上進一步訓練。這有助于模型微調其理解,并適應任務的特殊要求。
三、預訓練
3.1 數據收集及處理
3.1.1 數據來源
無論是怎樣的模型,數據的質量都是相當重要的。現有的大語言模型主要混合各種公共文本數據集作為預訓練語料庫。如下為一些代表性模型的預訓練數據來源的分布情況。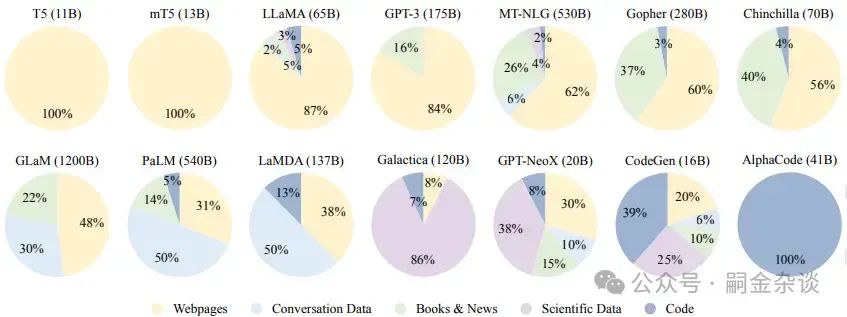 語料庫的來源可以廣義分為通用文本數據和專用文本數據。通用指的就是如網頁、書籍和對話文本等廣泛可獲取的,可以增強模型的泛化能力;專用文本數據就是在想讓模型更加專注某一專業領域時所用的,如科學數據、代碼等。如上圖中的模型中,就大部分都是使用了通用的預訓練數據。
語料庫的來源可以廣義分為通用文本數據和專用文本數據。通用指的就是如網頁、書籍和對話文本等廣泛可獲取的,可以增強模型的泛化能力;專用文本數據就是在想讓模型更加專注某一專業領域時所用的,如科學數據、代碼等。如上圖中的模型中,就大部分都是使用了通用的預訓練數據。
3.1.2 數據預處理
收集數據之后,由于不確定性,所以需要對數據進行預處理,尤其是噪聲、榮譽、無關或有害的數據。預處理過程如下: (1) 質量過濾(Quality Filtering)刪除低質量數據,常采用基于分類器和基于啟發式兩種方法。分類器就是使用用高質量數據訓練好的二分類的模型來對數據進行分類,不過可能會刪除方言、口語和社會語言的高質量文本。基于啟發式就是設計一組精心設計的規則來消除低質量文本,如基于語言、生成文本的評估度量、統計特征、關鍵詞等。
(1) 質量過濾(Quality Filtering)刪除低質量數據,常采用基于分類器和基于啟發式兩種方法。分類器就是使用用高質量數據訓練好的二分類的模型來對數據進行分類,不過可能會刪除方言、口語和社會語言的高質量文本。基于啟發式就是設計一組精心設計的規則來消除低質量文本,如基于語言、生成文本的評估度量、統計特征、關鍵詞等。
(2)去重(De-duplication)
重復數據會降低語言模型的多樣性,所以需要進行去重處理。
從數據顆粒上來說,可以分為在句子級、文檔級和數據集級等進行去重;(3)隱私去除(Privary Reduction)如涉及敏感個人信息的隱私內容,也是需要去除的,很簡單有效的就是用基于如姓名、地址、電話號碼等關鍵詞的方法。(4)分詞(Tokenization)非常關鍵的步驟,將原始文本分割成詞序列。
3.2 架構
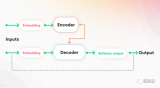
3.2.1 編碼器-解碼器架構(Encoder-Decoder)
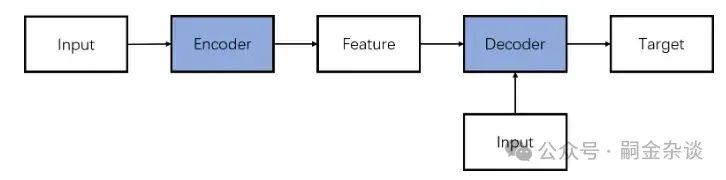 如傳統Transformer 模型就是建立在此結構上。它使用了6層的Encoder和Decoder
如傳統Transformer 模型就是建立在此結構上。它使用了6層的Encoder和Decoder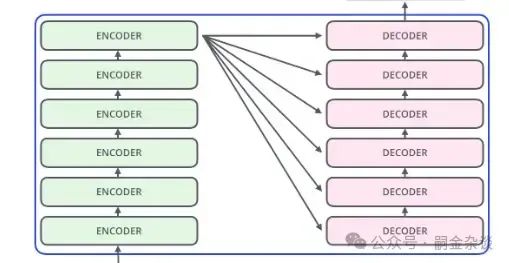
3.2.2 因果編碼器架構(Causal decoder)
這時當前主流使用的,采用單向注意力掩碼,以確保每個輸入標記只能關注過去的標記和它本身。輸入輸出標記通過解碼器以相同的方式處理。典型的模型有 GPT1/23, OPT, BLOOM, Gopher。
3.2.3 前綴解碼器架構(Prefix decoder)
修正了因果解碼器的掩碼機制,以使其能夠對前綴標記執行雙向注意力,并僅對生成的標記執行單向注意力。
這樣與編碼器-解碼器架構類似,前綴解碼器可以雙向編碼前綴序列并自回歸地逐個預測輸出標記,其中在編碼和解碼過程中共享相同的參數。總的來說,Encoder-Decoder適用于序列到序列的任務,Causal Decoder適用于需要生成自回歸序列的任務,而Prefix Decoder適用于需要根據特定前綴生成序列的任務。
3.3 模型訓練
在數據處理好,模型搭建好之后,就要開始對模型進行訓練。
四、微調和強化學習
在預訓練后,大語言模型可以獲得解決各種任務的通用能力。然而,還可以通過特定目標進一步調整,也就是微調(Instruction Tuning)
4.1 指令微調
通過在特定的指令性任務數據集上進行訓練,提高模型對于指令類輸入的理解和響應。指令的意思,舉個例子,對聊天機器人的指令,需要包括如“今天天氣如何”和對應的回答,供模型學習。也就是說需要包含明確指令的數據集,一個指令需要包括一個任務描述、一個輸入輸出對以及少量實例(可選)。常用的指令實例格式化方法有格式化已有的數據集還有格式化人類需求。指令微調對模型的性能改進和任務泛化能夠起到很好的作用
4.2 對齊微調
大語言模型有時可能表現出意外的行為,例如制造虛假信息、追求不準確的目標,以及產生有害的、誤導性的和偏見性的表達。為了避免這些意外行為,研究提出了人類對齊,使大語言模型行為能夠符合人類的期望也就是對齊微調。
在預訓練階段使用的訓練語料庫是沒有對模型的主觀定性評估的。所以可以在使用人類反饋的數據進行微調,這個過程稱為強化學。
五、應用
大語言模型作為具有廣泛應用的變革工具而受到重視。
文本生成:這些模型具有理解上下文、含義和語言的微妙復雜性的固有能力。因此,他們可以生成連貫且上下文相關的文本。
問答與信息檢索:大語言模型在問答和信息檢索領域正在快速發展。他們理解人類語言的卓越能力使他們能夠從龐大的數據存儲庫中提取相關細節。
情感分析與意見挖掘:了解人類的情感和觀點在不同的環境中都具有巨大的意義,從塑造品牌認知到進行市場分析。像在社交媒體監控和品牌認知分析領域的應用。
- 輔助代碼生成:如GitHub Copilot、通義靈碼
本文來源:嗣金雜談
-
語言模型
+關注
關注
0文章
520瀏覽量
10268 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595 -
LLM
+關注
關注
0文章
286瀏覽量
327
發布評論請先 登錄
相關推薦
什么是LLM?LLM在自然語言處理中的應用
如何訓練自己的LLM模型
新品|LLM Module,離線大語言模型模塊

理解LLM中的模型量化

大模型LLM與ChatGPT的技術原理
llm模型和chatGPT的區別
LLM模型的應用領域
什么是LLM?LLM的工作原理和結構
LLM之外的性價比之選,小語言模型
了解大型語言模型 (LLM) 領域中的25個關鍵術語
模型與人類的注意力視角下參數規模擴大與指令微調對模型語言理解的作用

2023年大語言模型(LLM)全面調研:原理、進展、領跑者、挑戰、趨勢





 工商網監
工商網監
評論