 如何基于OrangePi?AIpro開發AI推理應用
如何基于OrangePi?AIpro開發AI推理應用
香橙派AIpro開發板采用昇騰AI技術路線,接口豐富且具有強大的可擴展性,提供8/20TOPS澎湃算力,可廣泛使用于AI邊緣計算、深度視覺學習及視頻流AI分析、視頻圖像分析、自然語言處理等AI領域。通過昇騰CANN軟件棧的AI編程接口,可滿足大多數AI算法原型驗證、推理應用開發的需求。
AscendCL(Ascend Computing Language,昇騰計算語言)是昇騰計算開放編程框架,是對底層昇騰計算服務接口的封裝,提供Device管理、Context管理、Stream管理、內存管理、模型加載與執行、算子加載與執行、媒體數據處理等API,支持C&C++、Python編程語言,能夠實現深度學習推理計算、圖形圖像預處理、單算子加速計算等能力。
掌握了AscendCL的編程方法,就意味著可以在香橙派AIpro開發板上充分利用昇騰的算力資源,能夠基于深度學習算法開發圖片分類、目標檢測等一系列深度學習推理計算程序。
01總體流程
使用AscendCL開發推理應用時,開發流程大致分為以下幾步:
1.AscendCL初始化:初始化AscendCL內部資源,為程序運行做準備
2.運行管理資源申請:申請運行時相關資源,例如計算設備
3.媒體數據處理:可實現摳圖、縮放、視頻或圖片的編解碼等
4.模型推理:包括模型加載、執行、卸載
5.運行管理資源釋放:資源使用后及時釋放
6.AscendCL去初始化:與初始化配對使用
在開始之前,我們得先了解下,使用AscendCL時經常會提到的“數據類型的操作接口” ,它是什么?為什么會存在?
在C/C++中,對用戶開放的數據類型通常以Struct結構體方式定義、以聲明變量的方式使用,但這種方式一旦結構體要增加成員參數,用戶的代碼就涉及兼容性問題,不便于維護,因此AscendCL對用戶開放的數據類型,均以接口的方式操作該數據類型,例如,調用某個數據類型的Create接口創建該數據類型、調用Get接口獲取數據類型內參數值、調用Set接口設置數據類型內的參數值、調用Destroy接口銷毀該數據類型,用戶無需關注定義數據類型的結構體長什么樣,這樣即使后續數據類型需擴展,只需增加該數據類型的操作接口即可,也不會引起兼容性問題。
所以,總結下,“數據類型的操作接口”就是創建數據類型、Get/Set數據類型中的參數值、銷毀數據類型的一系列接口,存在的最大好處就是減少兼容性問題。
接下來,進入我們今天的主題,怎么用AscendCL的接口開發網絡模型推理場景下的應用。
02AscendCL初始化與去初始化
使用AscendCL接口開發應用時,必須先初始化AscendCL ,否則可能會導致后續系統內部資源初始化出錯,進而導致其它業務異常。在初始化時,還支持以下跟推理相關的配置項(例如,性能相關的采集信息配置),以json格式的配置文件傳入AscendCL初始化接口。如果當前的默認配置已滿足需求(例如,默認不開啟性能相關的采集信息配置),無需修改,可向AscendCL初始化接口中傳入NULL,或者可將配置文件配置為空json串(即配置文件中只有{})。
有初始化就有去初始化,在確定完成了AscendCL的所有調用之后,或者進程退出之前,需調用AscendCL接口實現AscendCL去初始化。

03運行管理資源申請與釋放
運行管理資源包括Device、Context、Stream、Event等,此處重點介紹Device、Context、Stream,其基本概念如下圖所示 。
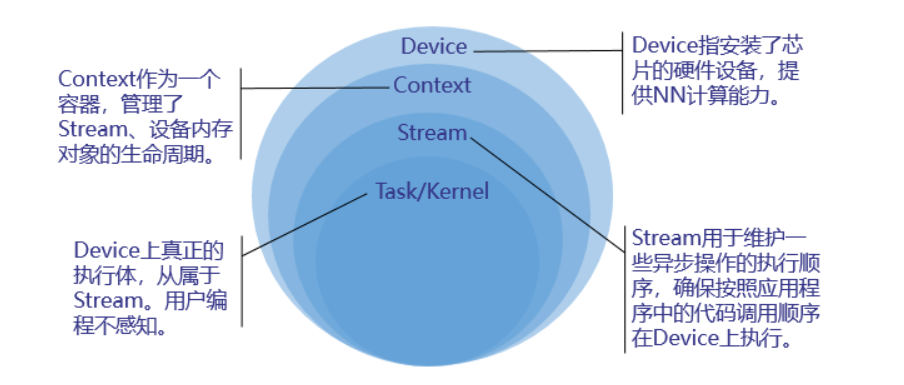
您需要按順序依次申請如下運行管理資源:Device、Context、Stream,確保可以使用這些資源執行運算、管理任務。所有數據處理都結束后,需要按順序依次釋放運行管理資源:Stream、Context、Device。
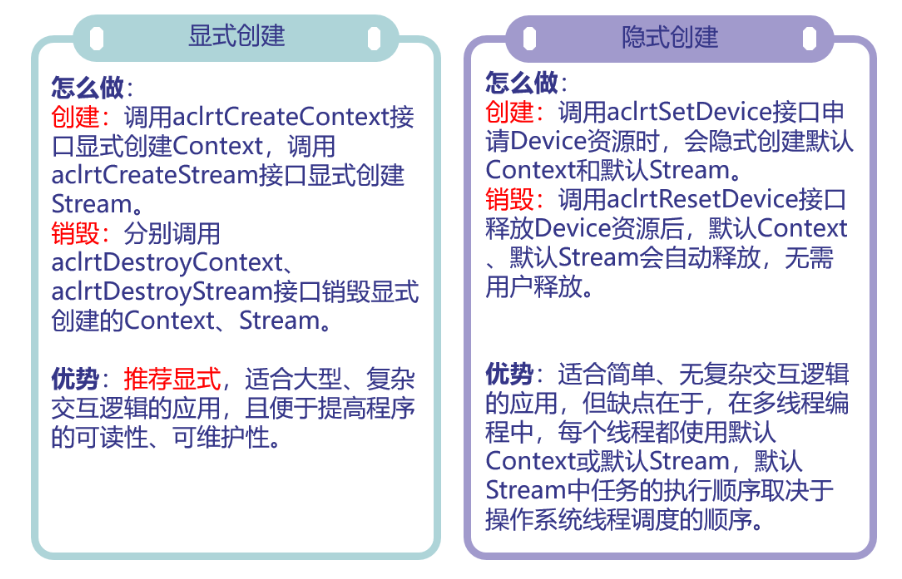
在申請運行管理資源時,Context、Stream支持隱式創建和顯式創建兩種申請方式:

04媒體數據處理
如果模型對輸入圖片的寬高要求與用戶提供的源圖不一致,AscendCL提供了媒體數據處理的接口,可實現摳圖、縮放、格式轉換、視頻或圖片的編解碼等,將源圖裁剪成符合模型的要求。后續會展開說明這個功能,本期著重介紹模型推理的部分,以輸入圖片滿足模型的要求為例。
05模型加載
模型推理場景下,必須要有適配昇騰AI處理器的離線模型(*.om文件),我們可以使用ATC(Ascend Tensor Compiler)來構建模型。如果模型推理涉及動態Batch、動態分辨率等特性,需在構建模型增加相關配置。關于如何使用ATC來構建模型,請移步文末“昇騰社區文檔中心”。
有了模型,就可以開始加載了,當前AscendCL支持以下幾種方式加載模型:
·從*.om文件中加載模型數據,由AscendCL管理內存
·從*.om文件中加載模型數據,由用戶自行管理內存
·從內存中加載模型數據,由AscendCL管理內存
·從內存中加載模型數據,由用戶自行管理內存
由用戶自行管理內存時,需關注工作內存、權值內存。工作內存用于存放模型執行過程中的臨時數據,權值內存用于存放權值數據。這個時候,是不是有疑問了,我怎么知道工作內存、權值內存需要多大?不用擔心,AscendCL不僅提供了加載模型的接口,同時也提供了“根據模型文件獲取模型執行時所需的工作內存和權值內存大小”的接口,方便用戶使用 。


06模型執行
在調用AscendCL接口進行模型推理時,模型推理有輸入、輸出數據,輸入、輸出數據需要按照AscendCL規定的數據類型存放。相關數據類型如下:
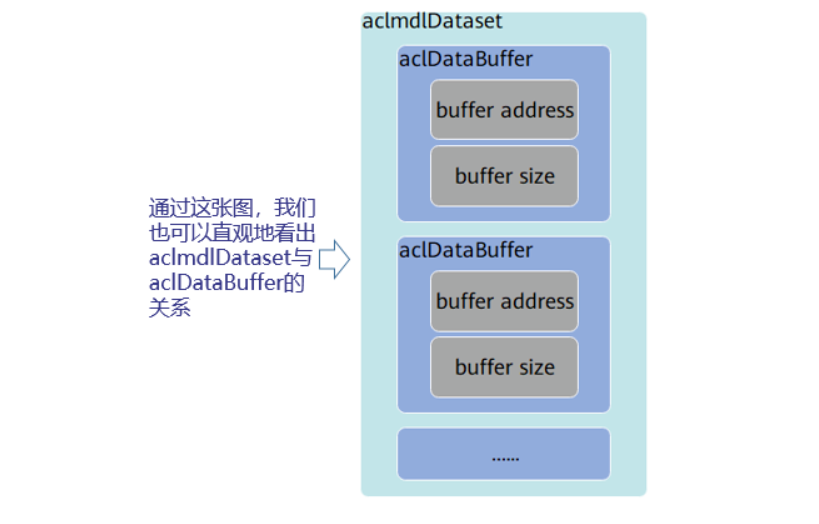
·使用aclmdlDesc類型的數據描述模型基本信息(例如輸入/輸出的個數、名稱、數據類型、Format、維度信息等)。模型加載成功后,用戶可根據模型的ID,調用該數據類型下的操作接口獲取該模型的描述信息,進而從模型的描述信息中獲取模型輸入/輸出的個數、內存大小、維度信息、Format、數據類型等信息。
·使用aclDataBuffer類型的數據來描述每個輸入/輸出的內存地址、內存大小。調用aclDataBuffer類型下的操作接口獲取內存地址、內存大小等,便于向內存中存放輸入數據、獲取輸出數據。
·使用aclmdlDataset類型的數據描述模型的輸入/輸出數據。模型可能存在多個輸入、多個輸出,調用aclmdlDataset類型的操作接口添加多個aclDataBuffer類型的數據。

準備好模型執行所需的輸入和輸出數據類型、且存放好模型執行的輸入數據后,可以執行模型推理了,如果模型的輸入涉及動態Batch、動態分辨率等特性,則在模型執行前,還需要調用AscendCL接口告訴模型本次執行時需要用的Batch數、分辨率等。
當前AscendCL支持同步模型執行、異步模型執行兩種方式,這里說的同步、異步是站在調用者和執行者的角度。
·若調用模型執行的接口后需等待推理完成再返回,則表示模型執行是同步的。當用戶調用同步模型執行接口后,可直接從該接口的輸出參數中獲取模型執行的結果數據,如果需要推理的輸入數據量很大,同步模型執行時,需要等所有數據都處理完成后,才能獲取推理的結果數據。
·若調用模型執行的接口后不等待推理完成完成再返回,則表示模型執行是異步的。當用戶調用異步模型執行接口時,需指定Stream( Stream用于維護一些異步操作的執行順序,確保按照應用程序中的代碼調用順序在Device上執行),另外,還需調用aclrtSynchronizeStream接口阻塞程序運行,直到指定Stream中的所有任務都完成,才可以獲取推理的結果數據。如果需要推理的輸入數據量很大,異步模型執行時,AscendCL提供了Callback機制,觸發回調函數,在指定時間內一旦有推理的結果數據,就獲取出來,達到分批獲取推理結果數據的目的,提高效率。

推理結束后,如果需要獲取并進一步處理推理結果數據,則由用戶自行編碼實現。最后,別忘了,我們還要銷毀aclmdlDataset、aclDataBuffer等數據類型,釋放相關內存,防止內存泄露。
07模型卸載
在模型推理結束后,還需要通過aclmdlUnload接口卸載模型,并銷毀aclmdlDesc類型的模型描述信息、釋放模型運行的工作內存和權值內存。

(以上內容來源于昇騰CANN公眾號)
-
Orange
+關注
關注
0文章
82瀏覽量
19665 -
AI
+關注
關注
87文章
30728瀏覽量
268886 -
開發板
+關注
關注
25文章
5032瀏覽量
97371 -
邊緣計算
+關注
關注
22文章
3084瀏覽量
48891
發布評論請先 登錄
相關推薦
AI算法在RZ/V芯片中的移植推理流程
基于OrangePi AIpro開發一個電子紙屏時鐘

開發者手機 AI - 目標識別 demo
【HarmonyOS HiSpark AI Camera】AI圖像開發
Dllite_micro (輕量級的 AI 推理框架)
深度剖析OpenHarmony AI調度管理與推理接口
嘉楠勘智K510開發板簡介——高精度AI邊緣推理芯片及應用
HarmonyOS:使用MindSpore Lite引擎進行模型推理
安晟培半導體通過AI推理應用程序進一步增強 Ampere Altra 的性能
邊緣AI推理應用設計的發展
香橙派聯合華為發布基于昇騰的Orange Pi AIpro開發板 業界首款基于昇騰AI開發板

ONNX Runtime支持龍架構,AI推理生態再添新翼
OrangePi AIpro應用:機械臂應用開發指南






 工商網監
工商網監
評論