

在我們的 先前的圖分析探索 中,我們使用 NVIDIA cuGraph 揭示了 GPU-CPU 融合的變革力量。基于這些見解,我們現在引入了一種革命性的新架構,它重新定義了圖處理的邊界。
圖形處理的發展
在我們早期涉足圖形分析的過程中,我們在使用的架構方面面臨著各種挑戰。這種體系結構雖然有效,但也造成了阻礙設置和性能的障礙。
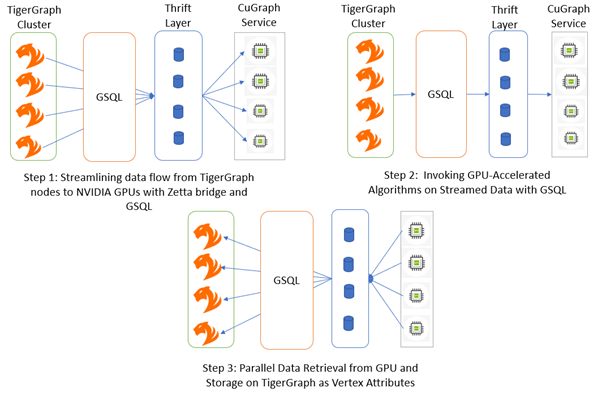
圖 1.(以前的體系結構)使用 TigerGraph、cuGraph 和 GSQL 進行高性能圖形分析的過程
以前體系結構的挑戰
對磁盤的依賴關系:我們在 TigerGraph 和 cuGraph 之間使用基于磁盤的數據傳輸,這會對可擴展性和性能造成限制。組件之間的數據傳輸依賴于臨時磁盤,從而引入延遲和潛在的性能瓶頸。
Python 依賴項:使用 Python 運行 cuGraph 將引入開銷和復雜性,從而影響性能,特別是在圖形處理等計算密集型任務中。
節儉層:節儉的通信會增加復雜性和開銷,從而可能影響系統的可靠性。
對設置和性能的影響
這些依賴關系不僅使設置過程復雜化,而且對實現最佳性能也提出了挑戰。對共享磁盤基礎設施的需求,加上基于 Python 的服務和 Thrift 通信,造成了一個難以有效配置和擴展的系統。
在我們尋求加速圖形分析的過程中,很明顯,范式轉變是必要的。進入下一代架構,這是一種革命性的方法,旨在克服前代架構的局限性,開啟圖形處理的新領域。讓我們詳細探討一下這一突破性的體系結構。
介紹下一代架構
在我們尋求徹底改變圖形分析的過程中,我們精心打造了代表圖形處理范式轉變的下一代架構。該體系結構完全構建在 C++中,利用尖端技術實現了前所未有的性能和可擴展性。
理解 TigerGraph 中的 GSQL 查詢執行過程
在深入研究我們新體系結構的復雜性之前,了解 GSQL 查詢傳統上是如何在 TigerGraph 集群中執行的至關重要:
步驟 1:編譯
GSQL 查詢將經編譯,然后轉換為 C++ 代碼。隨后,編譯這些代碼,并將其與專有的 TigerGraph 庫進行鏈接,以便執行準備。
第 2 步:執行
編譯后,將使用圖形處理引擎(GPE)在 TigerGraph 集群上執行查詢。GPE 負責管理集群通信,并協調分布式環境中算法的執行。
升級下一代體系結構
在我們的下一代體系結構中,我們對編譯和執行階段進行了重大升級,利用 GPU 加速的力量并簡化了處理流程:
步驟 1:增強加速的查詢編譯
我們通過將 cuGraph CUDA 庫直接集成到 TigerGraph 中,實現了對 GPU 加速圖形處理功能的無縫訪問。基于 cuGraph 庫,我們開發了 ZettaAccel,這是一個自定義的 C++ 庫,它公開了在 GSQL 查詢中可用作用戶定義函數(UDF)的函數。現在,在查詢編譯過程中,GSQL 查詢被編譯并與 TigerGraph、CUDA cuGraph 和 ZettaAccel 庫鏈接,從而解鎖其核心的加速圖處理能力。
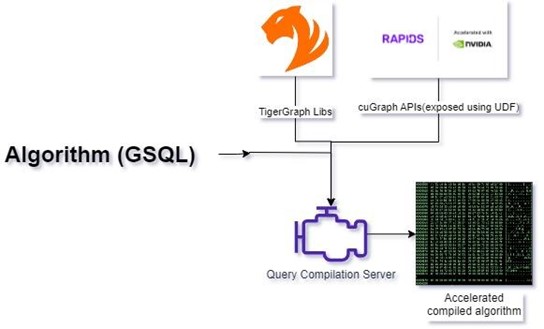
圖 2:加速 GSQL 編譯
步驟 2:通過 GPU 資源管理優化執行
在執行時,我們的體系結構使用 RAPID 生態系統庫動態分配 GPU 資源,以確保可用硬件的最佳利用率。圖形數據通過 ZettaAccel 庫從 TigerGraph 高效地傳輸到 GPU 內存,其中它被無縫轉換為可供處理的圖形結構。然后,算法直接在 GPU 上執行,利用其并行處理能力獲得無與倫比的性能提升。最后,生成的數據被無縫地傳輸回 CPU 和 TigerGraph,以進行進一步的分析和集成。
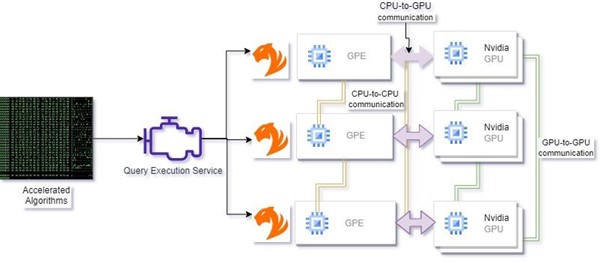
圖 3。加速 GSQL 執行
下一代架構的優勢
下一代架構代表了圖形處理效率和可擴展性的巨大飛躍:
前所未有的性能:通過充分利用 GPU 加速和精簡處理管道,我們的架構提供了無與倫比的性能提升,從而能夠快速執行復雜的圖形算法。
簡化的設置:通過將 cuGraph 和 ZettaAccel 集成到 TigerGraph 中,我們簡化了設置過程,消除了對復雜依賴關系的需求,并減少了配置開銷。
可擴展性和靈活性:借助動態 GPU 資源管理和高效的數據傳輸機制,我們的架構可以輕松擴展,以處理大規模的圖形數據集和多樣化的處理工作負載。
利用加速的 GSQL 構造進行圖形處理
為了利用加速的 GSQL 構造的力量進行高效的圖形處理,用戶可以遵循分為三個階段的結構化方法:流式圖形構造、算法執行和結果檢索。
讓我們以 pagerank 為例來看看所有三個階段:-
1.流圖構建:
在這個階段,用戶通過指定數據處理所需的關系和累加器來定義流圖。
|
SELECT s FROM Start:s -(friend:f)- :t ACCUM int graph_obj=@@graph_per_server.get(server_id) udf_stream_edges(graph_obj,getvid(s),getvid(t),store_transposed); |
在這里,用戶可以建立初始的圖結構,并積累相關信息,如圖對象和自定義流功能。這個udf_stream_edges 函數能夠有效地處理邊緣流并更新圖形結構。
2.執行算法:
一旦構建了流圖,用戶就可以使用 GSQL 結構高效地執行他們想要的算法。
|
V = SELECT s FROM vertex_per_server:s ACCUM udf_prank_execute(@@graph_per_server.get(s.@server_id),@@vertices_per_server.get(s.@server_id)); |
在這個階段,用戶使用加速的 GSQL 構造來執行像 PageRank 這樣的算法。這個udf_prank_execute函數可以有效地計算分布在服務器上的頂點的 PageRank 分數,從而優化算法執行時間。
3.檢索結果:
在執行算法之后,用戶從圖中取回計算結果,用于進一步分析或可視化。
|
V = SELECT s FROM Start:s ACCUM s.@score=udf_pagerank_score(@@graph_per_server.get(server_id),getvid(s)); |
在這里,用戶檢索在算法執行期間計算的 PageRank 分數,并將其存儲為頂點屬性,用于后續分析或可視化。
通過遵循這三個階段,用戶可以有效地利用加速的 GSQL 構造來簡化圖形處理任務,優化算法執行,并高效地從圖形數據中檢索有價值的見解。
績效基準和結果
圖形算法性能比較
該基準測試在 2 節點集群上進行,每個節點都具有 4x NVIDIA A100 40GB GPU、AMD EPYC 7713 64 核處理器和 512GB RAM。
基準數據集
Graphalytics 是由鏈接數據基準委員會(LDBC)開發的綜合基準套件,旨在評估圖形數據庫管理系統(GDBMS)和圖形處理框架的性能。它提供了真實世界的數據集、不同的工作負載和一系列圖形算法,以幫助研究人員和組織評估系統的效率和可擴展性。欲了解更多信息,請參閱 LDBC 圖形分析基準。
| 圖表 | 頂點 | 邊緣 | TigerGraph 群集(秒) | cuGraph+TigerGraph(python)(秒) | cuGraph+TigerGraph(本機)(秒) |
| 圖 22 | 239 萬? | 6400 萬 | 311.162 | 12.14(25 倍) | 6.91(45 倍) |
| 圖 23 | 460 萬? | 1.29 億 | 617.82 | 14.44(42X) | 9.04(68 倍) |
| 圖 24 | 887 萬 | 260 米 | 1205.34 | 24.63(48 倍) | 14.69(82 倍) |
| 圖表 25 | 1706 萬? | 5.23 億 | 2888.74 | 42.5(67 倍) | 21.09(137 倍) |
| 圖 26 | 3280 萬? | 10.5 億 | 4842.4 | 73.84(65 倍) | 41.01(118 倍) |
表 1。與 cuGraph 加速(Python 和 Native)集成方法相比,基于 TigerGraph CPU 的解決方案
優化圖形處理:在 TigerGraph 中集成 cuGraph 的成本分析
在追求增強圖形處理能力的過程中,cuGraph 與 TigerGraph 的集成已被證明是游戲規則的改變者。通過在 TigerGraph 框架內利用 cuGraph 的 GPU 加速功能,我們不僅實現了顯著的速度提高,還顯著降低了總體成本。
機器信息:以下是機器的詳細信息:
實例名稱:m7a.32xlarge
節點總數:2 個
按需時薪:7.41888 美元
vCPU 數量:128
內存大小:512 GiB
實例名稱:p4d.24xlarge
節點總數:1 個
按需時薪:$32.77
vCPU 數量:96
內存大小:1152 GiB
GPU 信息:
規格: NVIDIA A100 GPU
計數:8
內存:320 GB HBM2
| 圖表 | TigerGraph 群集(秒) | cuGraph+TigerGraph(本機)(秒) | CPU 成本 | GPU 成本 | 收益(X) |
| 圖 22 | 311.162 | 6.91(45 倍) | $1.28 | $0.06 | 20 |
| 圖 23 | 617.82 | 9.04(68 倍) | $2.55 | $0.08 | 31 |
| 圖 24 | 1205.34 | 14.69(82 倍) | $4.97 | $0.13 | 37 |
| 圖表 25 | 2888.74 | 21.09(137 倍) | $11.91 | $0.19 | 62 |
| 圖 26 | 4842.4 | 41.01(118 倍) | $19.96 | $0.37 | 53 |
表 2。與我們的基準機器相似的 AWS 機器的成本分析
這些結果表明,當將 cuGraph 與 TigerGraph 集成時,圖形處理的速度顯著提高了 100 倍。同時,成本分析顯示,總體成本大幅降低了 50 倍,顯示了這種集成的效率和成本效益。這種優化不僅確保了卓越的性能,而且為圖形分析工作負載提供了更經濟的解決方案。
總結
在對圖形分析的全面探索中,我們開始了一段徹底改變處理和分析復雜圖形數據方式的旅程。從傳統架構的挑戰到我們下一代解決方案的推出,本文涵蓋了一系列主題,展示了先進技術和創新方法的變革力量。
圖形處理技術的發展:
我們首先剖析了傳統圖形處理架構的局限性,強調了對共享磁盤基礎設施、Python 和 Thrift 通信層的依賴性。這些挑戰凸顯了對圖形分析新方法的需求,這種方法可以釋放新的性能、可擴展性和效率水平。
介紹下一代架構:下一代架構的引入。
進入我們的下一代架構——圖形處理中改變游戲規則的范式轉變。我們的體系結構完全構建在 C++中,利用一系列尖端技術,包括 cuGraph、Raft、NCCL 和 ZettaAccel,將圖形分析加速到前所未有的高度。
關鍵進展和創新:
通過我們的新體系結構,我們徹底改變了圖形處理的編譯和執行階段。通過將 cuGraph 和 ZettaAccel 直接集成到 TigerGraph 中,我們簡化了編譯過程,消除了復雜的依賴關系,并解鎖了 GPU 加速的圖形處理的核心。我們的體系結構的動態 GPU 資源管理和精簡的數據傳輸機制確保了各種圖形處理任務的最佳性能和可擴展性。
前所未有的性能和可擴展性:無與倫比的計算能力和靈活的架構設計。
結果不言自明——我們的下一代架構提供了無與倫比的性能提升,實現了復雜圖形算法的快速執行和處理大規模數據集的無縫可擴展性。通過利用 GPU 加速和創新 C++技術的力量,我們重新定義了圖形分析的邊界,使組織能夠釋放新的見解,推動不同領域的創新。
未來的發展方向和機遇:
當我們展望未來時,可能性是無限的。隨著 GPU 技術、算法優化以及與新興框架的集成的不斷進步,我們的體系結構將繼續發展,突破圖形分析的極限。
開始使用
如果你渴望利用加速圖形處理的力量,以下是你如何開始你的旅程:
檢查您的要求:確保您的 TigerGraph 版本 3.9.X 和 NVIDIA GPU 配備了 RAPID 支持。這些先決條件對于釋放加速圖形處理的潛力至關重要。
表達您的興趣:如果您對探索加速圖形處理感興趣,請聯系 TigerGraph 或Zettabolt。無論您是經驗豐富的數據科學家還是圖形分析的新手,他們的團隊都會隨時為您提供幫助。
指導和支持:一旦您表達了興趣,TigerGraph 或 Zettabolt 的專家將指導您完成最初的步驟,為您提供所有必要的信息,以啟動您的加速圖形處理之旅。從設置基礎架構到微調性能,他們的支持確保了實施的順利和成功。
審核編輯 黃宇
-
NVIDIA
+關注
關注
14文章
5174瀏覽量
105201 -
gpu
+關注
關注
28文章
4861瀏覽量
130172 -
算法
+關注
關注
23文章
4666瀏覽量
94130 -
圖形分析
+關注
關注
0文章
3瀏覽量
910
發布評論請先 登錄
相關推薦





 工商網監
工商網監

評論