

英特爾CEO帕特·基辛格在COMPUTEX 2024上發表主題演講,正式公布了下一代面向AI PC的移動處理器Lunar Lake,不僅CPU、GPU、NPU性能全面提升,能耗也大幅降低,綜合AI算力提升至120TOPS。

1、Lunar Lake首次全部由臺積電代工,但下一代的Panther lake將重回英特爾代工
據介紹Lunar Lake由7個主要部分組成,整個封裝包含內存、加固器和底層芯片,底層芯片使用Intel Foveros互連技術將計算芯片和平臺控制器芯片結合在一起。在工藝節點方面,Lunar Lake計算芯片(包括CPU、GPU和NPU等)采用臺積電的N3B工藝節點制造,平臺控制器芯片則采用臺積電的N6工藝節點制造,也就是說這款芯片的主要核心die全部都是由臺積電代工!
要知到之前英特爾的高端移動平臺芯片雖然有部分核心是交由臺積電代工,但是CPU核心一直是英特爾自己生產的。而這種轉變,一方面是臺積電在制程技術上的領先,另一方面則可能與英特爾代工業務獨立分拆有關。英特爾代工業務獨立分拆,使得英特爾的設計業務可以更自由的選擇外部更有競爭力的供應商,但是這對于英特爾代工業務集團來說并不是一個好消息,所幸的是Lunar Lake的封裝還是交由英特爾代工業務集團來完成的。
對此,基辛格表示,Lunar Lake之所以選擇臺積電制造,是因為當時臺積電有更好的制程技術,現在看仍是好選擇。感謝臺積電,提供了很多核心關鍵制造技術,使Lunar Lake成為可能,也能看出臺積電和英特爾在代工產業的合作,包括UCIe(通用小芯片互連)也是。
不過基辛格強調,到下一代Panther lake將幾乎全部是基于英特爾制程,將采用Intel 18A工藝,還有混合鍵合技術、晶圓對晶圓(Wafer to Wafer)堆疊,還有先進封裝技術和背面供電技術,希望屆時能夠向大家展示英特爾的晶圓廠能力。
1、CPU核心:4個P核+4個E核,性能及效率大幅提升
據介紹,Lunar Lake的CPU內核依然采用的Hybrid核心架構設計,擁有4個Lion Cove P-core性能核心和4個Skymont E-core效率核心,組合成8核心混合設計,以達到性能與效率的最佳。
Lunar Lake的Lion Cove P-core性能核心在緩存層次上進行了眾大改進,其采用了多層數據緩存,每個核心包括一個 48KB L0D 緩存(加載到使用延遲為 4 周期)、一個 192KB L1D 緩存(延遲為 9 周期)、一個擴展的 L2 緩存(最高可達 3MB,延遲為 17 周期)。總的來說,這使得 240KB 緩存的延遲時間與 CPU 內核的延遲時間相差無幾,而之前的 Redwood Cove 只能在相同時間內達到 48KB 緩存。4個P核心還共享了12MB L3緩存,可以帶來更出色的單線程性能,并優化核心PPA設計。
英特爾添加了第三個地址生成單元 (AGU)/存儲單元對,以進一步提升存儲性能。值得注意的是,這使加載和存儲管道的數量達到平衡,分別為 3 個;在大多數英特爾架構中,加載單元的數量都比存儲單元多。
總體而言,英特爾在真正的長期 CPU 設計理念中,已經投入了更多緩存來解決這個問題。隨著 CPU 復雜度的增加,緩存子系統也在不斷增加,以保證其正常運行。在這種情況下,保證 CPU 正常運行是提高其性能和保持其能效的關鍵改進。
深入研究 Lion Cove 的計算架構,該架構在英特爾的 P 核設計上專注于提高性能和效率。該架構采用一種新的前端方法來處理指令,其預測塊比以前大 8 倍,提取范圍更廣,解碼帶寬更高,Uops 緩存容量和讀取帶寬也大幅增加。UOP 隊列容量增加,這也提高了整體吞吐量。在執行過程中,Lion Cove 的無序引擎在整數 (INT) 和矢量 (VEC) 域之間劃分,具有獨立的重命名和調度功能。
數據轉換后備緩沖區 (DTLB) 也進行了修改,將其深度從 96 頁增加到 128 頁,以提高其命中率。這種分區方式可以實現未來的可擴展性、每個域的獨立增長,并且有利于降低特定域工作負載的功耗。亂序引擎也得到了改進,分配/重命名從 6 個增加到 8 個,退出從 8 個增加到 12 個,深度指令窗口從 512 個增加到 576 個,執行端口從 12 個增加到 18 個。這些變化使管道更加穩健,執行起來也更加靈活。
Lion Cove 中的整數執行單元也得到了改進:整數 ALU 從 5 個增加到 6 個,跳躍單元從 2 個增加到 3 個,移位單元從 2 個增加到 3 個。它們將64x64單元增加到超過64,并從 1 個單元增加到 3 個,為最復雜的操作提供更強大的計算能力。另一個顯著的進步是 P 核心數據庫從“sea of fubs”遷移到了 “sea of cells”。更新 P 核心子結構組織的過程從微小的、以鎖存器為主的分區轉變為更廣泛、更大的以觸發器為主的分區,這些分區在發展過程中非常不可知。
Lion Cove 架構也與性能提升保持一致,與上一代 Redwood Cove 相比,IPC 性能預計將提升兩位數百分比。這種提升尤其明顯,尤其是在超線程的改進方面,IPC 提高了 30%,動態功率效率提高了 20%,并且在不增加核心面積的情況下平衡了先前的技術,體現了英特爾在現有物理限制內提高性能的承諾。
Lion Cove 的電源管理也得到了改進,包括采用 AI 自調節控制器來取代靜態熱保護帶。它讓系統以自適應方式動態響應實際的實時運行條件,以實現更高的持續性能。它使用更精細的時鐘粒度,現在間隔為 16.67MHz。與 100MHz 相比,這意味著更精確的電源管理和性能調整,從而從功率預算中獲得最大效率。
至少從紙面上看,Lion Cove 看起來比 Golden Cove 有了很大的改進。它整合了改進的內存和緩存子系統、更好的電源管理以及 IPC 性能的提升,而不是專注于提高頻率。
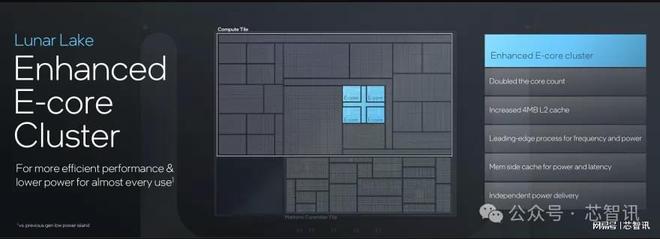
Lunar Lake的Skymont E-core效率核心是專為實現全新水平的性能效率而設計。4個E-core共享4MB L2緩存,能比上一代有著超過2倍的省電表現,并比上一代提升2倍的Vector與AI輸出性能。
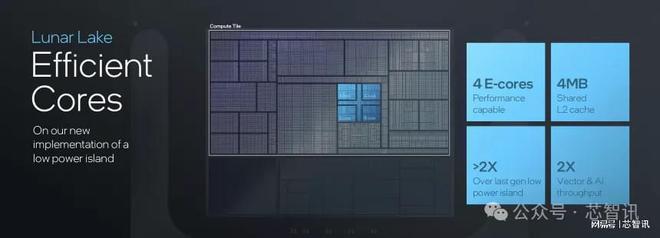
Skymont 核心具有更全面的微架構,首先是 9-wide 解碼階段,其解碼簇比前幾代多 50%。這由更大的微操作隊列支持,現在可容納 96 個條目,而舊設計中只有 64 個。使用“Nanocode”可在每個解碼簇內增加更多微代碼并行性。
Skymont核心的無序執行引擎也得到了顯著改進。分配寬度增加到 8-wide,而退出階段則加倍到 16-wide。這增強了內核同時發出和執行多條指令的能力,并通過依賴中斷機制減少了延遲。
Skymont 將重排序緩沖區從之前的 256 個條目加深到 416 個條目,以提供排隊和緩沖功能。此外,物理寄存器文件 (PRF) 和保留站的大小也增加了。這些增強功能使內核能夠處理更多正在運行的指令,從而提高指令執行的并行性。
需要注意的是,調度端口最初為 26 個,其中 8 個用于整數 ALU,3 個用于跳轉操作,3 個用于每個周期的加載操作,從而進一步實現了靈活高效的資源分配。在矢量性能方面,Skymont 支持 4×128 位 FP 和 SIMD 矢量,這使每秒千兆次浮點運算 (Gigaflops/TOPs) 翻倍,并降低了浮點運算的延遲。英特爾還重新設計了內存子系統,四個內核共享 4MB L2 緩存,將 L2 帶寬翻倍至每周期 128B,在此過程中,降低了內存訪問延遲,同時提高了數據吞吐量。
英特爾公布的性能指標,凸顯了Skymont E核的電源效率的顯著提升:與上代的Meteor Lake 的 LP E 核相比,單線程性能提高了 1.7 倍,而功耗僅為其三分之一。
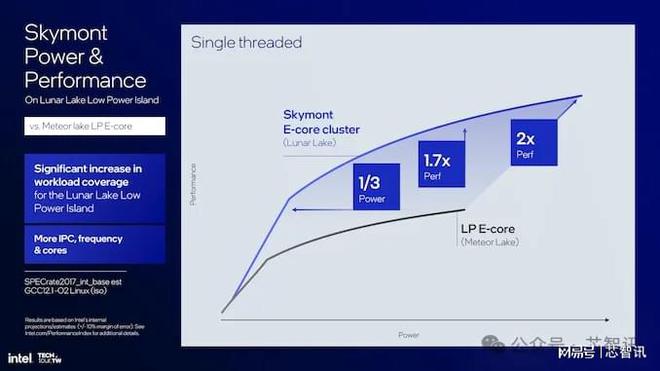
當將 Skymont E-core 集群與 Meteor Lake的 LP E-core 集群直接進行比較時,多線程性能提高了 2.9 倍,而功耗卻全面降低。
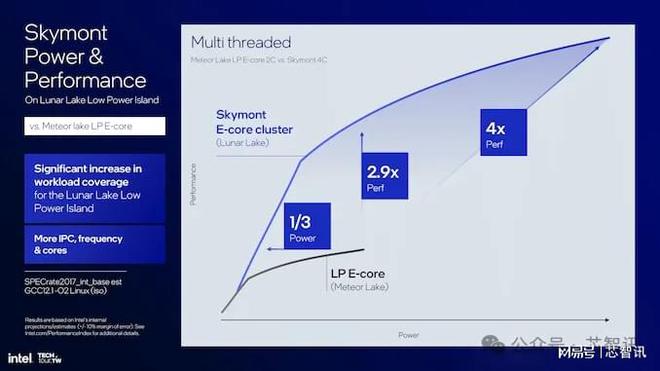
這對于移動和桌面設計同樣有用。換句話說,Skymont E 核心非常靈活,在移動場景中充分利用了低功耗結構和系統緩存,并針對桌面計算塊優化了多線程吞吐量。與 Raptor Cove 相比,Skymont在單線程工作負載中提供了 2% 更好的整數和浮點性能,其功率和熱量范圍幾乎與其前代產品相同。
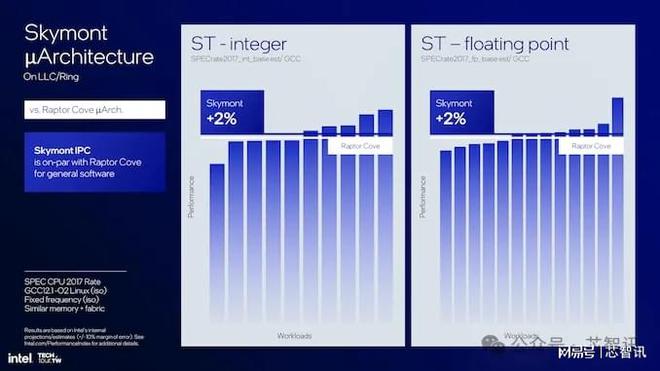
Skymont E 核代表了英特爾內核架構開發的下一步,在解碼、執行、內存子系統和電源效率方面取得了顯著的進步,滿足了更節能計算的需求,并且比以前的 Crestmont E 核提高了 IPC 增益。

2、GPU性能提升50%,還有全新顯示、多媒體和圖像引擎
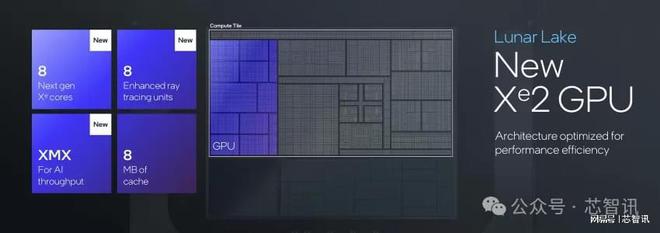
Lunar Lake的GPU采用的是新一代的Xe2 GPU構架,擁有8組新一代Xe核心、8個光線追蹤單元、XMX AI引擎和8MB的專屬緩存。能夠提供67 GPU TOPS的算力、實時的光線追蹤、基于AI的XeSS畫質提升、Intel Arc軟件堆疊等功能,相比上一代Meteor Lake能帶來50%的圖形處理性能提升。
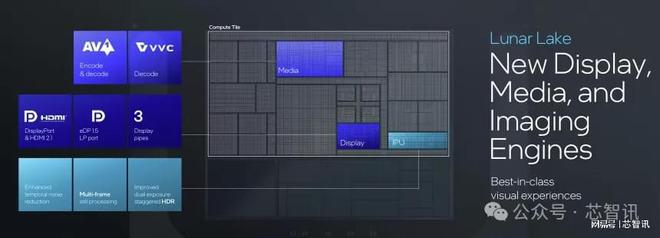
Lunar Lake內部還集成了與GPU搭配的全新顯示、多媒體和圖像引擎(IPU)。其中,顯示核心擁有3個eDP 1.5、DP與HDMI 2.1輸出接口,多媒體引擎支持AV1和最新的VVC編譯功能,IPU則可提供Temporal noise reduction、Multi-frame與Dual exposure staggered HDR等圖像強化功能。
具體來說,英特爾的 eDisplayPort 1.5 包含面板重放功能,該功能集成了自適應同步和選擇性更新機制。這有助于通過僅刷新屏幕發生變化的部分而不是整個顯示屏來降低功耗。這些創新不僅節省能源,而且還通過減少顯示延遲和提高同步精度來改善視覺體驗。
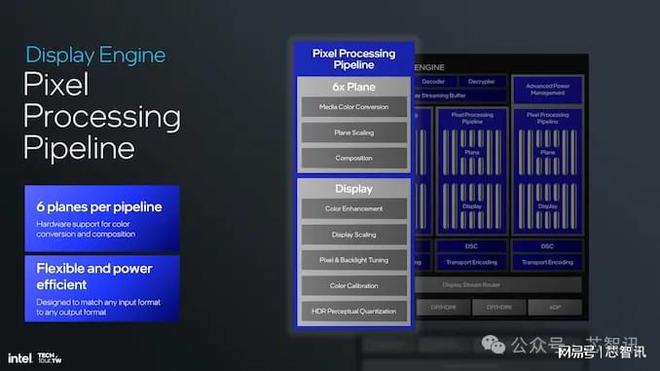
描繪像素處理管道是英特爾顯示引擎所依賴的基本基礎之一,每條管道支持六個平面,用于高級顏色轉換和合成。此外,它還集成了對顏色增強、顯示縮放、像素調整和 HDR 感知量化的硬件支持,確保屏幕上的圖形生動準確。該設計非常靈活,非常節能,性能經過精心設計,至少在紙面上支持各種輸入和輸出格式。到目前為止,英特爾尚未提供任何可量化的功率指標、TDP 或其他功率元素。
在壓縮和編碼方面,Xe2 架構可無損地將顯示流壓縮率提高到 3:1,包括針對 HDMI 和 DisplayPort 協議的傳輸編碼。這些芯片功能可進一步降低數據負載,并在輸出端保持高分辨率,而不會損失視覺質量。

多媒體引擎方面,英特爾采用 VVC 編解碼器對視頻壓縮技術的改進意義重大。與 AV1 相比,此編解碼器可將文件大小減少 10%,并支持自適應分辨率流媒體和針對 360 度和全景視頻的高級內容編碼。這將確保流媒體的比特率較低,而不會降低質量——這是現代多媒體應用的一個基本方面。

Windows GPU 軟件堆棧從上到下都非常強大,支持 D3D、Vulkan 和 Intel VPL API 和框架。這意味著,結合這些品質可以為市場上各種運行時和驅動程序提供全面支持,從而提高其在不同軟件環境中的整體效率和兼容性。

3、NPU算力提升至48TOPS
作為新一代面向筆記本電腦的AI PC處理器,Lunar Lake的神經處理單元(NPU)帶來了重大升級,其集成了全新的第四代NPU內核(NPU 4),具備6個Neural Compute引擎、12個強化SHAVE 數字信號處理器(DSP)與9MB緩存,能夠提供48 TOPS的AI算力。

與上一代 NPU 3 相比,NPU 4 在增強神經處理能力和效率方面有了巨大飛躍。NPU 4 的改進主要是通過實現更高的頻率、更好的電源架構和更多的引擎數量來實現的,從而賦予它更好的性能和效率。

在 NPU 4 中,這些改進在矢量性能架構中得到了增強,計算塊數量更多,矩陣計算的優化性更好。這需要大量的神經處理帶寬;換句話說,這對于需要超高速數據處理和實時推理的應用程序至關重要。

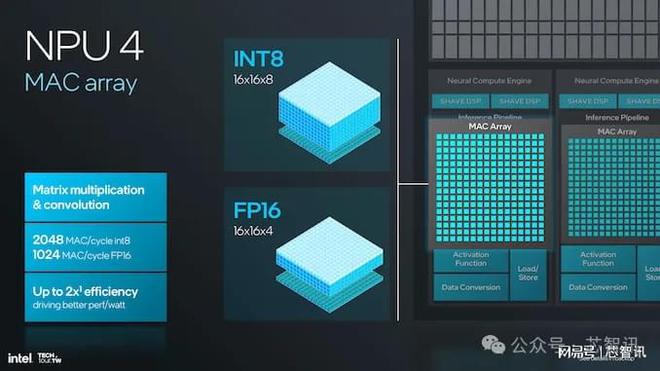
該架構支持 INT8 和 FP16 精度,INT8 每周期最多可進行 2048 次 MAC(乘法累加)運算,FP16 每周期最多可進行 1024 次 MAC 運算,這顯然表明計算效率顯著提高。
更深入地了解架構后,可以發現 NPU 4 的層次有所增加。其每個神經計算引擎都嵌入了令人難以置信的出色推理管道,包括 MAC 陣列和許多用于不同類型計算的專用 DSP。該管道專為眾多并行操作而構建,從而提高了性能和效率。新的 SHAVE DSP 經過優化,矢量計算能力是上一代的四倍,可以處理更復雜的神經網絡。
NPU 4 的另一項重大改進是提高了時鐘速度,并引入了一個新節點,在與 NPU 3 相同的功率水平下將性能提高了一倍。這使峰值性能提高了四倍,使 NPU 4 成為要求苛刻的 AI 應用的強大引擎。新的 MAC 陣列在芯片上具有先進的數據轉換功能,允許動態進行數據類型轉換、融合操作和輸出數據布局,從而使數據流以最小的延遲達到最佳狀態。
NPU 4 的帶寬改進對于處理更大的模型和數據集至關重要,尤其是在基于 Transformer 語言模型的應用程序中。該架構支持更高的數據流,從而減少瓶頸并確保即使在運行時也能順利運行。NPU 4 的 DMA(直接內存訪問)引擎將 DMA 帶寬翻倍——這是提高網絡性能的重要補充,也是處理重型神經網絡模型的有效方法。進一步支持更多功能,包括嵌入標記化,從而擴大了 NPU 4 的潛力。

NPU 4 的另一項顯著改進在于矩陣乘法和卷積運算,其中 MAC 陣列可以在單個周期內處理最多 2048 個 MAC 運算(INT8)和 1024 個 MAC 運算(FP16)。這反過來又使得 NPU 能夠以更高的速度和更低的功率處理更復雜的神經網絡計算。這在矢量寄存器文件的維度上產生了差異;NPU 4 的寬度為 512 位。這意味著在一個時鐘周期內,可以進行更多的矢量運算;這反過來又提高了計算效率。
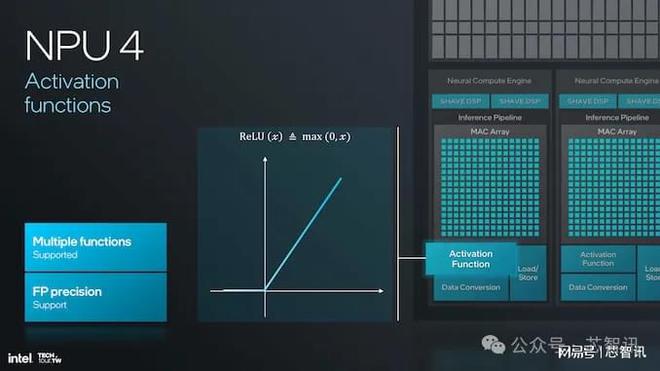
NPU 4 支持激活函數,現在有更多種類的激活函數可以支持和處理任何神經網絡,并可選擇精度來支持浮點計算,這將使計算更加精確和可靠。改進的激活函數和優化的推理管道,將使其能夠以更快的速度和更高的準確度執行更復雜和更細致的神經網絡模型。
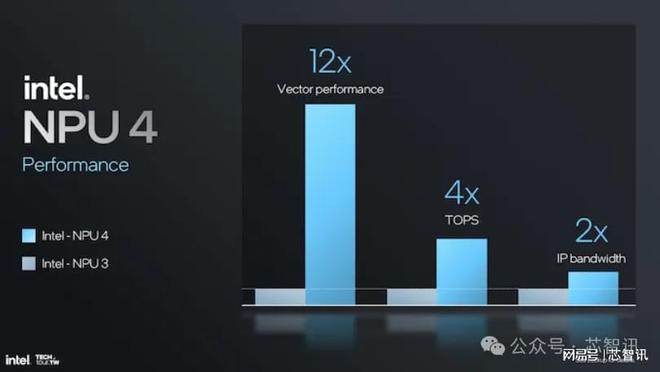
NPU 4 中的 SHAVE DSP 升級,使得其矢量計算能力達到了 NPU 3 的四倍,將整體的矢量性能整體提高 12 倍。這對于轉換器和大型語言模型 (LLM) 性能非常有用,使其更加快速和節能。增加每個時鐘周期的矢量操作可以實現更大的矢量寄存器文件大小,從而顯著提升 NPU 4 的計算能力。

總體而言,NPU 4 的性能比 NPU 3 有了大幅提升,整體的矢量性能提高了 12 倍,TOPS 算力提高了 4 倍,IP 帶寬提高了 2 倍。這些改進使 NPU 4 成為高性能和高效率的AI解決方案,適合性能和延遲至關重要的最新 AI 和機器學習應用。這些架構改進以及數據轉換和帶寬改進使 NPU 4 成為管理要求極高的 AI 工作負載的頂級解決方案。
4、更好的安全技術和高速連接技術
Lunar Lake平臺的控制層還內置了安全和新一代高速連接技術。
在安全方面,擁有Intel Partner Security(合作伙伴安全)引擎、Intel Silicon Security(硅安全)引擎、Converged Security和Manageability(融合安全與可管理性)引擎。
連接方面,Lunar Lake平臺則整合了最新的Wi-Fi 7、Bluetooth 5.4與1GbE MAC連接技術。
其中,集成的Wi-Fi 7解決方案支持多鏈路操作(Multi-Link Operation或MLO),它增加了可靠性,提高了吞吐量(支持5.8Gbps),改善了延遲,并實現了流量分離/區分。與BE200網絡接口相比,硅片尺寸縮小了28%,并采用11Gbps的CNVio3接口。此外,還采用了射頻干擾緩解技術,可動態調整對Wi-Fi性能有重大影響的DDR時鐘頻率。
英特爾還宣布與Meta 的合作更進一步,利用這項 Wi-Fi 7 技術來增強 VR 體驗。這進一步優化了視頻延遲性能并減少了干擾,從而使 VR 應用更加無縫和引人入勝,至少從無線連接的角度來看是如此。Wi-Fi 7 的新增強功能提供了高、可靠的速度和低延遲,可滿足 VR 應用中最具挑戰性的需求。

在接口方面,Lunar Lake提供4個PCIe 5.0、4個PCIe 4.0、3個整合的Thunderbolt 4(40Gbps)、2個USB 3.0與6個USB 2.0等接口。值得一提的是,Thunderbolt 4 接口通過Thunderbolt Share加速,可以將生產力提升到一個新水平,實現多臺電腦連接。
5、3D Foveros封裝與Scalable Fabric Gen 2互聯
Lunar Lake以上所有的計算核心、Memory Side緩存、安全、連接和I/O模塊均通過英特爾的3D Foveros多芯片封裝技術共同封裝在處理器基板上,并采用Memory On Package封裝,在Lunar Lake核心的旁邊封裝了32GB內存。
需要指出的是Lunar Lake的32GB w/ 2 Ranks LPDDR5X內存顆粒與處理器一同封裝在基版上,每芯片可有著8.5GT/s的傳輸頻寬、支持16b x 4信道,能夠降低40% PHY電源并節省250mm2的電路版面積。
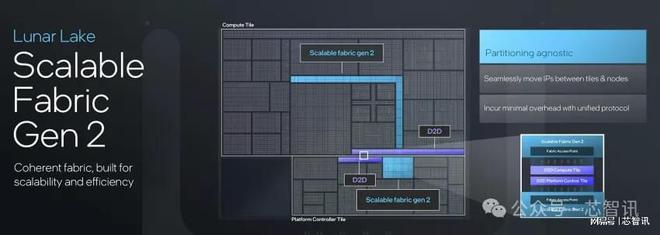
Lunar Lake的CPU、GPU和NPU計算核心則通過Scalable Fabric Gen 2進行互聯,然后通過D2D直接與平臺控制層的Scalable Fabric Gen 2連接,能夠無縫的銜接計算節點、芯片層,讓計算核心能有著更好的擴展性與效率。此外,借助Home Agent統籌整個層級的一致性(Hierarchical Coherency),包括Memory Side緩存、每個核心叢集中的Coherency Agent,包括平臺控制層的I/O Coherency。

6、全新的供電設計與電源管理,綜合能耗可降低40%
在供電方面,Lunar Lake采用了新的4個PMIC供電設計,可提供更多的供電路徑、動態電壓ID與更多的監控功能。針對SoC的供電使用優化達到最佳的性能效率。
在電源管理方面,集成的英特爾線程控制器專注于效率,還有針對每種負載類型優化的功率平衡器,增強的“睡眠”狀態電源和延遲,以及基于ML的WL分類與頻率控制。Thread Director(線程調度器)通過識別每個工作負載的級別并使用其能源和性能內核評分機制,幫助操作系統將線程調度到性能和效率最佳的內核上。
另外,Lunar Lake還在眾多核心芯片中加入了共享的8MB Memory Side緩存,可以降低DRAM的傳輸次數并節省電源,借助緩存機制讓核心與DRAM間的延遲進一步降低并提升傳輸帶寬。
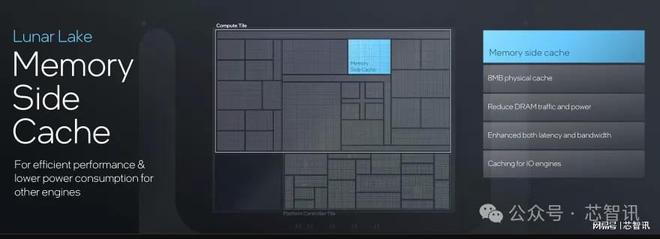
根據英特爾公布的數據顯示,得益于先進的工藝節點、新的E-core設計、Memory Side緩存、供電設計、電源管理及線程調度器技術,Lunar Lake比起上一代的Meteor Lake 的能耗可降低40%。
7、Lunar Lake三季度出貨,Arrow Lake四季度推出
據介紹,目前Lunar Lake已有超過80款設計,來自20家OEM廠商,預計第三季開始出貨。

英特爾還透露了未來的面向AI PC的移動處理器構架,今年第四季將推出面向桌面端的Arrow Lake,明年將會推出采用Intel 18A的Panther Lake,2026年后還會有后續新產品。

小結:綜合AI算力高達120 TOPS
從Lunar Lake的內部的各個核心來看,相對于上代的Meteor Lake,無疑是帶來了重大的升級,不僅CPU核心將 Lion Cove P 核與 Skymont E 核集成在一起,還帶了最新的 Xe2-LPG GPU架構,以及新一代的NPU 4 內核,帶來了領先的AI性能。
結合CPU、GPU和NPU所提供的AI算力,使得整個Lunar Lake平臺的AI總算力達到了120 TOPS,凸顯了英特爾在 AI 方面的投資。其中,CPU可通過VNNI與AVX指令提供5 TOPS的算力,驅動輕度AI工作;GPU提供的67 TOPS算力則通過XMX與DP4a提供游戲與創作所需的AI性能;NPU提供的48 TOPS算力能夠處理密集向量與矩陣運算,提供AI輔助與創作等功能。
作為對比,高通驍龍X Elite的NPU的算力為45TOPS,蘋果M4的NPU的算力只有38TOPS,雖然AMD最新推出的AI PC芯片——銳龍AI 300系列集成的AMD第三代NPU內核的AI算力提升到50TOPS,英特爾Lunar Lake的NPU內核的AI算力48TOPS略低,但是依然是大幅超過了微軟對于Copilot+ PC的最低NPU算力40TOPS的需求門檻,并且英特爾更專注于提供更高的綜合的AI算力,即通過AI引擎結合NPU、CPU和GPU,將綜合AI算力提高到了120TOPS,達到了上代Meteor Lake的接近3倍,這樣的提升幅度不可謂不高。
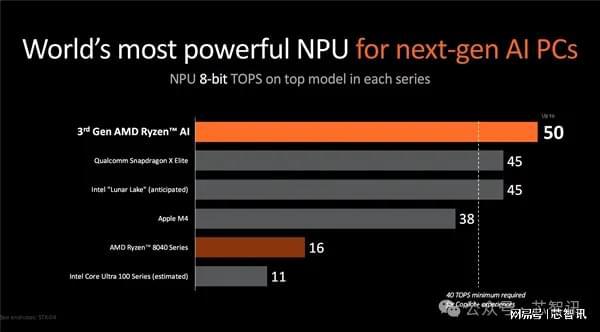
特別值得一提的是,Lunar Lake 還帶來了供電和電源管理方面的大幅改進,結合更先進的工藝節點、CPU計算核心等在能效方面的改進,使得Lunar Lake比起上一代的Meteor Lake 的能耗大幅降低,更適合于移動設備。
根據英特爾披露的數據顯示,Lunar Lake的GPU性能提升50%、NPU內核的AI算力增加了四倍、SoC耗電量減少40%、GPU AI算力增加3.5倍,整個SoC的算力超過了120TOPS。

總結來說,Lunar Lake相比上代的Meteor Lake帶來了巨大的性能提升,特別是在AI能力方面,同時也帶來了更高的能效和更低的功耗。相對于其他的AI PC芯片競品來說,依然有著不小的優勢。

英特爾CEO基辛格在演講當中也表示,非常看好AI PC的發展,目前已有超過800萬臺搭載英特爾—Core Ultra處理器的AI PC出貨,顯示AI PC時代已然來臨。
同時基辛格還預計今年基于英特爾芯片的AI PC出貨將達到4500萬臺,在2028年時,搭載AI功能的PC在所有PC當中的占比將達到80%的水平。而英特爾擁有300多個AI加速功能、500多個人工智能模型,當AI PC進入市場時,英特爾已經擁有了完整的AI PC生態系統。
顯然,隨著Lunar Lake的推出,將有助于進一步增強英特爾在AI PC芯片市場的競爭力。不過,Lunar Lake的具體市場表現如何,還有待觀察。
談到高通等Windows on Arm設備推出是否會影響英特爾X86 PC芯片的市占率,基辛格認為,這不是第一個Windows on Arm的產品發布,x86市占率仍維持領先,目前還沒明確誘因促使消費者從x86平臺轉換到Arm平臺,也還沒看到類似產品能取代x86現有構架,認為消費者需要有改變的理由,加上新推出的Lunar Lake擁有更好的性能表現,并不怕市占受影響。
被問到是否視高通為對手?基辛格笑說歡迎高通推出自家產品進入市場,因為這有助于更快創造整個市場,不過對自己很有自信,目前出貨量已經售100萬臺,從這角度看,表現比高通昨天呈現的Snapdragon X Elite更優秀。此外,從Lunar Lake到下一代Panther Lake,英特爾是打造自家生態系,是全新的篇章,在整個AI也很難被取代。
基辛格指出,下半年客戶購買Lunar Lake的PC會相當好的體驗,相信也會和高通產品做比較,未來會有更多跑分等信息出現。
目前英特爾積極擴展海外制造,在美國也有多項半導體建設。基辛格認為英特爾、三星、臺積電在美國布局,顯示美國芯片產業將有很大發展,研調機構也預期美國在半導體的影響力從10%增加至2030年的20%,相信會有很大動能的發展。英特爾在演講中不斷贊揚臺積電在Lunar Lake及與聯電的合作,顯示重視中國臺灣生態系,但全球需要更平衡的供應鏈,相信現在正在成形中。
對于被美國限制出口限制,是否可能讓中國加速芯片開發的問題,基辛格坦言,芯片禁令如同一條魔術界線(magic line),限制太強確實促使中國打造自研芯片,的確傷害出口市場,因此要小心平衡,英特爾要確保這方面能符合全球生態系伙伴的期待。同時英特爾也會持續出口產品到中國,隨著制程達到2nm以下,在中國半導體技術發展受到限制的背景下,英特爾這部分芯片在中國市場將更具吸引力。
審核編輯 黃宇
-
AI
+關注
關注
87文章
34001瀏覽量
275104 -
能耗
+關注
關注
1文章
392瀏覽量
13184 -
NPU
+關注
關注
2文章
318瀏覽量
19460 -
AI算力
+關注
關注
0文章
86瀏覽量
9127
發布評論請先 登錄
40+TOPS NPU,AI PC處理器開卷算力
6TOPS算力NPU加持!RK3588如何重塑8K顯示的邊緣計算新邊界
RK3588核心板在邊緣AI計算中的顛覆性優勢與場景落地
在英特爾酷睿Ultra AI PC上部署多種圖像生成模型

DeepSeek推動AI算力需求:800G光模塊的關鍵作用
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
英國政府計劃大幅提升AI算力
ThinkPad X1 Carbon Aura:以120TOPS算力、986克重量打造行業新巔峰!
NPU技術如何提升AI性能
《算力芯片 高性能 CPU/GPU/NPU 微架構分析》第1-4章閱讀心得——算力之巔:從基準測試到CPU微架構的深度探索
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
刷新AI PC NPU算力,AMD銳龍AI 9 HX 375領銜55 TOPS
加碼算力,8T可提升至12T,OrangePi AIpro/Kunpeng Pro升級不加價






 工商網監
工商網監

評論