 如何從處理器和加速器內核中榨取最大性能?
如何從處理器和加速器內核中榨取最大性能?
本文由半導體產業縱橫(ID:ICVIEWS)編譯自semiengineering
利用緩存增強低成本、上一代或中端的 SoC。
一些設計團隊在創建片上系統(SoC)設備時,有幸能夠使用最新和最先進的技術節點,并且擁有相對不受限制的預算來從可信的第三方供應商那里獲取知識產權(IP)模塊。然而,許多工程師并沒有這么幸運。對于每一個“不惜一切代價”的項目,都有一千個“在有限預算下盡你所能”的對應項目。
一種從成本較低、早期代、中檔處理器和加速器核心中擠出最大性能的方法是,明智地應用緩存。
削減成本圖1展示了一個典型的成本意識SoC場景的簡化示例。盡管SoC可能由許多IP組成,但這里為了清晰起見,只展示了三個。
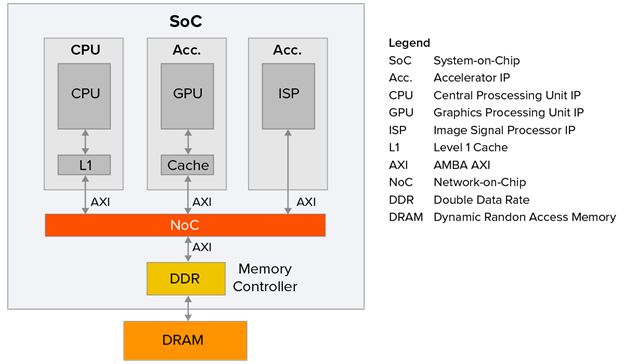
圖 1SoC內部IP之間連接的主要技術是網絡片上(NoC)互連IP。這可以被看作是一個跨越整個設備的IP。圖1中展示的例子可以假定為一個非緩存一致性場景。在這種情況下,任何一致性需求將由軟件處理。
假設SoC的時鐘運行在1GHz。假設一個基于精簡指令集計算機(RISC)架構的中央處理單元(CPU)運行一個典型指令將消耗一個時鐘周期。然而,訪問外部DRAM內存可能需要100到200個處理器時鐘周期(為了本文的目的,我們將這個平均為150個周期)。這意味著,如果CPU沒有一級(L1)緩存,并且通過NoC和DDR內存控制器直接連接到DRAM,那么每個指令將消耗150個處理器時鐘周期,導致CPU利用率僅為1/150 = 0.67%。
這就是為什么CPU以及一些加速器和其他IP使用緩存內存來提高處理器利用率和應用程序性能。緩存概念基于的基本原理是局部性原則。這個觀點是,在任何給定時間,只有一小部分主內存被使用,而且那個空間中的位置被多次訪問。主要是由于循環、嵌套循環和子程序,指令及其相關數據經歷時間、空間和順序局部性。這意味著,一旦一塊指令和數據從主內存復制到IP的緩存中,IP通常會反復訪問它們。
當今高端CPU IP通常至少有一個一級(L1)和二級(L2)緩存,它們通常還有一個三級(L3)緩存。此外,一些加速器IP,如圖形處理單元(GPU)通常有自己的內部緩存。然而,這些最新一代的高端IP的價格通常比上一代中檔產品高出5倍到10倍。因此,正如圖1所示,一個注重成本的SoC中的CPU可能只配備了一個L1緩存。
更深入地考慮CPU及其L1緩存。當CPU在其緩存中請求某物時,結果被稱為緩存命中。由于L1緩存通常以與處理器核心相同的速度運行,因此緩存命中將在單個處理器時鐘周期內處理。相比之下,如果請求的數據不在緩存中,結果稱為緩存未命中,將需要訪問主內存,這將消耗150個處理器時鐘周期。
現在考慮運行1,000,000條指令。如果緩存足夠大以包含整個程序,那么這將只消耗1,000,000個時鐘周期,從而實現100%的CPU效率。
不幸的是,中檔CPU中的L1緩存通常只有16KB到64KB的大小。如果我們假設95%的緩存命中率,那么我們的1,000,000條指令中的950,000條將需要一個處理器時鐘周期。其余的50,000條指令每條將消耗150個時鐘周期。因此,這種情況下的CPU效率可以計算為1,000,000/((950,000 * 1) + (50,000 * 150)) = ~12%。
提升性能
提高注重成本SoC性能的一種成本效益高的方式是添加緩存IP。例如,Arteris的CodaCache是一個可配置的、獨立的非一致性緩存IP。每個CodaCache實例可以高達8MB,并且可以在同一個SoC中實例化多個副本,如圖2所示。
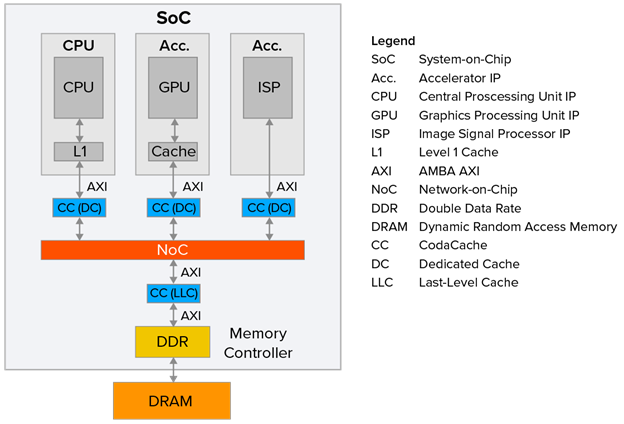
圖2
本文的目的并不是建議每個IP都應該配備一個CodaCache。圖2僅旨在提供潛在CodaCache部署的示例。
如果一個CodaCache實例與一個IP關聯,它被稱為專用緩存(DC)。或者,如果一個CodaCache實例與一個DDR內存控制器關聯,它被稱為末級緩存(LLC)。DC將加速與其關聯的IP的性能,而LLC將增強整個SoC的性能。
作為我們可能期望的性能提升類型的一個示例,考慮圖2中顯示的CPU。讓我們假設與這個IP關聯的CodaCache DC實例以處理器速度的一半運行,并且對這個緩存的任何訪問消耗20個處理器時鐘周期。如果我們還假設這個DC有95%的緩存命中率,那么對于1,000,000條指令——我們的整體CPU+L1+DC效率可以計算為1,000,000/((950,000 * 1) + (47,500 * 20) + (2,500 * 150)) = ~44%。這是一個~273%的性能提升!
結論過去,嵌入式程序員喜歡挑戰,盡可能從時鐘速度低、內存資源有限的小處理器中擠出最高性能。事實上,計算機雜志通常會向讀者提出挑戰,例如:“誰能在處理器Y上使用最少的時鐘周期和最小的內存量執行任務X?”
今天,許多SoC開發者喜歡挑戰,盡可能從他們的設計中擠出最高性能,特別是如果他們被限制使用性能較低的中檔IP。部署CodaCache IP作為專用和末級緩存,為工程師提供了一種負擔得起的方式來提升他們注重成本的SoC的性能。
-
處理器
+關注
關注
68文章
19259瀏覽量
229651 -
內核
+關注
關注
3文章
1372瀏覽量
40276 -
加速器
+關注
關注
2文章
796瀏覽量
37838
發布評論請先 登錄
相關推薦
充分利用數字信號處理器上的片內FIR和IIR硬件加速器
【FPGA干貨分享六】基于FPGA協處理器的算法加速的實現
【Aworks申請】中國科學院高能物理所質子直線加速器chopper電源
AM57x處理器實施多種內核
采用控制律加速器的Piccolo MCU
如何充分利用數字信號處理器上的片內FIR和IIR硬件加速器?
D-2700和D-1700處理器產品資料
利用硬件加速器提高處理器的性能
如何解放你的內核?硬件加速器“使用指南”奉上

TOPS 與現實世界的性能:AI 加速器的基準性能
利用數字信號處理器上的片上FIR和IIR硬件加速器
硬件加速器提升下一代SHARC處理器的性能





 工商網監
工商網監
評論