

隨著RISC-V這一革命性的開源指令集架構在全球范圍內的迅速普及,它為半導體行業帶來了前所未有的機遇與挑戰。在此大背景下,芯來科技和華東師范大學SOLE實驗室攜手合作,致力于在RISC-V處理器上進行深入的LLVM/CLANG編譯器優化以及程序性能優化和調優。
我們不僅優化了LLVM編譯器的多個關鍵環節,提升了代碼生成效率和執行性能,還針對視頻編解碼、性能測試等應用場景進行了深入分析和優化,提高了相關軟件的執行效率。
此次合作在RISC-V處理器上實現了一定程度的性能提升,同時,我們也希望能夠為RISC-V性能優化領域的同仁們提供一些有益的借鑒和參考。我們相信,通過持續的技術創新和開放的合作精神,我們可以共同推動這一領域的發展和進步。下面是我們本次合作的主要成果。
一、MCPPass冗余指令的刪除優化
在LLVM-17.x版本當中,生成的RISC-V端代碼會出現冗余數據搬運指令無法刪除的問題,詳情如下圖所示。在兩個紅框顯示的vmv指令當中,v0以及v8寄存器的值都沒有得到改變,但LLVM最終生成的RISC-V代碼依然會對這兩個值進行重復搬運。

冗余vmv指令無法在LLVM/Clang中消除的示例
經過核查,出現該問題的根因是LLVM的Machine Copy Propagation Pass對寄存器使用的Def-Use記錄不當所導致。經過對該問題進行修復后,該工作已經提交到了LLVM的上游倉庫。該優化亦應用到了LLVM多個后端的代碼生成當中,如RISC-V、X86以及AMDGPU的后端代碼生成當中。
二、RVV的低精度數據向量化取余以及右移代碼生成優化
C語言會采用Promotion Rule來保證混合精度或者是低精度數據運算結果的準確性,當遇到低精度數據如int8或者int16類型的數據進行逐元素(Element-Wise)取余或者是算術右移操作時,會先將相應的數據提升至32位,再將結果進行截斷至原來的精度以保證運算結果的正確性。然而,取決于RVV 1.0指令集動態調整元素大小的特性,該過程需要一系列的vsetvli類指令進行操作。
考慮到相關的計算溢出結果以及指令的行為在RVV 1.0指令集中已經得到明確定義,在LLVM編譯器生成相關代碼時可以進行下圖所示的優化:
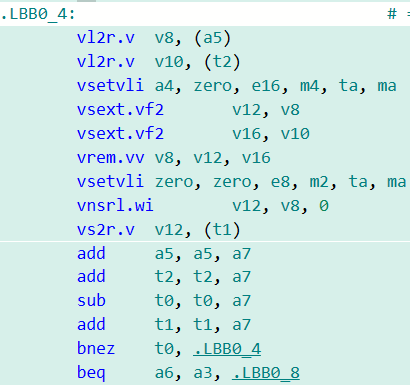
Element-wise vrem.vv優化前

Element-wise vrem.vv優化后

Element-wise vsra.vv優化前

Element-wise vsra.vv優化后 這些優化不僅可以從指令的語義上保證計算結果的正確性,而且能有效地避免頻繁復雜的數據精度提升與下降操作,這些優化工作亦被提交到了LLVM的上游倉庫當中。
三、FFMPEGX264編解碼熱點采集分析
RISC-V Vector 1.0向量化指令集可以被用于視頻編解碼應用的加速處理當中,而FFMPEG作為最常見的音視頻處理軟件之一,在其關鍵核心且可向量化函數當中,大部分亦都利用RVV 1.0匯編或者Intrinsic進行了重寫。盡管如此,如何針對其常用的x264編解碼功能進行編譯優化機會的探索,依然是提高其執行效率的一個重要手段。
我們采集對比了GCC 14.1與LLVM/Clang 17.2編譯出來的FFMPEG,在進行x264視頻編解碼時的熱點函數,詳情下圖所示。根據結果可以看到,熱點函數都聚集在了libx264的x264_piexel_sad類函數之上。
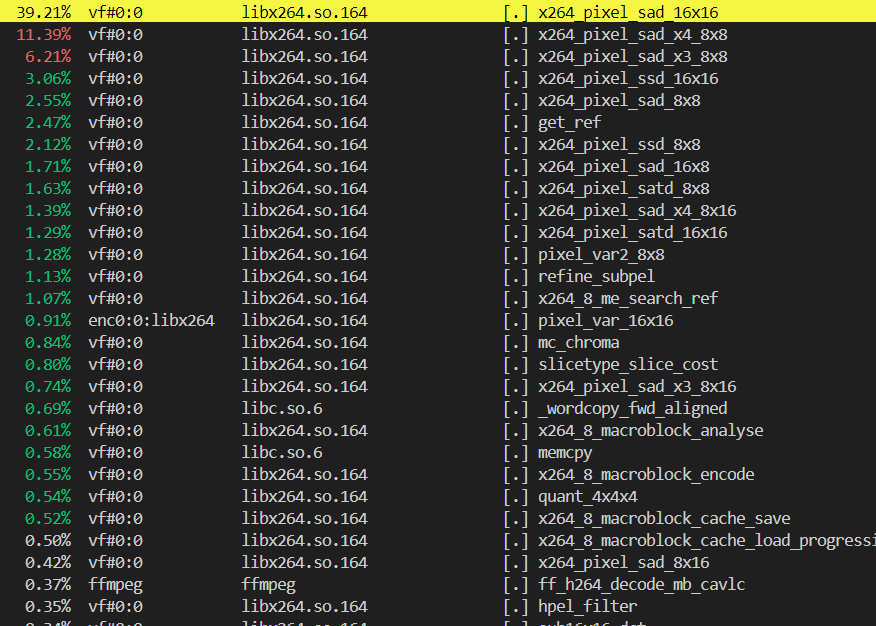
FFMPEG X264編碼熱點分析(GCC)

FFMPEG X264編碼熱點分析(LLVM/Clang)
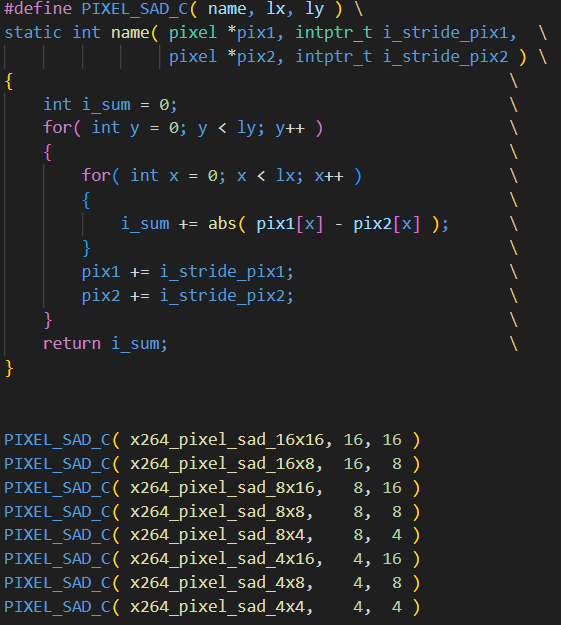
x264_pixel_sad類函數聲明
而這類x264_piexel_sad函數本質上就是一系列的abs函數的處理,這類函數的定義可以如上圖所示。
以16x16的迭代大小為例子,下面的圖分別對比了LLVM/Clang以及GCC在該函數上生成代碼的細致區別(開啟-O3)。
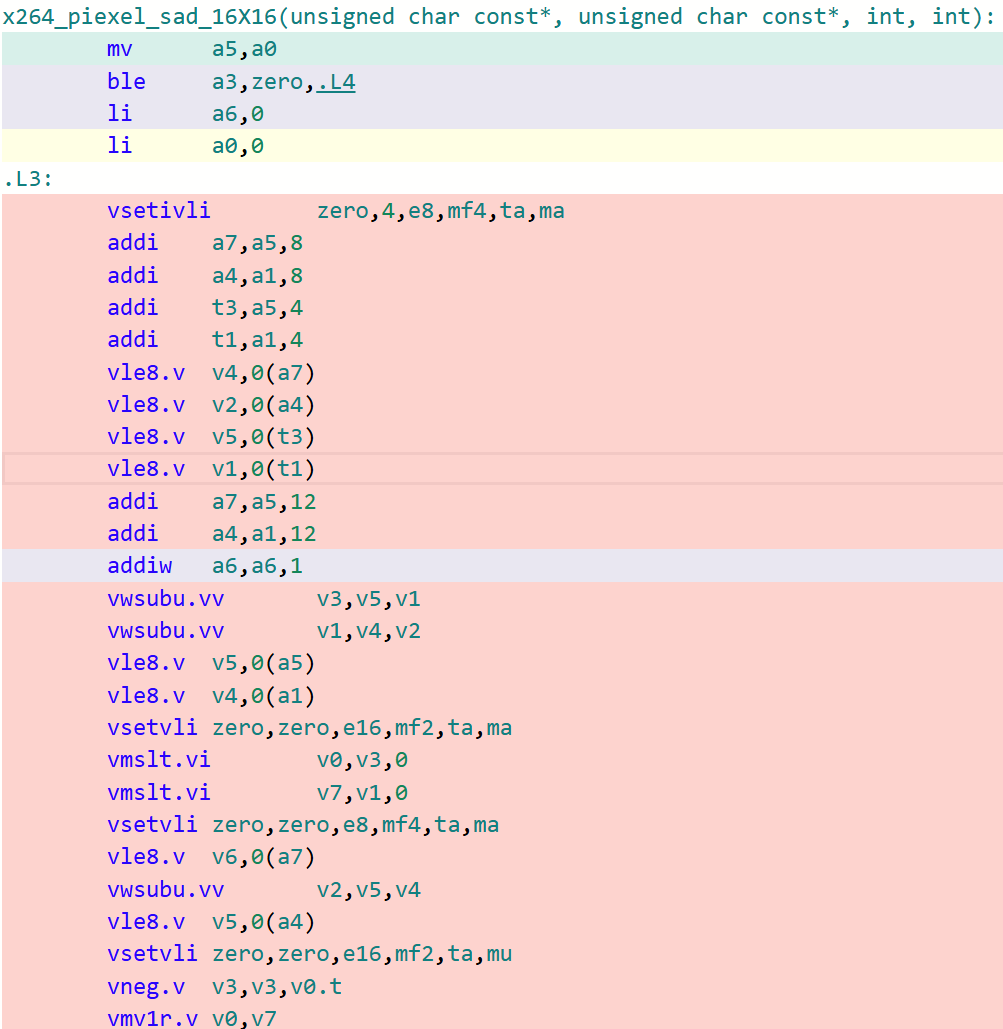
x264_piexel_sad_16x16函數 GCC生成代碼
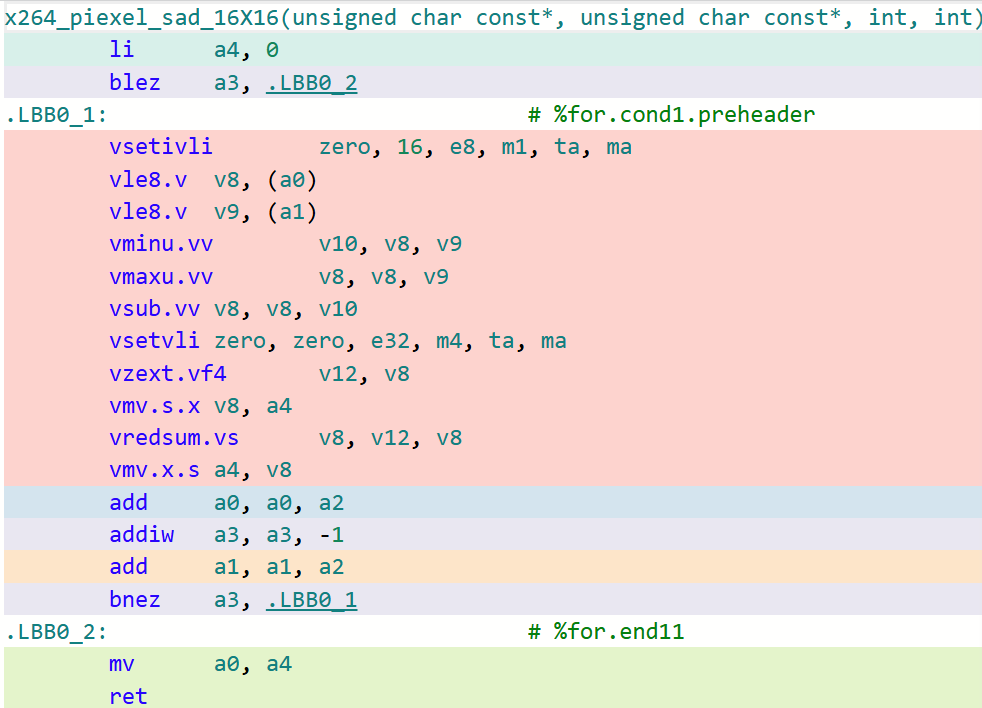
x264_piexel_sad_16x16函數 LLVM/Clang生成代碼
可以看到,在默認O3的選項下,GCC生成的代碼對于這類核心函數的處理效率遠不如LLVM/Clang。這是因為GCC默認采用LMUL=1(向量化分組大小為1)的大小進行代碼生成,即其生成的RVV代碼采用的LMUL大小不能高于1。在探索到這些根因后,可以采用GCC最新14.1版本中所提供的-mrvv-max-lmul=dynamic選項對這類生成的代碼進行改進,采用該選項優化后的代碼如下圖所示:

LMUL設置為dyanamic時GCC生成的代碼
此時,GCC在此處生成的代碼執行效率已經能夠和LLVM/Clang相匹配。因此,我們在采用GCC編譯的FFMPEG進行x264視頻編解碼時,為了更高的核心代碼執行效率,建議將GCC動態調整LMUL大小的編譯選項進行開啟。
四、CoreMark的JumpThreading優化
Coremark是評估CPU性能常見的一個測試程序,但是采用LLVM/Clang編譯器編譯優化coremark程序跑分效果遠遠比不上GCC,因此我們分析了Coremark程序的熱點函數,發現可以通過Jump Threading技術來進行優化,Jump Threading是一種專門用于控制流程圖(CFG)優化的一種編譯優化技術,它會在執行分支前遇到確定變量的值時,直接執行確認值在分支以后的路徑,即采用無條件的跳轉替代條件跳轉,詳情如下圖所示:
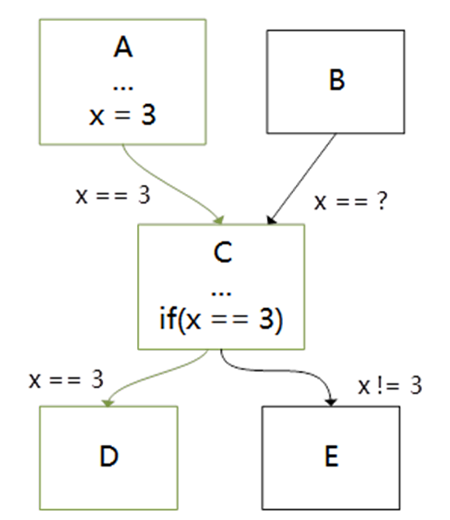
優化前的CFG
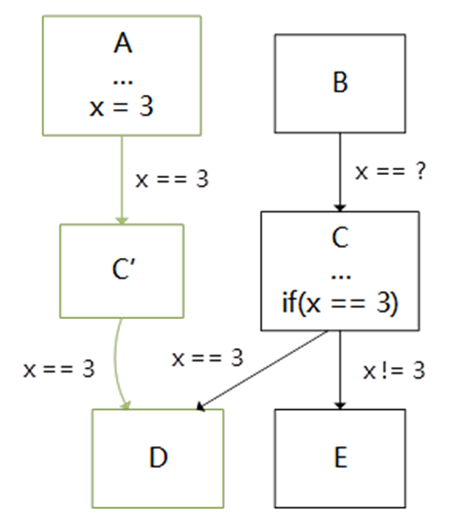
優化后的CFG
該優化會對CFG路徑中變量的值進行掃描遍歷,并尋找到可以利用無條件跳轉替換條件判斷的路徑,并進行基本塊的克隆與路徑的替換。考慮到該掃描過程較為耗時,LLVM中默認的Jump Threading優化采取較為輕量級的掃描方式。通過在芯來編譯工具鏈的LLVM/Clang中引入一系列更為激烈的Jump Threading掃描優化手段后,將采用Clang編譯的CoreMark并運行在芯來N300模擬器上的跑分提升約18%。
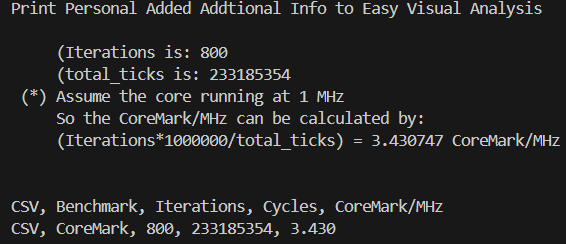
LLVM/Clang調優前CoreMark跑分
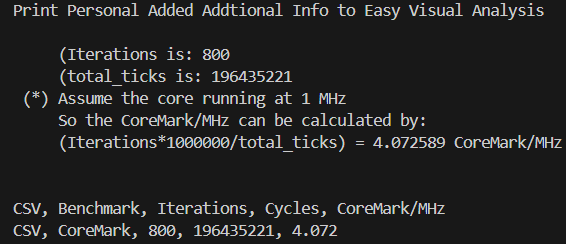
引入額外Jump Threading優化后的CoreMark跑分
五、SPECCPU2006的編譯選項調優
SPEC CPU 2006 INT是業界常用的CPU性能基準測試套件,為了提高SPEC CPU 2006 INT的測試跑分,常常需要找到更適合的編譯選項來對編譯器進行調優,以獲得更好的SPEC分數。然而,考慮到目前大部分的最佳跑分配置都是利用業界專用編譯器,如Intel的ICC編譯器以及AMD的AOCC編譯器等進行跑分。對于RISC-V指令集架構平臺,這類專用的編譯器并不能夠適用。同時,假如采用Ref測試集來進行編譯選項的調優,則需要消耗大量的測試時間。
為了加速調優,我們采用了一種更為靈活且快捷的基于Qemu仿真器的動態指令計數對比的編譯選項調優方法。下圖展示了采用GCC-13對SPEC CPU2006 INT的TEST測試集進行選項調優的結果。
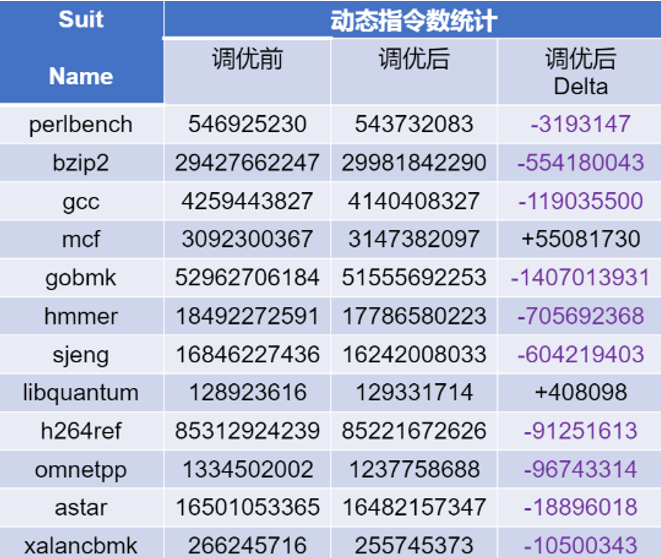
SPEC CPU 2006 INT動態指令數目調優結果
經過精心調優的編譯選項在SPEC CPU2006 INT的多項測試程序中顯著降低了動態指令的數量。進一步地,我們在FPGA開發板上進行了實際的性能對比測試。結果表明,這種基于動態指令計數的調優方法不僅有效,而且在資源受限的開發板或仿真CPU主頻受限的FPGA環境中,為編譯選項的優化提供了一種切實可行的策略。這一發現為在類似條件下的性能提升開辟了新的探索路徑。
此次合作是雙方在技術研究和應用開發領域共同努力的成果,它體現了我們團隊在探索和實踐過程中的專注與努力。同時,我們對于能夠參與到產學研合作這一推動技術革新的重要力量中來而深感榮幸。相信通過這樣的合作模式,我們能夠與業界同仁共同學習、相互啟發,為整個技術社區的發展貢獻綿薄之力。
審核編輯:彭菁
-
代碼
+關注
關注
30文章
4887瀏覽量
70259 -
編譯器
+關注
關注
1文章
1655瀏覽量
49891 -
視頻編解碼
+關注
關注
2文章
54瀏覽量
11931 -
芯來科技
+關注
關注
0文章
70瀏覽量
3367
原文標題:芯來科技與華東師范大學SOLE實驗室合作推動RISC-V性能優化
文章出處:【微信號:nucleisys,微信公眾號:芯來科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
紫光展銳“芯火”科普課堂走進華東師范大學張江實驗中學
伊利師范大學選購我司液氮制冷差示掃描量熱儀

華師大鴻星未來實驗室揭牌!迅龍軟件總經理趙一帆受聘企業碩士導師

是德科技和馬拉加大學成立6G研究與創新實驗室
龍芯“百芯計劃”聯合實驗室首批高校名單揭曉
Triton編譯器的優化技巧
Triton編譯器與其他編譯器的比較
深開鴻與華南師范大學簽署戰略合作框架協議,共探產學研協同創新

HighTec C/C++編譯器套件全面支持芯來RISC-V IP
DFRobot與西北師范大學教育技術學院簽署院企協同育人暨戰略合作協議
分享關于編譯器的科普
龍芯中科與南京師范大學達成產教合作
華東師范大學的老師 上課已經用上了大模型





 工商網監
工商網監

評論